Sibyl-AutoResearch: Autonomous Research Needs Self-Evolving Trial-and-Error Harnesses, Not Paper Generators
Pith reviewed 2026-05-22 01:59 UTC · model grok-4.3
The pith
Autonomous research systems gain judgment when trial outcomes update future actions and system processes rather than turning into prose.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
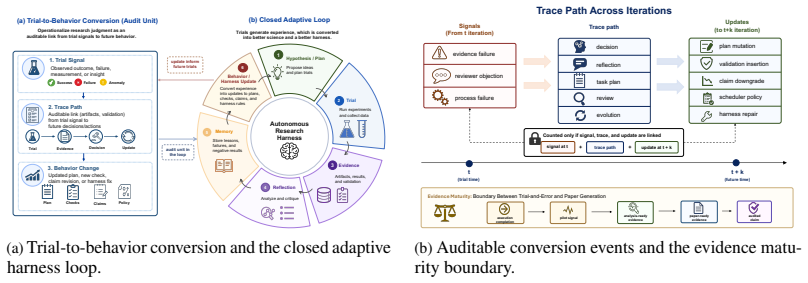
The paper claims that self-evolving AutoResearch requires Scientific Trial-and-Error Harnesses equipped with trial-to-behavior conversion and trial-to-harness-behavior conversion units. These units link trial signals to later research actions and recurring process failures to system updates. In the SIBYL implementation, a retrospective audit recovered eight high-confidence conversion events with a median latency of one iteration, and a recovered-failure registry showed how five failure classes were blocked, downgraded, or routed into repair.
What carries the argument
Scientific Trial-and-Error Harnesses: bounded trial structures that preserve outcomes and route lessons from both successes and failures into subsequent research steps and self-repair.
If this is right
- Positive and negative trial results become preserved inputs for later planning and validation instead of being discarded.
- Recurring failures are identified and trigger targeted updates to the harness or research process.
- Claim scope and evidence standards can be tightened based on prior trial signals.
- The system state remains inspectable so conversion paths from trials to behavior can be audited.
Where Pith is reading between the lines
- The same conversion approach could be tested in non-research agent tasks such as iterative code optimization or experimental protocol design.
- Over repeated cycles the harness might accumulate domain-specific heuristics that reduce the need for external correction.
- Long-running autonomous projects could maintain consistency by routing lessons across multiple sub-tasks rather than resetting memory each time.
Load-bearing premise
That the trial-to-behavior and trial-to-harness-behavior conversion units can be implemented to produce measurable improvements in research judgment.
What would settle it
A controlled comparison of research output quality and error repetition rates between an agent using the proposed conversion units and a baseline agent without them.
Figures






read the original abstract
Autonomous research systems increasingly make the scientific workflow executable: agents can propose ideas, run code, inspect results, and draft papers. But executable workflows do not by themselves produce research judgment. We analyze where current systems lose trial experience: weak evidence becomes prose, pilot signals become broad claims, memory remains textual, and recurring process failures do not change later behavior. We introduce Sibyl-AutoResearch, a self-evolving AutoResearch framework built around Scientific Trial-and-Error Harnesses. A harness lets agents run bounded trials, preserve positive and negative outcomes, and route lessons into later planning, validation, claim scope, scheduling, critique, writing, and harness repair. We formalize this through two auditable conversion units: trial-to-behavior conversion, which links trial signals to later research actions, and trial-to-harness-behavior conversion, which links recurring process failures to system updates. We implement the framework in SIBYL, a file-backed autonomous research system that exposes the state, roles, memory, gates, and artifact traces needed to inspect these conversion paths. A retrospective audit identifies eight high-confidence conversion events, with a median latency of one iteration and a maximum latency of three iterations. A recovered-failure registry further shows how five naturally occurring failure classes, including duplicate results, stale numbers, and unsupported statistics, were blocked, downgraded, or routed into later repair. These traces do not establish a comparative performance claim; they show that the proposed conversion units are recoverable from realistic autonomous-research workspaces. The SIBYL framework and system are available at https://github.com/Sibyl-Research-Team/AutoResearch-SibylSystem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Sibyl-AutoResearch, a self-evolving framework for autonomous research built around Scientific Trial-and-Error Harnesses. A harness enables bounded trials whose positive and negative outcomes are preserved and routed into later planning, validation, claim scoping, scheduling, critique, writing, and harness repair. The framework is formalized through two auditable conversion units (trial-to-behavior and trial-to-harness-behavior). It is implemented in the file-backed SIBYL system, which exposes state, roles, memory, gates, and traces. A retrospective audit of SIBYL identifies eight high-confidence conversion events (median latency one iteration) and five naturally occurring failure classes (duplicates, stale numbers, unsupported statistics) that were blocked or repaired. The paper explicitly disclaims comparative performance claims and limits its contribution to demonstrating recoverability of the proposed units; the code is released at https://github.com/Sibyl-Research-Team/AutoResearch-SibylSystem.
Significance. If controlled experiments later establish that the conversion units produce measurable gains in research judgment relative to standard persistent logging or memory mechanisms, the work would provide a concrete, auditable substrate for self-evolution in autonomous research agents. The open release of SIBYL and the explicit recoverability traces constitute a reproducible starting point for such follow-up studies. At present the retrospective self-audit supplies only existence and latency data rather than causal evidence.
major comments (2)
- [Abstract] Abstract and introduction: the title and framing assert that autonomous research 'needs' self-evolving trial-and-error harnesses rather than paper generators, yet the only empirical support is a retrospective audit of the authors' own system with no control condition, no comparison to simpler persistent-state mechanisms, and no external tasks or independent judges. This leaves the causal contribution of the two conversion units untested.
- [Retrospective audit] Retrospective audit section: the identification of eight high-confidence conversion events and five failure classes is presented without describing the audit protocol, inter-rater reliability, or decision criteria used to label an event as a 'conversion.' Without these details the claim that the units are 'recoverable from realistic autonomous-research workspaces' cannot be evaluated.
minor comments (1)
- The manuscript would benefit from an explicit table or diagram mapping each conversion unit to the downstream research activities it affects (planning, critique, harness repair, etc.).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address the major comments point by point below, clarifying the intended scope of the contribution while committing to revisions that improve evaluability without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and introduction: the title and framing assert that autonomous research 'needs' self-evolving trial-and-error harnesses rather than paper generators, yet the only empirical support is a retrospective audit of the authors' own system with no control condition, no comparison to simpler persistent-state mechanisms, and no external tasks or independent judges. This leaves the causal contribution of the two conversion units untested.
Authors: We agree that the retrospective audit provides no control condition or comparative baseline and therefore cannot establish causal superiority of the conversion units. The manuscript already states explicitly that the traces 'do not establish a comparative performance claim' and are limited to showing recoverability. The title and framing present a proposed direction rather than an empirical superiority claim. To reduce the risk of misinterpretation, we will revise the abstract and introduction to foreground the non-comparative scope and the role of this work as a reproducible substrate for subsequent controlled studies. revision: partial
-
Referee: [Retrospective audit] Retrospective audit section: the identification of eight high-confidence conversion events and five failure classes is presented without describing the audit protocol, inter-rater reliability, or decision criteria used to label an event as a 'conversion.' Without these details the claim that the units are 'recoverable from realistic autonomous-research workspaces' cannot be evaluated.
Authors: We accept that the audit protocol, decision criteria, and labeling process were insufficiently documented. In the revised manuscript we will add a dedicated subsection describing the retrospective audit procedure, the explicit criteria used to classify events as high-confidence conversions, the process for identifying the five failure classes, and the steps taken to ensure internal consistency. Because the audit was performed by the authors as a single retrospective review, formal inter-rater reliability statistics do not apply; we will note this limitation and document the consistency checks that were applied. revision: yes
Circularity Check
No significant circularity; audit limited to recoverability without performance claims
full rationale
The paper's chain introduces a conceptual framework of Trial-and-Error Harnesses and two conversion units, implements them in SIBYL, and reports a retrospective audit of conversion events and failure classes within that same system. However, the text explicitly disclaims any comparative performance claim and restricts the audit's purpose to showing that the units are recoverable from realistic workspaces. No equations, fitted parameters renamed as predictions, self-citations as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear. The central proposal therefore remains a design description with internal traces rather than a derivation that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Executable workflows in autonomous research do not by themselves produce research judgment
invented entities (2)
-
Scientific Trial-and-Error Harnesses
no independent evidence
-
trial-to-behavior conversion unit
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery and embed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formalize this through two auditable conversion units: trial-to-behavior conversion, which links trial signals to later research actions, and trial-to-harness-behavior conversion, which links recurring process failures to system updates.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Evidence maturity: Execution completion, pilot signal, analysis-ready evidence, paper-ready evidence, and audited claim are different states.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Writing effective tools for agents — with agents
Ken Aizawa. Writing effective tools for agents — with agents. https://www.anthropic. com/engineering/writing-tools-for-agents , 2025. Anthropic Engineering. Published 2025-09-11. Accessed 2026-05-05
work page 2025
-
[2]
Analemma Team. Introducing FARS. https://analemma.ai/blog/introducing-fars/,
- [3]
-
[4]
Aster: Autonomous scientific discovery over 20x faster than existing methods,
Emmett Bicker. Aster: Autonomous scientific discovery over 20x faster than existing methods,
- [5]
-
[6]
Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes
Daniil A. Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemical research with large language models.Nature, 624(7992):570–578, 2023. doi: 10.1038/ s41586-023-06792-0. URLhttps://doi.org/10.1038/s41586-023-06792-0
-
[7]
ChemCrow: Augmenting large-language models with chemistry tools
Andres M. Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D. White, and Philippe Schwaller. ChemCrow: Augmenting large-language models with chemistry tools, 2023. URL https://arxiv.org/abs/2304.05376. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Yuanqi Du, Botao Yu, Tianyu Liu, Tony Shen, Junwu Chen, Jan G. Rittig, Kunyang Sun, Yikun Zhang, Aarti Krishnan, Yu Zhang, Daniel Rosen, Rosali Pirone, Zhangde Song, Bo Zhou, Cassandra Masschelein, Yingze Wang, Haorui Wang, Haojun Jia, Chao Zhang, Hongyu Zhao, Martin Ester, Nir Hacohen, Teresa Head-Gordon, Carla P. Gomes, Huan Sun, Chenru Duan, Philippe S...
-
[9]
K. A. Ericsson and A. C. Lehmann. Expert and exceptional performance: Evidence of maximal adaptation to task constraints.Annual Review of Psychology, 47(1):273–305, February 1996. ISSN 1545-2085. doi: 10.1146/annurev.psych.47.1.273. URL http://dx.doi.org/10. 1146/annurev.psych.47.1.273
-
[10]
Ali Essam Ghareeb, Benjamin Chang, Ludovico Mitchener, Angela Yiu, Caralyn J. Szostkiewicz, Jon M. Laurent, Muhammed T. Razzak, Andrew D. White, Michaela M. Hinks, and Samuel G. Rodriques. Robin: A multi-agent system for automating scientific discovery,
- [11]
-
[12]
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, Khaled Saab, Dan Popovici, Jacob Blum, Fan Zhang, Katherine Chou, Avinatan Hassidim, Burak Gokturk, Amin Vahdat, Pushmeet Kohli, Yossi Matias, Andrew Carroll, Kavita Kulkarni, Nenad Tomasev, Yuan Guan, Vi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Odd Erik Gundersen and Sigbjørn Kjensmo. State of the art: Reproducibility in artificial intelligence.Proceedings of the AAAI Conference on Artificial Intelligence, 32(1), April 2018. ISSN 2159-5399. doi: 10.1609/aaai.v32i1.11503. URL http://dx.doi.org/10.1609/ aaai.v32i1.11503
-
[14]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. MetaGPT: Meta programming for a multi-agent collaborative framework, 2023. URLhttps://arxiv.org/abs/2308.00352
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
MLAgentBench: Evaluating language agents on machine learning experimentation, 2023
Qian Huang, Jian V ora, Percy Liang, and Jure Leskovec. MLAgentBench: Evaluating language agents on machine learning experimentation, 2023. URL https://arxiv.org/abs/2310. 03302
work page 2023
-
[16]
Frank Hutter, Lars Kotthoff, and Joaquin Vanschoren, editors.Automated Machine Learning - Methods, Systems, Challenges. Springer, 2019
work page 2019
-
[17]
John P. A. Ioannidis. Why most published research findings are false.PLoS Medicine, 2 (8):e124, August 2005. ISSN 1549-1676. doi: 10.1371/journal.pmed.0020124. URL http: //dx.doi.org/10.1371/journal.pmed.0020124
-
[18]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues?,
-
[19]
URLhttps://arxiv.org/abs/2310.06770
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Andrej Karpathy. autoresearch. https://github.com/karpathy/autoresearch, 2026. GitHub repository. Accessed 2026-05-05
work page 2026
-
[21]
Timothy Lebo, Satya Sahoo, Deborah McGuinness, Khalid Belhajjame, James Cheney, David Corsar, Daniel Garijo, Stian Soiland-Reyes, Stephan Zednik, and Jun Zhao.PROV-O: The PROV Ontology. W3C Recommendation. World Wide Web Consortium, United States, April 2013
work page 2013
-
[22]
AgentBench: Evaluating LLMs as agents, 2023
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. AgentBench: Evaluating LLMs as agents, 2023. URL https://arxiv.org/abs/2308. 03688. 11
work page 2023
-
[23]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery, 2024. URL https: //arxiv.org/abs/2408.06292
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Self-Refine: Iterative Refinement with Self-Feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback, 2023. URL https://arxiv.org/abs/2303.17651
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Kosmos: An AI Scientist for Autonomous Discovery
Ludovico Mitchener, Angela Yiu, Benjamin Chang, Mathieu Bourdenx, Tyler Nadolski, Arvis Sulovari, Eric C. Landsness, Daniel L. Barabasi, Siddharth Narayanan, Nicky Evans, Shriya Reddy, Martha Foiani, Aizad Kamal, Leah P. Shriver, Fang Cao, Asmamaw T. Wassie, Jon M. Laurent, Edwin Melville-Green, Mayk Caldas, Albert Bou, Kaleigh F. Roberts, Sladjana Zagora...
work page internal anchor Pith review arXiv 2025
-
[26]
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. Alphaevolve: A coding agent for scientific and algor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
OpenAI. Guardrails. https://openai.github.io/openai-agents-python/ guardrails/, 2026. OpenAI Agents SDK documentation. Accessed 2026-05-05
work page 2026
-
[28]
OpenAI. Tracing. https://openai.github.io/openai-agents-python/tracing/,
- [29]
-
[30]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Memgpt: Towards llms as operating systems, 2024. URL https: //arxiv.org/abs/2310.08560
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Generative Agents: Interactive Simulacra of Human Behavior
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior, 2023. URL https://arxiv.org/abs/2304.03442
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
CORAL: Towards autonomous multi-agent evolution for open-ended discovery, 2026
Ao Qu, Han Zheng, Zijian Zhou, Yihao Yan, Yihong Tang, Shao Yong Ong, Fenglu Hong, Kaichen Zhou, Chonghe Jiang, Minwei Kong, Jiacheng Zhu, Xuan Jiang, Sirui Li, Cathy Wu, Bryan Kian Hsiang Low, Jinhua Zhao, and Paul Pu Liang. CORAL: Towards autonomous multi-agent evolution for open-ended discovery, 2026. URL https://arxiv.org/abs/2604. 01658
work page 2026
-
[33]
Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools, 2023. URLhttps://arxiv.org/abs/2302.04761
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Agent Laboratory: Using LLM Agents as Research Assistants
Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. Agent laboratory: Using llm agents as research assistants, 2025. URLhttps://arxiv.org/abs/2501.04227
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning, 2023. URL https://arxiv.org/abs/2303.11366
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
PaperBench: Evaluating AI's Ability to Replicate AI Research
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Tejal Patwardhan. Paperbench: Evaluating ai’s ability to replicate ai research, 2025. URLhttps://arxiv.org/abs/2504.01848. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
V oyager: An open-ended embodied agent with large language models,
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models,
-
[38]
URLhttps://arxiv.org/abs/2305.16291
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
White, Doug Burger, and Chi Wang
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversation,
-
[40]
URLhttps://arxiv.org/abs/2308.08155
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Licong Xu, Milind Sarkar, Anto I. Lonappan, Inigo Zubeldia, Pablo Villanueva-Domingo, Santiago Casas, Christian Fidler, Chetana Amancharla, Ujjwal Tiwari, Adrian Bayer, Chadi Ait Ekioui, Miles Cranmer, Adrian Dimitrov, James Fergusson, Kahaan Gandhi, Sven Krippendorf, Andrew Laverick, Julien Lesgourgues, Antony Lewis, Thomas Meier, Blake Sherwin, Kristen ...
-
[42]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search, 2025. URLhttps://arxiv.org/abs/2504.08066
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated software engineering, 2024. URLhttps://arxiv.org/abs/2405.15793
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models, 2022. URL https: //arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[45]
Effective harnesses for long-running agents
Justin Young. Effective harnesses for long-running agents. https://www.anthropic.com/ engineering/effective-harnesses-for-long-running-agents , 2025. Anthropic En- gineering. Published 2025-11-26. Accessed 2026-05-05
work page 2025
-
[46]
Barret Zoph and Quoc V . Le. Neural architecture search with reinforcement learning, 2017. URLhttps://arxiv.org/abs/1611.01578. 13 Appendix The appendix follows the same order as the main argument. Appendix A expands the SIBYL mechanisms and supporting diagrams. Appendix B gives the workspace traces and the recovered- failure registry behind the conversio...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[47]
Iterations 1–5: initial measurement and narrative formation.The system builds an initial absorption story, writes drafts, runs targeted probes, and accumulates reflection artifacts. These iterations establish the central research object but also start the pattern that later becomes important: the paper can become smoother while source-to-paper numeric con...
-
[48]
Iterations 6–8: writing stagnation and missing validation.The quality trajectory stalls around 6.5. Reflection repeatedly asks for a source-to-paper validation script, but the recommendation remains a lesson rather than a hard writing gate. Iteration 8 records the ninth recommendation of the script and finds a fabricated 12.3% hedging number where raw dat...
-
[49]
Iteration 9: experiment-first break from polishing.The project breaks the writing-only loop by executing new empirical checks: activation patching, tightened hedging analysis, conditional- mutual-information replication, and threshold sensitivity. The score rises from 6.5 to 7.0 because the system has produced new evidence rather than only a cleaner narrative
-
[50]
Iteration 10: scientific progress plus evidence-boundary failure.The iteration produces a strong probe-degradation result (R2 = 0.777, ρ=−1.0 , p= 0.009 ), decoder-magnitude evidence (6.16 nats for first-letter and 3.98 nats for city-continent), and rate-distortion rejection across 131 pairs. The score still regresses from 7.0 to 6.5 because the paper imp...
-
[51]
Iteration 11: data integrity becomes the iteration objective.The next plan explicitly makes the iteration about data integrity and verification. The source-to-paper validation script is implemented, 51/53 checks pass, CI inversions are fixed, per-token aggregation becomes canonical, the headline changes from 4.1× to 2.7×, and the 21.6%/27.1%/34.5% first-l...
-
[52]
Iterations 0–7: idea formation, early pilots, and repeated evidence gaps.The project builds a dynamic weight-decay story and accumulates experiments across small and medium settings. Quality moves upward and downward rather than monotonically: the quality log includes 5.5, 7.0, 5.0, 6.5, 6.75, 7.0, and later 6.5. This volatility is useful because it expos...
-
[53]
Iterations 8–12: recurring control and generalization failure mode.Reflection and evolution records keep surfacing missing ImageNet evidence, equivalence-test weakness, budget confounds, and control reliability. The evolution outcome marks missing ImageNet evidence as recurring for 7+ iterations, records equivalence tests passing only 6/12 comparisons, an...
-
[54]
The important system behavior is that these signals do not get absorbed as prose caveats
Iteration 13: refinement becomes unavoidable.Reflection records raw-log mismatches, hidden negative auxiliary-baseline results, corrupted controls, higher-regularization control gaps, and a 90-epoch ImageNet need. The important system behavior is that these signals do not get absorbed as prose caveats. They become blockers for broad advancement
-
[55]
Iteration 14: repair, validation, and scoped advancement.The supervisor path introduces a repaired controller with floor clipping, moving-average smoothing, and epoch-budget assertions. The fix passes 9/9 stability tests; the single-parameter controller budget changes from 0.0 to 90.61; ImageNet control-signal informativeness reaches 0.987; one hypothesis...
-
[56]
Iteration 1: paper and metric errors become experiment requirements.Reflection fixes fabricated Wilcoxon claims, a tau = 0.0 paradox, failure-atlas number mismatches, a quality- 17 adjusted-speed formula inconsistency, a 6-pair overclaim where only 3 pairs are feasible, novelty overclaiming, and a speed-report mismatch for one proposed accelerator. The sa...
-
[57]
Iteration 2: the scientific story flips from multiplication to interference.Result debate reports 15 experiment groups, one proposed accelerator as a functional no-op around 1.16×, destructive interference between two accelerators, partial interference between another accelerator pair, and an autoregressive baseline comparison where Qwen2.5-7B reaches 96%...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.