CineOrchestra: Unified Entity-Centric Conditioning for Cinematic Video Generation
Pith reviewed 2026-06-27 06:50 UTC · model grok-4.3
The pith
CineOrchestra unifies control of subjects, events, cameras and shot transitions in video generation by treating each as an entity over a temporal interval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
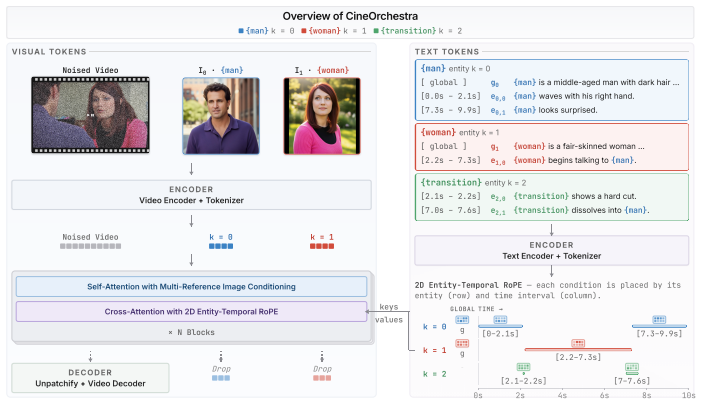
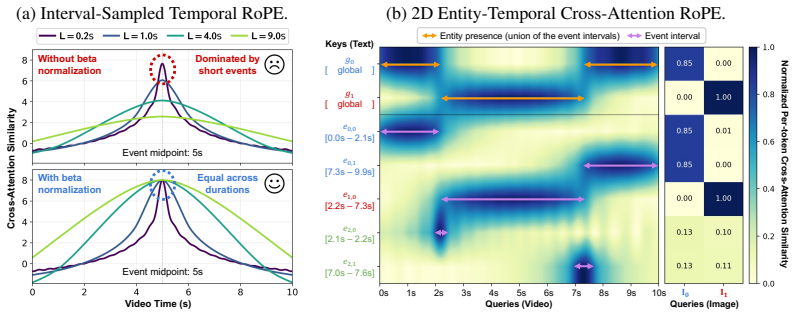
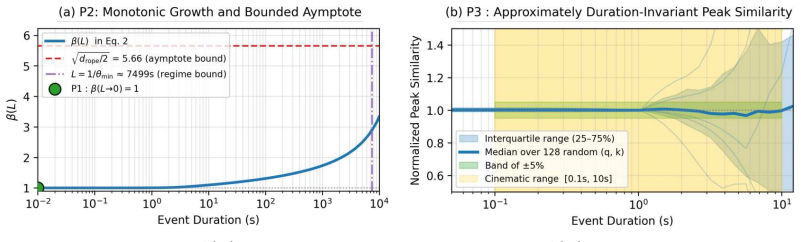
CineOrchestra is a unified video diffusion model that controls subjects, events, cameras, and shot transitions at once. The central claim is that these elements all function as entities acting over specific temporal intervals and can therefore share one conditioning structure of primitives augmented by reference images; this reduces the architectural problem to positional encoding, which the model solves with an interval-sampled temporal RoPE for consistent attention across varying durations and a 2D entity-temporal cross-attention RoPE that disambiguates per-entity conditions and routes them to the correct spatiotemporal locations.
What carries the argument
entity-centric conditioning primitives that express every cinematic element as an entity over a temporal interval, reduced to a positional encoding problem solved by two coordinated parameter-free rotary embeddings
If this is right
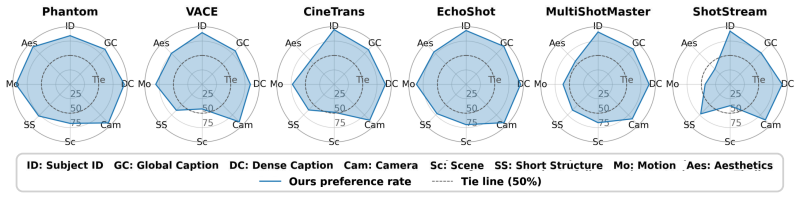
- The model outperforms six per-axis specialist models on dense caption following and shot-transition timing benchmarks.
- It produces consistent gains over baselines in pairwise user studies.
- Ablations confirm that both the interval-sampled temporal RoPE and the 2D entity-temporal RoPE contribute to the unified performance.
- The same framework simultaneously supports multi-subject personalization, temporal control, multi-shot synthesis and camera control.
Where Pith is reading between the lines
- The parameter-free RoPE design could be reused for other conditioning signals that also vary in duration without requiring new learned embeddings.
- If the entity-interval abstraction holds, similar unification might extend to audio tracks or 3D object trajectories within the same diffusion backbone.
- Longer videos with many overlapping entities would test whether the 2D cross-attention RoPE continues to route conditions correctly at scale.
Load-bearing premise
That subjects, events, cameras and shot transitions all share the same fundamental structure as entities acting over temporal intervals and therefore fit into one shared conditioning structure.
What would settle it
A cinematic control task whose required element cannot be expressed as any entity with a bounded temporal interval, such as a global lighting shift without a tied subject or event, would produce uncontrolled output or timing errors.
Figures




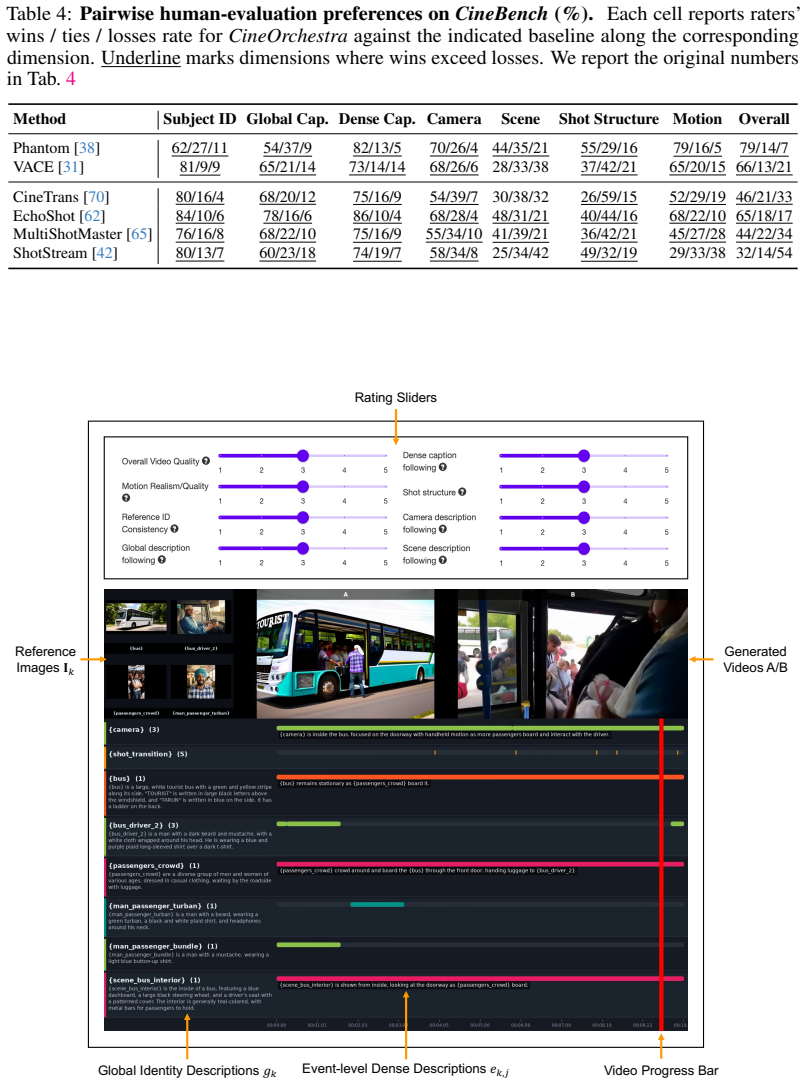






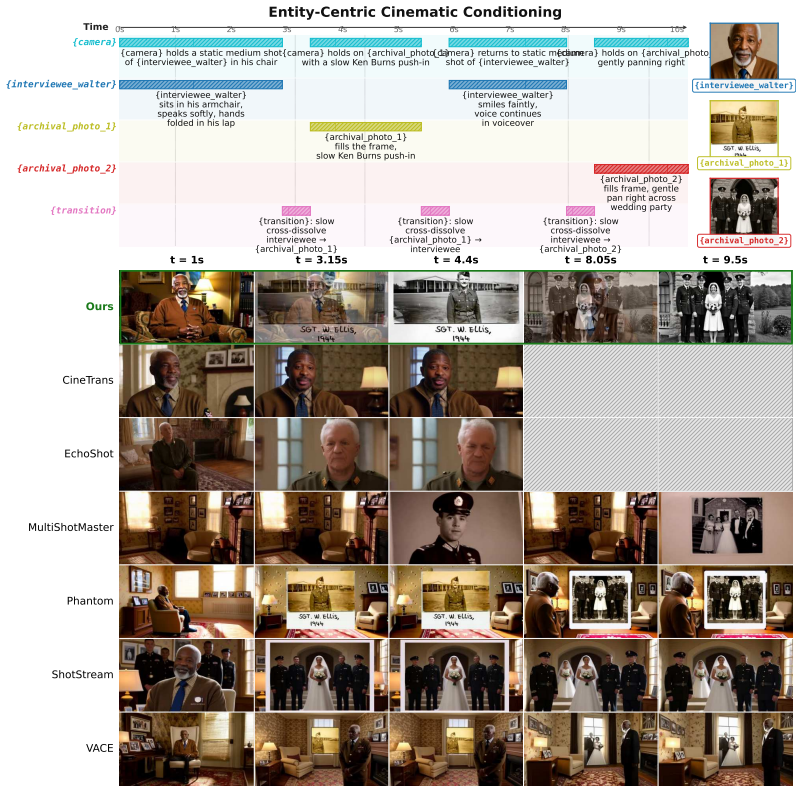
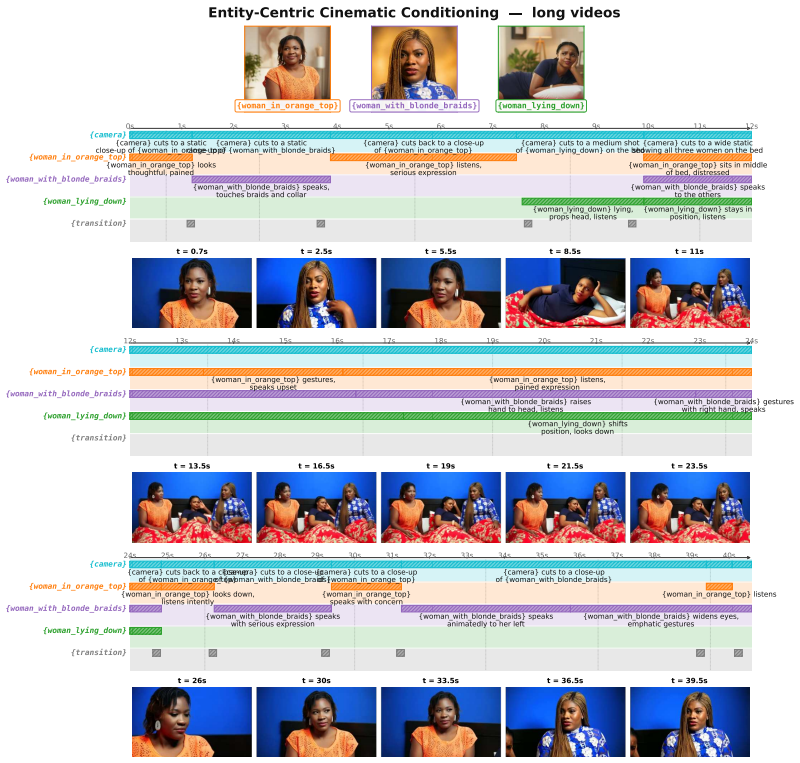

read the original abstract
Cinematic video depicts multiple subjects acting or interacting at specific moments, captured with deliberate camera movement, and stitched together by shot transitions. Together, these elements demand a level of fine-grained control beyond current text-to-video models. Existing work addresses each axis in isolation: multi-subject personalization, temporal control, multi-shot synthesis, or camera control; no prior framework jointly integrates all four. We present CineOrchestra, a unified video diffusion model that controls subjects, events, cameras, and shot transitions simultaneously. Our key insight is that these heterogeneous cinematic elements share a fundamental structure: each is an entity acting over a specific temporal interval, which can therefore all be expressed through one shared structure of entity-centric conditioning primitives, augmented with reference images for visual entities. This formulation reduces the architectural challenge to a single positional encoding problem, which we solve with two parameter-free coordinated rotary embeddings: (a) an interval-sampled temporal RoPE that yields consistent attention behavior across events of dramatically varying duration, and (b) a 2D entity-temporal cross-attention RoPE that disambiguates per-entity conditions and routes each to its corresponding spatiotemporal region. On two new benchmarks, CineOrchestra outperforms six per-axis specialists on dense caption following and shot-transition timing, with consistent gains in a pairwise user study and component ablations. Project page: https://snap-research.github.io/CineOrchestra
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CineOrchestra, a unified video diffusion model for cinematic video generation that simultaneously controls subjects, events, cameras, and shot transitions. It models these heterogeneous elements as entities acting over temporal intervals via a shared entity-centric conditioning structure augmented with reference images, reducing the problem to positional encoding solved by two parameter-free coordinated rotary embeddings: an interval-sampled temporal RoPE and a 2D entity-temporal cross-attention RoPE. The work claims outperformance over six per-axis specialist models on two new benchmarks for dense caption following and shot-transition timing, plus consistent gains in pairwise user studies and component ablations.
Significance. If the empirical claims hold, the unification via entity-centric temporal intervals would represent a meaningful advance in controllable video generation by replacing multiple specialized models with a single framework. The parameter-free character of the two RoPE variants and the introduction of new benchmarks for caption following and transition timing are explicit strengths that could facilitate reproducibility and future comparisons.
minor comments (2)
- Abstract: the claims of outperformance and 'consistent gains' are stated without any numerical metrics, error bars, dataset sizes, or specific benchmark scores, which limits immediate assessment of effect sizes even though the full results sections presumably contain them.
- The description of the two RoPE variants would benefit from an explicit equation or pseudocode block showing how interval sampling is implemented in the temporal RoPE and how the 2D cross-attention RoPE routes conditions to spatiotemporal regions.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of CineOrchestra, the recognition of its unified entity-centric approach, the parameter-free RoPE contributions, and the new benchmarks. The recommendation for minor revision is noted. No specific major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The paper presents a unification of cinematic controls via an entity-centric temporal interval structure that reduces the problem to two parameter-free RoPE variants. This builds directly on standard rotary embeddings without any fitted parameters renamed as predictions, without load-bearing self-citations for uniqueness theorems, and without ansatzes smuggled through prior work. New benchmarks are introduced rather than reusing fitted numbers from the same authors, and the derivation chain remains self-contained against external positional encoding methods.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rotary positional embeddings can be adapted to interval-sampled temporal and 2D entity-temporal cross-attention settings while remaining parameter-free and yielding consistent attention behavior.
Reference graph
Works this paper leans on
-
[1]
Ac3d: Analyzing and improving 3d camera control in video diffusion transformers
Sherwin Bahmani, Ivan Skorokhodov, Guocheng Qian, Aliaksandr Siarohin, Willi Menapace, Andrea Tagliasacchi, David B Lindell, and Sergey Tulyakov. Ac3d: Analyzing and improving 3d camera control in video diffusion transformers. InCVPR, 2025. 3, 11
2025
-
[2]
Lindell, and Sergey Tulyakov
Sherwin Bahmani, Ivan Skorokhodov, Aliaksandr Siarohin, Willi Menapace, Guocheng Qian, Michael Vasilkovsky, Hsin-Ying Lee, Chaoyang Wang, Jiaxu Zou, Andrea Tagliasacchi, David B. Lindell, and Sergey Tulyakov. VD3d: Taming large video diffusion transformers for 3d camera control. InICLR, 2025. 3
2025
-
[3]
Recammaster: Camera-controlled generative rendering from a single video
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, et al. Recammaster: Camera-controlled generative rendering from a single video. InICCV, 2025. 3, 11
2025
-
[4]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Align your latents: High-resolution video synthesis with latent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. InCVPR,
-
[6]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators. Technical report, OpenAI, 2024. 2, 3
2024
-
[7]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InICCV, 2021. 8
2021
-
[8]
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
Haoxin Chen, Menghan Xia, Yingqing He, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Jinbo Xing, Yaofang Liu, Qifeng Chen, Xintao Wang, Chao Weng, and Ying Shan. VideoCrafter1: Open diffusion models for high-quality video generation.arXiv preprint arXiv:2310.19512, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
VideoCrafter2: Overcoming data limitations for high-quality video diffusion models
Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, and Ying Shan. VideoCrafter2: Overcoming data limitations for high-quality video diffusion models. InCVPR, 2024. 3
2024
-
[10]
Tsai-Shien Chen, Chieh Hubert Lin, Hung-Yu Tseng, Tsung-Yi Lin, and Ming-Hsuan Yang. Motion- conditioned diffusion model for controllable video synthesis.arXiv preprint arXiv:2304.14404, 2023. 3
-
[11]
Panda-70m: Captioning 70m videos with multiple cross-modality teachers
Tsai-Shien Chen, Aliaksandr Siarohin, Willi Menapace, Ekaterina Deyneka, Hsiang-wei Chao, Byung Eun Jeon, Yuwei Fang, Hsin-Ying Lee, Jian Ren, Ming-Hsuan Yang, et al. Panda-70m: Captioning 70m videos with multiple cross-modality teachers. InCVPR, 2024. 3
2024
-
[12]
Multi-subject open-set personalization in video generation
Tsai-Shien Chen, Aliaksandr Siarohin, Willi Menapace, Yuwei Fang, Kwot Sin Lee, Ivan Skorokhodov, Kfir Aberman, Jun-Yan Zhu, Ming-Hsuan Yang, and Sergey Tulyakov. Multi-subject open-set personalization in video generation. InCVPR, 2025. 2, 3, 7, 8
2025
-
[13]
Omni-attribute: Open-vocabulary attribute encoder for visual concept personalization
Tsai-Shien Chen, Aliaksandr Siarohin, Guocheng Gordon Qian, Kuan-Chieh Jackson Wang, Egor Nemchi- nov, Moayed Haji-Ali, Riza Alp Guler, Willi Menapace, Ivan Skorokhodov, Anil Kag, et al. Omni-attribute: Open-vocabulary attribute encoder for visual concept personalization. InCVPR, 2026. 3
2026
-
[14]
Canvas-to-image: Compositional image generation with multimodal controls.ACM TOG, 2026
Yusuf Dalva, Guocheng Gordon Qian, Maya Goldenberg, Tsai-Shien Chen, Kfir Aberman, Sergey Tulyakov, Pinar Yanardag, and Kuan-Chieh Jackson Wang. Canvas-to-image: Compositional image generation with multimodal controls.ACM TOG, 2026. 3
2026
-
[15]
MAGREF: Masked guidance for any-reference video generation with subject disentanglement
Yufan Deng, Yuanyang Yin, Xun Guo, Yizhi Wang, Jacob Zhiyuan Fang, Shenghai Yuan, Yiding Yang, Angtian Wang, Bo Liu, Haibin Huang, and Chongyang Ma. MAGREF: Masked guidance for any-reference video generation with subject disentanglement. InICLR, 2026. 2, 3
2026
-
[16]
VIMI: Grounding video generation through multi-modal instruction
Yuwei Fang, Willi Menapace, Aliaksandr Siarohin, Tsai-Shien Chen, Kuan-Chien Wang, Ivan Skorokhodov, Graham Neubig, and Sergey Tulyakov. VIMI: Grounding video generation through multi-modal instruction. InEMNLP, 2024. 3
2024
-
[17]
Skyreels-a2: Compose anything in video diffusion transformers.arXiv preprint arXiv:2504.02436, 2025
Zhengcong Fei, Debang Li, Di Qiu, Jiahua Wang, Yikun Dou, Rui Wang, Jingtao Xu, Mingyuan Fan, Guibin Chen, Yang Li, et al. Skyreels-a2: Compose anything in video diffusion transformers.arXiv preprint arXiv:2504.02436, 2025. 2, 3
-
[18]
An image is worth one word: Personalizing text-to-image generation using textual inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit Haim Bermano, Gal Chechik, and Daniel Cohen-or. An image is worth one word: Personalizing text-to-image generation using textual inversion. In ICLR, 2023. 3
2023
-
[19]
Alchemint: Fine-grained temporal control for multi-reference consistent video generation
Sharath Girish, Viacheslav Ivanov, Tsai-Shien Chen, Hao Chen, Aliaksandr Siarohin, and Sergey Tulyakov. Alchemint: Fine-grained temporal control for multi-reference consistent video generation. InCVPR, 2026. 2, 3, 9, 10
2026
-
[20]
Google. Gemini. https://aistudio.google.com/models/gemini-2-5-flash-image , 2025. 7, 17, 18
2025
-
[21]
Google. Veo 3. https://deepmind.google/models/veo/, 2025. 2, 3
2025
-
[22]
Animatediff: Animate your personalized text-to-image diffusion models without specific tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. InICLR, 2024. 3
2024
-
[23]
Photorealistic video generation with diffusion models
Agrim Gupta, Lijun Yu, Kihyuk Sohn, Xiuye Gu, Meera Hahn, Fei-Fei Li, Irfan Essa, Lu Jiang, and José Lezama. Photorealistic video generation with diffusion models. InECCV, 2024. 3 12
2024
-
[24]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, Poriya Panet, Sapir Weissbuch, Victor Kulikov, Yaki Bitterman, Zeev Melumian, and Ofir Bibi. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2024. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Cameractrl: Enabling camera control for video diffusion models
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for video diffusion models. InICLR, 2025. 2, 3, 11
2025
-
[26]
Imagen Video: High Definition Video Generation with Diffusion Models
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion models.arXiv preprint arXiv:2210.02303, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InNeurIPS, 2020. 3
2020
-
[28]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. InNeurIPS Workshop, 2021. 19
2021
-
[29]
Video diffusion models
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models. InNeurIPS, 2022. 3
2022
-
[30]
Yuzhou Huang, Ziyang Yuan, Quande Liu, Qiulin Wang, Xintao Wang, Ruimao Zhang, Pengfei Wan, Di Zhang, and Kun Gai. Conceptmaster: Multi-concept video customization on diffusion transformer models without test-time tuning.arXiv preprint arXiv:2501.04698, 2025. 3
-
[31]
Vace: All-in-one video creation and editing
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. Vace: All-in-one video creation and editing. InICCV, 2025. 7, 9, 20, 22, 23
2025
-
[32]
Analyzing and improving the training dynamics of diffusion models
Tero Karras, Miika Aittala, Jaakko Lehtinen, Janne Hellsten, Timo Aila, and Samuli Laine. Analyzing and improving the training dynamics of diffusion models. InCVPR, 2024. 19
2024
-
[33]
YOLOv11: An Overview of the Key Architectural Enhancements
Rahima Khanam and Muhammad Hussain. Yolov11: An overview of the key architectural enhancements. arXiv preprint arXiv:2410.17725, 2024. 17
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114,
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Multi-concept customization of text-to-image diffusion
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customization of text-to-image diffusion. InCVPR, 2023. 3
2023
-
[37]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InICLR, 2023. 19
2023
-
[38]
Phantom: Subject-consistent video generation via cross-modal alignment
Lijie Liu, Tianxiang Ma, Bingchuan Li, Zhuowei Chen, Jiawei Liu, Gen Li, Siyu Zhou, Qian He, and Xinglong Wu. Phantom: Subject-consistent video generation via cross-modal alignment. InICCV, 2025. 2, 3, 7, 9, 20, 22, 23
2025
-
[39]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InECCV, 2024. 20
2024
-
[40]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and qiang liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InICLR, 2023. 19
2023
-
[41]
Decoupled Weight Decay Regularization
I Loshchilov. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 19
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
Yawen Luo, Xiaoyu Shi, Junhao Zhuang, Yutian Chen, Quande Liu, Xintao Wang, Pengfei Wan, and Tianfan Xue. Shotstream: Streaming multi-shot video generation for interactive storytelling.arXiv preprint arXiv:2603.25746, 2026. 2, 3, 4, 7, 9, 11, 20, 22, 23
-
[43]
Snap video: Scaled spatiotemporal transformers for text-to-video synthesis
Willi Menapace, Aliaksandr Siarohin, Ivan Skorokhodov, Ekaterina Deyneka, Tsai-Shien Chen, Anil Kag, Yuwei Fang, Aleksei Stoliar, Elisa Ricci, Jian Ren, et al. Snap video: Scaled spatiotemporal transformers for text-to-video synthesis. InCVPR, 2024. 2, 3
2024
-
[44]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023. 20
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023. 2, 3, 17
2023
-
[46]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih-Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models. arXiv preprint arXiv:2410.13720, 2024. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Guocheng Gordon Qian, Ruihang Zhang, Tsai-Shien Chen, Yusuf Dalva, Anujraaj Argo Goyal, Willi Menapace, Ivan Skorokhodov, Meng Dong, Arpit Sahni, Daniil Ostashev, et al. Layercomposer: Interactive personalized t2i via spatially-aware layered canvas.arXiv preprint arXiv:2510.20820, 2025. 3
-
[48]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InICML, 2021. 7, 8, 17, 20
2021
-
[49]
Exploring the limits of transfer learning with a unified text-to-text transformer
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. JMLR, 2020. 3, 17, 20
2020
-
[50]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 20
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022. 3 13
2022
-
[52]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMICCAI, 2015. 3
2015
-
[53]
Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation. InCVPR, 2023. 3
2023
-
[54]
Instantbooth: Personalized text-to-image generation without test-time finetuning
Jing Shi, Wei Xiong, Zhe Lin, and Hyun Joon Jung. Instantbooth: Personalized text-to-image generation without test-time finetuning. InCVPR, 2024. 3
2024
-
[55]
Make-a-video: Text-to-video generation without text-video data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, Devi Parikh, Sonal Gupta, and Yaniv Taigman. Make-a-video: Text-to-video generation without text-video data. InICLR, 2023. 3
2023
-
[56]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InICML, 2015. 3
2015
-
[57]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. In NeurIPS, 2019. 3
2019
-
[58]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 2024. 2, 5, 6, 15
2024
-
[59]
Qwen Team. Qwen3. 5-omni technical report.arXiv preprint arXiv:2604.15804, 2026. 20
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[60]
Attention is all you need
A Vaswani. Attention is all you need. InNeurIPS, 2017. 2, 3
2017
-
[61]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 2, 3, 17, 20
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Echoshot: Multi-shot portrait video generation
Jiahao Wang, Hualian Sheng, Sijia Cai, Weizhan Zhang, Caixia Yan, Yachuang Feng, Bing Deng, and Jieping Ye. Echoshot: Multi-shot portrait video generation. InNeurIPS, 2025. 2, 3, 4, 7, 9, 11, 20, 22, 23
2025
-
[63]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 9, 21
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
InstantID: Zero-shot Identity-Preserving Generation in Seconds
Qixun Wang, Xu Bai, Haofan Wang, Zekui Qin, and Anthony Chen. Instantid: Zero-shot identity-preserving generation in seconds.arXiv preprint arXiv:2401.07519, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
Multishotmaster: A controllable multi-shot video generation framework
Qinghe Wang, Xiaoyu Shi, Baolu Li, Weikang Bian, Quande Liu, Huchuan Lu, Xintao Wang, Pengfei Wan, Kun Gai, and Xu Jia. Multishotmaster: A controllable multi-shot video generation framework. In CVPR, 2026. 2, 3, 4, 7, 9, 11, 20, 22, 23
2026
-
[66]
Internvid: A large-scale video-text dataset for multimodal understanding and generation
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, Ping Luo, Ziwei Liu, Yali Wang, Limin Wang, and Yu Qiao. Internvid: A large-scale video-text dataset for multimodal understanding and generation. InICLR, 2024. 8, 20
2024
-
[67]
InternVideo: General Video Foundation Models via Generative and Discriminative Learning
Yi Wang, Kunchang Li, Yizhuo Li, Yinan He, Bingkun Huang, Zhiyu Zhao, Hongjie Zhang, Jilan Xu, Yi Liu, Zun Wang, et al. Internvideo: General video foundation models via generative and discriminative learning.arXiv preprint arXiv:2212.03191, 2022. 8, 20
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[68]
Motionctrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible motion controller for video generation. InSIGGRAPH, 2024. 2, 3, 11
2024
-
[69]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025. 6, 7, 17, 19
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
Cinetrans: Learning to generate videos with cinematic transitions via masked diffusion models
Xiaoxue Wu, Bingjie Gao, Yu Qiao, Yaohui Wang, and Xinyuan Chen. Cinetrans: Learning to generate videos with cinematic transitions via masked diffusion models. InICLR, 2026. 2, 3, 4, 7, 9, 11, 20, 22, 23
2026
-
[71]
Mind the time: Temporally-controlled multi-event video generation
Ziyi Wu, Aliaksandr Siarohin, Willi Menapace, Ivan Skorokhodov, Yuwei Fang, Varnith Chordia, Igor Gilitschenski, and Sergey Tulyakov. Mind the time: Temporally-controlled multi-event video generation. InCVPR, 2025. 2, 3, 5
2025
-
[72]
Cogvideox: Text-to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, Da Yin, Yuxuan.Zhang, Weihan Wang, Yean Cheng, Bin Xu, Xiaotao Gu, Yuxiao Dong, and Jie Tang. Cogvideox: Text-to-video diffusion models with an expert transformer. In ICLR, 2025. 2, 3
2025
-
[73]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[74]
Tora2: Motion and appearance customized diffusion transformer for multi-entity video generation
Zhenghao Zhang, Junchao Liao, Xiangyu Meng, Long Qin, and Weizhi Wang. Tora2: Motion and appearance customized diffusion transformer for multi-entity video generation. InACM MM, 2025. 3
2025
-
[75]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, et al. Pytorch fsdp: experiences on scaling fully sharded data parallel. arXiv preprint arXiv:2304.11277, 2023. 19
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[76]
Guangcong Zheng, Teng Li, Rui Jiang, Yehao Lu, Tao Wu, and Xi Li. Cami2v: Camera-controlled image-to-video diffusion model.arXiv preprint arXiv:2410.15957, 2024. 3, 11 14 CineOrchestra: Unified Entity-Centric Conditioning for Cinematic Video Generation Supplementary Material A Derivation and Properties ofβ(L) This appendix derives the closed form of the d...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.