DriveReward: A Comprehensive Dataset and Generative Vision-Language Reward Model for Autonomous Driving
Pith reviewed 2026-06-27 18:56 UTC · model grok-4.3
The pith
A specialized 1B vision-language reward model trained on the DriveReward dataset matches rule-based rewards in autonomous driving RL finetuning and trajectory scoring.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
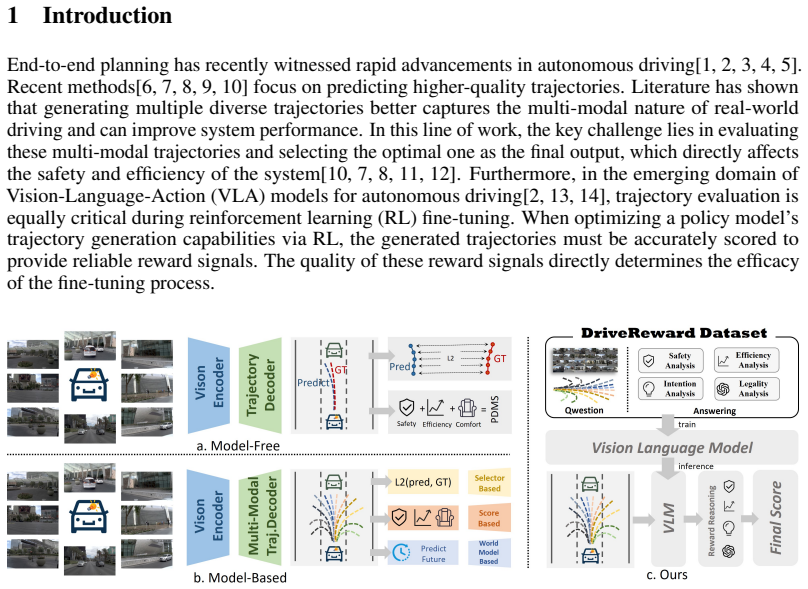
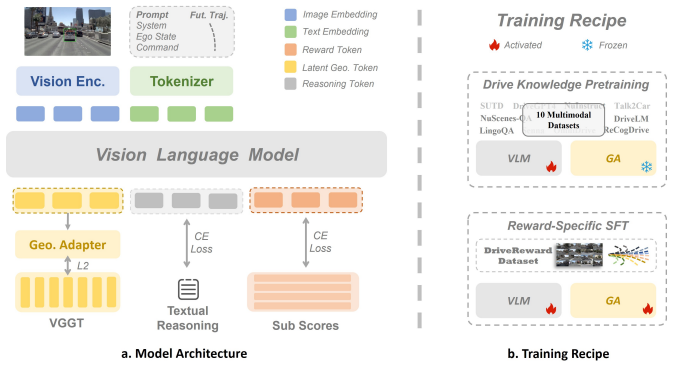
We introduce DriveReward, a reasoning trajectory evaluation dataset rigorously labeled via temporally-grounded visual guidance and augmented with counterfactual driving behaviors via a specialized annotation scheme, and train a 1B generative vision-language reward model that outperforms larger VLMs on task-specific reward alignment while achieving performance comparable to rule-based reward calculations when integrated into RL finetuning and multi-modal trajectory scoring across multiple baselines in open-loop and closed-loop evaluation.
What carries the argument
The counterfactual data annotation scheme that augments the DriveReward dataset with diverse driving styles and erroneous behaviors to train the specialized 1B vision-language reward model.
If this is right
- The 1B reward model outperforms larger VLMs on task-specific reward alignment in the DriveReward benchmark.
- Integrating the model into RL finetuning produces policies with performance comparable to rule-based objectives.
- Multi-modal trajectory scoring with the model matches rule-based calculations in both open-loop and closed-loop evaluations.
- Leading open-source and proprietary VLMs fail to excel across all tasks on the proposed benchmark.
Where Pith is reading between the lines
- Similar counterfactual augmentation could address failure-case scarcity in reward modeling for other robotics domains.
- The approach might reduce manual engineering of reward functions when scaling RL to new driving environments.
- Testing the model on trajectories from unseen geographic regions or weather conditions would check generalization beyond the dataset.
- The dataset could serve as a starting point for training even smaller or more efficient reward models.
Load-bearing premise
The counterfactual data annotation scheme to construct cases encompassing diverse driving styles and erroneous behaviors accurately represents real failure modes without introducing annotation artifacts or distribution shift.
What would settle it
If the 1B model produces trajectory scores or RL policies that diverge from rule-based rewards in a held-out closed-loop simulator or on new real-world video data, the claim of comparable effectiveness would be falsified.
Figures



read the original abstract
Reward models play a pivotal role in reinforcement learning (RL) and multi-modal trajectory selection for autonomous driving. However, acquiring such rewards typically relies on hand-crafted rule-based objectives or perception ground truth, which hinders generalization for data-scaling. While Vision-Language Models (VLMs) have demonstrated feasibility as reward models in other domains, their effectiveness in driving tasks remains underexplored. In this work, we bridge this gap by (1) introducing DriveReward, a reasoning trajectory evaluation dataset rigorously labeled via temporally-grounded visual guidance, and augmented with counterfactual driving behaviors., (2) alongside a specialized Vision-Language Reward Model. To address the scarcity of failure cases in conventional datasets, we propose a counterfactual data annotation scheme to construct cases encompassing diverse driving styles and erroneous behaviors. Evaluations on our proposed benchmark reveal that even leading open-source and proprietary VLMs fail to excel across all tasks, highlighting significant room for improvement in existing models. Building on these findings, we subsequently tailor a specialized 1B reward model that outperforms larger VLMs on task-specific reward alignment. Finally, we validate our reward model's effectiveness by integrating it into RL finetuning and multi-modal trajectory scoring across multiple baselines, achieving performance comparable to rule-based reward calculations in both open-loop and closed-loop evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DriveReward, a reasoning trajectory evaluation dataset for autonomous driving constructed via temporally-grounded visual guidance and counterfactual augmentation to address scarcity of failure cases, along with a specialized 1B-parameter vision-language reward model. The model is shown to outperform larger VLMs on task-specific alignment, and its integration into RL finetuning and multi-modal trajectory scoring yields performance comparable to rule-based rewards in open- and closed-loop evaluations.
Significance. If the central claims hold, the work offers a scalable data-driven alternative to hand-crafted rule-based rewards for AV applications, potentially improving generalization as datasets scale. The provision of a benchmark exposing limitations in existing VLMs and a compact specialized model are notable contributions, though their impact hinges on the fidelity of the synthetic failure cases.
major comments (3)
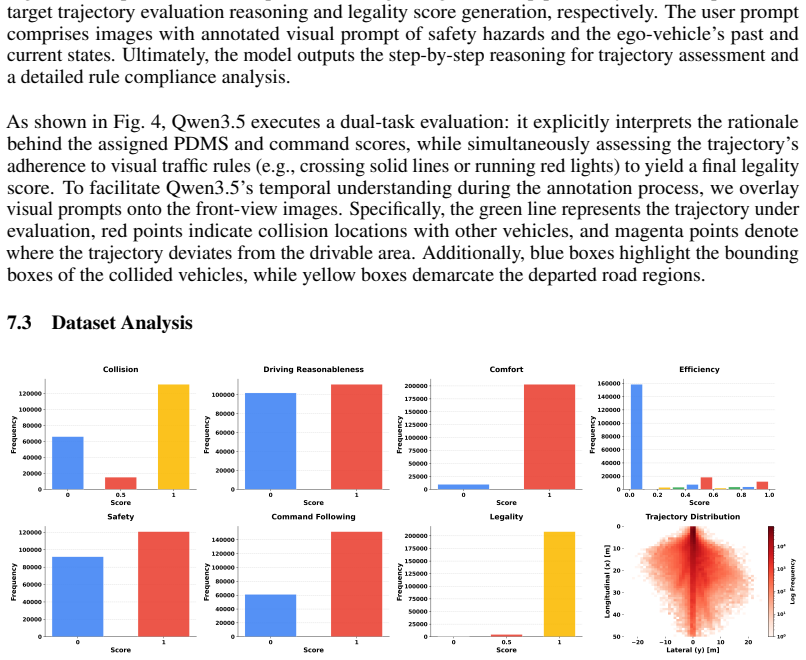
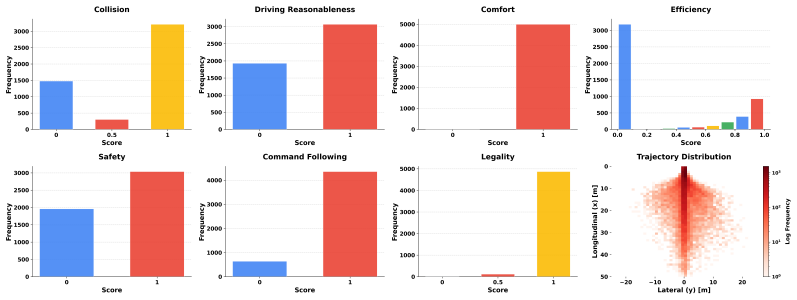
- [§3.2] §3.2 (Counterfactual Data Annotation): The claim that the temporally-grounded visual guidance scheme produces failure cases without introducing distribution shift or annotation artifacts is load-bearing for the RL results in §5, yet no quantitative validation (e.g., comparison of error category frequencies, visual feature statistics, or distributional metrics against real logs such as nuScenes or Waymo) is reported. This leaves open whether the reported matching to rule-based rewards reflects genuine generalization or overfitting to the augmentation process.
- [§4.3] §4.3 and Table 2: The 1B reward model is reported to outperform larger VLMs on reward alignment, but the training details do not clarify whether the evaluation set was held out from the counterfactual augmentation pipeline or if any overlap exists with the rule-based signals used to label the dataset; this directly affects the interpretation of the 'outperforms larger VLMs' result.
- [§5.1] §5.1 (RL Finetuning Experiments): The closed-loop evaluation claims performance 'comparable' to rule-based rewards across baselines, but no statistical significance testing, variance across multiple seeds, or ablation removing the counterfactual cases is provided, making it impossible to determine if the equivalence is robust or sensitive to the synthetic data distribution.
minor comments (3)
- [Abstract, §1] The abstract and §1 use 'rigorously labeled' without defining the inter-annotator agreement protocol or labeler expertise criteria; add this detail for reproducibility.
- [Figure 3] Figure 3 (dataset examples) would benefit from side-by-side comparison of original vs. counterfactual trajectories with explicit visual callouts for the introduced errors.
- [§4.1, §4.2] Notation for the reward model output (e.g., scalar vs. structured reasoning) is introduced inconsistently between §4.1 and the evaluation metrics in §4.2; standardize the definition.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Counterfactual Data Annotation): The claim that the temporally-grounded visual guidance scheme produces failure cases without introducing distribution shift or annotation artifacts is load-bearing for the RL results in §5, yet no quantitative validation (e.g., comparison of error category frequencies, visual feature statistics, or distributional metrics against real logs such as nuScenes or Waymo) is reported. This leaves open whether the reported matching to rule-based rewards reflects genuine generalization or overfitting to the augmentation process.
Authors: We agree that quantitative validation would strengthen the claims regarding minimal distribution shift. Our counterfactual augmentation is constructed via temporally-grounded visual guidance to preserve scene consistency and driving dynamics from real logs, but we did not report explicit distributional comparisons. In the revised manuscript, we will add analyses comparing error category frequencies and visual feature statistics (e.g., via feature-based metrics such as FID on CLIP embeddings) between the augmented cases and real datasets including nuScenes and Waymo. revision: yes
-
Referee: [§4.3] §4.3 and Table 2: The 1B reward model is reported to outperform larger VLMs on reward alignment, but the training details do not clarify whether the evaluation set was held out from the counterfactual augmentation pipeline or if any overlap exists with the rule-based signals used to label the dataset; this directly affects the interpretation of the 'outperforms larger VLMs' result.
Authors: The evaluation set was held out from the counterfactual augmentation pipeline with no trajectory overlap. Rule-based signals were used only to guide initial dataset labeling during construction; the reward model was trained exclusively on the VLM-generated reasoning annotations. We will revise §4.3 to explicitly clarify the held-out split and the distinction between labeling signals and training targets. revision: partial
-
Referee: [§5.1] §5.1 (RL Finetuning Experiments): The closed-loop evaluation claims performance 'comparable' to rule-based rewards across baselines, but no statistical significance testing, variance across multiple seeds, or ablation removing the counterfactual cases is provided, making it impossible to determine if the equivalence is robust or sensitive to the synthetic data distribution.
Authors: We recognize that multi-seed variance and statistical testing would improve robustness assessment. Closed-loop RL evaluations are computationally intensive, so experiments used fixed seeds for reproducibility across baselines. In the revision we will add an ablation removing counterfactual cases and report additional seeds where feasible; the current equivalence holds consistently across open- and closed-loop settings and multiple baselines. revision: partial
Circularity Check
No significant circularity; derivation relies on new dataset and external benchmarks
full rationale
The paper constructs DriveReward via temporally-grounded visual guidance and counterfactual augmentation, then trains a 1B VLM and evaluates it on task-specific alignment plus RL integration against rule-based rewards. No equations, self-citations, or definitions are provided that reduce any claimed prediction or result to the inputs by construction. The validation uses independent open/closed-loop metrics and comparisons to larger VLMs, keeping the chain self-contained against external signals rather than fitted or renamed inputs.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
DriveVer: Lightweight Trajectory Evaluator as Test-Time Verifier for Autonomous Driving
DriveVer is a lightweight dual-head test-time verifier that predicts safety confidence scores and geometric refinement vectors for candidate trajectories, improving base planners on the NAVSIM benchmark.
Reference graph
Works this paper leans on
-
[1]
Sparsedrive: End-to-end autonomous driving via sparse scene representation
Wenchao Sun, Xuewu Lin, Yining Shi, Chuang Zhang, Haoran Wu, and Sifa Zheng. Sparsedrive: End-to-end autonomous driving via sparse scene representation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8795–8801. IEEE, 2025
2025
-
[2]
Yuechen Luo, Fang Li, Shaoqing Xu, Zhiyi Lai, Lei Yang, Qimao Chen, Ziang Luo, Zixun Xie, Shengyin Jiang, Jiaxin Liu, et al. Adathinkdrive: Adaptive thinking via reinforcement learning for autonomous driving.arXiv preprint arXiv:2509.13769, 2025
-
[3]
Haoyu Fu, Diankun Zhang, Zongchuang Zhao, Jianfeng Cui, Dingkang Liang, Chong Zhang, Dingyuan Zhang, Hongwei Xie, Bing Wang, and Xiang Bai. Orion: A holistic end-to-end autonomous driving framework by vision-language instructed action generation.arXiv preprint arXiv:2503.19755, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Vad: Vectorized scene representation for efficient autonomous driving
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representation for efficient autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8340–8350, 2023
2023
-
[5]
Ziang Luo, Kangan Qian, Jiahua Wang, Yuechen Luo, Jinyu Miao, Zheng Fu, Yunlong Wang, Sicong Jiang, Zilin Huang, Yifei Hu, et al. Mtrdrive: Memory-tool synergistic reasoning for robust autonomous driving in corner cases.arXiv preprint arXiv:2509.20843, 2025
-
[6]
Hydra-next: Robust closed-loop driving with open-loop training.arXiv preprint arXiv:2503.12030, 2025
Zhenxin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Zuxuan Wu, and Jose M Alvarez. Hydra-next: Robust closed-loop driving with open-loop training.arXiv preprint arXiv:2503.12030, 2025
-
[7]
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
Zhenxin Li, Kailin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Yishen Ji, Zhiqi Li, Ziyue Zhu, Jan Kautz, Zuxuan Wu, et al. Hydra-mdp: End-to-end multimodal planning with multi-target hydra-distillation.arXiv preprint arXiv:2406.06978, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving
Bencheng Liao, Shaoyu Chen, Haoran Yin, Bo Jiang, Cheng Wang, Sixu Yan, Xinbang Zhang, Xiangyu Li, Ying Zhang, Qian Zhang, et al. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12037–12047, 2025
2025
-
[9]
Goalflow: Goal-driven flow matching for multimodal trajectories generation in end- to-end autonomous driving
Zebin Xing, Xingyu Zhang, Yang Hu, Bo Jiang, Tong He, Qian Zhang, Xiaoxiao Long, and Wei Yin. Goalflow: Goal-driven flow matching for multimodal trajectories generation in end- to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1602–1611, 2025
2025
-
[10]
Zhenxin Li, Wenhao Yao, Zi Wang, Xinglong Sun, Joshua Chen, Nadine Chang, Maying Shen, Zuxuan Wu, Shiyi Lan, and Jose M Alvarez. Generalized trajectory scoring for end-to-end multimodal planning.arXiv preprint arXiv:2506.06664, 2025
-
[11]
Driving on registers.arXiv preprint arXiv:2601.05083, 2026
Ellington Kirby, Alexandre Boulch, Yihong Xu, Yuan Yin, Gilles Puy, Éloi Zablocki, Andrei Bursuc, Spyros Gidaris, Renaud Marlet, Florent Bartoccioni, et al. Driving on registers.arXiv preprint arXiv:2601.05083, 2026
-
[12]
Qimao Chen, Fang Li, Shaoqing Xu, Zhiyi Lai, Zixun Xie, Yuechen Luo, Shengyin Jiang, Hanbing Li, Long Chen, Bing Wang, et al. Vilta: A vlm-in-the-loop adversary for enhancing driving policy robustness.arXiv preprint arXiv:2601.12672, 2026
-
[13]
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Yongkang Li, Kaixin Xiong, Xiangyu Guo, Fang Li, Sixu Yan, Gangwei Xu, Lijun Zhou, Long Chen, Haiyang Sun, Bing Wang, et al. Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving.arXiv preprint arXiv:2506.08052, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Zewei Zhou, Tianhui Cai, Seth Z Zhao, Yun Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma. Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning.arXiv preprint arXiv:2506.13757, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Navsim: Data-driven non- reactive autonomous vehicle simulation and benchmarking.Advances in Neural Information Processing Systems, 37:28706–28719, 2024
Daniel Dauner, Marcel Hallgarten, Tianyu Li, Xinshuo Weng, Zhiyu Huang, Zetong Yang, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, et al. Navsim: Data-driven non- reactive autonomous vehicle simulation and benchmarking.Advances in Neural Information Processing Systems, 37:28706–28719, 2024. 10
2024
-
[16]
Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driving.Advances in Neural Information Processing Systems, 37:819–844, 2024
Xiaosong Jia, Zhenjie Yang, Qifeng Li, Zhiyuan Zhang, and Junchi Yan. Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driving.Advances in Neural Information Processing Systems, 37:819–844, 2024
2024
-
[17]
Yingyan Li, Yuqi Wang, Yang Liu, Jiawei He, Lue Fan, and Zhaoxiang Zhang. End-to-end driving with online trajectory evaluation via bev world model.arXiv preprint arXiv:2504.01941, 2025
-
[18]
Bin Sun, Yaoguang Cao, Yan Wang, Rui Wang, Jiachen Shang, Xiejie Feng, Jiayi Lu, Jia Shi, Shichun Yang, Xiaoyu Yan, et al. Minddrive: An all-in-one framework bridging world models and vision-language model for end-to-end autonomous driving.arXiv preprint arXiv:2512.04441, 2025
-
[19]
Unleashing vla potentials in autonomous driving via explicit learning from failures
Yuechen Luo, Qimao Chen, Fang Li, Shaoqing Xu, Jaxin Liu, Ziying Song, Zhi-xin Yang, and Fuxi Wen. Unleashing vla potentials in autonomous driving via explicit learning from failures. arXiv preprint arXiv:2603.01063, 2026
-
[20]
Self-generated critiques boost reward modeling for language models
Yue Yu, Zhengxing Chen, Aston Zhang, Liang Tan, Chenguang Zhu, Richard Yuanzhe Pang, Yundi Qian, Xuewei Wang, Suchin Gururangan, Chao Zhang, et al. Self-generated critiques boost reward modeling for language models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language ...
2025
-
[21]
Gen-drive: Enhancing diffusion generative driving policies with reward modeling and reinforcement learning fine-tuning
Zhiyu Huang, Xinshuo Weng, Maximilian Igl, Yuxiao Chen, Yulong Cao, Boris Ivanovic, Marco Pavone, and Chen Lv. Gen-drive: Enhancing diffusion generative driving policies with reward modeling and reinforcement learning fine-tuning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 3445–3451. IEEE, 2025
2025
-
[22]
Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario
Tianwen Qian, Jingjing Chen, Linhai Zhuo, Yang Jiao, and Yu-Gang Jiang. Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 4542–4550, 2024
2024
-
[23]
NuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles
Holger Caesar, Juraj Kabzan, Kok Seang Tan, Whye Kit Fong, Eric Wolff, Alex Lang, Luke Fletcher, Oscar Beijbom, and Sammy Omari. nuplan: A closed-loop ml-based planning benchmark for autonomous vehicles.arXiv preprint arXiv:2106.11810, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[24]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026
2026
-
[25]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[27]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
2026
-
[29]
Jialv Zou, Shaoyu Chen, Bencheng Liao, Zhiyu Zheng, Yuehao Song, Lefei Zhang, Qian Zhang, Wenyu Liu, and Xinggang Wang. Diffusiondrivev2: Reinforcement learning-constrained trun- cated diffusion modeling in end-to-end autonomous driving.arXiv preprint arXiv:2512.07745, 2025
-
[30]
Rethinking the Open-Loop Evaluation of End-to-End Autonomous Driving in nuScenes
Jiang-Tian Zhai, Ze Feng, Jihao Du, Yongqiang Mao, Jiang-Jiang Liu, Zichang Tan, Yifu Zhang, Xiaoqing Ye, and Jingdong Wang. Rethinking the open-loop evaluation of end-to-end autonomous driving in nuscenes.arXiv preprint arXiv:2305.10430, 2023. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17853–17862, 2023
2023
-
[32]
Carla: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. Carla: An open urban driving simulator. InConference on robot learning, pages 1–16. PMLR, 2017
2017
-
[33]
Llava-critic: Learning to evaluate multimodal models
Tianyi Xiong, Xiyao Wang, Dong Guo, Qinghao Ye, Haoqi Fan, Quanquan Gu, Heng Huang, and Chunyuan Li. Llava-critic: Learning to evaluate multimodal models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13618–13628, 2025
2025
-
[34]
Yuhang Zang, Xiaoyi Dong, Pan Zhang, Yuhang Cao, Ziyu Liu, Shengyuan Ding, Shenxi Wu, Yubo Ma, Haodong Duan, Wenwei Zhang, et al. Internlm-xcomposer2. 5-reward: A simple yet effective multi-modal reward model, 2025.URL https://arxiv. org/abs/2501.12368
-
[35]
Xingzhou Lou, Dong Yan, Wei Shen, Yuzi Yan, Jian Xie, and Junge Zhang. Uncertainty- aware reward model: Teaching reward models to know what is unknown.arXiv preprint arXiv:2410.00847, 2024
-
[36]
Mm-rlhf: The next step forward in multimodal llm alignment, 2025c.URL https://arxiv
Yi-Fan Zhang, Tao Yu, Haochen Tian, Chaoyou Fu, Peiyan Li, Jianshu Zeng, Wulin Xie, Yang Shi, Huanyu Zhang, Junkang Wu, et al. Mm-rlhf: The next step forward in multimodal llm alignment, 2025c.URL https://arxiv. org/abs/2502.10391
-
[37]
Swift:a scalable lightweight infrastructure for fine-tuning, 2024
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, Wenmeng Zhou, and Yingda Chen. Swift:a scalable lightweight infrastructure for fine-tuning, 2024
2024
-
[38]
Drivelm: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering. InEuropean conference on computer vision, pages 256–274. Springer, 2024
2024
-
[39]
SUTD-TrafficQA: A Question Answering Benchmark and an Efficient Network for Video Reasoning Over Traffic Events
Li Xu, He Huang, and Jun Liu. SUTD-TrafficQA: A Question Answering Benchmark and an Efficient Network for Video Reasoning Over Traffic Events. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9878–9888, June 2021
2021
-
[40]
Talk2Car: Taking control of your self-driving car
Thierry Deruyttere, Simon Vandenhende, Dusan Grujicic, Luc Van Gool, and Marie-Francine Moens. Talk2Car: Taking control of your self-driving car. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors,Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Lang...
2019
-
[41]
Association for Computational Linguistics
-
[42]
Lingoqa: Visual question answering for autonomous driving
Ana-Maria Marcu, Long Chen, Jan Hünermann, Alice Karnsund, Benoit Hanotte, Prajwal Chidananda, Saurabh Nair, Vijay Badrinarayanan, Alex Kendall, Jamie Shotton, et al. Lingoqa: Visual question answering for autonomous driving. InEuropean Conference on Computer Vision, pages 252–269. Springer, 2024
2024
-
[43]
Holistic autonomous driving understanding by bird’s-eye-view injected multi-modal large models
Xinpeng Ding, Jianhua Han, Hang Xu, Xiaodan Liang, Wei Zhang, and Xiaomeng Li. Holistic autonomous driving understanding by bird’s-eye-view injected multi-modal large models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13668–13677, 2024
2024
-
[44]
Senna: Bridging Large Vision-Language Models and End-to-End Autonomous Driving
Bo Jiang, Shaoyu Chen, Bencheng Liao, Xingyu Zhang, Wei Yin, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Wang. Senna: Bridging large vision-language models and end-to-end autonomous driving.arXiv preprint arXiv:2410.22313, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Omnidrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning
Shihao Wang, Zhiding Yu, Xiaohui Jiang, Shiyi Lan, Min Shi, Nadine Chang, Jan Kautz, Ying Li, and Jose M Alvarez. Omnidrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22442–22452, 2025
2025
-
[46]
MOVE FORWARD,
Zhenhua Xu, Yujia Zhang, Enze Xie, Zhen Zhao, Yong Guo, Kwan-Yee K Wong, Zhenguo Li, and Hengshuang Zhao. Drivegpt4: Interpretable end-to-end autonomous driving via large language model.IEEE Robotics and Automation Letters, 9(10):8186–8193, 2024. 12 Appendix In the Appendix, we provide more comprehensive algorithmic details and experimental results. Speci...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.