Combating Textual Noise and Redundancy: Entropy-Aware Dense Visual Token Pruning
Pith reviewed 2026-07-03 14:45 UTC · model grok-4.3
The pith
Entropy filtering of textual noise followed by spatially-prioritized submodular selection lets vision-language models keep fine-grained visual cues under tight token budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EADP reformulates pruning as structured compression. It first uses statistical entropy to quantify and filter textual noise, producing a robust fine-grained instruction relevance score. It then casts token selection as submodular maximization with a spatial prior to guarantee a holistic non-redundant visual representation. Experiments show the framework improves the accuracy-efficiency trade-off of VLMs, preserves fine-grained cues under strict budgets, and reaches state-of-the-art results on challenging multimodal benchmarks.
What carries the argument
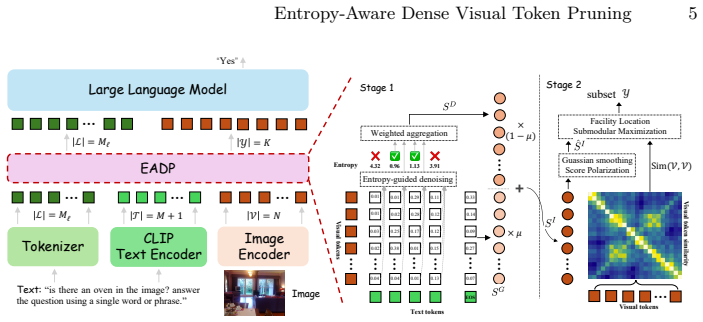
Entropy-Aware Dense Pruning (EADP), a two-stage process that cleans cross-modal scores via statistical entropy before performing submodular maximization under a spatial prior for token selection.
If this is right
- VLMs retain fine-grained visual information even when forced to a small fixed number of tokens.
- Token selection avoids both noise corruption in scoring and spatial clustering of kept patches.
- The accuracy-efficiency trade-off improves relative to prior pruning techniques on the same models.
- State-of-the-art results appear on multimodal benchmarks that stress fine detail and dense instructions.
Where Pith is reading between the lines
- The same entropy-plus-submodular pattern could be tested on other selection tasks where instructions introduce noise, such as audio or video token pruning.
- Real-time deployment settings with hard latency constraints would gain the most from the reported token reduction without accuracy loss.
- If the spatial prior is the main source of the coverage gain, simpler diversity penalties might achieve similar results at lower computational cost.
- Extending the entropy measure to multi-turn conversations could reveal whether accumulated textual noise grows and requires stronger filtering.
Load-bearing premise
Statistical entropy can reliably identify and remove the textual noise that distorts cross-modal relevance scores for individual image patches.
What would settle it
A controlled test that measures whether the entropy-cleaned scores correlate more strongly with human patch-relevance judgments than raw cross-modal scores, or that compares the submodular selections against top-k selections on the same budget for retention of task-critical patches.
Figures
read the original abstract
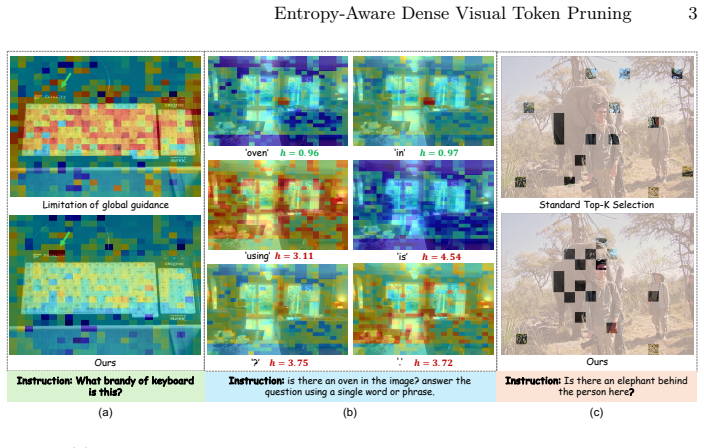
Visual token pruning is a crucial strategy for accelerating VLMs by compressing redundant image patches, yet existing methods often fail to preserve critical cues under dense instructions and fine-grained queries. In this paper, we investigate this failure and identify two underlying bottlenecks: the widespread dispersion of textual noise that corrupts dense cross-modal scoring, and the feature fragmentation inherent to standard token selection. To address these issues, we propose Entropy-Aware Dense Pruning (EADP), a framework that reformulates pruning as a structured compression problem. EADP first leverages statistical entropy to quantify and filter out textual noise, yielding a robust, fine-grained instruction relevance score. Subsequently, instead of naive Top-K selection, EADP casts token selection as a submodular maximization problem with a spatial prior, explicitly ensuring a holistic and non-redundant visual representation. Extensive experiments demonstrate that EADP improves the accuracy-efficiency trade-off of VLMs, robustly preserving fine-grained visual cues under strict token budgets while achieving SoTA performance on challenging multimodal benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that visual token pruning in VLMs is hindered by textual noise dispersion corrupting cross-modal scores and by feature fragmentation from naive selection. It proposes Entropy-Aware Dense Pruning (EADP), which first applies statistical entropy to filter textual noise and produce robust fine-grained relevance scores, then reformulates selection as submodular maximization incorporating a spatial prior to yield holistic non-redundant tokens. The abstract asserts that this improves the accuracy-efficiency trade-off and achieves SoTA results on challenging multimodal benchmarks under strict token budgets.
Significance. If the central claims are substantiated, the work would offer a structured compression approach that combines information-theoretic filtering with combinatorial optimization, potentially enabling more reliable preservation of fine-grained visual information in token-limited VLM inference.
major comments (2)
- [Abstract] Abstract: the assumption that statistical entropy reliably quantifies and removes textual noise corrupting dense cross-modal scoring is load-bearing for the entire pipeline, yet remains unexamined; if noise manifests as systematic semantic misalignment rather than high-entropy dispersion, the filtering step will not produce a robust relevance matrix and the subsequent submodular maximization cannot guarantee preservation of fine-grained cues.
- [Abstract] Abstract: the statements 'Extensive experiments demonstrate that EADP improves the accuracy-efficiency trade-off ... while achieving SoTA performance' are unsupported by any data, tables, ablations, error bars, or quantitative results in the manuscript text.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the specific comments on the abstract. We respond to each major comment below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assumption that statistical entropy reliably quantifies and removes textual noise corrupting dense cross-modal scoring is load-bearing for the entire pipeline, yet remains unexamined; if noise manifests as systematic semantic misalignment rather than high-entropy dispersion, the filtering step will not produce a robust relevance matrix and the subsequent submodular maximization cannot guarantee preservation of fine-grained cues.
Authors: We agree that the entropy filtering step is central and that its behavior under different noise regimes merits direct examination. The manuscript motivates the choice via the observed dispersion of textual noise in cross-modal scores and shows end-to-end gains, but does not isolate the entropy component with targeted ablations or score visualizations. In revision we will add an analysis subsection that (i) compares entropy-filtered versus raw relevance matrices on sample instructions and (ii) reports an ablation replacing entropy with alternative noise-robustness heuristics, thereby testing the assumption more explicitly. revision: yes
-
Referee: [Abstract] Abstract: the statements 'Extensive experiments demonstrate that EADP improves the accuracy-efficiency trade-off ... while achieving SoTA performance' are unsupported by any data, tables, ablations, error bars, or quantitative results in the manuscript text.
Authors: The full manuscript contains a complete Experiments section (including tables reporting accuracy-efficiency trade-offs, ablations on the submodular objective and spatial prior, error bars across multiple runs, and SoTA comparisons on the cited multimodal benchmarks under strict token budgets). The abstract summarizes those results. If the experimental content was inadvertently omitted from the version the referee received, we will ensure the revised submission makes the link between abstract claims and specific tables/figures explicit. revision: partial
Circularity Check
No circularity: method relies on empirical design choices without self-referential reductions
full rationale
The provided abstract and description introduce EADP via two design steps—entropy-based noise filtering to produce relevance scores, followed by submodular maximization with a spatial prior—but contain no equations, fitted parameters, self-citations, or derivations that reduce any claim to its own inputs by construction. No self-definitional loops, renamed predictions, or load-bearing self-citations appear. The framework is presented as a reformulation justified by identified bottlenecks and validated experimentally, remaining self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Flamingo: a Visual Language Model for Few-Shot Learning
Alayrac, J., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Men- sch, A., Millican, K., Reynolds, M., Ring, R., Rutherford, E., Cabi, S., Han, T., Gong, Z., Samangooei, S., Monteiro, M., Menick, J., Borgeaud, S., Brock, A., van den Driessche, G., Mugford, K., Sifre, L., Soyer, H., Doersch, C., Gupta, A., Stanczyk, P., Noh, H., Gontijo Lo...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Alvar, S.R., Singh, G., Akbari, M., Zhang, Y.: Divprune: Diversity-based visual token pruning for large multimodal models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 9392–9401 (2025) 1, 4, 11, 12, 25
2025
-
[3]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Bai, J., et al.: Qwen-VL: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966 (2023) 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report (2025),https://arxiv.org/abs/2502.13923 1, 10, 12, 24
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
In: European Conference on Computer Vision
Chen, L., Zhao, H., Liu, T., Bai, S., Lin, J., Zhou, C., Chang, B.: An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision- language models. In: European Conference on Computer Vision. pp. 19–35. Springer (2024) 1, 4, 11, 25
2024
-
[7]
Chen, Z., Wang, W., Cao, Y., Liu, Y., Gao, Z., Cui, E., Zhu, J., Ye, S., Tian, H., Liu, Z., et al.: Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271 (2024) 1, 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Chen, Z., et al.: InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. arXiv preprint arXiv:2312.14238 (2023) 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Cho, K., van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., Bengio, Y.: Learning phrase representations using RNN encoder–decoder for statistical machine translation. arXiv preprint arXiv:1406.1078 (2014) 3
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[10]
In: Linzen, T., Chrupała, G., Belinkov, Y., Hupkes, D
Clark, K., Khandelwal, U., Levy, O., Manning, C.D.: What does BERT look at? an analysis of BERT’s attention. In: Linzen, T., Chrupała, G., Belinkov, Y., Hupkes, D. (eds.) Proceedings of the 2019 ACL Workshop BlackboxNLP: AnalyzingandInterpretingNeuralNetworksforNLP.AssociationforComputational Linguistics, Florence, Italy (Aug 2019).https://doi.org/10.1865...
-
[11]
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale (2021), https://arxiv.org/abs/2010.119291 Supplementary Materials 33
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Duan, H., Yang, J., Qiao, Y., Fang, X., Chen, L., Liu, Y., Dong, X., Zang, Y., Zhang, P., Wang, J., et al.: Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 11198–11201 (2024) 11
2024
-
[13]
Duan, Y., Li, A., Li, Y., Li, L., Wang, P.: Gridprune: From" where to look" to" what to select" in visual token pruning for mllms. arXiv preprint arXiv:2511.10081 (2025) 1, 4, 7
-
[14]
Fu, C., Chen, P., Shen, Y., Qin, Y., Zhang, M., Lin, X., Yang, J., Zheng, X., Li, K., Sun, X., Wu, Y., Ji, R., Shan, C., He, R.: Mme: A comprehensive evaluation benchmark for multimodal large language models (2025),https://arxiv.org/abs/ 2306.1339410, 22
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Fu, C., Dai, Y., Luo, Y., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y., Zhang, M., Chen, P., Li, Y., Lin, S., Zhao, S., Li, K., Xu, T., Zheng, X., Chen, E., Shan, C., He, R., Sun, X.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis (2025),https://arxiv.org/abs/ 2405.2107511, 23
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Goyal, Y., Khot, T., Summers-Stay, D., Batra, D., Parikh, D.: Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 6325–6334 (2017).https://doi.org/10.1109/CVPR.2017.67010, 21
-
[17]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Guan, T., Liu, F., Wu, X., Xian, R., Li, Z., Liu, X., Wang, X., Chen, L., Huang, F., Yacoob, Y., Manocha, D., Zhou, T.: Hallusionbench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 1437...
2024
-
[18]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Guan, T., Wang, Z., Fu, P., Guo, Z., Shen, W., Zhou, K., Yue, T., Duan, C., Sun, H., Jiang, Q., et al.: A token-level text image foundation model for document understanding. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 23210–23220 (2025) 1
2025
-
[19]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Guan, T., Yang, Z., Wan, J., Yang, M., Guo, Z., Hu, Z., Luo, R., Chen, R., Jiang, S., Wang, P., et al.: Codepercept: Code-grounded visual stem perception for mllms. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 33542–33552 (2026) 1
2026
-
[20]
Gurari, D., Li, Q., Stangl, A.J., Guo, A., Lin, C., Grauman, K., Luo, J., Bigham, J.P.: Vizwiz grand challenge: Answering visual questions from blind people (2018), https://arxiv.org/abs/1802.0821810, 21
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[21]
Hudson, D.A., Manning, C.D.: Gqa: A new dataset for real-world visual reasoning andcompositionalquestionanswering.In:2019IEEE/CVFConferenceonComputer Vision and Pattern Recognition (CVPR). pp. 6693–6702 (2019).https://doi.org/ 10.1109/CVPR.2019.0068610, 21
-
[22]
Jia, C., Yang, Y., Xia, Y., Chen, Y., Parekh, Z., Pham, H., Le, Q.V., Sung, Y., Li, Z., Duerig, T.: ALIGN: Scaling up visual and vision-language representation learning with noisy text supervision. arXiv preprint arXiv:2102.05918 (2021) 3
-
[23]
Kembhavi, A., Salvato, M., Kolve, E., Seo, M., Hajishirzi, H., Farhadi, A.: A diagram is worth a dozen images (2016),https://arxiv.org/abs/1603.07396 10, 22
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[24]
Large Language Models are Zero-Shot Reasoners
Kojima, T., Gu, S.S., Reid, M., Matsuo, Y., Iwasawa, Y.: Large language models are zero-shot reasoners. arXiv preprint arXiv:2205.11916 (2022) 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
In: Tractability (2014), https://api.semanticscholar.org/CorpusID:61074902 34 X
Krause, A., Golovin, D.: Submodular function maximization. In: Tractability (2014), https://api.semanticscholar.org/CorpusID:61074902 34 X. Wang et al
2014
-
[26]
LLaVA-OneVision: Easy Visual Task Transfer
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y., Liu, Z., et al.: Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326 (2024) 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
In: Proceedings of the 40th International Conference on Machine Learning (ICML) (2023) 3, 4
Li, J., Li, D., Xiong, C., Hoi, S.C.H.: BLIP-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: Proceedings of the 40th International Conference on Machine Learning (ICML) (2023) 3, 4
2023
-
[28]
Li, K., Wang, Y., He, Y., Li, Y., Wang, Y., Liu, Y., Wang, Z., Xu, J., Chen, G., Lou, P., Wang, L., Qiao, Y.: Mvbench: A comprehensive multi-modal video understanding benchmark. In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 22195–22206 (2024).https://doi.org/10. 1109/CVPR52733.2024.0209511, 23
- [29]
-
[30]
In: Advances in Neural Information Processing Systems (NeurIPS) (2023) 3
Li, W., Chen, L., Dai, D., Zhu, Z., Tan, M., Yuan, L., Li, L., Wang, J., Liu, J.: InstructBLIP: Towards general-purpose vision-language models with instruction tuning. In: Advances in Neural Information Processing Systems (NeurIPS) (2023) 3
2023
-
[31]
In: Proceedings of the European Conference on Computer Vision (ECCV) (2020) 3
Li, X., Yin, X., Li, C., Zhang, P., Hu, X., Zhang, L., Wang, L., Hu, H., Dong, L., Wei, F., Choi, Y., Gao, J.: OSCAR: Object-semantics aligned pre-training for vision-language tasks. In: Proceedings of the European Conference on Computer Vision (ECCV) (2020) 3
2020
-
[32]
arXiv preprint arXiv:2508.07871 (2025) 2, 4
Li, Y., Yang, J., Shen, Z., Han, L., Xu, H., Tang, R.: Catp: Contextually adaptive token pruning for efficient and enhanced multimodal in-context learning. arXiv preprint arXiv:2508.07871 (2025) 2, 4
-
[33]
Li, Y., Wang, H., Duan, Y., Xu, H., Li, X.: Exploring visual interpretability for contrastive language-image pre-training (2022), https://arxiv.org/abs/2209. 0704618
2022
-
[34]
In: Bouamor, H., Pino, J., Bali, K
Li, Y., Du, Y., Zhou, K., Wang, J., Zhao, X., Wen, J.R.: Evaluating object hallucination in large vision-language models. In: Bouamor, H., Pino, J., Bali, K. (eds.) Proceedings of the 2023 Conference on Empirical Methods in Nat- ural Language Processing. Association for Computational Linguistics, Singa- pore (Dec 2023). https://doi.org/10.18653/v1/2023.em...
-
[35]
In: Proceedings of the 2024 conference on empirical methods in natural language processing
Lin, B., Ye, Y., Zhu, B., Cui, J., Ning, M., Jin, P., Yuan, L.: Video-llava: Learning united visual representation by alignment before projection. In: Proceedings of the 2024 conference on empirical methods in natural language processing. pp. 5971–5984 (2024) 1
2024
-
[36]
In: Annual Meeting of the Association for Computational Linguistics (2011), https://api.semanticscholar.org/CorpusID:3203712
Lin, H.C., Bilmes, J.A.: A class of submodular functions for document summariza- tion. In: Annual Meeting of the Association for Computational Linguistics (2011), https://api.semanticscholar.org/CorpusID:3203712
2011
-
[37]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Lin, Z., Lin, M., Lin, L., Ji, R.: Boosting multimodal large language models with visual tokens withdrawal for rapid inference. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 5334–5342 (2025) 1, 4
2025
-
[38]
io/blog/2024-01-30-llava-next/1, 10, 24
Liu, H., Li, C., Li, Y., Li, B., Zhang, Y., Shen, S., Lee, Y.J.: Llava-next: Improved reasoning, ocr, and world knowledge (January 2024),https://llava-vl.github. io/blog/2024-01-30-llava-next/1, 10, 24
2024
-
[39]
In: Advances in Neural Information Processing Systems (NeurIPS) (2023) 1, 3, 4, 10, 12, 24
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: Advances in Neural Information Processing Systems (NeurIPS) (2023) 1, 3, 4, 10, 12, 24
2023
-
[40]
HiPrune: Hierarchical Attention for Efficient Token Pruning in Vision-Language Models
Liu, J., Du, F., Zhu, G., Lian, N., Li, J., Chen, B.: Hiprune: Training-free visual token pruning via hierarchical attention in vision-language models. arXiv preprint arXiv:2508.00553 (2025) 2, 4, 11, 12, 25 Supplementary Materials 35
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., Chen, K., Lin, D.: Mmbench: Is your multi-modal model an all-around player? (2024),https://arxiv.org/abs/2307.0628110, 22
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Liu, Y., Li, Z., Huang, M., Yang, B., Yu, W., Li, C., Yin, X.C., Liu, C.L., Jin, L., Bai, X.: Ocrbench: on the hidden mystery of ocr in large multimodal models. Science China Information Sciences67(12) (Dec 2024).https://doi.org/10.1007/s11432- 024-4235-6,http://dx.doi.org/10.1007/s11432-024-4235-610, 22
-
[43]
In: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A
Lu, P., Mishra, S., Xia, T., Qiu, L., Chang, K.W., Zhu, S.C., Tafjord, O., Clark, P., Kalyan, A.: Learn to explain: Multimodal reasoning via thought chains for science question answering. In: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A. (eds.) Advances in Neural Information Processing Systems. vol. 35, pp. 2507–2521. Curran Associat...
2022
-
[44]
Advances in Applied Probability7(1), 83–122 (1975) 9
Macchi, O.: The coincidence approach to stochastic point processes. Advances in Applied Probability7(1), 83–122 (1975) 9
1975
-
[45]
In: Muresan, S., Nakov, P., Villavicencio, A
Masry, A., Long, D.X., Tan, J.Q., Joty, S., Hoque, E.: ChartQA: A benchmark for question answering about charts with visual and logical reasoning. In: Muresan, S., Nakov, P., Villavicencio, A. (eds.) Findings of the Association for Computational Linguistics: ACL 2022. Association for Computational Linguistics, Dublin, Ireland (May 2022). https://doi.org/1...
- [46]
- [47]
-
[48]
Mathematical Programming14, 265–294 (1978),https://api.semanticscholar.org/CorpusID:2068004252, 18
Nemhauser, G.L., Wolsey, L.A., Fisher, M.L.: An analysis of approximations for maximizing submodular set functions—i. Mathematical Programming14, 265–294 (1978),https://api.semanticscholar.org/CorpusID:2068004252, 18
1978
-
[49]
In: Proceedings of the 38th International Conference on Machine Learning (ICML) (2021) 2, 3, 18, 24
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: Proceedings of the 38th International Conference on Machine Learning (ICML) (2021) 2, 3, 18, 24
2021
-
[50]
Transactions of the Association for Computa- tional Linguistics8(2020)
Rogers, A., Kovaleva, O., Rumshisky, A.: A primer in BERTology: What we know about how BERT works. Transactions of the Association for Computa- tional Linguistics8(2020). https://doi.org/10.1162/tacl_a_00349 , https: //aclanthology.org/2020.tacl-1.54/5
-
[51]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Shang, Y., Cai, M., Xu, B., Lee, Y.J., Yan, Y.: Llava-prumerge: Adaptive token reduction for efficient large multimodal models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 22857–22867 (2025) 1, 4, 11, 25
2025
- [52]
-
[53]
In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Singh, A., Natarajan, V., Shah, M., Jiang, Y., Chen, X., Batra, D., Parikh, D., Rohrbach, M.: Towards vqa models that can read. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 8309–8318 (2019). https://doi.org/10.1109/CVPR.2019.0085110, 21
-
[54]
In: Proceedings of the 31st International Conference on Computational Linguistics
Song, D., Wang, W., Chen, S., Wang, X., Guan, M.X., Wang, B.: Less is more: A simple yet effective token reduction method for efficient multi-modal llms. In: Proceedings of the 31st International Conference on Computational Linguistics. pp. 7614–7623 (2025) 1, 4, 11, 19, 26 36 X. Wang et al
2025
-
[55]
In: Advances in Neural Information Processing Systems (NeurIPS) (2017) 1, 3
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems (NeurIPS) (2017) 1, 3
2017
-
[56]
In: Linzen, T., Chrupała, G., Belinkov, Y., Hupkes, D
Vig, J., Belinkov, Y.: Analyzing the structure of attention in a transformer language model. In: Linzen, T., Chrupała, G., Belinkov, Y., Hupkes, D. (eds.) Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. Association for Computational Linguistics, Florence, Italy (Aug 2019),https://aclanthology.org/W19-4808/2
2019
-
[57]
In: Advances in Neural Information Processing Systems (NeurIPS) (2022) 4
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q.V., Zhou, D.: Chain-of-thought prompting elicits reasoning in large language models. In: Advances in Neural Information Processing Systems (NeurIPS) (2022) 4
2022
-
[58]
important tokens
Wen, Z., Gao, Y., Wang, S., Zhang, J., Zhang, Q., Li, W., He, C., Zhang, L.: Stop looking for “important tokens” in multimodal language models: Duplication matters more. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 9972–9991 (2025) 1, 4, 11, 25
2025
-
[59]
In: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C
Wu, H., Li, D., Chen, B., Li, J.: LongVideoBench: A benchmark for long-context interleaved video-language understanding. In: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C. (eds.) Advances in Neural Informa- tion Processing Systems. vol. 37, pp. 28828–28857. Curran Associates, Inc. (2024). https://doi.org/10.52202/0790...
-
[60]
Xiao, G., Tian, Y., Chen, B., Han, S., Lewis, M.: Efficient streaming language models with attention sinks (2024),https://arxiv.org/abs/2309.174535
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
Xing, L., Huang, Q., Dong, X., Lu, J., Zhang, P., Zang, Y., Cao, Y., He, C., Wang, J., Wu, F., Lin, D.: Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction (2025),https://arxiv.org/abs/2410.17247 11, 25
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yang, S., Chen, Y., Tian, Z., Wang, C., Li, J., Yu, B., Jia, J.: Visionzip: Longer is better but not necessary in vision language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19792– 19802 (2025) 1, 4, 11, 25
2025
- [63]
-
[64]
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
Ye, R., Jin, W., Wang, H., Wu, Y., Xu, J., Liu, Y., Luo, P.: mplug-owl: Mod- ularization empowers large language models with multimodality. arXiv preprint arXiv:2304.14178 (2023) 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[65]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Ye, W., Wu, Q., Lin, W., Zhou, Y.: Fit and prune: Fast and training-free visual token pruning for multi-modal large language models. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 22128–22136 (2025) 1, 4
2025
-
[66]
Yu, W., Yang, Z., Li, L., Wang, J., Lin, K., Liu, Z., Wang, X., Wang, L.: Mm- vet: Evaluating large multimodal models for integrated capabilities (2024),https: //arxiv.org/abs/2308.0249010, 23
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language image pre-training (2023),https://arxiv.org/abs/2303.1534324
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[68]
arXiv preprint arXiv:2509.00320 (2025) 2, 4
Zhang, H., Lyu, M., He, C., Ao, Y., Lin, Y.: Trimtokenator: Towards adaptive visual token pruning for large multimodal models. arXiv preprint arXiv:2509.00320 (2025) 2, 4
- [69]
-
[70]
TRIO: Token Reduction via Inference-Objective Guidance for Efficient Vision-Language Models
Zhang, H., Ou, C., Yan, D., Wang, P., Yan, Q., Li, Y., Xiao, R., Shen, C.: Pio- fvlm: Rethinking training-free visual token reduction for vlm acceleration from an inference-objective perspective. arXiv preprint arXiv:2602.04657 (2026) 1, 4
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[71]
Zhang, K., Li, B., Zhang, P., Pu, F., Cahyono, J.A., Hu, K., Liu, S., Zhang, Y., Yang, J., Li, C., Liu, Z.: Lmms-eval: Reality check on the evaluation of large multimodal models (2024),https://arxiv.org/abs/2407.1277211
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[72]
arXiv preprint arXiv:2506.10967 (2025) 2, 4, 7, 11, 12, 19, 25, 26
Zhang, Q., Liu, M., Li, L., Lu, M., Zhang, Y., Pan, J., She, Q., Zhang, S.: Beyond attention or similarity: Maximizing conditional diversity for token pruning in mllms. arXiv preprint arXiv:2506.10967 (2025) 2, 4, 7, 11, 12, 19, 25, 26
-
[73]
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference
Zhang, Y., Fan, C.K., Ma, J., Zheng, W., Huang, T., Cheng, K., Gudovskiy, D., Okuno, T., Nakata, Y., Keutzer, K., et al.: Sparsevlm: Visual token sparsification for efficient vision-language model inference. arXiv preprint arXiv:2410.04417 (2024) 1, 4, 11, 25
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[74]
0271310, 13, 24
Zhang, Y., Wu, J., Li, W., Li, B., Ma, Z., Liu, Z., Li, C.: Llava-video: Video instruction tuning with synthetic data (2025), https://arxiv.org/abs/2410. 0271310, 13, 24
2025
-
[75]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Zhu, D., Chen, J., Shen, X., Li, X., Elhoseiny, M.: MiniGPT-4: Enhancing vision- language understanding with advanced large language models. arXiv preprint arXiv:2304.10592 (2023) 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[76]
Zou, X., Lu, D., Wang, Y., Yan, Y., Lyu, Y., Zheng, X., Zhang, L., Hu, X.: Don’t just chase "highlighted tokens" in mllms: Revisiting visual holistic context retention (2025),https://arxiv.org/abs/2510.029122
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.