From Refusal to Recovery: A Control-Theoretic Approach to Generative AI Guardrails
Pith reviewed 2026-05-21 20:39 UTC · model grok-4.3
The pith
Control theory turns AI refusals into real-time corrections that prevent harm.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
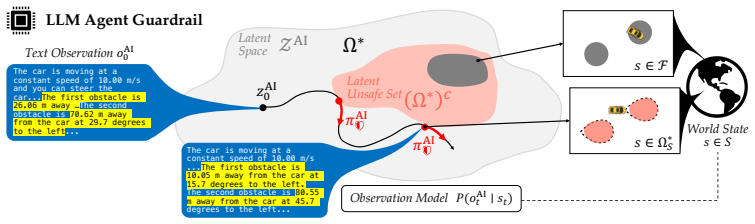
The authors argue that agentic AI safety arises from the evolving sequence of interactions between the AI and the world, and can therefore be formalized using safety-critical control theory inside the AI model's latent representation. This formalization yields predictive guardrails that monitor outputs in real time and proactively replace unsafe actions with safe ones in a model-agnostic manner. The guardrails are trained at scale through safety-critical reinforcement learning, enabling them to steer LLM agents away from catastrophic outcomes such as collisions or bankruptcy.
What carries the argument
Safety-critical control theory applied to the AI model's latent world representation, which supplies real-time predictive monitoring and correction of actions without requiring model internals or explicit dynamics.
If this is right
- Driving agents receive proactive corrections to steering and acceleration that prevent collisions before they occur.
- E-commerce agents receive spending or bidding adjustments that avert bankruptcy while completing purchases.
- The identical guardrail structure can be applied to different base models without retraining or internal access.
- Task performance metrics remain comparable to unguarded agents.
- Safety shifts from static refusal to dynamic recovery within ongoing sequences of actions.
Where Pith is reading between the lines
- The same latent-control layer could be tested in medical or legal agent settings to intercept harmful advice before it reaches users.
- Because the method is model-agnostic, it could become a reusable safety wrapper deployed across many commercial AI services.
- Integration with classical robotic control loops might produce hybrid systems that coordinate digital decisions with physical actuators.
- New experiments could measure how well the guardrails generalize to hazard types absent from the reinforcement-learning training distribution.
Load-bearing premise
That safety-critical control can be applied effectively inside the AI model's latent representation of the world in a model-agnostic way that does not need the true model internals or world dynamics.
What would settle it
A controlled driving simulation in which the guardrail is active yet the agent still collides with an obstacle or the overall task success rate falls markedly below the unguarded baseline.
Figures





read the original abstract
Generative AI systems are increasingly assisting and acting on behalf of end users in practical settings, from digital shopping assistants to next-generation autonomous cars. In this context, safety is no longer about blocking harmful content, but about preempting downstream hazards like financial or physical harm. Yet, most AI guardrails continue to rely on output classification based on labeled datasets and human-specified criteria,making them brittle to new hazardous situations. Even when unsafe conditions are flagged, this detection offers no path to recovery: typically, the AI system simply refuses to act--which is not always a safe choice. In this work, we argue that agentic AI safety is fundamentally a sequential decision problem: harmful outcomes arise from the AI system's continually evolving interactions and their downstream consequences on the world. We formalize this through the lens of safety-critical control theory, but within the AI model's latent representation of the world. This enables us to build predictive guardrails that (i) monitor an AI system's outputs (actions) in real time and (ii) proactively correct risky outputs to safe ones, all in a model-agnostic manner so the same guardrail can be wrapped around any AI model. We also offer a practical training recipe for computing such guardrails at scale via safety-critical reinforcement learning. Our experiments in simulated driving and e-commerce settings demonstrate that control-theoretic guardrails can reliably steer LLM agents clear of catastrophic outcomes (from collisions to bankruptcy) while preserving task performance, offering a principled dynamic alternative to today's flag-and-block guardrails.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that agentic AI safety is a sequential decision problem best addressed via safety-critical control theory applied inside an LLM's latent world representation. This yields model-agnostic predictive guardrails that monitor outputs in real time and proactively correct risky actions to safe ones, trained at scale with safety-critical RL. Experiments in simulated driving and e-commerce are said to show reliable avoidance of catastrophes (collisions, bankruptcy) while preserving task performance, providing a dynamic alternative to flag-and-block guardrails.
Significance. If the central technical claims hold, the work would offer a principled, recovery-oriented alternative to current refusal-based guardrails and could be broadly applicable because of the claimed model-agnostic property. The explicit use of control-theoretic invariants and a scalable RL training recipe are potential strengths if they are shown to be reproducible and to satisfy the necessary controllability conditions.
major comments (2)
- [Abstract] Abstract: The central claim that safety-critical control can be performed 'within the AI model's latent representation of the world' while remaining 'model-agnostic' (so that the guardrail 'can be wrapped around any AI model') is load-bearing for the entire contribution. Standard barrier-function or predictive-control methods require either explicit dynamics or a faithful embedding of state transitions; the manuscript provides no derivation showing how an arbitrary LLM's latent space satisfies the controllability or invariance conditions needed for guaranteed recovery when only token outputs are observable.
- [Experimental evaluation] Experimental evaluation (simulated driving and e-commerce): The reported success in steering agents clear of catastrophic outcomes rests on unspecified details of how latent states are extracted, how the control law is applied, and what data-exclusion or hyper-parameter rules were used. Without these, it is impossible to assess whether the results demonstrate the claimed model-agnostic property or merely reflect access to internal activations in the simulated environments.
minor comments (1)
- [Abstract] The abstract refers to 'safety-critical reinforcement learning' without indicating how the safety-critical objective is encoded (e.g., via control barrier functions, constrained policy optimization, or another formulation). A brief statement of the precise objective would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which identify key areas where the manuscript can be strengthened in both theoretical grounding and experimental transparency. We address each major comment below and outline corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that safety-critical control can be performed 'within the AI model's latent representation of the world' while remaining 'model-agnostic' (so that the guardrail 'can be wrapped around any AI model') is load-bearing for the entire contribution. Standard barrier-function or predictive-control methods require either explicit dynamics or a faithful embedding of state transitions; the manuscript provides no derivation showing how an arbitrary LLM's latent space satisfies the controllability or invariance conditions needed for guaranteed recovery when only token outputs are observable.
Authors: We agree that a complete theoretical derivation establishing controllability and invariance for arbitrary LLM latent spaces would strengthen the claims. The manuscript presents the latent space as an empirical proxy for the world state, with safety-critical RL used to learn approximate control barrier functions that enforce recovery in practice. The model-agnostic aspect is operational: the guardrail operates on extracted latents and token outputs without requiring model-specific retraining or internal weight access. We do not claim formal guarantees for every possible embedding; instead, we demonstrate empirical satisfaction of recovery conditions in the evaluated domains. In revision, we will add a new subsection in the methods that explicitly states the assumptions on the latent embedding, discusses when invariance may hold approximately, and clarifies the distinction between theoretical guarantees and the practical, learned approach. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation (simulated driving and e-commerce): The reported success in steering agents clear of catastrophic outcomes rests on unspecified details of how latent states are extracted, how the control law is applied, and what data-exclusion or hyper-parameter rules were used. Without these, it is impossible to assess whether the results demonstrate the claimed model-agnostic property or merely reflect access to internal activations in the simulated environments.
Authors: We concur that the current experimental description lacks sufficient implementation detail to allow full assessment of reproducibility and the model-agnostic claim. The simulations provide full access to model internals for the purpose of validating the control-theoretic method, but the guardrail itself is trained and applied using only the latent representations and output tokens. In the revised manuscript we will expand the experimental section with: (i) the precise layer(s) from which latent states are extracted, (ii) the procedure for projecting control corrections back into the token vocabulary, (iii) the full hyper-parameter table and data-exclusion protocol used during safety-critical RL training, and (iv) an explicit statement that the same guardrail architecture and training recipe can be applied to any model from which comparable latent states can be obtained. These additions will make clear that the reported performance is not an artifact of privileged simulation access but follows from the control law operating on the latent representation. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper frames agentic AI safety as a sequential decision problem and applies safety-critical control theory inside the LLM's latent representation to enable model-agnostic predictive guardrails, with a training recipe via safety-critical RL and experimental demonstrations in driving and e-commerce simulations. No load-bearing steps reduce by construction to fitted parameters, self-definitions, or self-citation chains; the central claims rest on external control-theoretic foundations and RL methods rather than tautological renaming or input-equivalent predictions. The approach is presented as building outward from established theory without the derivation looping back to its own fitted outputs or unverified self-citations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Webarena: A realistic web environment for building autonomous agents,
S. Zhou, F. F. Xu, H. Zhu, X. Zhou, R. Lo, A. Sridhar, X. Cheng, T. Ou, Y . Bisk, D. Friedet al., “Webarena: A realistic web environment for building autonomous agents,” inInternational Conference on Learning Representations, 2024
work page 2024
-
[2]
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
J. Y . Koh, R. Lo, L. Jang, V . Duvvur, M. C. Lim, P.-Y . Huang, G. Neubig, S. Zhou, R. Salakhut- dinov, and D. Fried, “Visualwebarena: Evaluating multimodal agents on realistic visual web tasks,”arXiv preprint arXiv:2401.13649, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Buy it in chatgpt: Instant checkout and the agentic commerce protocol,
OpenAI, “Buy it in chatgpt: Instant checkout and the agentic commerce protocol,” https://openai.com/index/buy-it-in-chatgpt/, September 2025
work page 2025
-
[4]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “Swe-bench: Can language models resolve real-world github issues?”arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Coding agents with multimodal browsing are generalist problem solvers,
A. B. Soni, B. Li, X. Wang, V . Chen, and G. Neubig, “Coding agents with multimodal browsing are generalist problem solvers,”arXiv preprint arXiv:2506.03011, 2025
-
[6]
Driving everywhere with large language model policy adaptation,
B. Li, Y . Wang, J. Mao, B. Ivanovic, S. Veer, K. Leung, and M. Pavone, “Driving everywhere with large language model policy adaptation,” 2024
work page 2024
-
[7]
Timing the message: Language-based notifications for time-critical assistive settings,
Y .-C. Hsu, J. DeCastro, A. Silva, and G. Rosman, “Timing the message: Language-based notifications for time-critical assistive settings,”arXiv preprint arXiv:2509.07438, 2025
-
[8]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketiet al., “Openvla: An open-source vision-language-action model,”arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Dolphins: Multimodal language model for driving,
Y . Ma, Y . Cao, J. Sun, M. Pavone, and C. Xiao, “Dolphins: Multimodal language model for driving,” 2023
work page 2023
-
[10]
Gemini Robotics: Bringing AI into the Physical World
T. Gemini Robotics, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, T. Armstrong, A. Balakrishna, R. Baruch, M. Bauza, M. Blokzijlet al., “Gemini robotics: Bringing ai into the physical world,”arXiv preprint arXiv:2503.20020, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Navigating the ai frontier: A primer on the evolution and impact of ai agents
B. Larsen, C. Li, S. Teeuwen, O. Denti, J. DePerro, and E. Raili, “Navigating the ai frontier: A primer on the evolution and impact of ai agents.” Technical report, World Economic Forum, 2024
work page 2024
-
[12]
The singapore consensus on global ai safety research priorities,
Y . Bengio, T. Maharaj, L. Ong, S. Russell, D. Song, M. Tegmark, L. Xue, Y .-Q. Zhang, S. Casper, W. S. Leeet al., “The singapore consensus on global ai safety research priorities,”arXiv preprint arXiv:2506.20702, 2025
-
[13]
An approach to technical agi safety and security,
R. Shah, A. Irpan, A. M. Turner, A. Wang, A. Conmy, D. Lindner, J. Brown-Cohen, L. Ho, N. Nanda, R. A. Popaet al., “An approach to technical agi safety and security,”arXiv preprint arXiv:2504.01849, 2025. 11
-
[14]
Nemo guardrails: A toolkit for controllable and safe llm applications with programmable rails,
T. Rebedea, R. Dinu, M. Sreedhar, C. Parisien, and J. Cohen, “Nemo guardrails: A toolkit for controllable and safe llm applications with programmable rails,”arXiv preprint arXiv:2310.10501, 2023
-
[15]
Current state of llm risks and ai guardrails,
S. G. Ayyamperumal and L. Ge, “Current state of llm risks and ai guardrails,”arXiv preprint arXiv:2406.12934, 2024
-
[16]
Building guardrails for large language models,
Y . Dong, R. Mu, G. Jin, Y . Qi, J. Hu, X. Zhao, J. Meng, W. Ruan, and X. Huang, “Building guardrails for large language models,”ICML, 2024
work page 2024
-
[17]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
H. Inan, K. Upasani, J. Chi, R. Rungta, K. Iyer, Y . Mao, M. Tontchev, Q. Hu, B. Fuller, D. Tes- tuggineet al., “Llama guard: Llm-based input-output safeguard for human-ai conversations,” arXiv preprint arXiv:2312.06674, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Preemptive detection and steering of llm misalignment via latent reachability,
S. Karnik and S. Bansal, “Preemptive detection and steering of llm misalignment via latent reachability,”arXiv preprint arXiv:2509.21528, 2025
-
[19]
The safety filter: A unified view of safety-critical control in autonomous systems,
K.-C. Hsu, H. Hu, and J. F. Fisac, “The safety filter: A unified view of safety-critical control in autonomous systems,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 7, 2024
work page 2024
-
[20]
K. P. Wabersich, A. J. Taylor, J. J. Choi, K. Sreenath, C. J. Tomlin, A. D. Ames, and M. N. Zeilinger, “Data-driven safety filters: Hamilton-jacobi reachability, control barrier functions, and predictive methods for uncertain systems,”IEEE Control Systems Magazine, vol. 43, no. 5, pp. 137–177, 2023
work page 2023
-
[21]
Hamilton-jacobi reachability: A brief overview and recent advances,
S. Bansal, M. Chen, S. Herbert, and C. J. Tomlin, “Hamilton-jacobi reachability: A brief overview and recent advances,” in2017 IEEE 56th Annual Conference on Decision and Control (CDC). IEEE, 2017, pp. 2242–2253
work page 2017
-
[22]
Control barrier functions: Theory and applications,
A. D. Ames, S. Coogan, M. Egerstedt, G. Notomista, K. Sreenath, and P. Tabuada, “Control barrier functions: Theory and applications,” in2019 18th European control conference (ECC). Ieee, 2019, pp. 3420–3431
work page 2019
-
[23]
Safe reinforcement learning with nonlinear dynamics via model predictive shield- ing,
O. Bastani, “Safe reinforcement learning with nonlinear dynamics via model predictive shield- ing,” in2021 American control conference (ACC). IEEE, 2021, pp. 3488–3494
work page 2021
-
[24]
M. K. Rad, H. Nghiem, A. Luo, S. Wadhwa, M. Sorower, and S. Rawls, “Refining input guardrails: Enhancing llm-as-a-judge efficiency through chain-of-thought fine-tuning and alignment,”arXiv preprint arXiv:2501.13080, 2025
-
[25]
Constrained Decoding for Safe Robot Navigation Foundation Models
P. Kapoor, A. Ganlath, C. Liu, S. Scherer, and E. Kang, “Constrained decoding for robotics foundation models,”arXiv preprint arXiv:2509.01728, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Detecting Language Model Attacks with Perplexity
G. Alon and M. Kamfonas, “Detecting language model attacks with perplexity,”arXiv preprint arXiv:2308.14132, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Measuring and mitigating unintended bias in text classification,
L. Dixon, J. Li, J. Sorensen, N. Thain, and L. Vasserman, “Measuring and mitigating unintended bias in text classification,” inProceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, 2018, pp. 67–73
work page 2018
-
[28]
Toxicchat: Unveiling hidden challenges of toxicity detection in real-world user-ai conversation,
Z. Lin, Z. Wang, Y . Tong, Y . Wang, Y . Guo, Y . Wang, and J. Shang, “Toxicchat: Unveiling hidden challenges of toxicity detection in real-world user-ai conversation,”arXiv preprint arXiv:2310.17389, 2023
-
[29]
Red teaming language models with language models,
E. Perez, S. Huang, F. Song, T. Cai, R. Ring, J. Aslanides, A. Glaese, N. McAleese, and G. Irving, “Red teaming language models with language models,”Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing,, 2022
work page 2022
-
[30]
Cbf-llm: Safe control for llm alignment,
Y . Miyaoka and M. Inoue, “Cbf-llm: Safe control for llm alignment,”arXiv preprint arXiv:2408.15625, 2024
-
[31]
Steering dialogue dynamics for robustness against multi-turn jailbreaking attacks,
H. Hu, A. Robey, and C. Liu, “Steering dialogue dynamics for robustness against multi-turn jailbreaking attacks,” inICML 2025 Workshop on Reliable and Responsible Foundation Models, 2025. 12
work page 2025
-
[32]
Aligning large language models with representation editing: A control perspective,
L. Kong, H. Wang, W. Mu, Y . Du, Y . Zhuang, Y . Zhou, Y . Song, R. Zhang, K. Wang, and C. Zhang, “Aligning large language models with representation editing: A control perspective,” Advances in Neural Information Processing Systems, vol. 37, pp. 37 356–37 384, 2024
work page 2024
-
[33]
Learning safety constraints for large language models,
X. Chen, Y . As, and A. Krause, “Learning safety constraints for large language models,” International Conference on Machine Learning, 2025
work page 2025
-
[34]
GuardAgent: Safeguard LLM Agents by a Guard Agent via Knowledge-Enabled Reasoning
Z. Xiang, L. Zheng, Y . Li, J. Hong, Q. Li, H. Xie, J. Zhang, Z. Xiong, C. Xie, C. Yanget al., “Guardagent: Safeguard llm agents by a guard agent via knowledge-enabled reasoning,”arXiv preprint arXiv:2406.09187, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Shieldagent: Shielding agents via verifiable safety policy reasoning,
Z. Chen, M. Kang, and B. Li, “Shieldagent: Shielding agents via verifiable safety policy reasoning,” inForty-second International Conference on Machine Learning, 2025
work page 2025
-
[36]
Webguard: Building a generalizable guardrail for web agents,
B. Zheng, Z. Liao, S. Salisbury, Z. Liu, M. Lin, Q. Zheng, Z. Wang, X. Deng, D. Song, H. Sunet al., “Webguard: Building a generalizable guardrail for web agents,”arXiv preprint arXiv:2507.14293, 2025
-
[37]
Learning-based model predictive control: Toward safe learning in control,
L. Hewing, K. P. Wabersich, M. Menner, and M. N. Zeilinger, “Learning-based model predictive control: Toward safe learning in control,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 3, no. 1, pp. 269–296, 2020
work page 2020
-
[38]
A time-dependent hamilton-jacobi formulation of reachable sets for continuous dynamic games,
I. M. Mitchell, A. M. Bayen, and C. J. Tomlin, “A time-dependent hamilton-jacobi formulation of reachable sets for continuous dynamic games,”IEEE Transactions on automatic control, vol. 50, no. 7, pp. 947–957, 2005
work page 2005
-
[39]
Hamilton–jacobi formulation for reach–avoid differential games,
K. Margellos and J. Lygeros, “Hamilton–jacobi formulation for reach–avoid differential games,” IEEE Transactions on automatic control, vol. 56, no. 8, pp. 1849–1861, 2011
work page 2011
-
[40]
Reach-avoid problems with time-varying dynamics, targets and constraints,
J. F. Fisac, M. Chen, C. J. Tomlin, and S. S. Sastry, “Reach-avoid problems with time-varying dynamics, targets and constraints,” inProceedings of the 18th international conference on hybrid systems: computation and control, 2015, pp. 11–20
work page 2015
-
[41]
Robust online motion planning via con- traction theory and convex optimization,
S. Singh, A. Majumdar, J.-J. Slotine, and M. Pavone, “Robust online motion planning via con- traction theory and convex optimization,” in2017 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2017, pp. 5883–5890
work page 2017
-
[42]
Learning safe multi-agent control with decentralized neural barrier certificates,
Z. Qin, K. Zhang, Y . Chen, J. Chen, and C. Fan, “Learning safe multi-agent control with decentralized neural barrier certificates,”arXiv preprint arXiv:2101.05436, 2021
-
[43]
Y . Chen, A. Singletary, and A. D. Ames, “Guaranteed obstacle avoidance for multi-robot operations with limited actuation: A control barrier function approach,”IEEE Control Systems Letters, vol. 5, no. 1, pp. 127–132, 2020
work page 2020
-
[44]
J. Li, Q. Liu, W. Jin, J. Qin, and S. Hirche, “Robust safe learning and control in an unknown environment: An uncertainty-separated control barrier function approach,”IEEE Robotics and Automation Letters, vol. 8, no. 10, pp. 6539–6546, 2023
work page 2023
-
[45]
Safe nonlinear control using robust neural lyapunov- barrier functions,
C. Dawson, Z. Qin, S. Gao, and C. Fan, “Safe nonlinear control using robust neural lyapunov- barrier functions,” inConference on Robot Learning. PMLR, 2022, pp. 1724–1735
work page 2022
-
[46]
Safe exploration algorithms for reinforcement learning controllers,
T. Mannucci, E.-J. Van Kampen, C. De Visser, and Q. Chu, “Safe exploration algorithms for reinforcement learning controllers,”IEEE transactions on neural networks and learning systems, vol. 29, no. 4, pp. 1069–1081, 2017
work page 2017
-
[47]
The flexible, extensible and efficient toolbox of level set methods,
I. M. Mitchell, “The flexible, extensible and efficient toolbox of level set methods,”Journal of Scientific Computing, vol. 35, no. 2, pp. 300–329, 2008
work page 2008
-
[48]
Control in a safe set: Addressing safety in human-robot interactions,
C. Liu and M. Tomizuka, “Control in a safe set: Addressing safety in human-robot interactions,” inDynamic Systems and Control Conference, vol. 46209. American Society of Mechanical Engineers, 2014, p. V003T42A003
work page 2014
-
[49]
Control barrier function based quadratic programs for safety critical systems,
A. D. Ames, X. Xu, J. W. Grizzle, and P. Tabuada, “Control barrier function based quadratic programs for safety critical systems,”IEEE Transactions on Automatic Control, vol. 62, no. 8, pp. 3861–3876, 2016. 13
work page 2016
-
[50]
A predictive safety filter for learning-based control of constrained nonlinear dynamical systems,
K. P. Wabersich and M. N. Zeilinger, “A predictive safety filter for learning-based control of constrained nonlinear dynamical systems,”Automatica, vol. 129, no. C, Jul. 2021. [Online]. Available: https://doi.org/10.1016/j.automatica.2021.109597
-
[51]
Bridging hamilton- jacobi safety analysis and reinforcement learning,
J. F. Fisac, N. F. Lugovoy, V . Rubies-Royo, S. Ghosh, and C. J. Tomlin, “Bridging hamilton- jacobi safety analysis and reinforcement learning,” in2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 8550–8556
work page 2019
-
[52]
Safety and liveness guarantees through reach-avoid reinforcement learning,
K.-C. Hsu, V . Rubies-Royo, C. J. Tomlin, and J. F. Fisac, “Safety and liveness guarantees through reach-avoid reinforcement learning,”arXiv preprint arXiv:2112.12288, 2021
-
[53]
Isaacs: Iterative soft adversarial actor-critic for safety,
K.-C. Hsu, D. P. Nguyen, and J. F. Fisac, “Isaacs: Iterative soft adversarial actor-critic for safety,” inLearning for Dynamics and Control Conference. PMLR, 2023, pp. 90–103
work page 2023
-
[54]
Deepreach: A deep learning approach to high-dimensional reachabil- ity,
S. Bansal and C. Tomlin, “Deepreach: A deep learning approach to high-dimensional reachabil- ity,”ICRA, 2020
work page 2020
-
[55]
One filter to deploy them all: Robust safety for quadrupedal navigation in unknown environments,
A. Lin, S. Peng, and S. Bansal, “One filter to deploy them all: Robust safety for quadrupedal navigation in unknown environments,”arXiv preprint arXiv:2412.09989, 2024
-
[56]
Agile but safe: Learning collision-free high-speed legged locomotion,
T. He, C. Zhang, W. Xiao, G. He, C. Liu, and G. Shi, “Agile but safe: Learning collision-free high-speed legged locomotion,”Robotics: Science and Systems, 2024
work page 2024
-
[57]
Generalizing safety beyond collision-avoidance via latent-space reachability analysis,
K. Nakamura, L. Peters, and A. Bajcsy, “Generalizing safety beyond collision-avoidance via latent-space reachability analysis,”Robotics: Science and Systems, 2025
work page 2025
-
[58]
Uncertainty-aware latent safety filters for avoiding out-of-distribution failures,
J. Seo, K. Nakamura, and A. Bajcsy, “Uncertainty-aware latent safety filters for avoiding out-of-distribution failures,”Conference on Robot Learning, 2025
work page 2025
-
[59]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow instructions with human feedback,” Advances in neural information processing systems, vol. 35, pp. 27 730–27 744, 2022
work page 2022
-
[60]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Y . Bai, A. Jones, K. Ndousse, A. Askell, A. Chen, N. DasSarma, D. Drain, S. Fort, D. Ganguli, T. Henighanet al., “Training a helpful and harmless assistant with reinforcement learning from human feedback,”arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[61]
Archer: Training language model agents via hierarchical multi-turn rl,
Y . Zhou, A. Zanette, J. Pan, S. Levine, and A. Kumar, “Archer: Training language model agents via hierarchical multi-turn rl,”arXiv preprint arXiv:2402.19446, 2024
-
[62]
Webrl: Training llm web agents via self-evolving online curriculum reinforcement learning,
Z. Qi, X. Liu, I. L. Iong, H. Lai, X. Sun, W. Zhao, Y . Yang, X. Yang, J. Sun, S. Yaoet al., “Webrl: Training llm web agents via self-evolving online curriculum reinforcement learning,” arXiv preprint arXiv:2411.02337, 2024
-
[63]
Agentgym: Evolving large language model-based agents across diverse environments,
Z. Xi, Y . Ding, W. Chen, B. Hong, H. Guo, J. Wang, D. Yang, C. Liao, X. Guo, W. Heet al., “Agentgym: Evolving large language model-based agents across diverse environments,”arXiv preprint arXiv:2406.04151, 2024
-
[64]
Z. Xi, J. Huang, C. Liao, B. Huang, H. Guo, J. Liu, R. Zheng, J. Ye, J. Zhang, W. Chen et al., “Agentgym-rl: Training llm agents for long-horizon decision making through multi-turn reinforcement learning,”arXiv preprint arXiv:2509.08755, 2025
-
[65]
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
Z. Wang, K. Wang, Q. Wang, P. Zhang, L. Li, Z. Yang, X. Jin, K. Yu, M. N. Nguyen, L. Liu et al., “Ragen: Understanding self-evolution in llm agents via multi-turn reinforcement learning,” arXiv preprint arXiv:2504.20073, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
R. Isaacs,Differential Games: A Mathematical Theory with Applications to Warfare and Pursuit, Control and Optimization, revised edition ed. Mineola, N.Y: Dover Publications, 1965
work page 1965
-
[67]
The bellman equation for minimizing the maximum cost
E. Barron and H. Ishii, “The bellman equation for minimizing the maximum cost.”NONLINEAR ANAL. THEORY METHODS APPLIC., vol. 13, no. 9, pp. 1067–1090, 1989
work page 1989
-
[68]
A game theoretic approach to controller design for hybrid systems,
C. Tomlin, J. Lygeros, and S. Shankar Sastry, “A game theoretic approach to controller design for hybrid systems,”Proceedings of the IEEE, vol. 88, no. 7, pp. 949–970, 2000. 14
work page 2000
-
[69]
On reachability and minimum cost optimal control,
J. Lygeros, “On reachability and minimum cost optimal control,”Automatica, vol. 40, no. 6, pp. 917–927, 2004
work page 2004
-
[70]
Fine-Tuning Language Models from Human Preferences
D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Radford, D. Amodei, P. Christiano, and G. Irv- ing, “Fine-tuning language models from human preferences,”arXiv preprint arXiv:1909.08593, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[71]
The Curious Case of Neural Text Degeneration
A. Holtzman, J. Buys, L. Du, M. Forbes, and Y . Choi, “The curious case of neural text degeneration,”arXiv preprint arXiv:1904.09751, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[72]
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fanet al., “The llama 3 herd of models,”arXiv e-prints, pp. arXiv–2407, 2024
work page 2024
-
[73]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models. arxiv 2021,”arXiv preprint arXiv:2106.09685, vol. 10, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[74]
Robots that ask for help: Uncertainty alignment for large language model planners,
A. Z. Ren, A. Dixit, A. Bodrova, S. Singh, S. Tu, N. Brown, P. Xu, L. Takayama, F. Xia, J. Varleyet al., “Robots that ask for help: Uncertainty alignment for large language model planners,” inConference on Robot Learning. PMLR, 2023, pp. 661–682
work page 2023
-
[75]
X. Sun, Y . Zhang, X. Tang, A. S. Bedi, and A. Bera, “Trustnavgpt: Modeling uncertainty to improve trustworthiness of audio-guided llm-based robot navigation,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 8794– 8801
work page 2024
-
[76]
Judging llm-as-a-judge with mt-bench and chatbot arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. Xinget al., “Judging llm-as-a-judge with mt-bench and chatbot arena,”Advances in neural information processing systems, vol. 36, pp. 46 595–46 623, 2023
work page 2023
-
[77]
Trl: Transformer reinforcement learning,
L. von Werra, Y . Belkada, L. Tunstall, E. Beeching, T. Thrush, N. Lambert, S. Huang, K. Rasul, and Q. Gallouédec, “Trl: Transformer reinforcement learning,” https://github.com/huggingface/ trl, 2020
work page 2020
-
[78]
OpenAI, “GPT-4o System Card,” Aug. 2024. [Online]. Available: https://openai.com/index/ gpt-4o-system-card/
work page 2024
-
[79]
Constitutional AI: Harmlessness from AI Feedback
Y . Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones, A. Chen, A. Goldie, A. Mirho- seini, C. McKinnonet al., “Constitutional ai: Harmlessness from ai feedback,”arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[80]
Generating robot constitutions & benchmarks for semantic safety,
P. Sermanet, A. Majumdar, A. Irpan, D. Kalashnikov, and V . Sindhwani, “Generating robot constitutions & benchmarks for semantic safety,”Conference on Robot Learning (CoRL) 2025, 2025, version 1. Project page: https://asimov-benchmark.github.io. [Online]. Available: https://arxiv.org/abs/2503.08663
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.