UnfoldArt: Zero-Shot Recovery of Full Articulated 3D Objects from Text or Image
Pith reviewed 2026-06-30 05:55 UTC · model grok-4.3
The pith
A two-round agent debate grounded in generated video recovers complete articulated 3D objects including hidden geometry from text or image inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
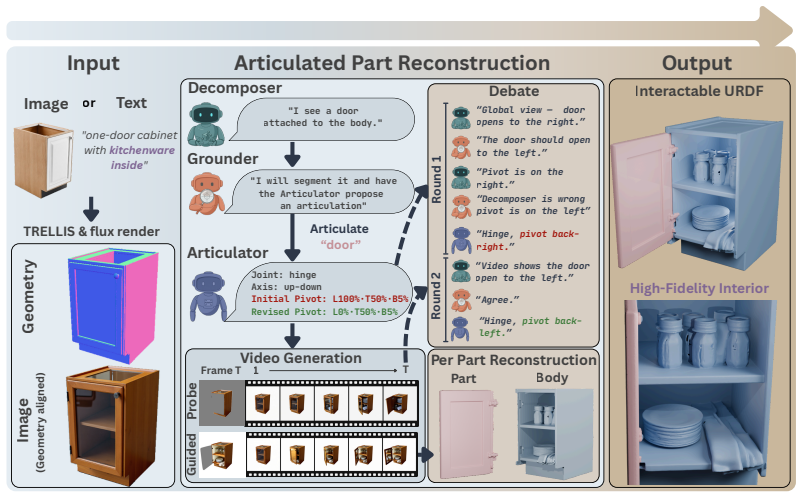
We present the first debate-driven agentic approach to articulated 3D object reconstruction from text or image inputs that both grounds articulation reasoning in concrete motion and exposes the occluded geometry revealed under articulation. High-level agents reason about object semantics and motion using knowledge from vision-language and video models, while low-level agents estimate articulation parameters and interaction points; together, they engage in a two-round structured debate that first exploits global--local disagreement and then grounds the agents in freely generated video. The same video prior, conditioned on the agreed articulation, then drives each part through its motion to ex
What carries the argument
The two-round structured debate between high-level semantic agents and low-level parameter agents, grounded by a video generative prior that drives agreed articulation to reveal occluded parts.
If this is right
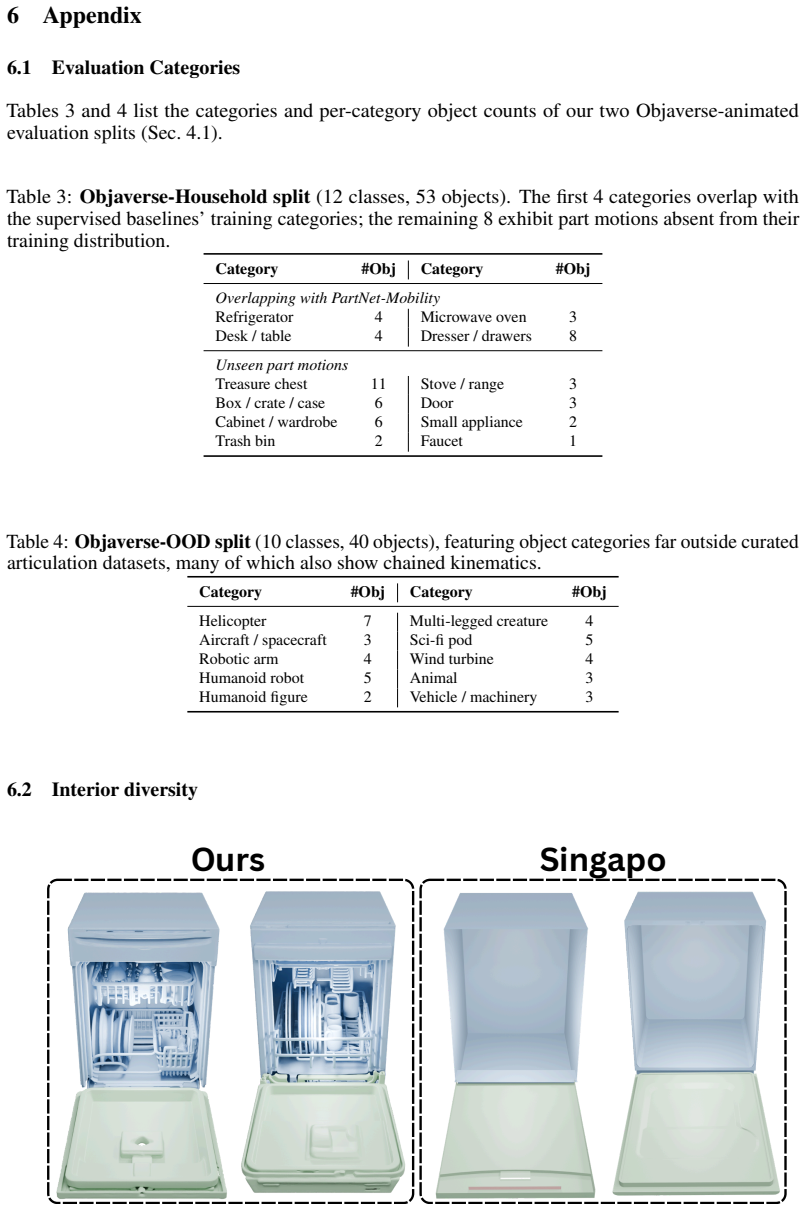
- The method jointly infers articulation parameters and reconstructs complete 3D geometry with internal structure from sparse inputs.
- Motion-consistent states are produced for each articulated part without direct observation of all surfaces.
- Reconstruction succeeds without supervised training data on articulated objects.
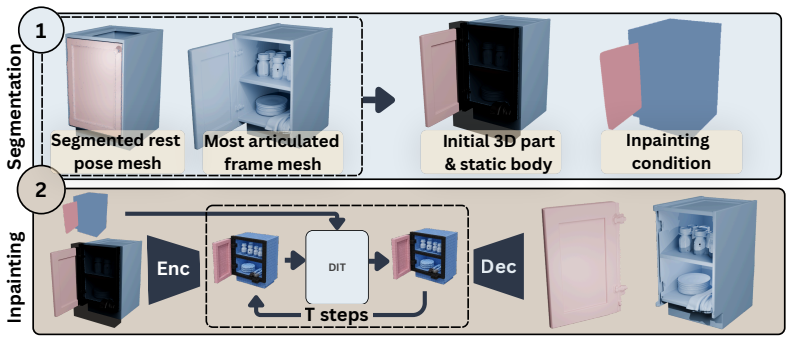
- Hidden geometry becomes recoverable by driving parts through motion in the generated video prior.
Where Pith is reading between the lines
- The debate process could be adapted to incorporate real observed video instead of generated video for tasks where motion footage is available.
- Similar agent disagreement resolution might help other zero-shot reconstruction problems that involve ambiguity or occlusion.
- The approach could support downstream tasks in robotics such as planning grasps on articulated objects whose internal structure is initially unknown.
Load-bearing premise
The video generative prior, once conditioned on the agreed articulation, produces motion that accurately reveals the true occluded interiors and geometry.
What would settle it
Generate the 3D reconstruction for a known articulated object from a single image, then compare the exposed internal geometry against a ground-truth 3D scan taken after physical disassembly or multi-view capture of the real object in motion.
Figures




read the original abstract
Articulated 3D objects are essential for interactive environments in embodied AI, robotics, and virtual reality, but reconstructing their structure and motion from sparse observations remains challenging. Existing approaches remain largely constrained by lack of supervised data or lack the priors needed to reliably recover articulation, hidden geometry, and internal object structure. We present the first debate-driven agentic approach to articulated 3D object reconstruction from text or image inputs that both grounds articulation reasoning in concrete motion and exposes the occluded geometry revealed under articulation. High-level agents reason about object semantics and motion using knowledge from vision-language and video models, while low-level agents estimate articulation parameters and interaction points; together, they engage in a two-round structured debate that first exploits global--local disagreement and then grounds the agents in freely generated video. The same video prior, conditioned on the agreed articulation, then drives each part through its motion to expose occluded interiors and geometry that cannot be inferred from a single static view. By combining agentic reasoning with a video generative prior, our approach jointly infers articulation and reconstructs complete 3D articulated objects, producing high-fidelity geometry, internal structure, and motion-consistent states beyond directly observed surfaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UnfoldArt, a zero-shot method for reconstructing complete articulated 3D objects (including internal structure and motion) from text or single-image inputs. It uses a two-round debate between high-level agents (leveraging vision-language and video models for semantics and motion) and low-level agents (estimating articulation parameters and interaction points), grounding the process in freely generated video that is then conditioned on the agreed articulation to drive part motion and reveal occluded geometry.
Significance. If the central claims hold, the work would offer a notable advance in zero-shot articulated reconstruction by reducing dependence on supervised data and using agentic debate plus video generative priors to jointly infer articulation and hidden geometry. This could impact embodied AI, robotics, and VR applications where full object models with motion are needed from sparse inputs.
major comments (2)
- [Abstract] Abstract and method overview: The central claim that 'the same video prior, conditioned on the agreed articulation, then drives each part through its motion to expose occluded interiors and geometry' is load-bearing for the reconstruction result, yet the description provides no mechanism to validate or correct the generated video against real geometry (e.g., no consistency checks, no comparison to ground-truth motion, and no handling of known video-model artifacts such as inconsistent physics or view-dependent hallucinations).
- [Method] Method description (debate and video grounding steps): The two-round structured debate is presented as grounding articulation reasoning in 'concrete motion,' but the manuscript does not specify how disagreement between global and local agents is quantified or resolved when the subsequent video generation step introduces errors, leaving the pipeline vulnerable to propagating incorrect articulation parameters into the final 3D reconstruction.
minor comments (1)
- [Abstract] The abstract states the approach is 'the first' debate-driven method; a brief related-work paragraph should explicitly contrast against prior agentic or video-prior reconstruction papers to support this positioning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting key aspects of the video grounding and debate process in UnfoldArt. We address each major comment below with clarifications on the zero-shot design and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract and method overview: The central claim that 'the same video prior, conditioned on the agreed articulation, then drives each part through its motion to expose occluded interiors and geometry' is load-bearing for the reconstruction result, yet the description provides no mechanism to validate or correct the generated video against real geometry (e.g., no consistency checks, no comparison to ground-truth motion, and no handling of known video-model artifacts such as inconsistent physics or view-dependent hallucinations).
Authors: We agree that the video prior is central and that the zero-shot setting precludes direct validation against real geometry or ground-truth motion, as no such data is available by design. The agent debate provides the primary grounding mechanism prior to video generation. We will add an explicit limitations discussion on video model artifacts (e.g., physics inconsistencies) and their potential propagation, without altering the core pipeline. revision: partial
-
Referee: [Method] Method description (debate and video grounding steps): The two-round structured debate is presented as grounding articulation reasoning in 'concrete motion,' but the manuscript does not specify how disagreement between global and local agents is quantified or resolved when the subsequent video generation step introduces errors, leaving the pipeline vulnerable to propagating incorrect articulation parameters into the final 3D reconstruction.
Authors: The first debate round explicitly surfaces global-local disagreements for resolution through structured discussion, with the second round using video to ground the consensus parameters. Resolution occurs via agent convergence rather than a numerical metric. We will revise the method section to detail the debate protocol, including how video conditions are applied to mitigate errors, to improve clarity. revision: yes
Circularity Check
No significant circularity; derivation relies on external priors
full rationale
The paper's claimed pipeline uses external vision-language models, video generative priors, and agent debate to infer articulations and reconstruct geometry. No equations, parameters, or results are shown to reduce by construction to fitted inputs, self-definitions, or self-citation chains. The video-driven exposure step is presented as an application of an independent generative model rather than a tautological renaming or prediction forced by the method's own data. The approach is self-contained against external benchmarks with no load-bearing internal equivalences.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ziang Cao, Fangzhou Hong, Zhaoxi Chen, Liang Pan, and Ziwei Liu. Physx-anything: Simulation-ready physical 3d assets from single image.arXiv preprint arXiv:2511.13648,
-
[2]
SAM 3: Segment Anything with Concepts
URLhttps://arxiv.org/abs/2511.16719. Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. Shapenet: An information-rich 3d model repository.arXiv preprint arXiv:1512.03012,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Freeart3d: Training-free articulated object generation using 3d diffusion
Chuhao Chen, Isabella Liu, Xinyue Wei, Hao Su, and Minghua Liu. Freeart3d: Training-free articulated object generation using 3d diffusion. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–13,
2025
-
[4]
Zoey Chen, Aaron Walsman, Marius Memmel, Kaichun Mo, Alex Fang, Karthikeya Vemuri, Alan Wu, Dieter Fox, and Abhishek Gupta. Urdformer: A pipeline for constructing articulated simulation environments from real-world images.arXiv preprint arXiv:2405.11656,
-
[5]
Automated creation of digital cousins for robust policy learning.arXiv preprint arXiv:2410.07408,
Tianyuan Dai, Josiah Wong, Yunfan Jiang, Chen Wang, Cem Gokmen, Ruohan Zhang, Jiajun Wu, and Li Fei-Fei. Automated creation of digital cousins for robust policy learning.arXiv preprint arXiv:2410.07408,
-
[6]
Objaverse: A Universe of Annotated 3D Objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects.arXiv preprint arXiv:2212.08051,
-
[7]
Objaverse-XL: A Universe of 10M+ 3D Objects
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram V oleti, Samir Yitzhak Gadre, Eli VanderBilt, Aniruddha Kembhavi, Carl V ondrick, Georgia Gkioxari, Kiana Ehsani, Ludwig Schmidt, and Ali Farhadi. Objaverse-xl: A universe of 10m+ 3d objects. arXiv preprint arXiv:2307.05663,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate.arXiv preprint arXiv:2305.14325,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
A3vlm: Actionable articulation-aware vision language model.arXiv preprint arXiv:2406.07549,
11 Siyuan Huang, Haonan Chang, Yuhan Liu, Yimeng Zhu, Hao Dong, Peng Gao, Abdeslam Boularias, and Hong- sheng Li. A3vlm: Actionable articulation-aware vision language model.arXiv preprint arXiv:2406.07549,
-
[10]
Cotracker3: Simpler and better point tracking by pseudo-labelling real videos
Nikita Karaev, Iurii Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Cotracker3: Simpler and better point tracking by pseudo-labelling real videos. InProc. arXiv:2410.11831, 2024a. Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Cotracker: It is better to track to...
-
[11]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
URL https://arxiv.org/abs/2506.15742. Long Le, Jason Xie, William Liang, Hung-Ju Wang, Yue Yang, Yecheng Jason Ma, Kyle Vedder, Arjun Krishna, Dinesh Jayaraman, and Eric Eaton. Articulate-anything: Automatic modeling of articulated objects via a vision-language foundation model. InInternational Conference on Learning Representations, volume 2025, pages 17...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
SegviGen: Repurposing 3D Generative Model for Part Segmentation
Lin Li, Haoran Feng, Zehuan Huang, Haohua Chen, Wenbo Nie, Shaohua Hou, Keqing Fan, Pan Hu, Sheng Wang, Buyu Li, and Lu Sheng. Segvigen: Repurposing 3d generative model for part segmentation.arXiv preprint arXiv:2603.16869,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Particulate: Feed-forward 3d object articulation.arXiv preprint arXiv:2512.11798,
Ruining Li, Yuxin Yao, Chuanxia Zheng, Christian Rupprecht, Joan Lasenby, Shangzhe Wu, and Andrea Vedaldi. Particulate: Feed-forward 3d object articulation.arXiv preprint arXiv:2512.11798,
-
[14]
URL https://arxiv.org/abs/2506.05573. Jiayi Liu, Ali Mahdavi-Amiri, and Manolis Savva. Paris: Part-level reconstruction and motion analysis for articulated objects. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 352–363,
-
[15]
Singapo: Single image controlled generation of articulated parts in objects
Jiayi Liu, Denys Iliash, Angel Chang, Manolis Savva, and Ali Mahdavi Amiri. Singapo: Single image controlled generation of articulated parts in objects. InInternational Conference on Learning Representations, volume 2025, pages 97511–97532, 2025a. Minghua Liu, Mikaela Angelina Uy, Donglai Xiang, Hao Su, Sanja Fidler, Nicholas Sharp, and Jun Gao. Partfield...
-
[16]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Changfeng Ma, Yang Li, Xinhao Yan, Jiachen Xu, Yunhan Yang, Chunshi Wang, Zibo Zhao, Yanwen Guo, Zhuo Chen, and Chunchao Guo. P3-sam: Native 3d part segmentation.arXiv preprint arXiv:2509.06784,
-
[17]
Articulate anymesh: Open-vocabulary 3d articulated objects modeling.arXiv preprint arXiv:2502.02590,
Xiaowen Qiu, Jincheng Yang, Yian Wang, Zhehuan Chen, Yufei Wang, Tsun-Hsuan Wang, Zhou Xian, and Chuang Gan. Articulate anymesh: Open-vocabulary 3d articulated objects modeling.arXiv preprint arXiv:2502.02590,
-
[18]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalk- wyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
X-part: high fi- delity and structure coherent shape decomposition.ArXiv, abs/2509.08643, 2025
Jianfeng Xiang, Xiaoxue Chen, Sicheng Xu, Ruicheng Wang, Zelong Lv, Yu Deng, Hongyuan Zhu, Yue Dong, Hao Zhao, Nicholas Jing Yuan, and Jiaolong Yang. Native and compact structured latents for 3d generation. Tech report, 2025a. Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d ...
-
[20]
Sampart3d: Segment any part in 3d objects.arXiv preprint arXiv:2411.07184,
Yunhan Yang, Yukun Huang, Yuan-Chen Guo, Liangjun Lu, Xiaoyang Wu, Edmund Y Lam, Yan-Pei Cao, and Xihui Liu. Sampart3d: Segment any part in 3d objects.arXiv preprint arXiv:2411.07184,
-
[21]
Omnipart: Part-aware 3d generation with semantic decoupling and structural cohesion
Yunhan Yang, Yufan Zhou, Yuan-Chen Guo, Zi-Xin Zou, Yukun Huang, Ying-Tian Liu, Hao Xu, Ding Liang, Yan-Pei Cao, and Xihui Liu. Omnipart: Part-aware 3d generation with semantic decoupling and structural cohesion. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–12,
2025
-
[22]
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Zibo Zhao, Zeqiang Lai, Qingxiang Lin, Yunfei Zhao, Haolin Liu, Shuhui Yang, Yifei Feng, Mingxin Yang, Sheng Zhang, Xianghui Yang, et al. Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation.arXiv preprint arXiv:2501.12202,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Articraft: An Agentic System for Scalable Articulated 3D Asset Generation
Matt Zhou, Ruining Li, Xiaoyang Lyu, Zhaomou Song, Zhening Huang, Chuanxia Zheng, Christian Rupprecht, Andrea Vedaldi, and Shangzhe Wu. Articraft: An agentic system for scalable articulated 3d asset generation. arXiv preprint arXiv:2605.15187,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.