Event-VLA: Action-Conditioned Event Fusion for Robust Vision-Language-Action Model
Pith reviewed 2026-06-30 06:59 UTC · model grok-4.3
The pith
Event-VLA routes event camera data through action queries to keep vision-language-action manipulation reliable when lighting drops.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
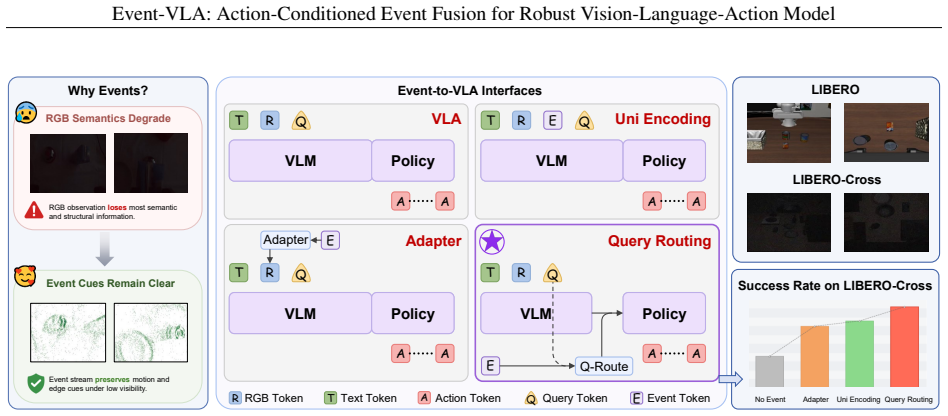
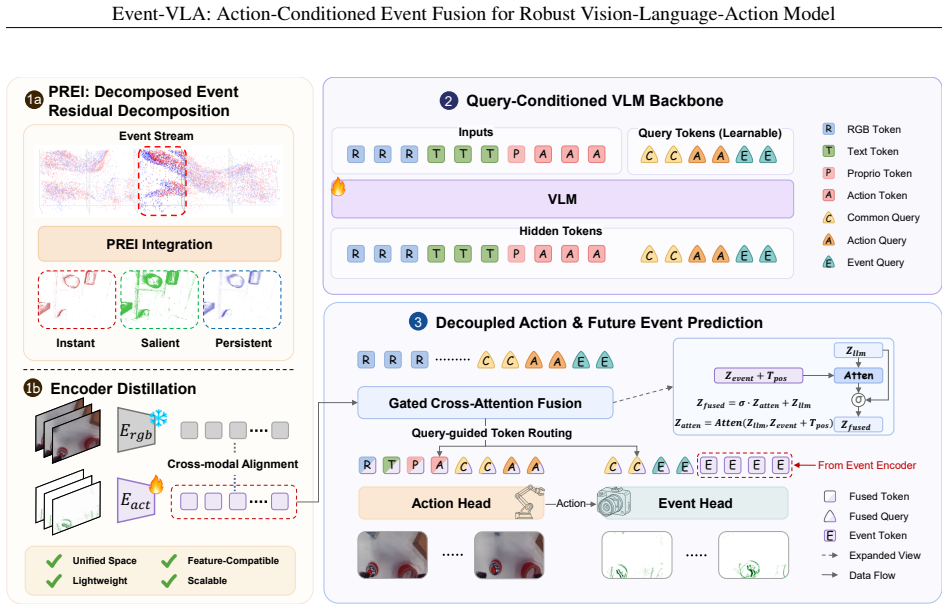
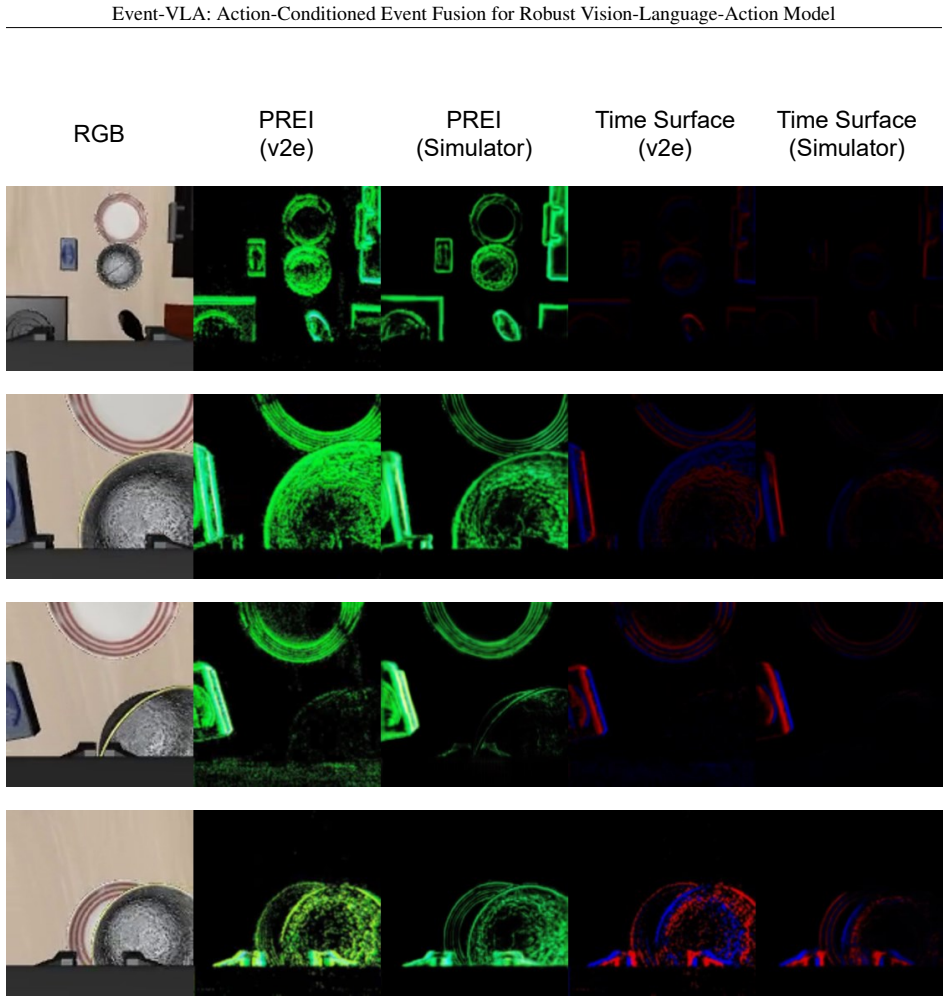
Event-VLA formulates degraded-visibility manipulation as a robustness problem for RGB-centric VLA policies and solves it by injecting event information through an action-query routing pathway: learnable action queries extract task-relevant semantics from the VLA reasoning process and then selectively aggregate event tokens via gated cross-attention to build event-aware action representations, thereby preserving pretrained RGB-language semantic priors while supplying illumination-robust cues for action prediction.
What carries the argument
The action-query routing pathway, which uses learnable action queries to pull task-relevant semantics and gated cross-attention to fuse event tokens into action representations.
If this is right
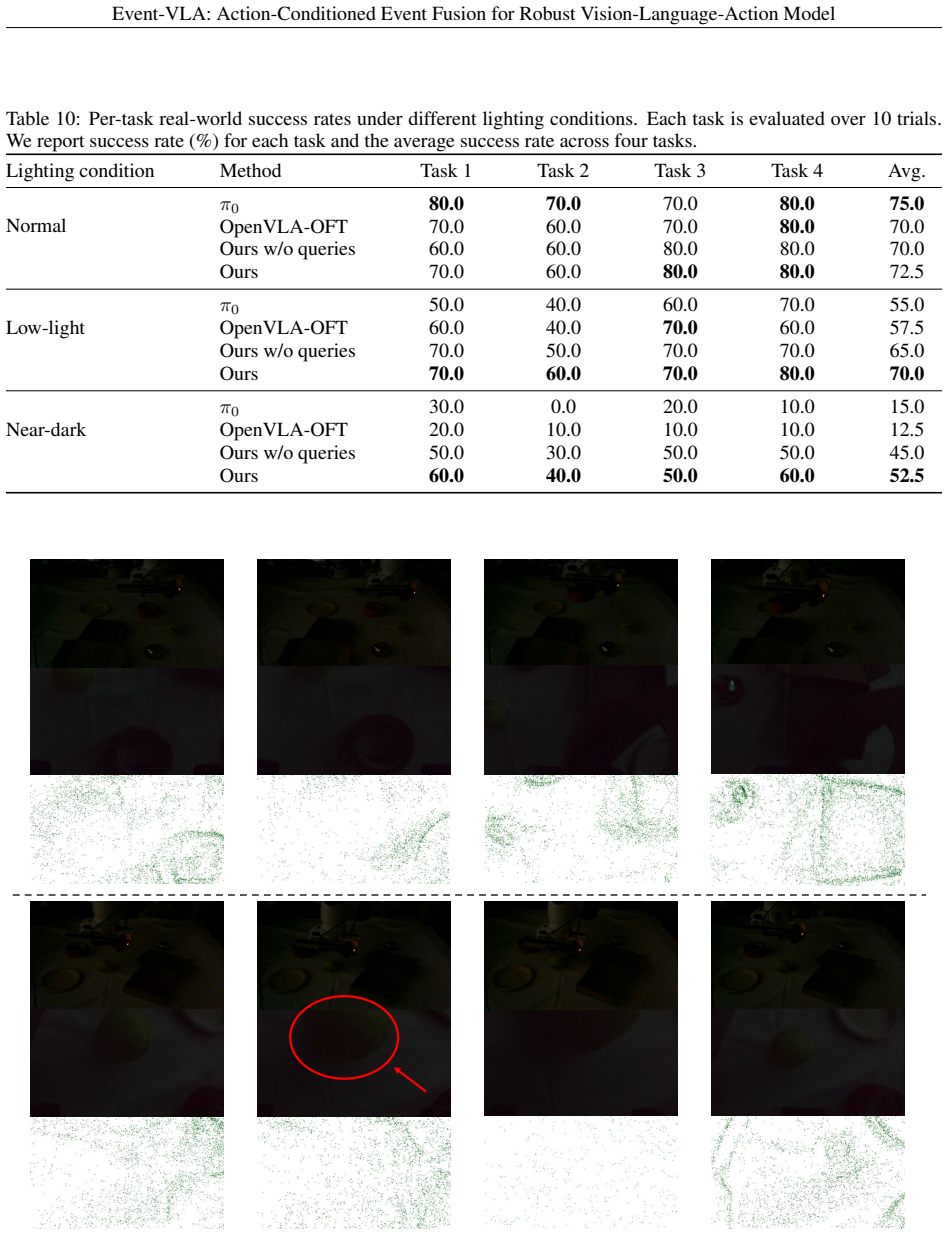
- The model maintains baseline success rates under normal indoor lighting.
- Success rates rise under simulated low-light degradation and in real near-dark deployments.
- The pretrained RGB-language priors remain intact because event data never enters the global semantic token space directly.
- The same architecture works for both simulation and physical robot hardware without separate retraining.
Where Pith is reading between the lines
- The same query-routing idea could be tested with other event-like sensors such as thermal or depth to handle different failure modes.
- If the gating mechanism proves stable, it might allow incremental addition of new modalities without full model retraining.
- Real-world deployment data already hints that the method generalizes across at least two distinct lighting regimes.
Load-bearing premise
That selectively routing event tokens through action queries will add useful complementary motion information without harming the pretrained RGB-language understanding.
What would settle it
A controlled comparison in which the same VLA backbone with and without the event-fusion module shows no gain (or a drop) in success rate on identical low-light and near-dark manipulation trials.
Figures




read the original abstract
Vision-Language-Action (VLA) models have become an important paradigm of embodied AI. However, existing VLA models typically assume well-lit and stable indoor settings, while real-world embodied manipulation may involve degraded RGB observations caused by illumination shifts, posing critical challenges for robust robotic manipulation. To address this gap, we propose \textbf{Event-VLA}, an event-enhanced VLA framework for generalizable manipulation across varying illumination conditions. We formulate VLA-based manipulation under degraded visibility as a practical robustness problem for RGB-centric policies, and introduce event streams as an illumination-robust, motion-sensitive complementary observation to improve robustness across visibility levels. Specifically, unlike conventional multimodal fusion that directly merges event features into the global semantic token space, Event-VLA injects event information through an action-query routing pathway. It uses learnable action queries to extract task-relevant semantics from the VLA reasoning process, and selectively aggregates event tokens via gated cross-attention to construct event-aware action representations. This design preserves the pretrained RGB-language semantic priors while effectively leveraging event information for robust action prediction. Experiments in simulation and real-world deployment show that Event-VLA maintains strong manipulation performance under normal lighting and improves success rates under low-light degradation and near-dark real-world settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Event-VLA, a VLA framework that injects event-camera streams via learnable action queries and gated cross-attention rather than direct multimodal fusion, claiming this preserves pretrained RGB-language priors while improving manipulation success under low-light and near-dark conditions in both simulation and real-world settings.
Significance. If the empirical claims are substantiated with baselines and controls, the work targets a genuine robustness gap in embodied VLA policies; the action-query routing mechanism is a plausible way to add motion-sensitive, illumination-invariant signals without wholesale retraining.
major comments (2)
- [Abstract] Abstract: the claim that the gated cross-attention pathway 'preserves the pretrained RGB-language semantic priors' is load-bearing for the central contribution, yet the manuscript supplies no supporting controls (side-by-side normal-light success rates of the unmodified base VLA versus Event-VLA, language-token similarity, or zero-shot VQA scores before/after the event branch).
- [Experiments] Experiments (implied by the reported success-rate gains): no baseline comparisons, ablation tables, error bars, or dataset statistics are referenced, so it is impossible to determine whether the reported improvements under degraded visibility are statistically meaningful or whether normal-light performance is truly unchanged.
minor comments (1)
- [Abstract] The abstract would benefit from explicit citation of the simulation environments and real-world manipulation tasks used to generate the success-rate numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback identifying gaps in supporting evidence for our central claims. We address each major comment below and commit to revisions that strengthen the manuscript with additional controls and clearer experimental reporting.
read point-by-point responses
-
Referee: [Abstract] the claim that the gated cross-attention pathway 'preserves the pretrained RGB-language semantic priors' is load-bearing for the central contribution, yet the manuscript supplies no supporting controls (side-by-side normal-light success rates of the unmodified base VLA versus Event-VLA, language-token similarity, or zero-shot VQA scores before/after the event branch).
Authors: We agree the preservation claim requires stronger substantiation. The experiments section reports that Event-VLA maintains comparable success rates to the base VLA under normal lighting, but we did not include explicit side-by-side tables or auxiliary metrics such as token similarity. We will revise the manuscript to add these direct controls and comparisons. revision: yes
-
Referee: [Experiments] no baseline comparisons, ablation tables, error bars, or dataset statistics are referenced, so it is impossible to determine whether the reported improvements under degraded visibility are statistically meaningful or whether normal-light performance is truly unchanged.
Authors: The manuscript includes baseline comparisons against standard VLA models, ablation studies on the action-query routing and gated attention, and dataset statistics in the experimental setup. Error bars from repeated trials appear in the supplementary material. We will revise to reference these elements more prominently in the main text and add explicit normal-light comparisons against the unmodified base model. revision: yes
Circularity Check
No derivation chain; empirical architecture proposal
full rationale
The paper introduces Event-VLA as an empirical architecture for fusing event streams into a pretrained VLA via action queries and gated cross-attention. No equations, first-principles derivations, fitted parameters, or uniqueness theorems appear in the provided text. Claims rest on experimental success rates under varying illumination rather than any closed-form result that reduces to its inputs by construction. Self-citations, if present, are not load-bearing for any mathematical step. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable action queries
Reference graph
Works this paper leans on
-
[1]
Dreamvla: a vision-language-action model dreamed with comprehensive world knowledge.Advances in Neural Information Processing Systems, 38:24195–24228, 2026
Wenyao Zhang, Hongsi Liu, Zekun Qi, Yunnan Wang, Xinqiang Yu, Jiazhao Zhang, Runpei Dong, Jiawei He, He Wang, Zhizheng Zhang, et al. Dreamvla: a vision-language-action model dreamed with comprehensive world knowledge.Advances in Neural Information Processing Systems, 38:24195–24228, 2026
2026
-
[2]
Rdt-1b: a diffusion foundation model for bimanual manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation. InInternational Conference on Learning Representations, volume 2025, pages 29982–30009, 2025
2025
-
[3]
DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control
Junjie Wen, Yichen Zhu, Jinming Li, Zhibin Tang, Chaomin Shen, and Feifei Feng. Dexvla: Vision-language model with plug-in diffusion expert for general robot control.arXiv preprint arXiv:2502.05855, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, et al. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1702–1713, 2025
2025
-
[5]
Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies
Ruijie Zheng, Yongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daum ´e III, Andrey Kolobov, Furong Huang, and Jianwei Yang. Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. InInternational Conference on Learning Representations, volume 2025, pages 54277–54296, 2025
2025
-
[6]
Predictive inverse dynamics models are scalable learners for robotic manipulation
Yang Tian, Sizhe Yang, Jia Zeng, Ping Wang, Dahua Lin, Hao Dong, and Jiangmiao Pang. Predictive inverse dynamics models are scalable learners for robotic manipulation. InInternational Conference on Learning Rep- resentations, volume 2025, pages 92033–92052, 2025
2025
-
[7]
Jianke Zhang, Yanjiang Guo, Yucheng Hu, Xiaoyu Chen, Xiang Zhu, and Jianyu Chen. Up-vla: A unified understanding and prediction model for embodied agent.arXiv preprint arXiv:2501.18867, 2025
-
[8]
Minghui Lin, Pengxiang Ding, Shu Wang, Zifeng Zhuang, Yang Liu, Xinyang Tong, Wenxuan Song, Shangke Lyu, Siteng Huang, and Donglin Wang. Hif-vla: Hindsight, insight and foresight through motion representation for vision-language-action models.arXiv preprint arXiv:2512.09928, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
A survey on vision–language–action models for embodied ai.IEEE Transactions on Neural Networks and Learning Systems, 2026
Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, and Irwin King. A survey on vision–language–action models for embodied ai.IEEE Transactions on Neural Networks and Learning Systems, 2026
2026
-
[10]
Zhenhao Zhang, Jiaxin Liu, Ye Shi, and Jingya Wang. Unihm: Unified dexterous hand manipulation with vision language model.arXiv preprint arXiv:2603.00732, 2026
-
[11]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.\π 0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al.π 0.5: A vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Con- nors, James Darpinian, Karan Dhabalia, Jared DiCarlo, et al.π ∗ 0.6: A VLA that learns from experience.arXiv preprint arXiv:2511.14759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Mm-act: Learn from multimodal parallel generation to act.arXiv preprint arXiv:2512.00975, 2025
Haotian Liang, Xinyi Chen, Bin Wang, Mingkang Chen, Yitian Liu, Yuhao Zhang, Zanxin Chen, Tianshuo Yang, Yilun Chen, Jiangmiao Pang, et al. Mm-act: Learn from multimodal parallel generation to act.arXiv preprint arXiv:2512.00975, 2025
-
[17]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Mmada: Multimodal large diffusion language models.Advances in Neural Information Processing Systems, 38:138867–138907, 2026
Ling Yang, Ye Tian, Bowen Li, Xinchen Zhang, Ke Shen, Yunhai Tong, and Mengdi Wang. Mmada: Multimodal large diffusion language models.Advances in Neural Information Processing Systems, 38:138867–138907, 2026
2026
-
[19]
Shanshan Zhao, Xinjie Zhang, Jintao Guo, Jiakui Hu, Lunhao Duan, Minghao Fu, Yong Xien Chng, Guo-Hua Wang, Qing-Guo Chen, Zhao Xu, et al. Unified multimodal understanding and generation models: Advances, challenges, and opportunities.arXiv preprint arXiv:2505.02567, 2025. 9 Event-VLA: Action-Conditioned Event Fusion for Robust Vision-Language-Action Model
-
[20]
Gemini Robotics: Bringing AI into the Physical World
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montserrat Gonzalez Are- nas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[22]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, et al. Smolvla: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
Senyu Fei, Siyin Wang, Junhao Shi, Zihao Dai, Jikun Cai, Pengfang Qian, Li Ji, Xinzhe He, Shiduo Zhang, Zhaoye Fei, et al. Libero-plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
A 128×128 120 dB 15µs latency asynchronous temporal contrast vision sensor.IEEE journal of solid-state circuits, 43(2):566–576, 2008
Patrick Lichtsteiner, Christoph Posch, and Tobi Delbruck. A 128×128 120 dB 15µs latency asynchronous temporal contrast vision sensor.IEEE journal of solid-state circuits, 43(2):566–576, 2008
2008
-
[25]
A 240×180 130 db 3µs latency global shutter spatiotemporal vision sensor.IEEE Journal of Solid-State Circuits, 49(10):2333–2341, 2014
Christian Brandli, Raphael Berner, Minhao Yang, Shih-Chii Liu, and Tobi Delbruck. A 240×180 130 db 3µs latency global shutter spatiotemporal vision sensor.IEEE Journal of Solid-State Circuits, 49(10):2333–2341, 2014
2014
-
[26]
Event-based vision: A survey.IEEE transactions on pattern analysis and machine intelligence, 44(1):154–180, 2020
Guillermo Gallego, Tobi Delbr ¨uck, Garrick Orchard, Chiara Bartolozzi, Brian Taba, Andrea Censi, Stefan Leutenegger, Andrew J Davison, J ¨org Conradt, Kostas Daniilidis, et al. Event-based vision: A survey.IEEE transactions on pattern analysis and machine intelligence, 44(1):154–180, 2020
2020
-
[27]
Recent event camera innovations: A survey
Bharatesh Chakravarthi, Aayush Atul Verma, Kostas Daniilidis, Cornelia Fermuller, and Yezhou Yang. Recent event camera innovations: A survey. InEuropean conference on computer vision, pages 342–376. Springer, 2024
2024
-
[28]
Xu Zheng, Yexin Liu, Yunfan Lu, Tongyan Hua, Tianbo Pan, Weiming Zhang, Dacheng Tao, and Lin Wang. Deep learning for event-based vision: A comprehensive survey and benchmarks.arXiv preprint arXiv:2302.08890, 2023
-
[29]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InCon- ference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[31]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems, 35:23716–23736, 2022
2022
-
[33]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Vla-touch: Enhancing vision- language-action model with dual-level tactile feedback.IEEE Robotics and Automation Letters, 2026
Jianxin Bi, Kevin Yuchen Ma, Ce Hao, Mike Shou Zheng, and Harold Soh. Vla-touch: Enhancing vision- language-action model with dual-level tactile feedback.IEEE Robotics and Automation Letters, 2026
2026
-
[35]
PaLM-E: An Embodied Multimodal Language Model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
StereoVLA: Enhancing Vision-Language-Action Models with Stereo Vision
Shengliang Deng, Mi Yan, Yixin Zheng, Jiayi Su, Wenhao Zhang, Xiaoguang Zhao, Heming Cui, Zhizheng Zhang, and He Wang. Stereovla: Enhancing vision-language-action models with stereo vision.arXiv preprint arXiv:2512.21970, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Jialei Huang, Shuo Wang, Fanqi Lin, Yihang Hu, Chuan Wen, and Yang Gao. Tactile-vla: unlocking vision- language-action model’s physical knowledge for tactile generalization.arXiv preprint arXiv:2507.09160, 2025
-
[38]
Zhengxue Cheng, Yiqian Zhang, Wenkang Zhang, Haoyu Li, Keyu Wang, Li Song, and Hengdi Zhang. Omnivtla: Vision-tactile-language-action model with semantic-aligned tactile sensing.arXiv preprint arXiv:2508.08706, 2025. 10 Event-VLA: Action-Conditioned Event Fusion for Robust Vision-Language-Action Model
-
[39]
Hots: a hierar- chy of event-based time-surfaces for pattern recognition.IEEE transactions on pattern analysis and machine intelligence, 39(7):1346–1359, 2016
Xavier Lagorce, Garrick Orchard, Francesco Galluppi, Bertram E Shi, and Ryad B Benosman. Hots: a hierar- chy of event-based time-surfaces for pattern recognition.IEEE transactions on pattern analysis and machine intelligence, 39(7):1346–1359, 2016
2016
-
[40]
EV-FlowNet: Self-Supervised Optical Flow Estimation for Event-based Cameras
Alex Zihao Zhu, Liangzhe Yuan, Kenneth Chaney, and Kostas Daniilidis. Ev-flownet: Self-supervised optical flow estimation for event-based cameras.arXiv preprint arXiv:1802.06898, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[41]
Learning monocular dense depth from events
Javier Hidalgo-Carri ´o, Daniel Gehrig, and Davide Scaramuzza. Learning monocular dense depth from events. In2020 International Conference on 3D Vision (3DV), pages 534–542. IEEE, 2020
2020
-
[42]
High speed and high dynamic range video with an event camera.IEEE transactions on pattern analysis and machine intelligence, 43(6):1964–1980, 2019
Henri Rebecq, Ren ´e Ranftl, Vladlen Koltun, and Davide Scaramuzza. High speed and high dynamic range video with an event camera.IEEE transactions on pattern analysis and machine intelligence, 43(6):1964–1980, 2019
1964
-
[43]
Events-to-video: Bringing modern com- puter vision to event cameras
Henri Rebecq, Ren ´e Ranftl, Vladlen Koltun, and Davide Scaramuzza. Events-to-video: Bringing modern com- puter vision to event cameras. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3857–3866, 2019
2019
-
[44]
Hats: Histograms of averaged time surfaces for robust event-based object classification
Amos Sironi, Manuele Brambilla, Nicolas Bourdis, Xavier Lagorce, and Ryad Benosman. Hats: Histograms of averaged time surfaces for robust event-based object classification. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1731–1740, 2018
2018
-
[45]
Learning dense and continuous optical flow from an event camera
Zhexiong Wan, Yuchao Dai, and Yuxin Mao. Learning dense and continuous optical flow from an event camera. IEEE Transactions on Image Processing, 31:7237–7251, 2022
2022
-
[46]
Krishna Vinod, Prithvi Jai Ramesh, Bharatesh Chakravarthi, et al. Sebvs: Synthetic event-based visual servoing for robot navigation and manipulation.arXiv preprint arXiv:2508.17643, 2025
-
[47]
Efficient event-based robotic grasping perception using hyperdimensional computing.Internet of Things, 26: 101207, 2024
Eman Hassan, Zhuowen Zou, Hanning Chen, Mohsen Imani, Yahya Zweiri, Hani Saleh, and Baker Mohammad. Efficient event-based robotic grasping perception using hyperdimensional computing.Internet of Things, 26: 101207, 2024
2024
-
[48]
Event-based robotic grasping detection with neuromorphic vision sensor and event-grasping dataset.Frontiers in neurorobotics, 14:51, 2020
Bin Li, Hu Cao, Zhongnan Qu, Yingbai Hu, Zhenke Wang, and Zichen Liang. Event-based robotic grasping detection with neuromorphic vision sensor and event-grasping dataset.Frontiers in neurorobotics, 14:51, 2020
2020
-
[49]
Neuromorphic eye-in-hand visual servoing.IEEE Access, 9:55853–55870, 2021
Rajkumar Muthusamy, Abdulla Ayyad, Mohamad Halwani, Dewald Swart, Dongming Gan, Lakmal Seneviratne, and Yahya Zweiri. Neuromorphic eye-in-hand visual servoing.IEEE Access, 9:55853–55870, 2021
2021
-
[50]
Force-evt: A closer look at robotic gripper force measurement with event-based vision transformer
Qianyu Guo, Ziqing Yu, Jiaming Fu, Yawen Lu, Yahya Zweiri, and Dongming Gan. Force-evt: A closer look at robotic gripper force measurement with event-based vision transformer. In2024 6th International Conference on Reconfigurable Mechanisms and Robots (ReMAR), pages 608–613. IEEE, 2024
2024
-
[51]
Event-based fusion for motion deblurring with cross-modal attention
Lei Sun, Christos Sakaridis, Jingyun Liang, Qi Jiang, Kailun Yang, Peng Sun, Yaozu Ye, Kaiwei Wang, and Luc Van Gool. Event-based fusion for motion deblurring with cross-modal attention. InEuropean conference on computer vision, pages 412–428. Springer, 2022
2022
-
[52]
Gs-evt: Cross-modal event camera tracking based on gaussian splatting
Tao Liu, Runze Yuan, Yi’ang Ju, Xun Xu, Jiaqi Yang, Xiangting Meng, Xavier Lagorce, and Laurent Kneip. Gs-evt: Cross-modal event camera tracking based on gaussian splatting. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 4587–4593. IEEE, 2025
2025
-
[53]
Eventgpt: Event stream understanding with multimodal large language models
Shaoyu Liu, Jianing Li, Guanghui Zhao, Yunjian Zhang, Xin Meng, Fei Richard Yu, Xiangyang Ji, and Ming Li. Eventgpt: Event stream understanding with multimodal large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29139–29149, 2025
2025
-
[54]
Eventvggt: Exploring cross-modal distillation for consistent event-based depth estimation
Yinrui Ren, Jinjing Zhu, Kanghao Chen, Zhuoxiao Li, Jing Ou, Zidong Cao, Tongyan Hua, Peilun Shi, Yingchun Fu, Wufan Zhao, et al. Eventvggt: Exploring cross-modal distillation for consistent event-based depth estimation. arXiv preprint arXiv:2603.09385, 2026
-
[55]
Ev-segnet: Semantic segmentation for event-based cameras
Inigo Alonso and Ana C Murillo. Ev-segnet: Semantic segmentation for event-based cameras. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 0–0, 2019
2019
-
[56]
N-imagenet: Towards robust, fine-grained object recognition with event cameras
Junho Kim, Jaehyeok Bae, Gangin Park, Dongsu Zhang, and Young Min Kim. N-imagenet: Towards robust, fine-grained object recognition with event cameras. InProceedings of the IEEE/CVF international conference on computer vision, pages 2146–2156, 2021
2021
-
[57]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776– 44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776– 44791, 2023
2023
-
[58]
v2e: From video frames to realistic dvs events
Yuhuang Hu, Shih-Chii Liu, and Tobi Delbruck. v2e: From video frames to realistic dvs events. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1312–1321, 2021
2021
-
[59]
Dsec: A stereo event camera dataset for driving scenarios.IEEE Robotics and Automation Letters, 6(3):4947–4954, 2021
Mathias Gehrig, Willem Aarents, Daniel Gehrig, and Davide Scaramuzza. Dsec: A stereo event camera dataset for driving scenarios.IEEE Robotics and Automation Letters, 6(3):4947–4954, 2021. 11 Event-VLA: Action-Conditioned Event Fusion for Robust Vision-Language-Action Model
2021
-
[60]
Esim: an open event camera simulator
Henri Rebecq, Daniel Gehrig, and Davide Scaramuzza. Esim: an open event camera simulator. InConference on robot learning, pages 969–982. PMLR, 2018
2018
-
[61]
Blinkvision: A benchmark for optical flow, scene flow and point tracking estimation using rgb frames and events
Yijin Li, Yichen Shen, Zhaoyang Huang, Shuo Chen, Weikang Bian, Xiaoyu Shi, Fu-Yun Wang, Keqiang Sun, Hujun Bao, Zhaopeng Cui, et al. Blinkvision: A benchmark for optical flow, scene flow and point tracking estimation using rgb frames and events. InEuropean conference on computer vision, pages 19–36. Springer, 2024
2024
-
[62]
V2ce: Video to continuous events simulator
Zhongyang Zhang, Shuyang Cui, Kaidong Chai, Haowen Yu, Subhasis Dasgupta, Upal Mahbub, and Tauhidur Rahman. V2ce: Video to continuous events simulator. In2024 IEEE international conference on robotics and automation (ICRA), pages 12455–12461. IEEE, 2024
2024
-
[63]
Pris- matic vlms: Investigating the design space of visually-conditioned language models
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, and Dorsa Sadigh. Pris- matic vlms: Investigating the design space of visually-conditioned language models. InForty-first International Conference on Machine Learning, 2024
2024
-
[64]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024. ...
2024
-
[65]
None” variant removes event prediction regularization and trains only with the action prediction loss. The “w/o mask
Common queries provide task- level context, action queries condition action-oriented routing, and event queries support event-oriented routing and the auxiliary future-PREI prediction objective. The input to the pretrained VLA backbone is Xt = [Z v t ;z s t ;Z ℓ;Z a 0 ;Q c 0;Q a 0;Q e 0],(32) whereZ v t denotes RGB visual tokens,z s t denotes the proprioc...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.