A Lifecycle and Application-Stack Survey of Large Language Model Vulnerabilities: Attacks, Risks, Defenses, and Open Problems
Pith reviewed 2026-07-01 04:41 UTC · model grok-4.3
The pith
LLM vulnerabilities must be analyzed across an eight-stage lifecycle and application stack because attacks and risks affect eight distinct security objectives and point defenses rarely compose.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
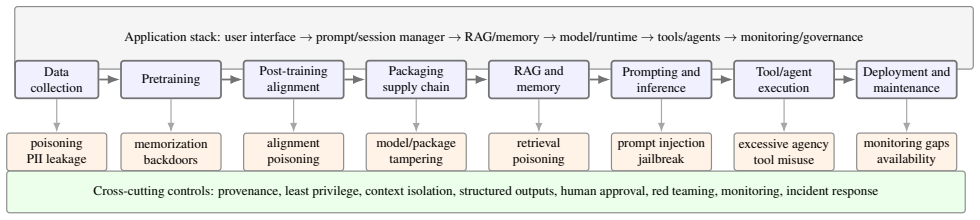
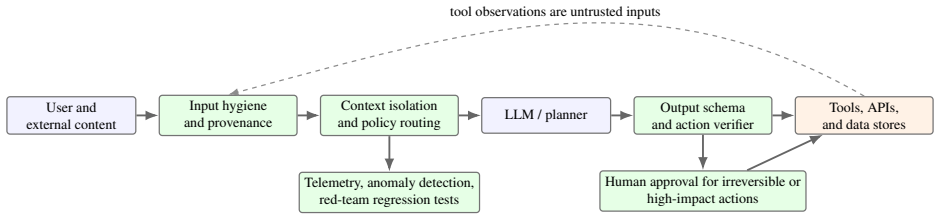
The paper claims that LLM system vulnerabilities are best systematized by organizing attacks across eight stages—data collection, pretraining, post-training alignment, model packaging and supply chain, retrieval and memory, prompting and inference, tool/agent execution, and deployment/maintenance—and by mapping LLM-specific vulnerabilities to the objectives of confidentiality, integrity, availability, safety, privacy, fairness, accountability, and agency-control. This lens reveals where trust boundaries fail, how untrusted data becomes executable instruction, how delegated authority amplifies model errors, and why point defenses rarely compose into overall security.
What carries the argument
The eight-stage lifecycle model of LLM systems paired with the mapping of vulnerabilities to eight security objectives.
If this is right
- Compositional security analysis is required rather than stage-isolated defenses.
- Provenance-aware retrieval mechanisms are needed to stop untrusted data from becoming instructions.
- Tool-call containment is necessary to limit the impact of errors in agent execution.
- Long-horizon evaluation of agents and realistic red teaming are needed to assess real deployment risks.
- Privacy-preserving adaptation and deployment-grade incident response remain open research needs.
Where Pith is reading between the lines
- The framework could be used to audit a deployed coding assistant by tracing a single data-poisoning attack through retrieval, prompting, and tool execution stages.
- Fairness failures in pretraining may interact with agency-control failures during long-horizon agent tasks in ways the current mapping leaves unexamined.
- Stage-specific logging could support accountability by allowing incident responders to identify the exact lifecycle point where control was lost.
- New benchmarks that simulate cross-stage attacks would be a direct way to test whether the claimed non-composition of defenses holds in practice.
Load-bearing premise
That the chosen eight-stage lifecycle division and the mapping to security objectives accurately reveal where trust boundaries fail and why point defenses rarely compose.
What would settle it
An empirical demonstration that a small number of point defenses do compose to protect an end-to-end LLM application across all eight stages, or a study showing that observed attacks cluster in patterns that the eight-stage division does not predict.
Figures
read the original abstract
Large language models are no longer only text generators. They are increasingly embedded in retrieval pipelines, enterprise assistants, coding environments, robotic systems, security-operation workflows, and autonomous agents that can read private data, call tools, write files, execute code, and act across organizational boundaries. This shift changes the security problem: risks do not arise from the model weights alone, but from the full lifecycle and application stack through which data, prompts, model outputs, tools, memories, and user authority interact. This paper systematizes the literature on vulnerabilities in large language model systems through a lifecycle and application-stack lens. We organize attacks across eight stages: data collection, pretraining, post-training alignment, model packaging and supply chain, retrieval and memory, prompting and inference, tool/agent execution, and deployment/maintenance. For each stage, we analyze attacker capabilities, affected security objectives, representative attacks, practical risks, evaluation practices, and defenses. We further map LLM-specific vulnerabilities to confidentiality, integrity, availability, safety, privacy, fairness, accountability, and agency-control objectives. Unlike taxonomies that list isolated attack names, the proposed systematization emphasizes where trust boundaries fail, how untrusted data becomes executable instruction, how delegated authority amplifies model errors, and why point defenses rarely compose. We close with a research agenda for secure LLM systems, including compositional security, provenance-aware retrieval, tool-call containment, long-horizon agent evaluation, privacy-preserving adaptation, realistic red teaming, and deployment-grade incident response.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to systematize the literature on LLM system vulnerabilities via an eight-stage lifecycle (data collection, pretraining, post-training alignment, model packaging and supply chain, retrieval and memory, prompting and inference, tool/agent execution, deployment/maintenance) and a mapping of vulnerabilities to eight security objectives (confidentiality, integrity, availability, safety, privacy, fairness, accountability, agency-control). It argues that this lens reveals trust-boundary failures, how untrusted data becomes executable, how delegated authority amplifies errors, and why point defenses rarely compose, and closes with a research agenda on compositional security, provenance-aware retrieval, tool-call containment, and related topics.
Significance. If the survey delivers balanced coverage and accurate representation of cited works, the lifecycle-plus-objectives framework would be a useful organizing contribution for the field. It shifts focus from isolated model attacks to full-stack interactions and supplies a concrete research agenda with falsifiable directions such as long-horizon agent evaluation and deployment-grade incident response. The absence of new derivations or fitted parameters is appropriate for a survey; the value lies in the systematization itself.
minor comments (2)
- Abstract: the eight stages are listed but the mapping to the eight security objectives is only named; adding one concrete cross-stage example (e.g., how a data-collection poisoning attack affects both integrity and agency-control) would improve reader orientation without lengthening the abstract excessively.
- Throughout: ensure every stage section explicitly states the attacker capabilities, affected objectives, representative attacks, risks, evaluation practices, and defenses as promised; if any stage omits one of these six elements, the claimed uniformity of treatment is weakened.
Simulated Author's Rebuttal
We thank the referee for the thorough summary and positive assessment of the paper's contribution. The recommendation for minor revision is noted, but the report contains no specific major comments requiring response or changes.
Circularity Check
No significant circularity: survey organizes literature without derivations or self-referential reductions
full rationale
The paper is a literature survey that proposes an eight-stage lifecycle framework and a mapping to security objectives as an organizing lens. No equations, fitted parameters, predictions, or derivations appear in the abstract or described structure. The central contribution is systematization of existing attacks and defenses; the framework is presented explicitly as an organizing device rather than a theorem or empirical result derived from its own inputs. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results as new derivations are detectable. The assumption that the chosen stages reveal trust-boundary failures is a modeling choice, not a circular reduction. This matches the default expectation for non-circular survey papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Y . Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones, A. Chen, A. Goldie, A. Mirhoseini, C. McKinnon, et al. Constitutional AI: Harmlessness from AI feedback.arXiv preprint arXiv:2212.08073,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
On the Opportunities and Risks of Foundation Models
R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brun- skill, et al. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems, volume 33, pages 1877–1901,
1901
-
[4]
X. Chen, C. Liu, B. Li, K. Lu, and D. Song. Targeted backdoor attacks on deep learning systems using data poisoning.arXiv preprint arXiv:1712.05526,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
K. Chu. A systematic survey of security threats and defenses in LLM-based AI agents: A layered attack surface framework. arXiv preprint arXiv:2604.23338,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
SoK: The attack surface of agentic AI — tools, and autonomy,
A. Dehghantanha et al. SoK: The attack surface of agentic AI – tools, and autonomy.arXiv preprint arXiv:2603.22928,
- [7]
-
[8]
L. Derczynski, E. Galinkin, J. Martin, S. Majumdar, N. Inie, et al. garak: A framework for security probing large language models.arXiv preprint arXiv:2406.11036,
-
[9]
E. Derner and K. Batistic. A security risk taxonomy for large language models.arXiv preprint arXiv:2309.06899,
-
[10]
Checkmarks indicate primary coverage; partial coverage indicates that the topic is discussed but not used as an organizing axis
16 Table 7: Positioning of this survey relative to representative surveys and practitioner frameworks. Checkmarks indicate primary coverage; partial coverage indicates that the topic is discussed but not used as an organizing axis. Work / framework Lifecycle RAG Agents Privacy Supply chain Defenses EvaluationMain distinction LLM security/privacy surveys (...
2025
-
[11]
partial partial partial partial✓ ✓ emphasize model capabilities, alignment, and evaluation Agent-security surveys (Chu, 2026; Ferrag et al., 2025; Ling et al.,
2026
-
[12]
✓partial partial✓partial✓partial general adversarial ML terminology and lifecycle stages This survey✓ ✓ ✓ ✓ ✓ ✓ ✓unifies lifecycle stage, application stack, security objective, attacker capability, and defense layer M. A. Ferrag, N. Tihanyi, D. Hamouda, L. Maglaras, A. Lakas, and M. Debbah. From prompt injections to protocol ex- ploits: Threats in LLM-pow...
-
[13]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
D. Ganguli, L. Lovitt, J. Kernion, A. Askell, Y . Bai, S. Ka- davath, B. Mann, E. Perez, N. Schiefer, K. Ndousse, et al. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned.arXiv preprint arXiv:2209.07858,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
- [15]
-
[16]
Y . Ling, S. Yu, Z. Chen, and C. Fang. Toward secure LLM agents: Threat surfaces, attacks, defenses, and evaluation. arXiv preprint arXiv:2606.10749,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Y . Liu, G. Deng, Z. Xu, Y . Li, Y . Zheng, Y . Zhang, L. Zhao, T. Zhang, K. Wang, and Y . Liu. Prompt injection at- tack against LLM-integrated applications.arXiv preprint arXiv:2306.05499, 2023a. Y . Liu, Y . Yao, J. Ton, X. Zhang, R. Cheng, Y . Klochkov, M. F. Taufiq, and H. Li. Trustworthy LLMs: A survey and guideline for evaluating large language mod...
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Accessed 2026-06-29
URL https:// atlas.mitre.org/. Accessed 2026-06-29. M. Nasr, R. Shokri, and A. Houmansadr. Comprehensive pri- vacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning. IEEE Symposium on Security and Privacy,
2026
-
[19]
A Comprehensive Overview of Large Language Models
H. Naveed, A. U. Khan, S. Qiu, M. Saqib, S. Anwar, M. Us- man, N. Akhtar, N. Barnes, and A. Mian. A comprehen- sive overview of large language models.arXiv preprint arXiv:2307.06435,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
OpenAI. GPT-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
OWASP top 10 for large language model applications 2025,
OWASP GenAI Security Project. OWASP top 10 for large language model applications 2025,
2025
-
[22]
Ignore Previous Prompt: Attack Techniques For Language Models
URL https:// genai.owasp.org/llm-top-10/. Accessed 2026- 06-29. F. Perez and I. Ribeiro. Ignore previous prompt: At- tack techniques for language models.arXiv preprint arXiv:2211.09527,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
X. Qi, Y . Zeng, T. Xie, P.-Y . Chen, R. Jia, P. Mittal, and P. Hen- derson. Fine-tuning aligned language models compromises safety, even when users do not intend to!arXiv preprint arXiv:2310.03693,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Y . Qin, S. Liang, Y . Ye, K. Zhu, L. Yan, Y . Lu, Y . Lin, X. Cong, X. Tang, B. Qian, et al. ToolLLM: Facilitating large language models to master 16000+ real-world APIs.arXiv preprint arXiv:2307.16789,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Er- mon, and C. Finn. Direct preference optimization: Your language model is secretly a reward model.arXiv preprint arXiv:2305.18290,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
A. Wei, N. Haghtalab, and J. Steinhardt. Jailbroken: How does LLM safety training fail?arXiv preprint arXiv:2307.02483,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Ethical and social risks of harm from Language Models
L. Weidinger, J. Mellor, M. Rauh, C. Griffin, J. Uesato, P.-S. Huang, M. Cheng, A. Glaese, B. Balle, A. Kasirzadeh, et al. Ethical and social risks of harm from language models.arXiv preprint arXiv:2112.04359,
work page internal anchor Pith review Pith/arXiv arXiv
- [28]
- [29]
- [30]
-
[31]
AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents
R. Zhang et al. AgentDojo: A dynamic environment to eval- uate attacks and defenses for LLM agents.arXiv preprint arXiv:2406.13352,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
W. Zhao, Z. Li, P. Zhang, and J. Sun. ClawGuard: A runtime security framework for tool-augmented LLM agents against indirect prompt injection.arXiv preprint arXiv:2604.11790,
work page internal anchor Pith review Pith/arXiv arXiv
- [33]
-
[34]
18 D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Rad- ford, D. Amodei, P. Christiano, and G. Irving. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[35]
A. Zou, Z. Wang, J. Z. Kolter, and M. Fredrikson. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.