Listwise Policy Optimization: Group-based RLVR as Target-Projection on the LLM Response Simplex
Pith reviewed 2026-05-21 08:58 UTC · model grok-4.3
The pith
Group-based policy gradients for LLM reasoning implicitly project toward a target on the response simplex, and making this explicit yields monotonic listwise improvement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
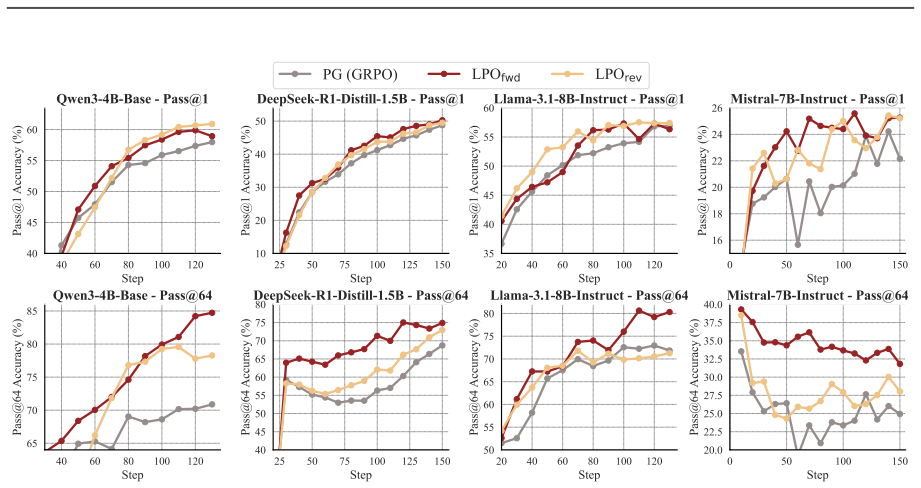
Existing group-based policy gradients in RLVR each implicitly define a target distribution on the response simplex and project the policy toward it via first-order approximation. Listwise Policy Optimization instead restricts the proximal RL objective to the response simplex and performs the projection through exact divergence minimization, which demystifies the target and supplies monotonic improvement on the listwise objective together with bounded, zero-sum, self-correcting gradients and flexible divergence choice.
What carries the argument
The decoupled projection step on the response simplex, which separates target definition from the policy update and replaces first-order approximation with exact divergence minimization.
If this is right
- The listwise objective improves monotonically under the projected updates.
- Projection gradients remain bounded, sum to zero, and self-correct over steps.
- Different divergence functions can be substituted in the projection step, each carrying distinct structural properties.
- Performance on reasoning benchmarks rises relative to standard group-based baselines while response diversity and optimization stability are preserved.
Where Pith is reading between the lines
- The geometric framing could be used to construct new targets that address specific failure modes such as repetitive or off-topic reasoning steps.
- The same simplex-projection idea might apply to other sequential generation settings beyond language, such as code or structured output.
- Stability benefits may derive more from the exact projection mechanics than from the particular form of the advantage signal.
Load-bearing premise
That the common geometric structure of group-based methods is accurately described by restricting the proximal objective to the response simplex and that exact divergence minimization produces the claimed stability and performance properties.
What would settle it
A direct comparison of training curves in which the explicit projection step is removed while the same group-relative target is retained, checking whether monotonic improvement and gradient boundedness disappear.
Figures












read the original abstract
Reinforcement learning with verifiable rewards (RLVR) has become a standard approach for large language models (LLMs) post-training to incentivize reasoning capacity. Among existing recipes, group-based policy gradient is prevalent, which samples a group of responses per prompt and updates the policy via group-relative advantage signals. This work reveals that these optimization strategies share a common geometric structure: each implicitly defines a target distribution on the response simplex and projects toward it via first-order approximation. Building on this insight, we propose Listwise Policy Optimization (LPO) to explicitly conduct the target-projection, which demystifies the implicit target by restricting the proximal RL objective to the response simplex, and then projects the policy via exact divergence minimization. This framework provides (i) monotonic improvement on the listwise objective with bounded, zero-sum, and self-correcting projection gradients, and (ii) flexibility in divergence selection with distinct structural properties through the decoupled projection step. On diverse reasoning tasks and LLM backbones, LPO consistently improves training performance over typical policy gradient baselines under matched targets, while intrinsically preserving optimization stability and response diversity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reinterprets group-based policy gradients in RLVR for LLMs as implicit first-order target projections onto the response simplex. It proposes Listwise Policy Optimization (LPO), which explicitly restricts the proximal RL objective to the simplex and performs exact divergence minimization to the target distribution derived from group-relative advantages. The authors claim this yields monotonic improvement on the listwise objective, bounded/zero-sum/self-correcting gradients, flexibility in divergence choice, and empirical gains over standard policy-gradient baselines on reasoning benchmarks while preserving stability and diversity.
Significance. If the geometric equivalence and transfer of stability guarantees hold, LPO would supply a principled, divergence-flexible framework that unifies and improves upon prevalent group-based RLVR methods. The explicit projection step could enable more stable post-training of reasoning LLMs and reduce reliance on ad-hoc advantage normalization.
major comments (2)
- [§3.2] §3.2 and Eq. (8)–(11): the claimed exact recovery of group-relative policy gradients as the first-order approximation to simplex-restricted divergence minimization is not shown to hold when advantages are computed over token sequences rather than whole responses; the normalization across the sampled group appears to introduce an effective target shift that is not accounted for in the projection step.
- [Theorem 1] Theorem 1 (monotonic improvement): the proof assumes the target distribution remains fixed during the exact projection, but the group-relative advantage used to define the target is itself recomputed from the current policy samples; this creates a moving-target issue that may invalidate the monotonicity guarantee unless an additional contraction argument is supplied.
minor comments (2)
- [§2] Notation for the response simplex and the projection operator is introduced without an explicit definition of the ambient probability space over variable-length sequences.
- [§5] Experimental section compares LPO only against matched-target baselines; an ablation varying the divergence (KL vs. reverse KL vs. Jensen-Shannon) would strengthen the claim of structural flexibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below, clarifying the scope of our derivations and indicating the revisions we will make to improve rigor and transparency.
read point-by-point responses
-
Referee: [§3.2] §3.2 and Eq. (8)–(11): the claimed exact recovery of group-relative policy gradients as the first-order approximation to simplex-restricted divergence minimization is not shown to hold when advantages are computed over token sequences rather than whole responses; the normalization across the sampled group appears to introduce an effective target shift that is not accounted for in the projection step.
Authors: We thank the referee for this observation. Our analysis in §3.2 and Eqs. (8)–(11) is developed for the standard response-level setting of group-based RLVR, where advantages are computed over complete responses and group normalization directly yields the target distribution on the response simplex. In this regime the first-order approximation recovers the group-relative policy gradient without additional shift. We acknowledge that token-sequence advantages would introduce a per-token normalization effect that shifts the effective target. We will revise the manuscript to explicitly state the response-level assumption, add a clarifying remark on the token-level case, and note that the geometric equivalence holds precisely under response-level advantages. revision: yes
-
Referee: [Theorem 1] Theorem 1 (monotonic improvement): the proof assumes the target distribution remains fixed during the exact projection, but the group-relative advantage used to define the target is itself recomputed from the current policy samples; this creates a moving-target issue that may invalidate the monotonicity guarantee unless an additional contraction argument is supplied.
Authors: We appreciate the referee’s careful examination of the proof. Theorem 1 establishes monotonic improvement on the listwise objective for a single exact projection step with the target held fixed. In the iterative algorithm the target is recomputed from the current policy’s samples, which indeed creates a moving-target dynamic. This is a standard consideration in iterative policy optimization. We will revise the theorem statement and surrounding discussion to clarify that the monotonicity guarantee applies conditionally to each projection step with fixed target, and we will add a remark acknowledging the iterative moving-target issue while noting that empirical results demonstrate stable improvement. A full contraction-mapping analysis of the overall iteration is left for future work. revision: partial
Circularity Check
Reinterpretation of group-based gradients as implicit target-projection on simplex makes monotonicity and stability claims reduce to the same construction
specific steps
-
renaming known result
[Abstract]
"This work reveals that these optimization strategies share a common geometric structure: each implicitly defines a target distribution on the response simplex and projects toward it via first-order approximation. Building on this insight, we propose Listwise Policy Optimization (LPO) to explicitly conduct the target-projection, which demystifies the implicit target by restricting the proximal RL objective to the response simplex, and then projects the policy via exact divergence minimization. This framework provides (i) monotonic improvement on the listwise objective with bounded, zero-sum, a"
The geometric structure is presented as a revelation about prior group-based methods, yet LPO is defined by making that same structure explicit. The monotonicity and stability properties are then derived from the projection geometry itself. Once the target is identified with the group-relative advantage distribution and the simplex restriction is imposed, the listed benefits are tautological consequences of the construction rather than new results independent of the original group-based updates.
full rationale
The paper's core derivation begins by asserting that existing group-based policy gradients implicitly define a target on the response simplex and approximate projection via first-order updates. LPO is then introduced by restricting the proximal objective to that simplex and replacing the approximation with exact divergence minimization. The listed guarantees (monotonic listwise improvement, bounded/zero-sum/self-correcting gradients) are obtained directly from the geometry of this explicit projection. Because the target and projection step are defined from the very group-relative advantages and sampling procedure of the baseline methods, the claimed advantages follow by construction once the equivalence is posited, rather than from an independent derivation or external benchmark. This matches the renaming-known-result pattern with load-bearing impact on the central claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Group-based policy gradient methods implicitly define a target distribution on the response simplex and project toward it via first-order approximation.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_fourth_deriv_at_zero unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
max_w∈Δ^{K-1} Ĵ(w) = ∑ w_k R_k - τ D_KL(w∥P_t) ... w^*_k = softmax(R_k/τ + s_t,k)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Natural gradient works efficiently in learning , author=. Neural computation , volume=. 1998 , publisher=
work page 1998
-
[2]
Maximum a Posteriori Policy Optimisation
Maximum a posteriori policy optimisation , author=. arXiv preprint arXiv:1806.06920 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Encyclopedia of Machine Learning , pages=
Kullback-leibler divergence , author=. Encyclopedia of Machine Learning , pages=
-
[4]
Reference-Sampled Boltzmann Projection for KL-Regularized RLVR: Target-Matched Weighted SFT, Finite One-Shot Gaps, and Policy Mirror Descent , author=. arXiv preprint arXiv:2605.02469 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Back to basics: Revisiting REINFORCE-style optimization for learning from human feedback in LLMs , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[6]
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Machine learning , volume=. 1992 , publisher=
work page 1992
-
[7]
Journal of Machine Learning Research , volume=
Gflownet foundations , author=. Journal of Machine Learning Research , volume=
-
[8]
From ranknet to lambdarank to lambdamart: An overview , author=. Learning , volume=
-
[9]
Proceedings of the 24th international conference on Machine learning , pages=
Learning to rank: from pairwise approach to listwise approach , author=. Proceedings of the 24th international conference on Machine learning , pages=
-
[10]
Using expectation-maximization for reinforcement learning , author=. Neural Computation , volume=. 1997 , publisher=
work page 1997
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Reinforce++: A simple and efficient approach for aligning large language models , author=. arXiv e-prints , pages=
-
[13]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review
Reinforcement learning and control as probabilistic inference: Tutorial and review , author=. arXiv preprint arXiv:1805.00909 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
arXiv preprint arXiv:2602.02710 , year=
Maximum Likelihood Reinforcement Learning , author=. arXiv preprint arXiv:2602.02710 , year=
-
[16]
Understanding R1-Zero-Like Training: A Critical Perspective
Understanding r1-zero-like training: A critical perspective , author=. arXiv preprint arXiv:2503.20783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [17]
-
[18]
Small Generalizable Prompt Predictive Models Can Steer Efficient RL Post-Training of Large Reasoning Models , author=. arXiv preprint arXiv:2602.01970 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [19]
-
[20]
arXiv preprint arXiv:2502.18548 , year=
What is the Alignment Objective of GRPO? , author=. arXiv preprint arXiv:2502.18548 , year=
-
[21]
Advances in neural information processing systems , volume=
A natural policy gradient , author=. Advances in neural information processing systems , volume=
-
[22]
arXiv preprint arXiv:1909.12238 , year=
V-mpo: On-policy maximum a posteriori policy optimization for discrete and continuous control , author=. arXiv preprint arXiv:1909.12238 , year=
- [23]
-
[24]
International conference on machine learning , pages=
A theory of regularized markov decision processes , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[25]
Reinforcement Learning with Verifiable Rewards: GRPO's Effective Loss, Dynamics, and Success Amplification , author=. arXiv preprint arXiv:2503.06639 , year=
-
[26]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Learning to predict by the methods of temporal differences , author=. Machine learning , volume=. 1988 , publisher=
work page 1988
-
[28]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring Mathematical Problem Solving With the MATH Dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Inter-GPS: Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning , author =. The Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2021) , year =
work page 2021
-
[31]
Process Reinforcement through Implicit Rewards
Process reinforcement through implicit rewards , author=. arXiv preprint arXiv:2502.01456 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. arXiv preprint arXiv:2402.14008 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Advances in Neural Information Processing Systems , volume=
Solving quantitative reasoning problems with language models , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
The Twelfth International Conference on Learning Representations , year=
Let's verify step by step , author=. The Twelfth International Conference on Learning Representations , year=
-
[35]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
arXiv preprint arXiv:2510.01135 , year=
Prompt curriculum learning for efficient llm post-training , author=. arXiv preprint arXiv:2510.01135 , year=
- [37]
-
[38]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [39]
-
[40]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
An, Chenxin and Xie, Zhihui and Li, Xiaonan and Li, Lei and Zhang, Jun and Gong, Shansan and Zhong, Ming and Xu, Jingjing and Qiu, Xipeng and Wang, Mingxuan and Kong, Lingpeng , year =. POLARIS: A Post-Training Recipe for Scaling Reinforcement Learning on Advanced Reasoning Models , url =
-
[42]
Jiayi Pan and Junjie Zhang and Xingyao Wang and Lifan Yuan and Hao Peng and Alane Suhr , title =
-
[43]
arXiv preprint arXiv:2603.10887 , year=
Dynamics-predictive sampling for active RL finetuning of large reasoning models , author=. arXiv preprint arXiv:2603.10887 , year=
-
[44]
Yun Qu, Qi Wang, Yixiu Mao, Vincent Tao Hu, Bj¨orn Ommer, and Xiangyang Ji
Can prompt difficulty be online predicted for accelerating rl finetuning of reasoning models? , author=. arXiv preprint arXiv:2507.04632 , year=
-
[45]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Advantage-weighted regression: Simple and scalable off-policy reinforcement learning , author=. arXiv preprint arXiv:1910.00177 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[46]
arXiv preprint arXiv:2310.10505 , year=
Remax: A simple, effective, and efficient reinforcement learning method for aligning large language models , author=. arXiv preprint arXiv:2310.10505 , year=
-
[47]
Deepcoder: A fully open-source 14b coder at o3-mini level , author=. Notion Blog , year=
-
[48]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Relative entropy policy search , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[49]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
The American Statistician , volume=
A tutorial on MM algorithms , author=. The American Statistician , volume=. 2004 , publisher=
work page 2004
-
[52]
Proceedings of the Royal Society of London
An invariant form for the prior probability in estimation problems , author=. Proceedings of the Royal Society of London. Series A. Mathematical and Physical Sciences , volume=. 1946 , publisher=
work page 1946
-
[53]
Learning in graphical models , pages=
A view of the EM algorithm that justifies incremental, sparse, and other variants , author=. Learning in graphical models , pages=. 1998 , publisher=
work page 1998
-
[54]
International conference on machine learning , pages=
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[55]
IEEE Transactions on Information theory , volume=
Divergence measures based on the Shannon entropy , author=. IEEE Transactions on Information theory , volume=. 2002 , publisher=
work page 2002
- [56]
-
[57]
Maestro: Learning to Collaborate via Conditional Listwise Policy Optimization for Multi-Agent LLMs , author=. arXiv preprint arXiv:2511.06134 , year=
-
[58]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[59]
First Conference on Language Modeling , year=
Gpqa: A graduate-level google-proof q&a benchmark , author=. First Conference on Language Modeling , year=
-
[60]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Journal of the Royal Statistical Society Series C: Applied Statistics , volume=
The analysis of permutations , author=. Journal of the Royal Statistical Society Series C: Applied Statistics , volume=. 1975 , publisher=
work page 1975
-
[62]
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
work page 2024
-
[63]
It Takes Two: Your GRPO Is Secretly DPO
It takes two: Your grpo is secretly dpo , author=. arXiv preprint arXiv:2510.00977 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Minimax-m1: Scaling test-time compute efficiently with lightning attention , author=. arXiv preprint arXiv:2506.13585 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[66]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. 2024 , eprint=
work page 2024
-
[67]
Advances in neural information processing systems , volume=
Policy gradient methods for reinforcement learning with function approximation , author=. Advances in neural information processing systems , volume=
-
[68]
arXiv preprint arXiv:2509.15207 , year=
Flowrl: Matching reward distributions for llm reasoning , author=. arXiv preprint arXiv:2509.15207 , year=
-
[69]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[71]
LiPO: Listwise Preference Optimization through Learning-to-Rank , author=. 2025 , eprint=
work page 2025
-
[72]
Modeling purposeful adaptive behavior with the principle of maximum causal entropy , author=. 2010 , publisher=
work page 2010
-
[73]
Beyond reverse kl: Generalizing direct preference optimization with diverse divergence constraints , author=. arXiv preprint arXiv:2309.16240 , year=
-
[74]
The choice of divergence: A neglected key to mitigating diversity collapse in reinforcement learning with verifiable reward , author=. arXiv preprint arXiv:2509.07430 , year=
-
[75]
Reverse-KL Reinforcement Learning Can Sample From Multiple Diverse Modes , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.