ROVER: Routing Object-Centric Visual Evidence for Grounded Multi-Image Reasoning
Pith reviewed 2026-06-29 13:38 UTC · model grok-4.3
The pith
ROVER routes object-centric visual evidence in MLLMs by injecting step-specific token triplets upon grounding predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
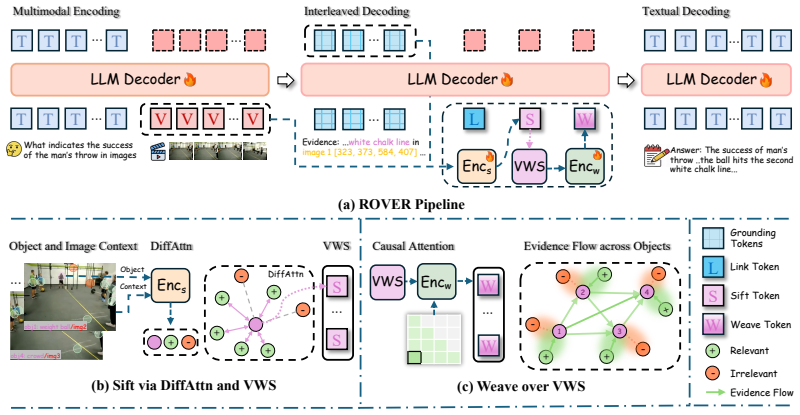
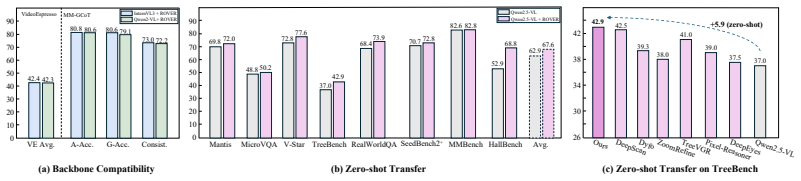
ROVER is a learnable plugin for efficient global visual evidence routing. Upon each object grounding prediction, ROVER injects a step-specific token triplet to synergistically aggregate the ongoing reasoning context, distill intra-image cues into a visual working space via object-centric differential attention, and route and integrate history-aware evidence across objects and images within this space for subsequent reasoning. Integrated into Qwen2.5-VL-7B with an interleaved SFT-to-GRPO pipeline and evaluated on original datasets and protocols, it achieves the best performance on MM-GCoT and VideoEspresso while showing transferability.
What carries the argument
The step-specific token triplet injected upon object grounding predictions, which performs context aggregation, object-centric differential attention for cue distillation, and cross-object/image evidence routing.
If this is right
- Higher answer accuracy on MM-GCoT and VideoEspresso benchmarks.
- Higher grounding accuracy on MM-GCoT.
- Strong transferability to diverse other benchmarks after training on VideoEspresso.
- Avoids decoding costs that scale with the number and size of regions of interest.
Where Pith is reading between the lines
- The routing approach could apply to single-image tasks that still require selective evidence focus without cropping.
- Differential attention inside the token triplet might generalize to other forms of history-aware multimodal integration.
- Training pipelines that interleave supervised fine-tuning with reinforcement learning could become standard for similar routing plugins.
Load-bearing premise
The token triplet with object-centric differential attention will preserve holistic scene understanding and inter-object relations while avoiding scaling costs and without requiring fine-grained supervision.
What would settle it
Evaluating the ROVER-enhanced model against the base model on MM-GCoT under the paper's exact protocols and finding no gain in grounding accuracy or answer accuracy.
Figures










read the original abstract
Multimodal Large Language Models (MLLMs) have increasingly localized and interleaved visual evidence for deliberative reasoning. Grounding-based approaches typically focus on regions of interest (RoIs) by injecting cropped image patches or RoI-specific features into the reasoning context. However, such designs can weaken holistic scene understanding and inter-object relations, while incurring decoding costs that scale with the number and size of RoIs. Alternatively, adaptive visual feature selection often requires fine-grained supervision or complex heuristics. To address these limitations, we propose ROVER (Routing Object-centric Visual Evidence for grounded multi-image Reasoning), a lightweight, learnable plugin for efficient global visual evidence routing. Upon each object grounding prediction, ROVER injects a step-specific token triplet to synergistically: (i) aggregate the ongoing reasoning context, (ii) distill intra-image cues into a visual working space via object-centric differential attention, and (iii) route and integrate history-aware evidence across objects and images within this space for subsequent reasoning. We integrate ROVER into Qwen2.5-VL-7B and develop an interleaved SFT-to-GRPO training pipeline. Strictly adhering to the original datasets and evaluation protocols, our method achieves the best performance on MM-GCoT (+4.8% answer accuracy, +14.6% grounding accuracy) and VideoEspresso (+8.6% answer accuracy). The VideoEspresso-trained model demonstrates strong transferability, outperforming the base model by +4.7% on average across diverse benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ROVER, a lightweight learnable plugin for MLLMs that, upon each object grounding prediction, injects a step-specific token triplet to (i) aggregate reasoning context, (ii) distill intra-image cues into a visual working space via object-centric differential attention, and (iii) route and integrate history-aware evidence across objects and images. The plugin is integrated into Qwen2.5-VL-7B together with an interleaved SFT-to-GRPO training pipeline; the resulting model reports the best results on MM-GCoT (+4.8% answer accuracy, +14.6% grounding accuracy) and VideoEspresso (+8.6% answer accuracy) while strictly following original datasets and protocols, plus transfer gains on other benchmarks.
Significance. If the performance deltas are shown to arise from the ROVER routing mechanism rather than the accompanying training changes, the approach would provide a scalable, supervision-light alternative to RoI-cropping methods that avoids weakening holistic scene understanding and inter-object relations. The explicit adherence to original evaluation protocols is a positive feature that supports direct comparability.
major comments (2)
- [Abstract] Abstract: the central performance claims (+4.8% answer accuracy / +14.6% grounding accuracy on MM-GCoT, +8.6% on VideoEspresso) are attributed to the ROVER token-triplet mechanism with object-centric differential attention, yet the method is introduced together with a new interleaved SFT-to-GRPO pipeline on Qwen2.5-VL-7B. No ablation is described that holds the training procedure fixed while adding or removing only the ROVER plugin, so it remains possible that the reported gains are driven primarily by the training changes.
- [Abstract] Abstract / problem setup: the claim that ROVER avoids the scaling costs of prior RoI-based methods and the need for fine-grained supervision while preserving inter-object relations rests on the design of the step-specific token triplet and differential attention, but the abstract provides no quantitative evidence (e.g., memory or latency scaling curves, or comparison against a RoI baseline with matched training) that these properties hold under the reported experimental conditions.
minor comments (1)
- [Abstract] The abstract could more explicitly state the dimensionality and initialization of the injected token triplet and the precise formulation of the object-centric differential attention operation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. Below we respond point-by-point to the major comments and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (+4.8% answer accuracy / +14.6% grounding accuracy on MM-GCoT, +8.6% on VideoEspresso) are attributed to the ROVER token-triplet mechanism with object-centric differential attention, yet the method is introduced together with a new interleaved SFT-to-GRPO training pipeline on Qwen2.5-VL-7B. No ablation is described that holds the training procedure fixed while adding or removing only the ROVER plugin, so it remains possible that the reported gains are driven primarily by the training changes.
Authors: We agree that the current experiments do not isolate the ROVER plugin from the interleaved SFT-to-GRPO pipeline, leaving open the possibility that gains are driven primarily by training changes. In the revised manuscript we will add an ablation that applies the identical SFT-to-GRPO schedule to the base Qwen2.5-VL-7B without ROVER and directly compares it to the full ROVER model on MM-GCoT and VideoEspresso. revision: yes
-
Referee: [Abstract] Abstract / problem setup: the claim that ROVER avoids the scaling costs of prior RoI-based methods and the need for fine-grained supervision while preserving inter-object relations rests on the design of the step-specific token triplet and differential attention, but the abstract provides no quantitative evidence (e.g., memory or latency scaling curves, or comparison against a RoI baseline with matched training) that these properties hold under the reported experimental conditions.
Authors: The abstract summarizes the design rationale; quantitative efficiency evidence and matched-training RoI comparisons appear only in the experimental section. We will revise the abstract to include a concise reference to the efficiency results and will ensure the main text contains explicit memory/latency scaling curves together with a RoI baseline trained under the same protocol. revision: partial
Circularity Check
No significant circularity; results are empirical outcomes on external benchmarks
full rationale
The paper introduces ROVER as a plugin with a described token-triplet mechanism and an interleaved SFT-to-GRPO pipeline, then reports performance on MM-GCoT and VideoEspresso using the original datasets and evaluation protocols. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims rest on external benchmark results rather than reducing to self-defined inputs or prior author work by construction. This is the expected self-contained empirical case.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Model card addendum: Claude 3.5 haiku and upgraded claude 3.5 sonnet
Sonnet Anthropic. Model card addendum: Claude 3.5 haiku and upgraded claude 3.5 sonnet. In Claude 3.5 Sonnet, 2024
2024
-
[3]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities.ArXiv, abs/2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Qwen2.5-vl technical report, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2025
2025
-
[5]
Tianyi Bai, Zengjie Hu, Fupeng Sun, Jiantao Qiu, Yizhen Jiang, Guangxin He, Bohan Zeng, Conghui He, Binhang Yuan, and Wentao Zhang. Multi-step visual reasoning with visual tokens scaling and verification.arXiv preprint arXiv:2506.07235, 2025
-
[6]
Microvqa: A multimodal reasoning benchmark for microscopy-based scientific research
James Burgess, Jeffrey J Nirschl, Laura Bravo-Sánchez, Alejandro Lozano, Sanket Rajan Gupte, Jesus G Galaz-Montoya, Yuhui Zhang, Yuchang Su, Disha Bhowmik, Zachary Coman, et al. Microvqa: A multimodal reasoning benchmark for microscopy-based scientific research. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19...
2025
-
[7]
M3-embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation
Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. M3-embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. InFindings of the Association for Computational Linguistics: ACL 2024, pages 2318–2335, Bangkok, Thailand, August 2024. Association for Computational Linguistics
2024
-
[8]
Ict: Image-object cross-level trusted intervention for mitigating object hallucination in large vision-language models
Junzhe Chen, Tianshu Zhang, Shiyu Huang, Yuwei Niu, Linfeng Zhang, Lijie Wen, and Xuming Hu. Ict: Image-object cross-level trusted intervention for mitigating object hallucination in large vision-language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 4209–4221, 2025
2025
-
[9]
R1-v: Reinforcing super generaliza- tion ability in vision-language models with less than $3
Liang Chen, Lei Li, Haozhe Zhao, Yifan Song, and Vinci. R1-v: Reinforcing super generaliza- tion ability in vision-language models with less than $3. https://github.com/Deep-Agent /R1-V, 2025. Accessed: 2025-02-02
2025
-
[10]
Xinyan Chen, Renrui Zhang, Dongzhi Jiang, Aojun Zhou, Shilin Yan, Weifeng Lin, and Hongsheng Li. Mint-cot: Enabling interleaved visual tokens in mathematical chain-of-thought reasoning.arXiv preprint arXiv:2506.05331, 2025
-
[11]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shen- glong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185–24198, 2024
2024
-
[13]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Computer Vision, pages 148–166. Springer, 2024
2024
-
[14]
Interleaved-modal chain-of-thought
Jun Gao, Yongqi Li, Ziqiang Cao, and Wenjie Li. Interleaved-modal chain-of-thought. In 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19520–19529. IEEE, 2025. 10
2025
-
[15]
Gemini: A Family of Highly Capable Multimodal Models
Google Gemini Team. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Hallusion- bench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, Dinesh Manocha, and Tianyi Zhou. Hallusion- bench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision ...
2024
-
[17]
Regiongpt: Towards region understanding vision language model
Qiushan Guo, Shalini De Mello, Hongxu Yin, Wonmin Byeon, Ka Chun Cheung, Yizhou Yu, Ping Luo, and Sifei Liu. Regiongpt: Towards region understanding vision language model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13796–13806, 2024
2024
-
[18]
Visual programming: Compositional visual reasoning without training
Tanmay Gupta and Aniruddha Kembhavi. Visual programming: Compositional visual reasoning without training. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14953–14962, 2023
2023
-
[19]
Videoespresso: A large-scale chain-of-thought dataset for fine-grained video reasoning via core frame selection
Songhao Han, Wei Huang, Hairong Shi, Le Zhuo, Xiu Su, Shifeng Zhang, Xu Zhou, Xiaojuan Qi, Yue Liao, and Si Liu. Videoespresso: A large-scale chain-of-thought dataset for fine-grained video reasoning via core frame selection. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 26181–26191, June 2025
2025
-
[20]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[21]
Zhitao He, Sandeep Polisetty, Zhiyuan Fan, Yuchen Huang, Shujin Wu, and Yi R. Fung. MMBoundary: Advancing MLLM knowledge boundary awareness through reasoning step confidence calibration. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16427–16444, Vienna, Austria, July
-
[22]
Association for Computational Linguistics
-
[23]
Yushi Hu, Weijia Shi, Xingyu Fu, Dan Roth, Mari Ostendorf, Luke Zettlemoyer, Noah A Smith, and Ranjay Krishna. Visual sketchpad: Sketching as a visual chain of thought for multimodal language models.arXiv preprint arXiv:2406.09403, 2024
-
[24]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Mantis: Interleaved multi-image instruction tuning.arXiv preprint arXiv:2405.01483, 2024
Dongfu Jiang, Xuan He, Huaye Zeng, Cong Wei, Max Ku, Qian Liu, and Wenhu Chen. Mantis: Interleaved multi-image instruction tuning.arXiv preprint arXiv:2405.01483, 2024
-
[27]
Thinking, fast and slow.Farrar, Straus and Giroux, 2011
Daniel Kahneman. Thinking, fast and slow.Farrar, Straus and Giroux, 2011
2011
-
[28]
Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
2022
-
[29]
The removal of information from working memory.Annals of the New York Academy of Sciences, 1424(1):33–44, 2018
Jarrod A Lewis-Peacock, Yoav Kessler, and Klaus Oberauer. The removal of information from working memory.Annals of the New York Academy of Sciences, 1424(1):33–44, 2018
2018
-
[30]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Seed-bench-2-plus: Benchmarking multimodal large language models with text-rich visual comprehension, 2024
Bohao Li, Yuying Ge, Yi Chen, Yixiao Ge, Ruimao Zhang, and Ying Shan. Seed-bench-2-plus: Benchmarking multimodal large language models with text-rich visual comprehension, 2024. 11
2024
-
[32]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models. arXiv preprint arXiv:2407.07895, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Dyfo: A training-free dynamic focus visual search for enhancing lmms in fine-grained visual understanding
Geng Li, Jinglin Xu, Yunzhen Zhao, and Yuxin Peng. Dyfo: A training-free dynamic focus visual search for enhancing lmms in fine-grained visual understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9098–9108, 2025
2025
-
[34]
Yangfu Li, Hongjian Zhan, Jiawei Chen, Yuning Gong, Qi Liu, and Yue Lu. Deepscan: A training-free framework for visually grounded reasoning in large vision-language models.arXiv preprint arXiv:2603.03857, 2026
-
[35]
Llama-vid: An image is worth 2 tokens in large language models
Yanwei Li, Chengyao Wang, and Jiaya Jia. Llama-vid: An image is worth 2 tokens in large language models. InEuropean Conference on Computer Vision, pages 323–340. Springer, 2024
2024
-
[36]
Migician: Revealing the magic of free-form multi- image grounding in multimodal large language models
You Li, Heyu Huang, Chi Chen, Kaiyu Huang, Chao Huang, Zonghao Guo, Zhiyuan Liu, Jinan Xu, Yuhua Li, Ruixuan Li, et al. Migician: Revealing the magic of free-form multi- image grounding in multimodal large language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 9845–9867, 2025
2025
-
[37]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[38]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[39]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision, pages 38–55. Springer, 2024
2024
-
[40]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Argus: Vision-centric reasoning with grounded chain-of- thought
Yunze Man, De-An Huang, Guilin Liu, Shiwei Sheng, Shilong Liu, Liang-Yan Gui, Jan Kautz, Yu-Xiong Wang, and Zhiding Yu. Argus: Vision-centric reasoning with grounded chain-of- thought. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14268–14280, 2025
2025
-
[43]
Refixation behavior in naturalistic viewing: Methods, mechanisms, and neural correlates.Attention, Perception, & Psychophysics, 87(1):25–49, 2025
Andrey R Nikolaev, Radha Nila Meghanathan, and Cees van Leeuwen. Refixation behavior in naturalistic viewing: Methods, mechanisms, and neural correlates.Attention, Perception, & Psychophysics, 87(1):25–49, 2025
2025
-
[44]
Working memory and attention–a conceptual analysis and review.Journal of cognition, 2(1):36, 2019
Klaus Oberauer. Working memory and attention–a conceptual analysis and review.Journal of cognition, 2(1):36, 2019
2019
-
[45]
Openai o3
OpenAI. Openai o3. https://openai.com/index/introducing-o3-and-o4-mini , 2025
2025
-
[46]
V-thinker: Interactive thinking with images
Runqi Qiao, Qiuna Tan, Minghan Yang, Guanting Dong, Peiqing Yang, Shiqiang Lang, Enhui Wan, Xiaowan Wang, Yida Xu, Lan Yang, et al. V-thinker: Interactive thinking with images. arXiv preprint arXiv:2511.04460, 2025
-
[47]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling, 2024
2024
-
[48]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. 12
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[49]
Hao Shao, Shengju Qian, Han Xiao, Guanglu Song, Zhuofan Zong, Letian Wang, Yu Liu, and Hongsheng Li. Visual cot: Advancing multi-modal language models with a comprehen- sive dataset and benchmark for chain-of-thought reasoning.Advances in Neural Information Processing Systems, 37:8612–8642, 2024
2024
-
[50]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Chuming Shen, Wei Wei, Xiaoye Qu, and Yu Cheng. Satori-r1: Incentivizing multimodal reasoning with spatial grounding and verifiable rewards.arXiv preprint arXiv:2505.19094, 2025
-
[52]
Min Shi, Fuxiao Liu, Shihao Wang, Shijia Liao, Subhashree Radhakrishnan, Yilin Zhao, De-An Huang, Hongxu Yin, Karan Sapra, Yaser Yacoob, et al. Eagle: Exploring the design space for multimodal llms with mixture of encoders.arXiv preprint arXiv:2408.15998, 2024
-
[53]
Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers
Zhaochen Su, Peng Xia, Hangyu Guo, Zhenhua Liu, Yan Ma, Xiaoye Qu, Jiaqi Liu, Yanshu Li, Kaide Zeng, Zhengyuan Yang, et al. Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers.arXiv preprint arXiv:2506.23918, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Cambrian-1: A fully open, vision-centric exploration of multimodal llms.Advances in Neural Information Processing Systems, 37:87310–87356, 2024
Peter Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Adithya Jairam Vedagiri IYER, Sai Charitha Akula, Shusheng Yang, Jihan Yang, Manoj Middepogu, Ziteng Wang, et al. Cambrian-1: A fully open, vision-centric exploration of multimodal llms.Advances in Neural Information Processing Systems, 37:87310–87356, 2024
2024
-
[55]
Eyes wide shut? exploring the visual shortcomings of multimodal llms
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9568–9578, 2024
2024
-
[56]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[57]
Haochen Wang, Xiangtai Li, Zilong Huang, Anran Wang, Jiacong Wang, Tao Zhang, Jiani Zheng, Sule Bai, Zijian Kang, Jiashi Feng, et al. Traceable evidence enhanced visual grounded reasoning: Evaluation and methodology.arXiv preprint arXiv:2507.07999, 2025
-
[58]
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
Haozhe Wang, Alex Su, Weiming Ren, Fangzhen Lin, and Wenhu Chen. Pixel reasoner: Incentivizing pixel-space reasoning with curiosity-driven reinforcement learning.arXiv preprint arXiv:2505.15966, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
VGR: Visual Grounded Reasoning
Jiacong Wang, Zijian Kang, Haochen Wang, Haiyong Jiang, Jiawen Li, Bohong Wu, Ya Wang, Jiao Ran, Xiao Liang, Chao Feng, et al. Vgr: Visual grounded reasoning.arXiv preprint arXiv:2506.11991, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
Simple o3: Towards interleaved vision-language reasoning.arXiv preprint arXiv:2508.12109, 2025
Ye Wang, Qianglong Chen, Zejun Li, Siyuan Wang, Shijie Guo, Zhirui Zhang, and Zhongyu Wei. Simple o3: Towards interleaved vision-language reasoning.arXiv preprint arXiv:2508.12109, 2025
-
[62]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[63]
V*: Guided visual search as a core mechanism in multimodal llms
Penghao Wu and Saining Xie. V*: Guided visual search as a core mechanism in multimodal llms. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13084–13094. IEEE, 2024. 13
2024
-
[64]
arXiv preprint arXiv:2503.12799 (2025)
Qiong Wu, Xiangcong Yang, Yiyi Zhou, Chenxin Fang, Baiyang Song, Xiaoshuai Sun, and Rongrong Ji. Grounded chain-of-thought for multimodal large language models.arXiv preprint arXiv:2503.12799, 2025
-
[65]
Realworldqa: A benchmark for evaluating spatial understanding and physical reasoning in the real world, 2024
xAI. Realworldqa: A benchmark for evaluating spatial understanding and physical reasoning in the real world, 2024. Benchmark release
2024
-
[66]
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. Mm-react: Prompting chatgpt for multimodal reasoning and action.arXiv preprint arXiv:2303.11381, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[67]
mPLUG-Owl3: Towards Long Image-Sequence Understanding in Multi-Modal Large Language Models
Jiabo Ye, Haiyang Xu, Haowei Liu, Anwen Hu, Ming Yan, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. mplug-owl3: Towards long image-sequence understanding in multi-modal large language models.arXiv preprint arXiv:2408.04840, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[68]
Differential transformer.arXiv preprint arXiv:2410.05258, 2024
Tianzhu Ye, Li Dong, Yuqing Xia, Yutao Sun, Yi Zhu, Gao Huang, and Furu Wei. Differential transformer.arXiv preprint arXiv:2410.05258, 2024
-
[69]
Runpeng Yu, Xinyin Ma, and Xinchao Wang. Introducing visual perception token into multi- modal large language model.arXiv preprint arXiv:2502.17425, 2025
-
[70]
Zoom-refine: Boosting high-resolution multimodal understanding via localized zoom and self-refinement, 2025
Xuan Yu, Dayan Guan, and Yanfeng Gu. Zoom-refine: Boosting high-resolution multimodal understanding via localized zoom and self-refinement, 2025
2025
-
[71]
Look twice: A generalist computational model predicts return fixations across tasks and species.PLoS computational biology, 18(11):e1010654, 2022
Mengmi Zhang, Marcelo Armendariz, Will Xiao, Olivia Rose, Katarina Bendtz, Margaret Livingstone, Carlos Ponce, and Gabriel Kreiman. Look twice: A generalist computational model predicts return fixations across tasks and species.PLoS computational biology, 18(11):e1010654, 2022
2022
-
[72]
Long Context Transfer from Language to Vision
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision. arXiv preprint arXiv:2406.16852, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[73]
Llava-next: A strong zero-shot video understanding model, April 2024
Yuanhan Zhang, Bo Li, haotian Liu, Yong jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. Llava-next: A strong zero-shot video understanding model, April 2024
2024
-
[74]
Automatic Chain of Thought Prompting in Large Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. Automatic chain of thought prompting in large language models.arXiv preprint arXiv:2210.03493, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[75]
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. Mul- timodal chain-of-thought reasoning in language models.arXiv preprint arXiv:2302.00923, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[76]
Chatspot: bootstrapping multimodal llms via precise referring instruction tuning
Liang Zhao, En Yu, Zheng Ge, Jinrong Yang, Haoran Wei, Hongyu Zhou, Jianjian Sun, Yuang Peng, Runpei Dong, Chunrui Han, et al. Chatspot: bootstrapping multimodal llms via precise referring instruction tuning. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, pages 1743–1752, 2024
2024
-
[77]
Llamafactory: Unified efficient fine-tuning of 100+ language models
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. Llamafactory: Unified efficient fine-tuning of 100+ language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), Bangkok, Thailand, 2024. Association for Computational Linguistics
2024
-
[78]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deepeyes: Incentivizing" thinking with images" via reinforcement learning.arXiv preprint arXiv:2505.14362, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[79]
Liangyu Zhong, Fabio Rosenthal, Joachim Sicking, Fabian Hüger, Thorsten Bagdonat, Hanno Gottschalk, and Leo Schwinn. Focus: Internal mllm representations for efficient fine-grained visual question answering.arXiv preprint arXiv:2506.21710, 2025
-
[80]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 14 A Appendix A.1 Additional Implementation Details Training Details.All SFT and GRPO experiments a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.