CosFly: Plan in the Matrix, Fly in the World
Pith reviewed 2026-05-20 09:01 UTC · model grok-4.3
The pith
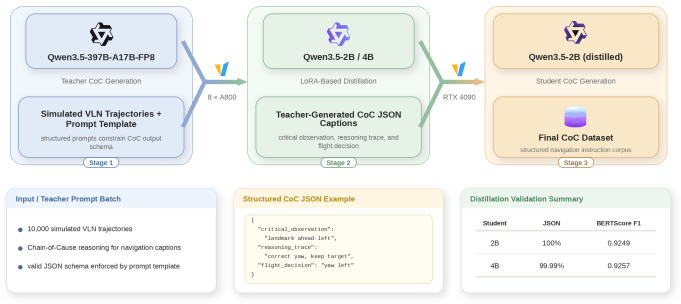
CosFly provides a seven-step pipeline that converts 3D environments into planned UAV trajectories and synchronized multi-modal sensor data for aerial tracking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the modular seven-step pipeline, built on the CARLA simulator, converts 3D map data into structured obstacle representations suitable for trajectory planning, then projects the resulting paths into multi-modal sensor outputs that include configurable camera intrinsics, enabling the creation of large-scale datasets that pair navigation instructions with precise pose information for aerial tracking research.
What carries the argument
The box-structured planning and multimodal simulation pipeline that simplifies 3D worlds into grids for trajectory optimization and renders the results as synchronized multi-modal observations with 6-DOF annotations.
If this is right
- Enables large-scale training of dynamic target tracking algorithms using paired multi-modal sensor data and natural language instructions.
- Supports UAV navigation research through complete 6-DOF pose annotations across hundreds of trajectories.
- Allows direct comparison of two-stage candidate generation versus single-objective gradient-based planning within the same simulated environments.
- Provides a foundation for multi-modal perception studies that combine RGB, depth, and semantic segmentation outputs.
- Scales aerial-ground collaborative experiments by covering diverse scene types without repeated real-world data gathering.
Where Pith is reading between the lines
- If the simulated data transfers well, the approach could lower the barrier to entry for researchers who lack access to physical drone fleets.
- The fixed-FOV zoom feature could be used to isolate how changes in camera focal length affect tracking robustness across different distances.
- Extending the pipeline to include modeled sensor noise or wind disturbances would test robustness claims more directly.
- Integration with other simulators might allow systematic study of how environment variety influences learned tracking policies.
Load-bearing premise
That trajectories planned and sensor data rendered inside the CARLA simulator will prove representative enough of real-world UAV dynamics and perception to train systems that transfer effectively to physical platforms.
What would settle it
A side-by-side test in which a model trained exclusively on the CosFly-Track dataset shows substantially lower tracking accuracy when flown on a physical drone in environments matched to the simulated ones.
Figures















































read the original abstract
We present CosFly, a box-structured planning and multimodal simulation pipeline for aerial tracking, together with CosFly-Track, a large-scale UAV dataset for dynamic target tracking across diverse environments including urban centers, highways, rural landscapes, forests, and coastal towns. In our current implementation on CARLA, CosFly provides a modular 7-step construction pipeline that converts complex 3D worlds into structured obstacle representations for planning, then projects the resulting trajectories back into multi-modal sensor data -- including RGB images, high-precision depth maps, and semantic segmentation masks -- paired with natural language navigation instructions. A key feature is the support for configurable fixed-FOV zoom levels (one FOV setting drawn per trajectory and held constant throughout), enabling simulation of various focal lengths through camera-intrinsic adjustments. The pipeline covers the complete workflow from 3D map export through grid simplification, pedestrian and drone trajectory planning, multi-modal rendering with 6-DOF pose annotations, quality inspection, and teacher-student caption generation. We analyze two trajectory-planning paradigms for aerial target tracking: a conventional two-stage pipeline with front-end candidate generation and backend refinement, and a direct gradient-based formulation that optimizes multiple tracking constraints in a single objective. The public CosFly-Track release contains 250 validated trajectories and approximately 100,000 rendered images with complete 6-DOF drone pose annotations (position x, y, z and orientation yaw, pitch, roll). Together, the pipeline and dataset establish a scalable foundation for aerial-ground collaborative research, supporting dynamic target tracking, UAV navigation, and multi-modal perception across diverse environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CosFly, a modular 7-step CARLA-based pipeline that converts 3D worlds into structured obstacle grids for planning, generates trajectories via either a two-stage or gradient-based optimizer, and renders multi-modal outputs (RGB, depth, segmentation) with 6-DOF pose annotations and natural-language instructions. It releases the CosFly-Track dataset of 250 validated trajectories and ~100k images spanning urban, highway, rural, forest, and coastal environments, with configurable fixed-FOV camera settings.
Significance. If the simulated trajectories and sensor renders prove representative, the pipeline and dataset would supply a useful, scalable resource for training models in dynamic target tracking, UAV navigation, and multi-modal aerial-ground perception. The explicit release of 6-DOF annotations, multi-modal renders, and two distinct planning formulations is a concrete strength that could accelerate reproducible research in the area.
major comments (2)
- [Abstract] Abstract: the central claim that the pipeline and dataset 'establish a scalable foundation for aerial-ground collaborative research, supporting dynamic target tracking, UAV navigation, and multi-modal perception' is not accompanied by any quantitative validation, error analysis, success rates, or baseline comparisons, leaving the effectiveness of both planning paradigms and the sim-to-real utility untested.
- [Abstract] Abstract: the assumption that CARLA-generated obstacle grids, gradient-based planners, and fixed-FOV projections produce statistics representative of physical UAV aerodynamics, wind effects, motion blur, and depth noise is load-bearing for all real-world claims, yet no quantitative comparison to real drone logs or hardware sensor characteristics is reported.
minor comments (1)
- [Abstract] Abstract: specify the exact criteria and quantitative thresholds used during the 'quality inspection' step of the 7-step pipeline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below, clarifying the scope of the contribution as a simulation pipeline and dataset release while committing to revisions that better align the abstract and discussion with the manuscript content.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the pipeline and dataset 'establish a scalable foundation for aerial-ground collaborative research, supporting dynamic target tracking, UAV navigation, and multi-modal perception' is not accompanied by any quantitative validation, error analysis, success rates, or baseline comparisons, leaving the effectiveness of both planning paradigms and the sim-to-real utility untested.
Authors: We agree that the abstract phrasing overstates the validated scope. The manuscript centers on the modular 7-step CARLA pipeline, the two planning formulations (two-stage and gradient-based), and the release of the CosFly-Track dataset with 250 trajectories and ~100k multi-modal images. No quantitative benchmarks, success rates, or baseline comparisons appear because the work is positioned as a resource for the community rather than an evaluated method. In revision we will rewrite the abstract to describe the pipeline and dataset as a scalable simulation foundation without claiming untested effectiveness for real-world tasks, and we will expand the validation section with qualitative trajectory inspection results and any internal consistency checks performed during dataset construction. revision: yes
-
Referee: [Abstract] Abstract: the assumption that CARLA-generated obstacle grids, gradient-based planners, and fixed-FOV projections produce statistics representative of physical UAV aerodynamics, wind effects, motion blur, and depth noise is load-bearing for all real-world claims, yet no quantitative comparison to real drone logs or hardware sensor characteristics is reported.
Authors: The manuscript does not assert that the CARLA outputs are statistically representative of physical UAV dynamics or sensor noise; all experiments remain inside the simulator. We will revise the abstract to remove any implication of direct real-world transfer and add an explicit limitations paragraph that states the absence of paired real-drone logs, the lack of wind or motion-blur modeling, and the fixed-FOV simplification. This will make the sim-to-real gap transparent to readers. revision: yes
Circularity Check
No circularity: pipeline and dataset construction are self-contained descriptions
full rationale
The paper describes a 7-step CARLA-based construction pipeline that converts 3D worlds into obstacle grids, plans trajectories (two-stage or gradient-based), renders multi-modal sensor data with 6-DOF poses, and generates captions. No equations, fitted parameters, predictions, or first-principles derivations are presented that reduce to the inputs by construction. The central claim is that the released CosFly-Track dataset (250 trajectories, ~100k images) supports UAV research; this is a factual statement about the artifact, not a result forced by self-definition or self-citation. No load-bearing uniqueness theorems or ansatzes appear. The work is a systems contribution whose validity rests on external validation against real UAV data, not internal reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CARLA simulator accurately models real-world physics, sensor behavior, and diverse environments including urban, rural, and natural settings
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We analyze two trajectory-planning paradigms... direct gradient-based formulation that optimizes multiple tracking constraints in a single objective... MuCO jointly adjusts every interior waypoint by finite-difference gradient descent
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
visibility-aware Track A* frontend on a 4D spatio-temporal voxel grid... five-ray visibility test
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
CosFly-Track: A Large-Scale Multi-Modal Dataset for UAV Visual Tracking via Multi-Constraint Trajectory Optimization
CosFlyTrack supplies 2.4 million timesteps of aligned RGB, depth, segmentation, pose, target state, and bilingual instructions from expert UAV trajectories, with experiments showing 53-69 point gains in SR@1m after fi...
-
CosFly-Track: A Large-Scale Multi-Modal Dataset for UAV Visual Tracking via Multi-Constraint Trajectory Optimization
CosFlyTrack provides 12,000 expert UAV trajectories with aligned RGB, depth, segmentation, pose, target state, and bilingual instructions to train visual tracking agents, yielding 53-69 point gains in success rate aft...
Reference graph
Works this paper leans on
-
[1]
Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sünderhauf, Ian Reid, Stephen Gould, and Anton van den Hengel. Vision-and-language navigation: Inter- preting visually-grounded navigation instructions in real environments. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 3674– 3683, 2018
work page 2018
-
[2]
D. J. Butler, J. Wulff, G. B. Stanley, and M. J. Black. A naturalistic open source movie for optical flow evaluation. In European Conference on Computer Vision (ECCV) , Part IV , LNCS 7577, pages 611–625, 2012
work page 2012
-
[3]
A class of local interpolating splines
Edwin Catmull and Raphael Rom. A class of local interpolating splines. In Robert E. Barn- hill and Richard F. Riesenfeld, editors, Computer Aided Geometric Design , pages 317–326. Academic Press, 1974
work page 1974
-
[4]
Track A*: Fast Visibility-Aware Trajectory Planning for Active Target Tracking
Hanxuan Chen, Kangli Wang, and Ji Pei. Track a*: Fast visibility-aware trajectory planning for active target tracking. arXiv preprint arXiv:2605.05338, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Vision-and-Language Navigation for UAVs: Progress, Challenges, and a Research Roadmap
Hanxuan Chen, Jie Zheng, Siqi Y ang, Tianle Zeng, Siwei Feng, Songsheng Cheng, Ruilong Ren, Hanzhong Guo, Shuai Yuan, Xiangyue Wang, and others. Vision-and-language navigation for UA Vs: Progress, challenges, and a research roadmap. arXiv preprint arXiv:2604.13654, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Video depth anything: Consistent depth estimation for super-long videos
Sili Chen, Lihe Y ang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Video depth anything: Consistent depth estimation for super-long videos. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2025
work page 2025
-
[7]
Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner
Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. ScanNet: Richly-annotated 3D reconstructions of indoor scenes. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages 2432–2443, 2017
work page 2017
- [8]
-
[9]
Carla: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio López, and Vladlen Koltun. Carla: An open urban driving simulator. In Proceedings of the 1st Annual Conference on Robot Learn- ing (CoRL) , volume 78 of Proceedings of Machine Learning Research , pages 1–16. PMLR, 2017. 24
work page 2017
-
[10]
David H. Douglas and Thomas K. Peucker. Algorithms for the reduction of the number of points required to represent a digitized line or its caricature. Cartographica: The International Journal for Geographic Information and Geovisualization , 10(2):112–122, 1973
work page 1973
-
[11]
The unmanned aerial vehicle benchmark: Object detection and tracking
Dawei Du, Yuankai Qi, Hongyang Yu, Yifan Y ang, Kaiwen Duan, Guorong Li, Weigang Zhang, Qingming Huang, and Qi Tian. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), pages 370– 386, 2018
work page 2018
-
[12]
Openfly: A comprehensive platform for aerial vision-language navigation
Yunpeng Gao, Chenhui Li, Zhongrui Y ou, Junli Liu, Zhen Li, Pengan Chen, Qizhi Chen, Zhong- han Tang, Liansheng Wang, Penghui Y ang, et al. Openfly: A comprehensive platform for aerial vision-language navigation. In The Fourteenth International Conference on Learning Represen- tations, 2026
work page 2026
-
[13]
Openfly: A comprehensive platform for aerial vision-language navigation, 2026
Yunpeng Gao, Chenhui Li, Zhongrui Y ou, Junli Liu, Zhen Li, Pengan Chen, Qizhi Chen, Zhong- han Tang, Liansheng Wang, Penghui Y ang, Yiwen Tang, Yuhang Tang, Shuai Liang, Songyi Zhu, Ziqin Xiong, Yifei Su, Xinyi Y e, Jianan Li, Y an Ding, Dong Wang, Xuelong Li, Zhigang Wang, and Bin Zhao. Openfly: A comprehensive platform for aerial vision-language naviga...
work page 2026
-
[14]
Are we ready for autonomous driving? The KITTI vision benchmark suite
Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? The KITTI vision benchmark suite. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3354–3361, 2012
work page 2012
-
[15]
Jing Gu, Manolis Savva, and Angel X. Gao. Vision-and-language navigation: A survey of tasks, methods, and future directions. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), 2022
work page 2022
-
[17]
Peter E. Hart, Nils J. Nilsson, and Bertram Raphael. A formal basis for the heuristic deter- mination of minimum cost paths. IEEE Transactions on Systems Science and Cybernetics , 4(2):100–107, 1968
work page 1968
-
[18]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[19]
Hu, Y elong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Y elong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In In- ternational Conference on Learning Representations (ICLR) , 2022
work page 2022
-
[20]
DepthCrafter: Generating consistent long depth sequences for open-world videos
Wenbo Hu, Xiangjun Gao, Xiaoyu Li, Sijie Zhao, Xiaodong Cun, Y ong Zhang, Long Quan, and Ying Shan. DepthCrafter: Generating consistent long depth sequences for open-world videos. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2025
work page 2025
-
[21]
Sampling-based algorithms for optimal motion planning
Sertac Karaman and Emilio Frazzoli. Sampling-based algorithms for optimal motion planning. The International Journal of Robotics Research , 30(7):846–894, 2011
work page 2011
-
[22]
Kavraki, Petr Svestka, Jean-Claude Latombe, and Mark H
Lydia E. Kavraki, Petr Svestka, Jean-Claude Latombe, and Mark H. Overmars. Probabilistic roadmaps for path planning in high-dimensional configuration spaces. IEEE Transactions on Robotics and Automation, 12(4):566–580, 1996
work page 1996
-
[23]
Repurposing diffusion-based image generators for monocular depth estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Metzger, Rodrigo Caye Daudt, and Kon- rad Schindler. Repurposing diffusion-based image generators for monocular depth estimation. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2024
work page 2024
-
[24]
Real-time obstacle avoidance for manipulators and mobile robots
Oussama Khatib. Real-time obstacle avoidance for manipulators and mobile robots. The Inter- national Journal of Robotics Research , 5(1):90–98, 1986
work page 1986
-
[25]
AI2-THOR: An Interactive 3D Environment for Visual AI
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Roberto Gordon, Chenxia Zhu, Ali Farhadi, Arsalan Mousavian, Ram Vedantam, and Aniruddha Kembhavi. AI2-THOR: An interactive 3d environment for visual AI. arXiv preprint arXiv:1712.05474, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Model Predictive Control: Classical, Robust and Stochastic
Basil Kouvaritakis and Mark Cannon. Model Predictive Control: Classical, Robust and Stochastic. Advanced Textbooks in Control and Signal Processing. Springer, 2016. 25
work page 2016
-
[27]
Emre Koyuncu and Gokhan Inalhan. A probabilistic B-spline motion planning algorithm for unmanned helicopters flying in dense 3D environments. In 2008 IEEE/RSJ International Con- ference on Intelligent Robots and Systems, pages 815–821. IEEE, 2008
work page 2008
-
[28]
Konstantinos J. Kyriakopoulos and George N. Saridis. Minimum jerk path generation. In Proceedings. 1988 IEEE International Conference on Robotics and Automation , pages 364–
work page 1988
-
[29]
IEEE Computer Society Press, 1988
work page 1988
-
[30]
Steven M. LaValle. Rapidly-exploring random trees: A new tool for path planning. Technical Report TR 98-11, Computer Science Department, Iowa State University, 1998
work page 1998
-
[31]
CityNav: A large-scale dataset for real-world aerial navigation
Jungdae Lee, Taiki Miyanishi, Shuhei Kurita, Koya Sakamoto, Daichi Azuma, Yutaka Mat- suo, and Nakamasa Inoue. CityNav: A large-scale dataset for real-world aerial navigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , 2025
work page 2025
-
[32]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping language- image pre-training with frozen image encoders and large language models. In Proceedings of the 40th International Conference on Machine Learning (ICML) , volume 202 of Proceedings of Machine Learning Research. PMLR, 2023
work page 2023
-
[33]
MatrixCity: A large-scale city dataset for city-scale neural rendering and beyond
Yixuan Li, Lihan Jiang, Linning Xu, Yuanbo Xiangli, Zhenzhi Wang, Dahua Lin, and Bo Dai. MatrixCity: A large-scale city dataset for city-scale neural rendering and beyond. In Interna- tional Conference on Computer Vision (ICCV) , 2023
work page 2023
-
[34]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Y ong Jae Lee. Visual instruction tuning. In Advances in Neural Information Processing Systems (NeurIPS), volume 36, 2023. Oral Presen- tation
work page 2023
-
[35]
Aerialvln: Vision-and-language navigation for uavs
Shubo Liu, Hongsheng Zhang, Yuankai Qi, Peng Wang, Y aning Zhang, and Qi Wu. Aerialvln: Vision-and-language navigation for uavs. In Proceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 15384–15394, 2023
work page 2023
-
[36]
Aerialvln: Vision-and-language navigation for uavs, 2023
Shubo Liu, Hongsheng Zhang, Yuankai Qi, Peng Wang, Y aning Zhang, and Qi Wu. Aerialvln: Vision-and-language navigation for uavs, 2023
work page 2023
-
[37]
Tomás Lozano-Pérez and Michael A. Wesley. An algorithm for planning collision-free paths among polyhedral obstacles. Communications of the ACM, 22(10):560–570, 1979
work page 1979
-
[38]
Spring: A high-resolution high-detail dataset and benchmark for scene flow, optical flow and stereo
Lukas Mehl, Jenny Schmalfuss, Azin Jahedi, Y aroslava Nalivayko, and Andrés Bruhn. Spring: A high-resolution high-detail dataset and benchmark for scene flow, optical flow and stereo. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2023
work page 2023
-
[39]
A benchmark and simulator for UA V track- ing
Matthias Mueller, Neil Smith, and Bernard Ghanem. A benchmark and simulator for UA V track- ing. In European Conference on Computer Vision (ECCV) , pages 445–461. Springer, 2016
work page 2016
-
[40]
BuckTales: A multi-UA V dataset for multi-object tracking and re-identification of wild antelopes
Hemal Naik, Junran Y ang, Dipin Das, Margaret C Crofoot, Akanksha Rathore, and Vivek Hari Sridhar. BuckTales: A multi-UA V dataset for multi-object tracking and re-identification of wild antelopes. In Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2024
work page 2024
-
[41]
OpenAI. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Heuristic search viewed as path finding in a graph
Ira Pohl. Heuristic search viewed as path finding in a graph. Artificial Intelligence, 1(3–4):193– 204, 1970
work page 1970
-
[43]
Aria synthetic environments dataset
Project Aria. Aria synthetic environments dataset. https://www.projectaria.com/ datasets/ase/, 2024
work page 2024
-
[44]
MUST: The first dataset and unified framework for multispectral UA V single object tracking
Haolin Qin, Tingfa Xu, Tianhao Li, Zhenxiang Chen, Tao Feng, and Jianan Li. MUST: The first dataset and unified framework for multispectral UA V single object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2025
work page 2025
-
[45]
Elastic bands: connecting path planning and control
Sean Quinlan and Oussama Khatib. Elastic bands: connecting path planning and control. In Pro- ceedings IEEE International Conference on Robotics and Automation , pages 802–807. IEEE Computer Society Press, 1993
work page 1993
-
[46]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Pro- ceedings of the 38th International Conference on Machine Learning (ICML) , volume 139 of P...
work page 2021
-
[47]
Andrew Bagnell, and Siddhartha Srinivasa
Nathan Ratliff, Matt Zucker, J. Andrew Bagnell, and Siddhartha Srinivasa. CHOMP: Gradient optimization techniques for efficient motion planning. In 2009 IEEE International Conference on Robotics and Automation , pages 489–494. IEEE, 2009
work page 2009
-
[48]
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M. Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. In International Conference on Computer Vi- sion (ICCV), pages 10912–10922, 2021
work page 2021
-
[49]
Habitat: A platform for embodied AI research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, and Dhruv Batra. Habitat: A platform for embodied AI research. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages 9339–9347, 2019
work page 2019
-
[50]
High-resolution stereo datasets with subpixel-accurate ground truth
Daniel Scharstein, Heiko Hirschmüller, Y ork Kitajima, Greg Krathwohl, Nera Nešić, Xi Wang, and Porter Westling. High-resolution stereo datasets with subpixel-accurate ground truth. In German Conference on Pattern Recognition (GCPR) , pages 31–42, 2014
work page 2014
-
[51]
Motion planning with sequential convex op- timization and convex collision checking
John Schulman, Y an Duan, Jonathan Ho, Alex Lee, Ibrahim Awwal, Henry Bradlow, Jia Pan, Sachin Patil, Ken Goldberg, and Pieter Abbeel. Motion planning with sequential convex op- timization and convex collision checking. The International Journal of Robotics Research , 33(9):1251–1270, 2014
work page 2014
-
[52]
Airsim: High-fidelity visual and physical simulation for autonomous vehicles
Shital Shah, Debadeepta Dey, Chris Lovett, and Ashish Kapoor. Airsim: High-fidelity visual and physical simulation for autonomous vehicles. In Field and Service Robotics, Springer Pro- ceedings in Advanced Robotics, pages 621–635. Springer, 2018
work page 2018
-
[53]
Indoor segmentation and support inference from RGBD images
Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. Indoor segmentation and support inference from RGBD images. In European Conference on Computer Vision (ECCV) , pages 746–760, 2012
work page 2012
-
[54]
Griffin: Aerial-ground cooperative detection and tracking dataset and benchmark, 2025
Jiahao Wang, Xiangyu Cao, Jiaru Zhong, Yuner Zhang, Zeyu Han, Haibao Yu, Chuang Zhang, Lei He, Shaobing Xu, and Jianqiang Wang. Griffin: Aerial-ground cooperative detection and tracking dataset and benchmark, 2025
work page 2025
-
[55]
UA VScenes: A multi-modal dataset for UA Vs
Sijie Wang, Siqi Li, Y awei Zhang, Shangshu Yu, Shenghai Yuan, Rui She, Quanjiang Guo, JinXuan Zheng, Ong Kang Howe, Leonrich Chandra, et al. UA VScenes: A multi-modal dataset for UA Vs. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
work page 2025
-
[56]
TartanAir: A dataset to push the limits of visual SLAM
Wenshan Wang, Delong Zhu, Xiangwei Wang, Y aoyu Hu, Yuheng Qiu, Chen Wang, Y afei Hu, Ashish Kapoor, and Sebastian Scherer. TartanAir: A dataset to push the limits of visual SLAM. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages 4909– 4916, 2020
work page 2020
-
[57]
Towards realistic UA V vision-language navigation: Platform, benchmark, and methodology
Xiangyu Wang, Donglin Y ang, Ziqin Wang, Hohin Kwan, Jinyu Chen, Wenjun Wu, Hong- sheng Li, Yue Liao, and Si Liu. Towards realistic UA V vision-language navigation: Platform, benchmark, and methodology. In Proceedings of the International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[58]
Y an Wang, Wenjie Luo, Junjie Bai, Yulong Cao, Tong Che, Ke Chen, Yuxiao Chen, Jenna Dia- mond, Yifan Ding, Wenhao Ding, et al. Alpamayo-r1: Bridging reasoning and action prediction for generalizable autonomous driving in the long tail. arXiv preprint arXiv:2511.00088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Detection, tracking, and counting meets drones in crowds: A benchmark
Longyin Wen, Dawei Du, Pengfei Zhu, Xiao Bian, Haibin Ling, Qinghua Hu, and Tao Mei. Detection, tracking, and counting meets drones in crowds: A benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 7780– 7789, 2021
work page 2021
-
[60]
Zamir, Zhi- Y ang He, Alexander Sax, Jitendra Malik, and Silvio Savarese
Fei Xia, Amir R. Zamir, Zhi- Y ang He, Alexander Sax, Jitendra Malik, and Silvio Savarese. Gibson env: Real-world perception for embodied agents. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 9068–9079, 2018. Spotlight Oral
work page 2018
-
[61]
RGBD objects in the wild: Scaling real- world 3D object learning from RGB-D videos
Hongchi Xia, Y ang Fu, Sifei Liu, and Xiaolong Wang. RGBD objects in the wild: Scaling real- world 3D object learning from RGB-D videos. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 27
work page 2024
-
[62]
Lihe Y ang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Heng- shuang Zhao. Depth anything V2. In Advances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[63]
ScanNet++: A high- fidelity dataset of 3D indoor scenes
Chandan Y eshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. ScanNet++: A high- fidelity dataset of 3D indoor scenes. In International Conference on Computer Vision (ICCV) , 2023
work page 2023
-
[64]
Tianle Zeng, Hanxuan Chen, Y anci Wen, and Hong Zhang. CARLA-Air: Fly drones inside a CARLA world–a unified infrastructure for air-ground embodied intelligence. arXiv preprint arXiv:2603.28032, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[65]
Tianle Zeng, Xinrong Gu, Feifan Y an, Meixi He, and Dengke He. Y oco: Y ou only calibrate once for accurate extrinsic parameter in lidar-camera systems.Measurement Science and Technology, 36(7):075009, 2025
work page 2025
-
[66]
EZREAL: Enhancing zero-shot outdoor robot navigation toward distant targets under varying visibility
Tianle Zeng, Jianwei Peng, Hanjing Y e, Guangcheng Chen, Senzi Luo, and Hong Zhang. EZREAL: Enhancing zero-shot outdoor robot navigation toward distant targets under varying visibility. arXiv preprint arXiv:2509.13720, 2025
-
[67]
Chunhui Zhang et al. WebUA V-3M: A benchmark for unveiling the power of million-scale deep UA V tracking.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(12):14538– 14556, 2023
work page 2023
-
[68]
Uav-track vla: Embodied aerial tracking via vision-language- action models, 2026
Qiyao Zhang, Shuhua Zheng, Jianli Sun, Chengxiang Li, Xianke Wu, Zihan Song, Zhiyong Cui, Yisheng Lv, and Y onglin Tian. Uav-track vla: Embodied aerial tracking via vision-language- action models, 2026
work page 2026
-
[69]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Y oav Artzi. BERTScore: Evaluating text generation with BERT. In Proceedings of the 8th International Conference on Learning Representations (ICLR), 2020
work page 2020
-
[70]
M3OT: A multi-drone multi-modality dataset for multi-object tracking
Xin Zhang et al. M3OT: A multi-drone multi-modality dataset for multi-object tracking. Sci- entific Data, 12, 2025
work page 2025
-
[71]
Anti-UA V challenge 2023: Methods and results
Jian Zhao et al. Anti-UA V challenge 2023: Methods and results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , 2023
work page 2023
-
[72]
Drone-person tracking in uniform appearance crowd: A new dataset
Jianwei Zhao et al. Drone-person tracking in uniform appearance crowd: A new dataset. Sci- entific Data, 10, 2023
work page 2023
-
[73]
Byrd, Peihuang Lu, and Jorge Nocedal
Ciyou Zhu, Richard H. Byrd, Peihuang Lu, and Jorge Nocedal. Algorithm 778: L-BFGS- B: Fortran subroutines for large-scale bound-constrained optimization. ACM Transactions on Mathematical Software, 23(4):550–560, 1997
work page 1997
-
[74]
Detection and tracking meet drones challenge, 2021
Pengfei Zhu, Longyin Wen, Dawei Du, Xiao Bian, Heng Fan, Qinghua Hu, and Haibin Ling. Detection and tracking meet drones challenge, 2021
work page 2021
-
[75]
Pengfei Zhu, Longyin Wen, Dawei Du, Xiao Bian, Haibin Ling, Qinghua Hu, Jie Nie, Chengjie Chen, Y afei Wang, Xin Zhang, Xinyao Lyu, Jianhua Liu, Guan Zhou, Yue Kang, Heng Liu, Jiayuan Cheng, and Tao Mei. Detection and tracking meet drones challenge.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(11):7380–7399, 2021
work page 2021
-
[76]
Longkun Zou, Jiale Wang, Rongqin Liang, Hai Wu, Ke Chen, and Y aowei Wang. UA V-MM3D: A large-scale synthetic benchmark for 3d perception of unmanned aerial vehicles with multi- modal data. arXiv preprint arXiv:2511.22404, 2025. 28 A Justification for 32-bit Float Depth Map Storage This section provides a comprehensive quantitative and qualitative analysi...
-
[77]
TA* + Smooth release output: included; primary method
-
[78]
MuCO release output: included; primary one-shot global-planning baseline
-
[79]
RRT*, PRM, B-spline PRM, elastic band, minimum jerk: included as Python reference context
-
[80]
3D A*, Weighted A*, Theta*, Visibility-A*: included as search-family controls
-
[81]
Potential field, CHOMP-lite, L-BFGS-B TrajOpt: included as local-optimization controls
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.