PInVerify: An Offline Embodied Benchmark for Active Instance Verification
Pith reviewed 2026-06-29 07:28 UTC · model grok-4.3
The pith
PInVerify benchmark shows MLLM agents verify fine-grained instances at 85.6 percent yet gain nothing reliable from choosing active viewpoints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
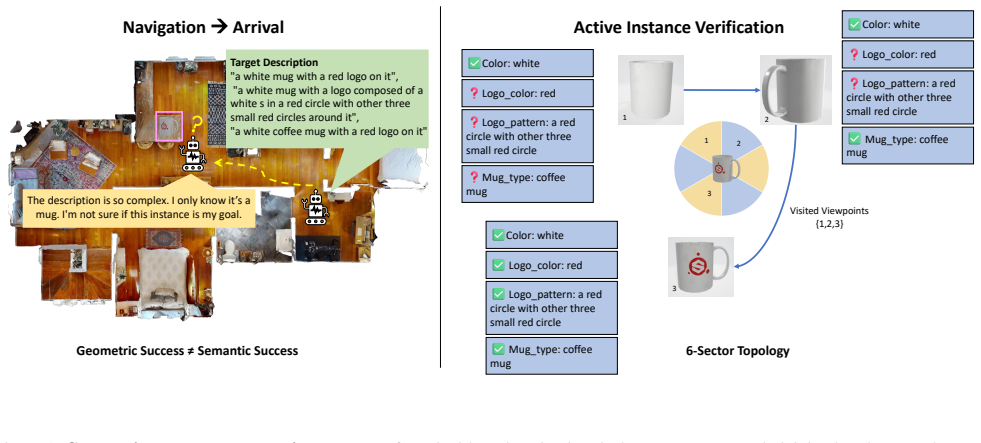
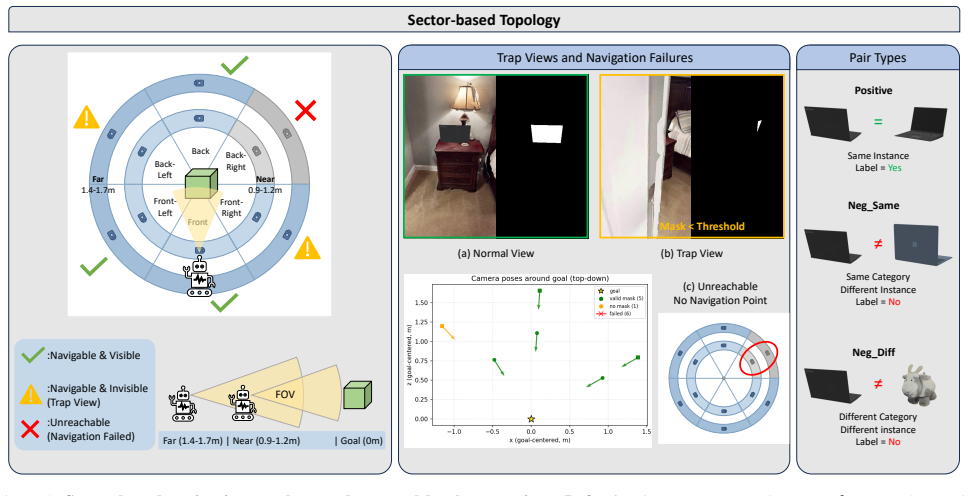
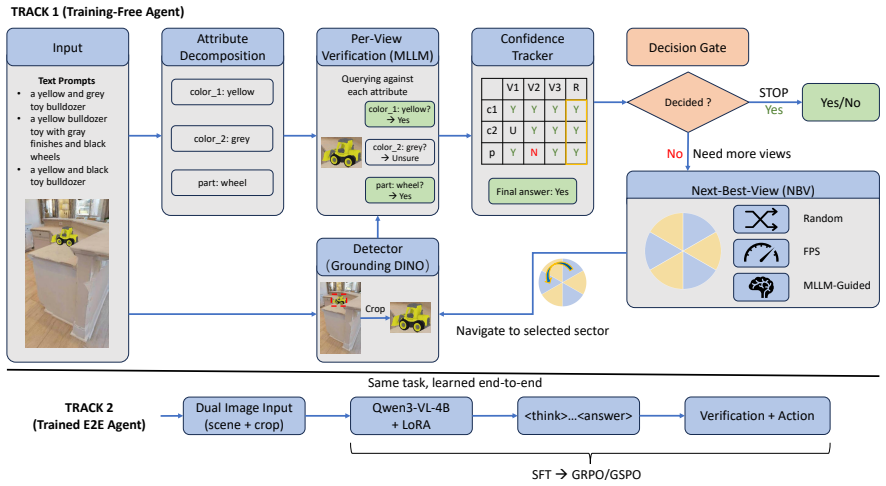
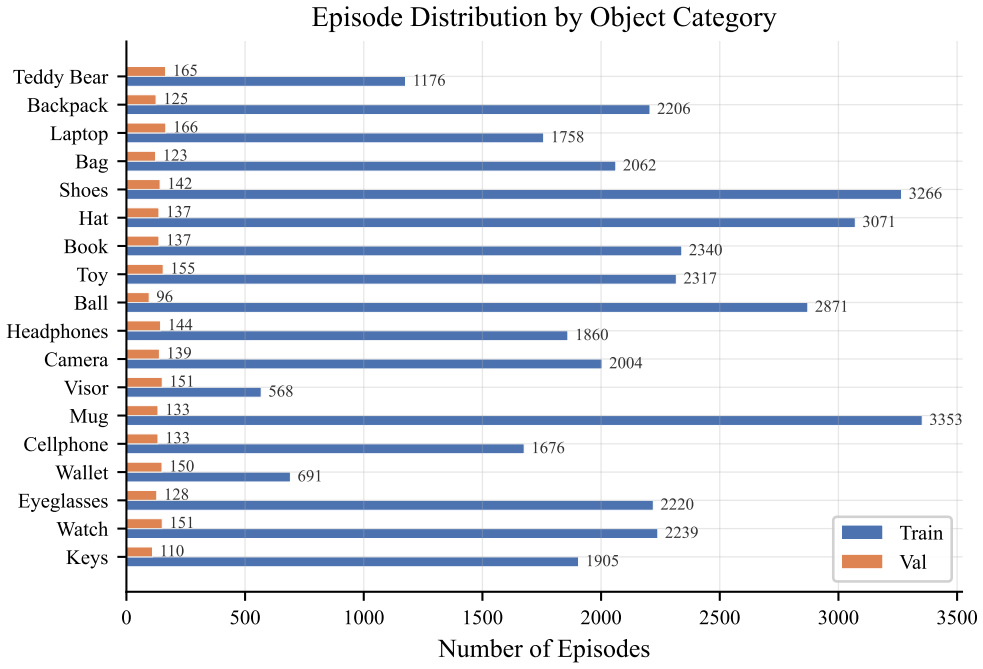
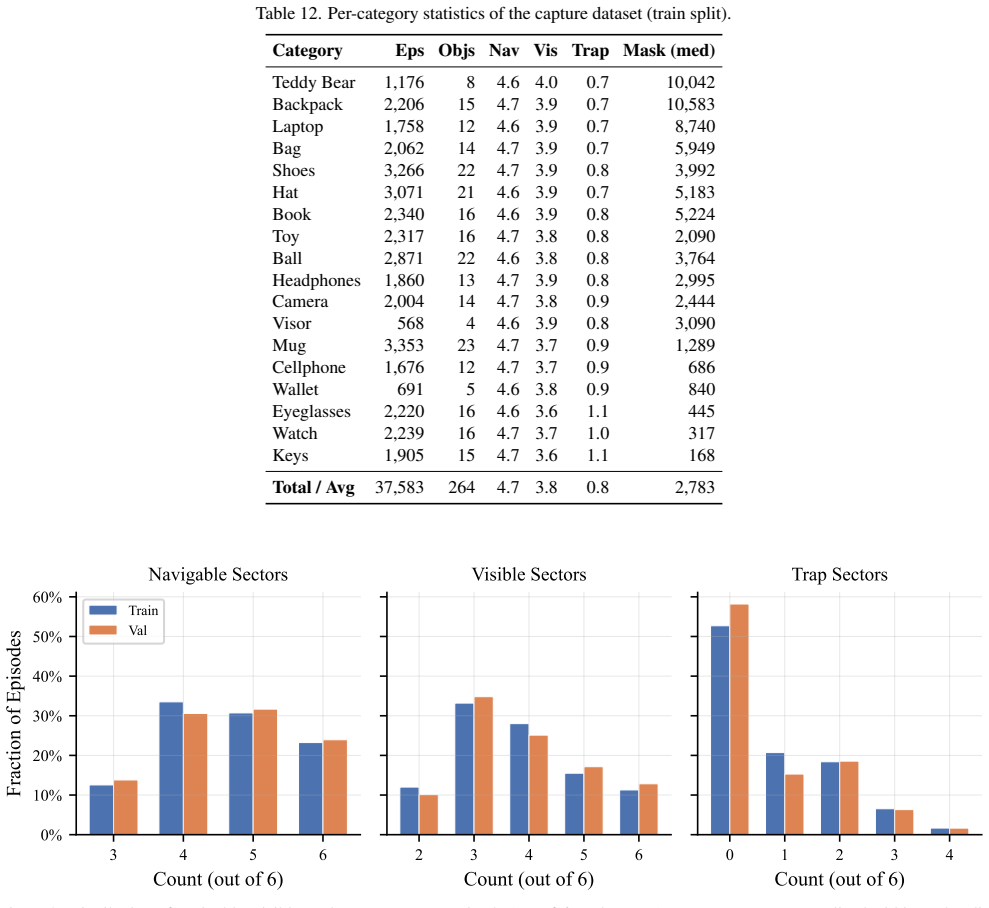
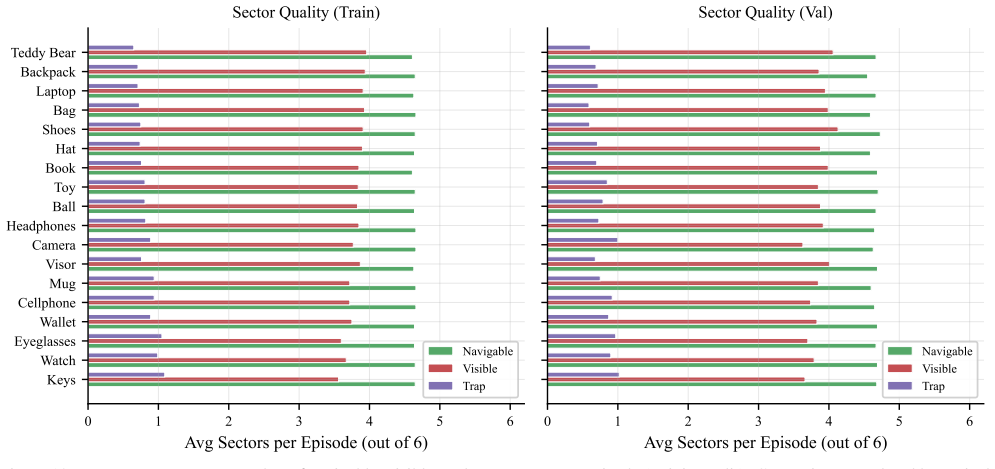
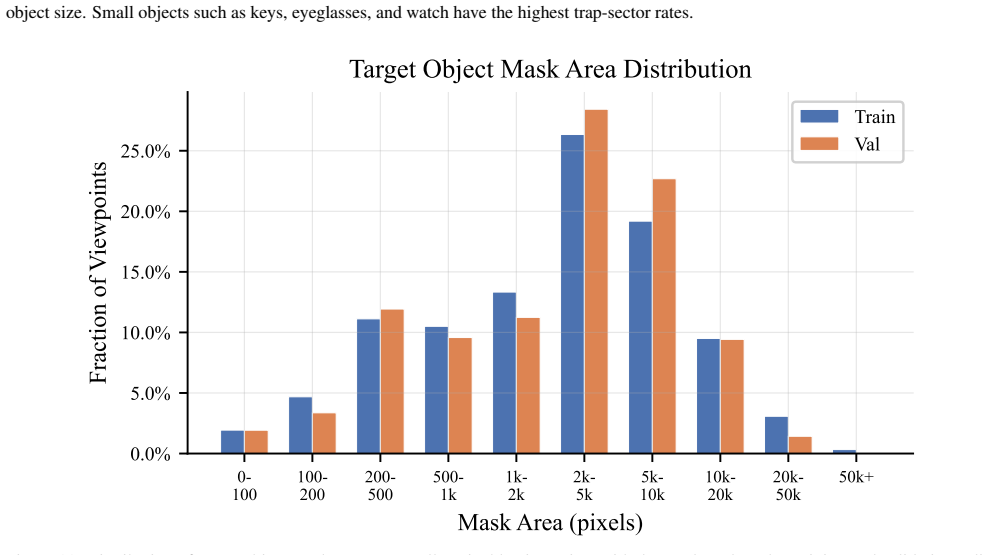
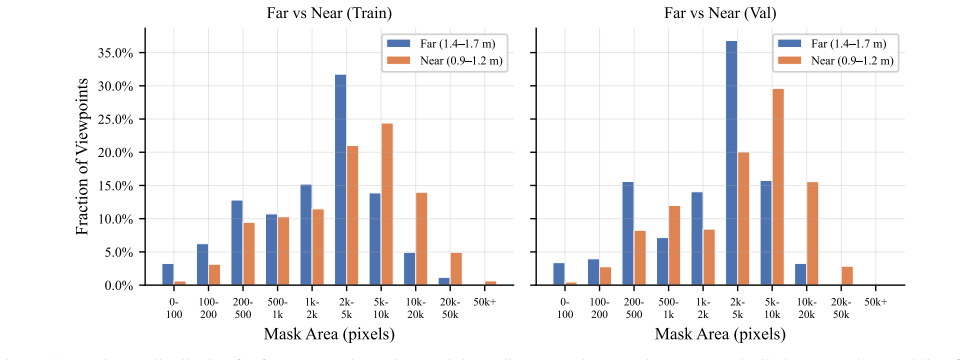
The authors formalize Active Instance Verification as a finite-horizon decision process and release PInVerify as an offline embodied benchmark that supplies 3,000 evaluation episodes with a 6-sector navigation topology exposing trap views and unreachable sectors; on this benchmark the best multimodal large-language-model baseline exceeds the best embedding baseline by 4.9 percentage points, ground-truth box ablations reveal a 3.1-point detection gap, tested next-best-view strategies yield no reliable gains, and a LoRA-fine-tuned agent using SFT plus GSPO reaches 85.6 percent accuracy.
What carries the argument
The 6-sector navigation topology with explicitly defined trap views and unreachable sectors that structures the finite-horizon decision process for viewpoint selection around candidate objects.
If this is right
- Ground-truth bounding boxes improve performance by 3.1 percentage points, indicating that perception errors remain a bottleneck.
- The best multimodal large-language-model pipeline outperforms the best embedding pipeline by 4.9 percentage points across the tested models.
- A LoRA-fine-tuned end-to-end agent reaches 85.6 percent accuracy on the 3,000-episode benchmark.
- None of the three next-best-view strategies tested delivers reliable accuracy gains over non-active baselines.
Where Pith is reading between the lines
- Attribute decomposition and visibility-weighted tracking appear more decisive for success than the choice of next-best-view rule in the current setup.
- The benchmark could be used to test whether models that explicitly reason about subtle attribute contrasts (floral versus striped) close the remaining gap to human-level verification.
- Adding explicit movement or time costs to the decision process might change whether active viewpoint selection becomes advantageous.
Load-bearing premise
The offline multi-view captures with fixed trap and unreachable sectors faithfully represent the information-gathering problems an agent would face when physically moving a camera in a real environment.
What would settle it
Deploy the same agents and next-best-view strategies on a physical robot in the same object categories and measure whether accuracy stays near 85.6 percent and whether active viewpoint selection produces measurable gains over random or fixed views.
Figures




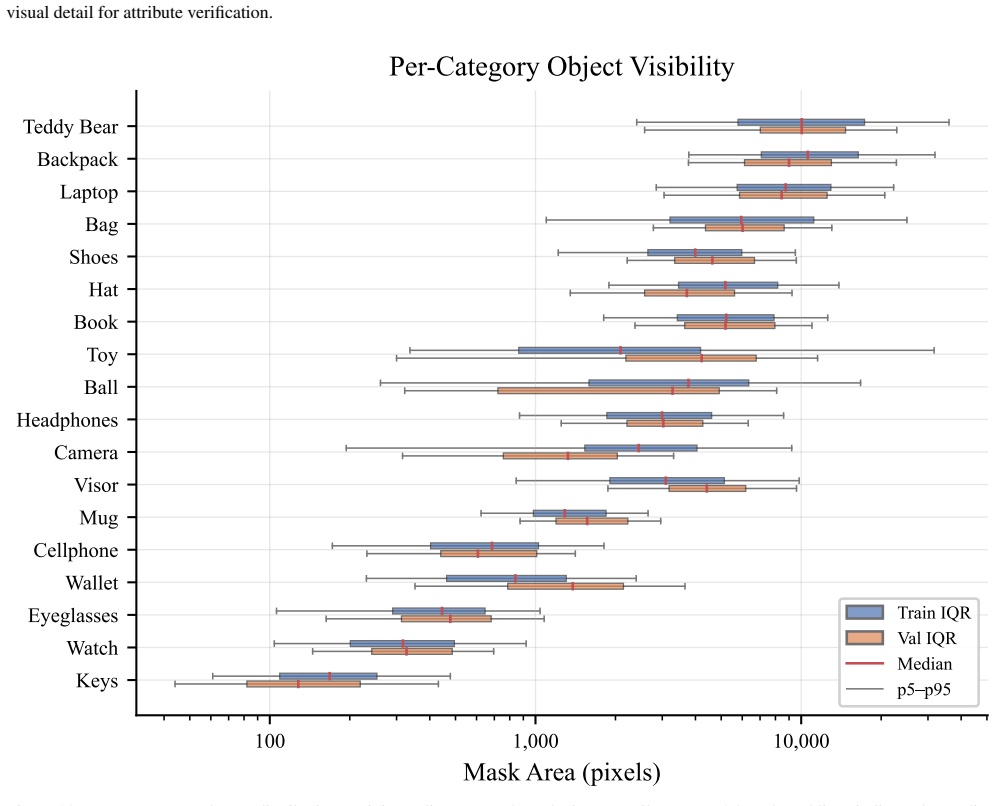
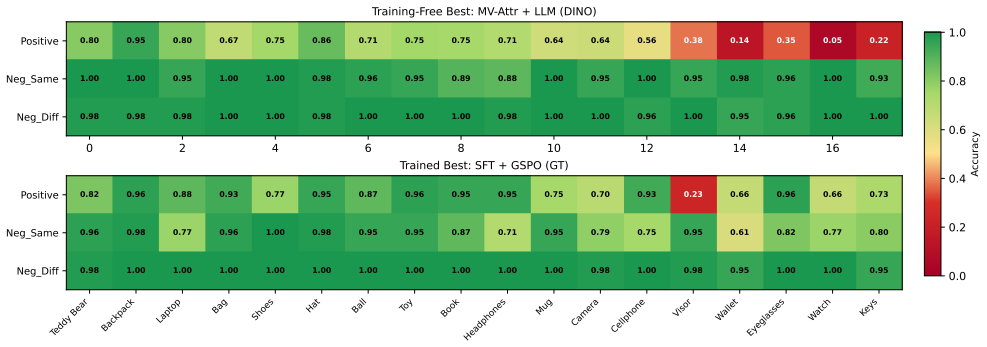


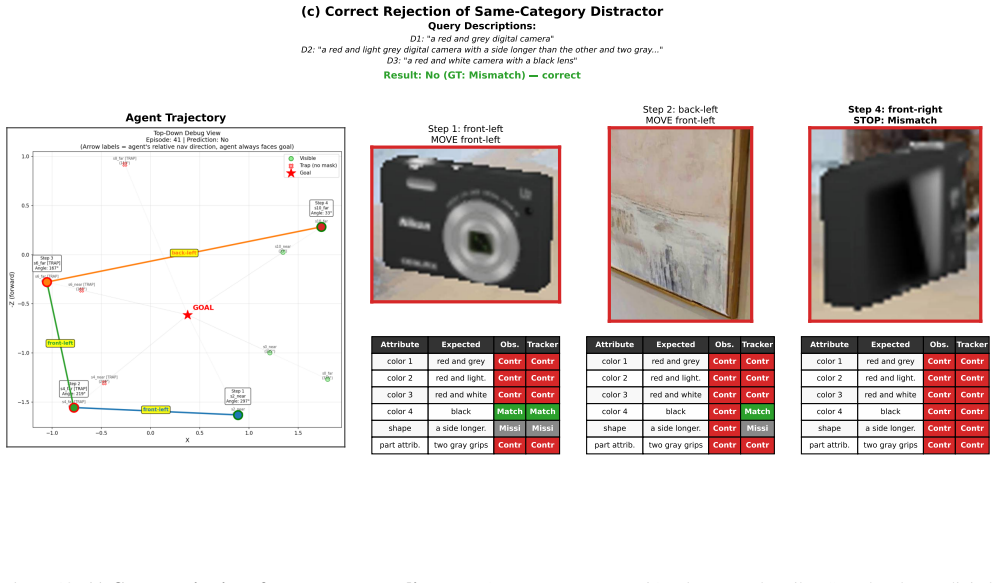

read the original abstract
Embodied agents have made strong progress in navigating to target objects, but reaching the goal vicinity does not guarantee that the agent has found the correct instance: subtle attribute differences (e.g., "white floral" vs. "white striped") often require close-range, multi-view inspection. We address this gap with Active Instance Verification (AIV), a task in which an agent actively selects viewpoints around a candidate object to decide whether it matches a fine-grained natural-language description. We formalize AIV as a finite-horizon decision process and introduce PInVerify, an offline embodied benchmark for AIV: 3,000 evaluation episodes across 18 object categories, delivered as multi-view captures with a 6-sector navigation topology that exposes trap views (navigable but uninformative) and unreachable sectors. As reference baselines we build a training-free pipeline and a LoRA-fine-tuned end-to-end agent around open-source multimodal large language models (MLLMs) at on-device scale ($\leq$8B parameters), with attribute decomposition, a visibility-weighted multi-view tracker, and three next-best-view (NBV) strategies. In our evaluation across Qwen3-VL (4B/8B), SenseNova-SI-1.2-InternVL3-8B, CLIP, and SigLIP2, the best MLLM-based baseline exceeds the best embedding baseline by 4.9 pp; GT-box ablations show a +3.1 pp detection gap; and we do not observe reliable gains from active viewpoint selection within the tested NBV strategies. A LoRA-fine-tuned agent (SFT+GSPO) reaches 85.6%. PInVerify aims to support further work on active, fine-grained semantic verification in embodied AI. Code: https://github.com/Avalon-S/PInVerify.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PInVerify, an offline embodied benchmark for Active Instance Verification (AIV) with 3,000 episodes across 18 categories delivered as 6-sector multi-view captures that include explicitly defined trap views and unreachable sectors. It evaluates training-free MLLM pipelines (Qwen3-VL 4B/8B, SenseNova-SI-1.2-InternVL3-8B) and embedding baselines (CLIP, SigLIP2) with attribute decomposition, visibility-weighted tracking, and three NBV strategies, plus a LoRA-fine-tuned SFT+GSPO agent. Key results: best MLLM baseline exceeds best embedding baseline by 4.9 pp; GT-box ablations yield +3.1 pp; no reliable gains from the tested NBV strategies; fine-tuned agent reaches 85.6%. Code is released.
Significance. If the benchmark's offline topology is accepted as a faithful proxy, the work supplies a reproducible, on-device-scale testbed for fine-grained embodied verification that highlights the value of MLLM attribute reasoning over pure embeddings and the sufficiency of passive multi-view aggregation in this setting. The public code release and explicit parameter counts strengthen reproducibility.
major comments (2)
- [§3] §3 (Benchmark Construction): The 6-sector topology with pre-specified trap views and unreachable sectors removes the discovery of informative viewpoints, so the headline finding that 'we do not observe reliable gains from active viewpoint selection within the tested NBV strategies' (abstract) rests on an assumption that may not generalize to real embodied movement; this is load-bearing for the central claim about NBV utility.
- [§4] §4 (Experiments): The statements of 4.9 pp and 3.1 pp gaps and 'no reliable gains' are given without error bars, per-episode variance, or statistical tests across the 3,000 episodes, so it is unclear whether the equivalence of NBV strategies is robust or sensitive to unstated sampling or aggregation choices.
minor comments (1)
- [Abstract, §4.1] The abstract and §4.1 would benefit from a brief explicit statement of how the 6-sector captures were collected and whether any real-robot validation was performed.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The 6-sector topology with pre-specified trap views and unreachable sectors removes the discovery of informative viewpoints, so the headline finding that 'we do not observe reliable gains from active viewpoint selection within the tested NBV strategies' (abstract) rests on an assumption that may not generalize to real embodied movement; this is load-bearing for the central claim about NBV utility.
Authors: The 6-sector topology with pre-specified trap views and unreachable sectors is a deliberate design choice to create a reproducible offline benchmark at on-device scale that isolates the verification decision process while still requiring agents to select among sectors that include uninformative options. The NBV evaluation and associated claim are therefore scoped to selection within this fixed topology. We acknowledge that this does not test discovery of informative viewpoints from arbitrary starting positions in open environments and that the headline finding may not generalize to full embodied navigation. We will revise the abstract, Section 3, and the discussion to explicitly qualify the scope of the NBV results and note this as a benchmark limitation. revision: partial
-
Referee: [§4] §4 (Experiments): The statements of 4.9 pp and 3.1 pp gaps and 'no reliable gains' are given without error bars, per-episode variance, or statistical tests across the 3,000 episodes, so it is unclear whether the equivalence of NBV strategies is robust or sensitive to unstated sampling or aggregation choices.
Authors: We agree that the reported performance gaps and the conclusion of no reliable NBV gains would be more robust with accompanying statistical analysis. We will add standard deviations (across episodes and categories), per-episode variance summaries where relevant, and statistical tests (e.g., paired significance tests) for the 4.9 pp MLLM-embedding gap, the 3.1 pp GT-box ablation, and the NBV strategy comparisons. These will be incorporated into the revised Section 4, tables, and figures. revision: yes
Circularity Check
Empirical benchmark paper with no load-bearing derivations or self-referential reductions
full rationale
The paper introduces PInVerify as an offline benchmark consisting of 3000 episodes with a fixed 6-sector topology and reports direct empirical results from training-free pipelines, LoRA-fine-tuned agents, and comparisons between MLLM and embedding baselines. No equations, fitted parameters, or predictions are defined such that any claimed outcome reduces to its own inputs by construction. The observation that tested NBV strategies yield no reliable gains is a measurement within the benchmark's pre-specified sectors rather than a self-definitional or fitted-input result. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The work is self-contained as an empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vision-and-language navigation: In- terpreting visually-grounded navigation instructions in real environments
Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko S ¨underhauf, Ian Reid, Stephen Gould, and Anton van den Hengel. Vision-and-language navigation: In- terpreting visually-grounded navigation instructions in real environments. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3674–3683,
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhao- hai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Jun- yang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shix...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Uncertainty-informed active perception for open vocabulary object goal navigation
Utkarsh Bajpai, Julius R¨uckin, Cyrill Stachniss, and Marija Popovi´c. Uncertainty-informed active perception for open vocabulary object goal navigation. InEuropean Conference on Mobile Robots (ECMR), 2025. arXiv:2506.13367. 2
-
[4]
Personalized instance-based nav- igation toward user-specific objects in realistic environments
Luca Barsellotti, Roberto Bigazzi, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. Personalized instance-based nav- igation toward user-specific objects in realistic environments. InAdvances in Neural Information Processing Systems, pages 11228–11250, 2024. arXiv:2410.18195. 1, 2, 3, 5, 27
-
[5]
Scaling spatial intelligence with multimodal foundation models
Zhongang Cai, Ruisi Wang, Chenyang Gu, Fanyi Pu, Junx- iang Xu, Yubo Wang, Wanqi Yin, Zhitao Yang, Chen Wei, Qingping Sun, Tongxi Zhou, Jiaqi Li, Hui En Pang, Oscar Qian, Yukun Wei, Zhiqian Lin, Xuanke Shi, Kewang Deng, Xiaoyang Han, Zukai Chen, Xiangyu Fan, Hanming Deng, Lewei Lu, Liang Pan, Bo Li, Ziwei Liu, Quan Wang, Dahua Lin, and Lei Yang. Scaling s...
-
[6]
Matterport3D: Learning from RGB-D Data in Indoor Environments
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Hal- ber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from RGB- D data in indoor environments. InInternational Conference on 3D Vision (3DV), pages 667–676, 2017. arXiv:1709.06158. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
Object goal navigation using goal-oriented semantic exploration
Devendra Singh Chaplot, Dhiraj Prakashchand Gandhi, Abhi- nav Gupta, and Russ R Salakhutdinov. Object goal navigation using goal-oriented semantic exploration. InAdvances in Neural Information Processing Systems, pages 4247–4258,
- [8]
-
[9]
Gennbv: Generalizable next-best-view policy for active 3d reconstruction
Xiao Chen, Quanyi Li, Tai Wang, Tianfan Xue, and Jiangmiao Pang. Gennbv: Generalizable next-best-view policy for active 3d reconstruction. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 16436–16445, 2024. arXiv:2402.16174. 2
-
[10]
Abhishek Das, Samyak Datta, Georgia Gkioxari, Stefan Lee, Devi Parikh, and Dhruv Batra. Embodied question answering. InProceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition, pages 1–10, 2018. arXiv:1711.11543. 3
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Objaverse-XL: A Universe of 10M+ 3D Objects
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram V oleti, Samir Yitzhak Gadre, et al. Objaverse-xl: A universe of 10m+ 3d objects. InAdvances in Neural In- formation Processing Systems, pages 35799–35813, 2023. arXiv:2307.05663. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Mengfei Du, Binhao Wu, Zejun Li, Xuanjing Huang, and Zhongyu Wei. EmbSpatial-Bench: Benchmarking spatial understanding for embodied tasks with large vision-language models. InProceedings of the Annual Meeting of the Associa- tion for Computational Linguistics, 2024. arXiv:2406.05756. 3, 5
-
[13]
Multi-view active fine- grained visual recognition
Ruoyi Du, Wenqing Yu, Heqing Wang, Ting-En Lin, Dongliang Chang, and Zhanyu Ma. Multi-view active fine- grained visual recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023. arXiv:2206.01153. 2
-
[14]
Next best view plan- ning for active model improvement
Enrique Dunn and Jan-Michael Frahm. Next best view plan- ning for active model improvement. InBMVC, pages 1–11,
-
[15]
Evidential active recognition: Intelligent and prudent open- world embodied perception
Lei Fan, Mingfu Liang, Yunxuan Li, Gang Hua, and Ying Wu. Evidential active recognition: Intelligent and prudent open- world embodied perception. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16351–16361, 2024. arXiv:2311.13793. 2
-
[16]
BLINK: Multimodal Large Language Models Can See but Not Perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A. Smith, Wei-Chiu Ma, and Ranjay Krishna. BLINK: Multimodal large language mod- els can see but not perceive. InEuropean Conference on Computer Vision, 2024. arXiv:2404.12390. 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Arnold: A benchmark for language-grounded task learning with continuous states in realistic 3d scenes
Ran Gong, Jiangyong Huang, Yizhou Zhao, Haoran Geng, Xi- aofeng Gao, Qingyang Wu, Wensi Ai, Ziheng Zhou, Demetri Terzopoulos, Song-Chun Zhu, et al. Arnold: A benchmark for language-grounded task learning with continuous states in realistic 3d scenes. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 20483–20495,
-
[18]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. arXiv:2106.09685. 6
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Neu-nbv: Next best view planning using uncertainty estima- tion in image-based neural rendering
Liren Jin, Xieyuanli Chen, Julius R¨uckin, and Marija Popovi´c. Neu-nbv: Next best view planning using uncertainty estima- tion in image-based neural rendering. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 11305–11312. IEEE, 2023. arXiv:2303.01284. 1, 2
-
[20]
Goat-bench: A benchmark for multi-modal lifelong navigation
Mukul Khanna, Ram Ramrakhya, Gunjan Chhablani, Sriram Yenamandra, Theophile Gervet, Matthew Chang, Zsolt Kira, Devendra Singh Chaplot, Dhruv Batra, and Roozbeh Mot- taghi. Goat-bench: A benchmark for multi-modal lifelong navigation. InProceedings of the IEEE/CVF Conference 9 on Computer Vision and Pattern Recognition, pages 16373– 16383, 2024. arXiv:2404....
-
[21]
Juil Koo, Daehyeon Choi, Sangwoo Youn, Phillip Y . Lee, and Minhyuk Sung. Toward ambulatory vision: Learn- ing visually-grounded active view selection.arXiv preprint arXiv:2512.13250, 2025. 3
-
[22]
Instance-aware exploration-verification-exploitation for in- stance imagegoal navigation
Xiaohan Lei, Min Wang, Wengang Zhou, Li Li, and Houqiang Li. Instance-aware exploration-verification-exploitation for in- stance imagegoal navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16329–16339, 2024. arXiv:2402.17587. 3
-
[23]
iGibson 2.0: Object-centric simulation for robot learning of everyday household tasks
Chengshu Li, Fei Xia, Roberto Mart´ın-Mart´ın, Michael Lin- gelbach, Sanjana Srivastava, Bokui Shen, Kent Vainio, Cem Gokmen, Gokul Dharan, Tanish Jain, et al. iGibson 2.0: Object-centric simulation for robot learning of everyday household tasks. InProceedings of the 5th Conference on Robot Learning (CoRL), 2022. arXiv:2108.03272. 2
-
[24]
Chengshu Li, Ruohan Zhang, Josiah Wong, Cem Gokmen, Sanjana Srivastava, Roberto Mart ´ın-Mart´ın, Chen Wang, Gabrael Levine, Michael Lingelbach, Jiankai Sun, et al. Behavior-1k: A benchmark for embodied ai with 1,000 every- day activities and realistic simulation. InConference on Robot Learning, pages 80–93. PMLR, 2023. arXiv:2403.09227. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Compassnav: Steering from path imitation to decision understanding in navigation
LinFeng Li, Jian Zhao, Yuan Xie, Xin Tan, and Xuelong Li. Compassnav: Steering from path imitation to decision understanding in navigation. InInternational Conference on Learning Representations (ICLR), 2026. arXiv:2510.10154. 1, 3
-
[26]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean Conference on Computer Vision, pages 38–55. Springer, 2024. arXiv:2303.05499. 3, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Wufei Ma, Haoyu Chen, Guofeng Zhang, Yu-Cheng Chou, Jieneng Chen, Celso M. de Melo, and Alan Yuille. 3DSR- Bench: A comprehensive 3d spatial reasoning benchmark. InInternational Conference on Computer Vision, 2025. arXiv:2412.07825. 3, 5
-
[28]
Openeqa: Embodied question answering in the era of foundation models
Arjun Majumdar, Anurag Ajay, Xiaohan Zhang, Pranav Putta, Sriram Yenamandra, Mikael Henaff, Sneha Silwal, Paul Mc- vay, Oleksandr Maksymets, Sergio Arnaud, et al. Openeqa: Embodied question answering in the era of foundation models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16488–16498, 2024. 3, 5
2024
-
[29]
Generation and Comprehension of Unambiguous Object Descriptions
Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Cam- buru, Alan L Yuille, and Kevin Murphy. Generation and comprehension of unambiguous object descriptions. InPro- ceedings of the IEEE conference on computer vision and pattern recognition, pages 11–20, 2016. arXiv:1511.02283. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[30]
Atlas: End- to-end 3d scene reconstruction from posed images
Zak Murez, Tarrence van As, James Bartolozzi, Ayan Sinha, Vijay Badrinarayanan, and Andrew Rabinovich. Atlas: End- to-end 3d scene reconstruction from posed images. InECCV,
-
[31]
Reverie: Remote embodied visual referring expression in real indoor environments
Yuankai Qi, Qi Wu, Peter Anderson, Xin Wang, William Yang Wang, Chunhua Shen, and Anton van den Hengel. Reverie: Remote embodied visual referring expression in real indoor environments. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9982– 9991, 2020. arXiv:1904.10151. 2, 5
-
[32]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021. arXiv:2103.00020. 7
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[33]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct prefer- ence optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Sys- tems, 2023. arXiv:2305.18290. 6, 27
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI
Santhosh K Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alex Clegg, John Turner, Eric Under- sander, Wojciech Galuba, Andrew Westbury, Angel X Chang, et al. Habitat-matterport 3d dataset (HM3D): 1000 large-scale 3d environments for embodied AI. InAdvances in Neural Information Processing Systems (Datasets and Benchmarks Track), 2021. a...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[35]
Habitat: A platform for embodied ai research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied ai research. InProceedings of the IEEE/CVF international conference on computer vision, pages 9339– 9347, 2019. arXiv:1904.01201. 3
-
[36]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junx- iao Song, Mingchuan Zhang, YK Li, Y Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muham- mad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Andreas Steiner, et al. Siglip 2: Multilingual vision-language en- coders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
View planning for 3d object reconstruction with a mobile manipulator robot
Juan Ignacio Vasquez-Gomez, Luis Enrique Sucar, and Rafael Murrieta-Cid. View planning for 3d object reconstruction with a mobile manipulator robot. InIROS, 2014. 1, 2
2014
-
[39]
Static and plugged: Make em- bodied evaluation simple.arXiv preprint arXiv:2508.06553,
Jiahao Xiao, Jianbo Zhang, BoWen Yan, Shengyu Guo, Tongrui Ye, Kaiwei Zhang, Zicheng Zhang, Xiaohong Liu, Zhengxue Cheng, Lei Fan, et al. Static and plugged: Make em- bodied evaluation simple.arXiv preprint arXiv:2508.06553,
-
[40]
Neural visibility field for uncertainty-driven active mapping
Shangjie Xue, Jesse Dill, Pranay Mathur, Frank Dellaert, Panagiotis Tsiotras, and Danfei Xu. Neural visibility field for uncertainty-driven active mapping. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18122–18132, 2024. arXiv:2406.06948. 2
-
[41]
Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces
Jihan Yang, Shusheng Yang, Anjali W. Gupta, Rilyn Han, Fei- Fei Li, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. In 10 Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, 2025. arXiv:2412.14171. 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Hm3d-ovon: A dataset and bench- mark for open-vocabulary object goal navigation
Naoki Yokoyama, Ram Ramrakhya, Abhishek Das, Dhruv Batra, and Sehoon Ha. Hm3d-ovon: A dataset and bench- mark for open-vocabulary object goal navigation. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5543–5550. IEEE, 2024. arXiv:2409.14296. 1, 2, 5
-
[43]
Modeling Context in Referring Expressions
Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling context in referring expressions. InEuropean conference on computer vision, pages 69–85. Springer, 2016. arXiv:1608.00272. 1, 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[44]
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yun- lin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, et al. Swift: a scalable lightweight infras- tructure for fine-tuning. InProceedings of the AAAI Con- ference on Artificial Intelligence, pages 29733–29735, 2025. arXiv:2408.05517. 25
-
[45]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. Group sequence policy optimization, 2025. arXiv:2507.18071. 6, 27
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Sheng- long Ye, Lixin Gu, Hao Tian, Yuchen Duan, et al. Internvl3: Exploring advanced training and test-time recipes for open- source multimodal models.arXiv preprint arXiv:2504.10479,
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
ACTIVE-o3: Empowering MLLMs with Active Perception via Pure Reinforcement Learning
Muzhi Zhu, Hao Zhong, Canyu Zhao, Zongze Du, Zheng Huang, Mingyu Liu, Hao Chen, Cheng Zou, Jingdong Chen, Ming Yang, et al. Active-o3: Empowering multimodal large language models with active perception via grpo.arXiv preprint arXiv:2505.21457, 2025. 3 11 Supplementary Material App. A gives the multi-view capture pipeline; App. B a trap-view capture exampl...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Sampleα∼ U(α min, αmax)
-
[49]
Compute candidate:x=g x +rcosα,z=g z +rsinα
-
[50]
Snap to the nearest navigable point on the NavMesh via the Habitat pathfinder
-
[51]
Ray-aligned sampling..To align the near view with the far view’s directionθ far:
Accept if the snapped point is navigable; reject otherwise. Ray-aligned sampling..To align the near view with the far view’s directionθ far:
-
[52]
On the first attempt, useθ=θ far exactly
-
[53]
On subsequent attempts, add a small perturbation:θ=θ far +δ, whereδ∼ U(−2 ◦,+2 ◦)
-
[54]
Compute candidate:x=g x +rcosθ,z=g z +rsinθ
-
[55]
navigable sectors
Snap and validate as in ring sampling. Up to 3 ray-aligned attempts are made before falling back to unconstrained ring sampling within the sector. A.5. Frustum Visibility Check After positioning the agent and orienting the camera toward the goal, a frustum check verifies that the goal position falls within the camera’s field of view. Given the camera’s or...
-
[56]
Parses the viewpoint array (supporting both v1 and v2 format)
-
[57]
Identifies valid start sectors: sectors where at least one viewpoint hasmask meets threshold = true
-
[58]
Counts navigable sectors (sectors with at least one navigable viewpoint) and mask-visible sectors
-
[59]
episode_path
Emits a JSONL record with episode metadata and sector statistics. Output..A temporary raw index file ( tmp raw.jsonl) where each line is a JSON object: { "episode_path": "val/scene_name/episode_id", "scene": "scene_key", "episode": "episode_id", "target_object_id": "object_id", "target_object_category": "category", "valid_start_sectors": [0, 2, 4], "navig...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.