AQuaUI: Visual Token Reduction for GUI Agents with Adaptive Quadtrees
Pith reviewed 2026-05-20 06:16 UTC · model grok-4.3
The pith
AQuaUI merges tokens inside adaptive quadtree leaves on GUI screenshots to cut visual input size while keeping nearly all agent performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
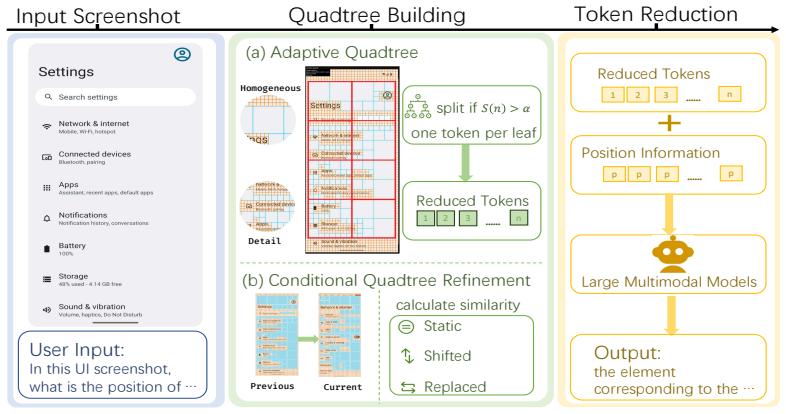
AQuaUI partitions each screenshot with an adaptive quadtree and retains a single representative merged token per leaf, while a conditional refinement step uses the prior quadtree to stabilize the partition across consecutive frames; this produces up to 29.52 percent fewer visual tokens and 13.22 percent speedup on GUI-Owl-1.5-32B-Instruct while preserving 99.06 percent of the original grounding and navigation accuracy.
What carries the argument
Adaptive quadtree that recursively splits the screenshot according to local homogeneity and collapses each final leaf to one merged token, with position information preserved and a conditional variant that references the preceding frame’s partition.
If this is right
- Existing GUI agent models obtain better accuracy-versus-speed trade-offs on grounding and navigation benchmarks without retraining.
- Token usage falls by up to 29.52 percent and inference speeds up by up to 13.22 percent on models such as GUI-Owl-1.5-32B-Instruct.
- Position encodings remain consistent because retained tokens keep their original spatial coordinates through the entire pipeline.
- Temporal stability improves across multi-step interactions when the conditional quadtree reuses structure from prior frames.
Where Pith is reading between the lines
- The same quadtree partitioning idea could be tested on other visual-agent domains that also show large homogeneous regions, such as robotic camera feeds or document interfaces.
- Varying the homogeneity threshold or leaf-size limit according to the current task might yield further efficiency gains beyond the fixed settings reported.
- The method’s reliance on spatial redundancy suggests it could combine with existing attention-based compressors for hybrid token budgets.
Load-bearing premise
A single representative token per quadtree leaf still contains every piece of information the downstream agent needs to make correct grounding and navigation decisions.
What would settle it
Measure grounding or navigation accuracy on a standard benchmark set of screenshots that contain critical small text or icons inside large visually uniform panels; a drop below roughly 99 percent of full-token performance would indicate the representative-token step discards necessary detail.
Figures


read the original abstract
Large Multimodal Models (LMMs) have recently emerged as promising backbones for GUI-agent models, where high-resolution GUI screenshots are introduced to the prompts at each iteration step. However, these screenshots exhibit highly non-uniform spatial information density: large regions may carry little information and are visually homogeneous, while key text and icons may require high visual fidelity. Existing approaches to this problem either require additional training or rely on attention-based token compression, ignoring the structured layout and spatial redundancy of GUI screenshots. To fill the gap, this paper proposes AquaUI, a training-free inference-time token reduction method for GUI agent models that utilizes the non-uniform information density in screenshots. AQuaUI constructs an adaptive quadtree on each screenshot input and keeps one representative merged token per leaf of the quadtree. AQuaUI preserves the spatial positions of retained tokens throughout the pipeline to ensure that all position-encoding stages remain consistent. To further improve temporal consistency across multi-step GUI interactions, we propose a conditional quadtree algorithm that leverages the continuity between consecutive screenshots within a single request. Specifically, it refines the current quadtree using previous quadtrees as references, helping preserve fine-grained regions across static or mildly shifted GUI states. We implement AQuaUI on state-of-the-art GUI agent models and conduct experiments on standard grounding and navigational benchmarks. AQuaUI consistently shows improved accuracy-efficiency trade-offs over prior baselines. Notably, on GUI-Owl-1.5-32B-Instruct, AQuaUI achieves up to 13.22% speedup and 29.52% fewer visual tokens while retaining 99.06% of full-token performance, suggesting that the spatial redundancy of GUI screenshots can be exploited at inference without retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AQuaUI, a training-free inference-time token reduction method for GUI agent models. It constructs an adaptive quadtree on each GUI screenshot to exploit non-uniform spatial information density, retaining one representative merged token per quadtree leaf while preserving spatial positions. A conditional quadtree variant leverages continuity between consecutive screenshots for temporal consistency in multi-step interactions. Experiments on standard grounding and navigational benchmarks report improved accuracy-efficiency trade-offs, including up to 13.22% speedup and 29.52% fewer visual tokens while retaining 99.06% of full-token performance on GUI-Owl-1.5-32B-Instruct.
Significance. If the results hold, this work offers a practical contribution by enabling efficient inference for high-resolution GUI agents without retraining or attention-based compression. The training-free design, explicit preservation of spatial positions, and conditional quadtree for temporal consistency are clear strengths that align with the structured redundancy in GUI screenshots. The approach could meaningfully advance deployment of LMM-based agents in resource-limited settings, provided the core merging assumption is substantiated.
major comments (2)
- [Abstract] Abstract: the reported performance numbers (13.22% speedup, 29.52% token reduction, 99.06% retention on GUI-Owl-1.5-32B-Instruct) are presented without error bars, ablation studies on quadtree depth or merging parameters, or any description of how the representative token is computed inside each leaf (mean, max-pool, or other). These omissions make the central efficiency claim difficult to evaluate or reproduce.
- [Token-merging step] Token-merging step (described in abstract): the assumption that one representative merged token per adaptive quadtree leaf preserves all task-relevant information for downstream grounding and navigation is stated but unsupported. No analysis is given of the splitting criterion (e.g., pixel variance or homogeneity) or its reliability for small but semantically critical elements such as 8-12 px icons or single-line text in dense toolbars.
minor comments (1)
- [Abstract] The abstract refers to 'standard grounding and navigational benchmarks' without naming them (e.g., ScreenSpot, AndroidControl); explicit citation would improve comparability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We have carefully considered each comment and revised the paper to improve clarity, reproducibility, and substantiation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported performance numbers (13.22% speedup, 29.52% token reduction, 99.06% retention on GUI-Owl-1.5-32B-Instruct) are presented without error bars, ablation studies on quadtree depth or merging parameters, or any description of how the representative token is computed inside each leaf (mean, max-pool, or other). These omissions make the central efficiency claim difficult to evaluate or reproduce.
Authors: We agree that these details are important for evaluation and reproducibility. In the revised manuscript, we describe the representative token computation as the mean pooling of the feature vectors within each quadtree leaf. We have added ablation studies varying the quadtree depth and merging parameters, with results reported in a new table in the experiments section. For error bars, as the quadtree construction is deterministic for a given image and threshold, we instead provide results across multiple benchmarks and models to demonstrate consistency. The abstract has been updated to mention these supporting analyses. revision: yes
-
Referee: [Token-merging step] Token-merging step (described in abstract): the assumption that one representative merged token per adaptive quadtree leaf preserves all task-relevant information for downstream grounding and navigation is stated but unsupported. No analysis is given of the splitting criterion (e.g., pixel variance or homogeneity) or its reliability for small but semantically critical elements such as 8-12 px icons or single-line text in dense toolbars.
Authors: We acknowledge the need for more explicit support of this assumption. We have added a detailed explanation of the splitting criterion in Section 3.2, which uses a homogeneity measure based on pixel variance to decide splits, ensuring that regions with text or icons are subdivided until they meet the homogeneity threshold or reach minimum size. To evaluate reliability for small elements, we include a new qualitative analysis with examples of dense toolbars, demonstrating that critical 8-12 px icons and text are preserved through adaptive splitting. The high retention rate of 99.06% on grounding tasks further substantiates that task-relevant information is maintained. We have expanded the discussion to address potential limitations in highly dense interfaces. revision: yes
Circularity Check
No significant circularity in AQuaUI derivation
full rationale
The paper describes AQuaUI as a training-free, inference-time procedural algorithm that builds an adaptive quadtree on GUI screenshots and retains one representative merged token per leaf while preserving positions. Performance results (e.g., 99.06% retention) are reported from empirical benchmarks on models like GUI-Owl-1.5-32B-Instruct rather than from any closed-form derivation or fitted parameters. No equations, self-definitional reductions, or load-bearing self-citations appear in the provided text that would make the claimed efficiency gains equivalent to the method's own inputs by construction. The approach is self-contained as an algorithmic exploitation of spatial redundancy.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GUI screenshots exhibit highly non-uniform spatial information density with large homogeneous regions
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AQuaUI constructs an adaptive quadtree on each screenshot input and keeps one representative merged token per leaf of the quadtree... splitting criterion s(n)=wn hn ·Var(grey(n))
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
conditional quadtree algorithm that leverages the continuity between consecutive screenshots
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Developing a computer use model, 2024
Anthropic. Developing a computer use model, 2024. URL https://www.anthropic.com/ news/developing-computer-use
work page 2024
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, et al. Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling.arXiv preprint arXiv:2406.02069, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Zefan Cai, Wen Xiao, Hanshi Sun, Cheng Luo, Yikai Zhang, Ke Wan, Yucheng Li, Yeyang Zhou, Li-Wen Chang, Jiuxiang Gu, et al. R-kv: Redundancy-aware kv cache compression for reasoning models.arXiv preprint arXiv:2505.24133, 2025
-
[5]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InEuropean Conference on Computer Vision, pages 19–35. Springer, 2024
work page 2024
-
[6]
Kyle R Chickering, Bangzheng Li, and Muhao Chen. Qlip: A dynamic quadtree vision prior enhances mllm performance without retraining.arXiv preprint arXiv:2505.23004, 2025
-
[7]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
work page 2022
-
[8]
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
work page 2023
-
[9]
Pact: Pruning and clustering-based token reduction for faster visual language models
Mohamed Dhouib, Davide Buscaldi, Sonia Vanier, and Aymen Shabou. Pact: Pruning and clustering-based token reduction for faster visual language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14582–14592, 2025
work page 2025
-
[10]
Kung-Hsiang Huang, Haoyi Qiu, Yutong Dai, Caiming Xiong, and Chien-Sheng Wu. Gui-kv: Ef- ficient gui agents via kv cache with spatio-temporal awareness.arXiv preprint arXiv:2510.00536, 2025
-
[11]
Gregory M. Hunter and Kenneth Steiglitz. Operations on images using quad trees.IEEE Transactions on Pattern Analysis and Machine Intelligence, PAMI-1(2):145–153, 1979. doi: 10.1109/TPAMI.1979.4766900
-
[12]
Yutao Jiang, Qiong Wu, Wenhao Lin, Wei Yu, and Yiyi Zhou. What kind of visual tokens do we need? training-free visual token pruning for multi-modal large language models from the perspective of graph. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 4075–4083, 2025
work page 2025
-
[13]
Screenspot-pro: Gui grounding for professional high-resolution computer use
Kaixin Li, Ziyang Meng, Hongzhan Lin, Ziyang Luo, Yuchen Tian, Jing Ma, Zhiyong Huang, and Tat-Seng Chua. Screenspot-pro: Gui grounding for professional high-resolution computer use. InProceedings of the 33rd ACM International Conference on Multimedia, pages 8778– 8786, 2025
work page 2025
-
[14]
Wei Li, William Bishop, Alice Li, Chris Rawles, Folawiyo Campbell-Ajala, Divya Tyamagundlu, and Oriana Riva. On the effects of data scale on ui control agents.Advances in Neural Information Processing Systems, 37:92130–92154, 2024
work page 2024
-
[15]
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation.Advances in Neural Information Processing Systems, 37:22947–22970, 2024. 10
work page 2024
-
[16]
Showui: One vision-language-action model for gui visual agent
Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Shiwei Wu, Zechen Bai, Stan Weix- ian Lei, Lijuan Wang, and Mike Zheng Shou. Showui: One vision-language-action model for gui visual agent. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19498–19508, 2025
work page 2025
-
[17]
Ui-voyager: A self-evolving gui agent learning via failed experience
Zichuan Lin, Feiyu Liu, Yijun Yang, Jiafei Lyu, Yiming Gao, Yicheng Liu, Zhicong Lu, Yangbin Yu, Mingyu Yang, Junyou Li, et al. Ui-voyager: A self-evolving gui agent learning via failed experience.arXiv preprint arXiv:2603.24533, 2026
-
[18]
Jizhihui Liu, Guangdao Zhu, and Feiyi Du. Hiprune: Training-free visual token pruning via hierarchical attention in vision-language models (student abstract). InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 41275–41277, 2026
work page 2026
-
[19]
Omniparser for pure vision based gui agent.arXiv preprint arXiv:2408.00203, 2024
Yadong Lu, Jianwei Yang, Yelong Shen, and Ahmed Awadallah. Omniparser for pure vision based gui agent.arXiv preprint arXiv:2408.00203, 2024
-
[20]
TriAttention: Efficient Long Reasoning with Trigonometric KV Compression
Weian Mao, Xi Lin, Wei Huang, Yuxin Xie, Tianfu Fu, Bohan Zhuang, Song Han, and Yukang Chen. Triattention: Efficient long reasoning with trigonometric kv compression.arXiv preprint arXiv:2604.04921, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Shravan Nayak, Xiangru Jian, Kevin Qinghong Lin, Juan A Rodriguez, Montek Kalsi, Rabiul Awal, Nicolas Chapados, M Tamer Özsu, Aishwarya Agrawal, David Vazquez, et al. Ui- vision: A desktop-centric gui benchmark for visual perception and interaction.arXiv preprint arXiv:2503.15661, 2025
-
[22]
Mingyu Ouyang, Kevin Qinghong Lin, Mike Zheng Shou, and Hwee Tou Ng. Focusui: Efficient ui grounding via position-preserving visual token selection.arXiv preprint arXiv:2601.03928, 2026
-
[23]
Tianfan Peng, Yuntao Du, Pengzhou Ji, Shijie Dong, Kailin Jiang, Mingchuan Ma, Yijun Tian, Jinhe Bi, Qian Li, Wei Du, et al. Can visual input be compressed? a visual token compression benchmark for large multimodal models.arXiv preprint arXiv:2511.02650, 2025
-
[24]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. Ui-tars: Pioneering automated gui interaction with native agents.arXiv preprint arXiv:2501.12326, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Mary- beth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, et al. Androidworld: A dynamic benchmarking environment for autonomous agents.arXiv preprint arXiv:2405.14573, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
ClawGUI: A Unified Framework for Training, Evaluating, and Deploying GUI Agents
Fei Tang, Zhiqiong Lu, Boxuan Zhang, Weiming Lu, Jun Xiao, Yueting Zhuang, and Yongliang Shen. Clawgui: A unified framework for training, evaluating, and deploying gui agents.arXiv preprint arXiv:2604.11784, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception
Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. Mobile-agent: Autonomous multi-modal mobile device agent with visual perception. arXiv preprint arXiv:2401.16158, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Xuehui Wang, Zhenyu Wu, JingJing Xie, Zichen Ding, Bowen Yang, Zehao Li, Zhaoyang Liu, Qingyun Li, Xuan Dong, Zhe Chen, et al. Mmbench-gui: Hierarchical multi-platform evaluation framework for gui agents.arXiv preprint arXiv:2507.19478, 2025
-
[30]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, et al. Os-atlas: A foundation action model for generalist gui agents.arXiv preprint arXiv:2410.23218, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
work page 2024
-
[32]
Haiyang Xu, Xi Zhang, Haowei Liu, Junyang Wang, Zhaozai Zhu, Shengjie Zhou, Xuhao Hu, Feiyu Gao, Junjie Cao, Zihua Wang, et al. Mobile-agent-v3. 5: Multi-platform fundamental gui agents.arXiv preprint arXiv:2602.16855, 2026
-
[33]
Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction
Yiheng Xu, Zekun Wang, Junli Wang, Dunjie Lu, Tianbao Xie, Amrita Saha, Doyen Sahoo, Tao Yu, and Caiming Xiong. Aguvis: Unified pure vision agents for autonomous gui interaction. arXiv preprint arXiv:2412.04454, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Visionzip: Longer is better but not necessary in vision language models
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. Visionzip: Longer is better but not necessary in vision language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19792–19802, 2025
work page 2025
-
[35]
Mobile-Agent-v3: Fundamental Agents for GUI Automation
Jiabo Ye, Xi Zhang, Haiyang Xu, Haowei Liu, Junyang Wang, Zhaoqing Zhu, Ziwei Zheng, Feiyu Gao, Junjie Cao, Zhengxi Lu, et al. Mobile-agent-v3: Fundamental agents for gui automation.arXiv preprint arXiv:2508.15144, 2025
work page internal anchor Pith review arXiv 2025
-
[36]
Enhancing multi- modal large language models complex reason via similarity computation
Xiaofeng Zhang, Fanshuo Zeng, Yihao Quan, Zheng Hui, and Jiawei Yao. Enhancing multi- modal large language models complex reason via similarity computation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 10203–10211, 2025
work page 2025
-
[37]
Hanzhang Zhou, Xu Zhang, Panrong Tong, Jianan Zhang, Liangyu Chen, Quyu Kong, Chenglin Cai, Chen Liu, Yue Wang, Jingren Zhou, et al. Mai-ui technical report: Real-world centric foundation gui agents.arXiv preprint arXiv:2512.22047, 2025
-
[38]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023. 12 A Detailed Algorithm A.1 Grid Alignment and Boundary Handling Given a resized screenshot of size W×H , AQuaUI c...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.