A Multimodal 3D Foundation Model for Light Sheet Fluorescence Microscopy Enables Few-Shot Segmentation, Classification, and Deblurring
Pith reviewed 2026-06-29 22:58 UTC · model grok-4.3
The pith
A 3D foundation model pretrained on light sheet microscopy volumes enables few-shot adaptation to segmentation, classification, and deblurring.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
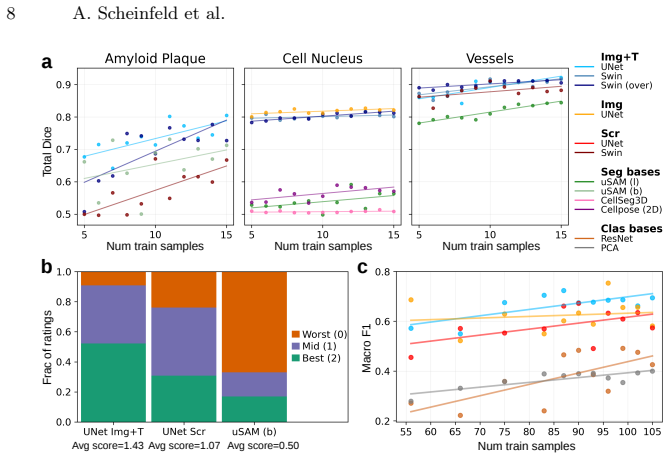
The pretrained backbone drastically reduces the annotation burden, enabling efficient, few-shot adaptation for varied downstream tasks. We evaluate this approach on downstream segmentation, classification, and deblurring. Our results demonstrate consistent improvements over baselines, when measured using standard evaluation metrics and when rigorously assessed by domain experts. This highlights the potential of foundation model pretraining to reduce annotation requirements while improving performance across diverse LSM analysis tasks.
What carries the argument
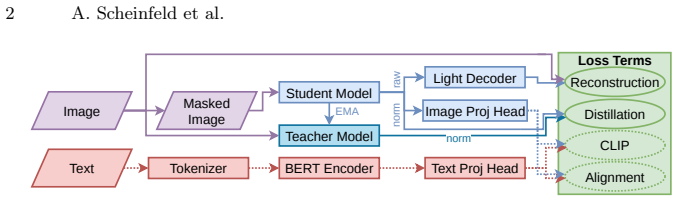
The 3D foundation model backbone pretrained jointly via masked reconstruction and image-text alignment on a large multi-organism LSM collection, which then serves as the starting point for few-shot task adaptation.
If this is right
- Few-shot segmentation of cellular structures and vascular networks in new LSM volumes requires far fewer manual annotations than training from scratch.
- Classification of 3D LSM images by organism, stain, or pathology achieves higher accuracy after adaptation of the same backbone.
- Deblurring of volumetric LSM data improves when the pretrained representations are fine-tuned with limited paired examples.
- The same pretrained weights support multiple tasks without retraining the entire model from random initialization for each one.
- Performance gains remain stable across variations in imaging protocols and biological specimens not seen during pretraining.
Where Pith is reading between the lines
- If the image-text alignment component incorporates richer metadata, the model could support additional zero-shot retrieval or captioning tasks on LSM archives.
- The approach suggests that similar joint reconstruction and alignment objectives could be tested on other high-dimensional microscopy modalities that also suffer from annotation scarcity.
- Public release of the weights allows direct measurement of how much the pretraining reduces the number of required labels on any new LSM collection.
- Extending the pretraining corpus with more recent high-resolution volumes could further test whether the observed transfer gains scale with data diversity.
Load-bearing premise
That pretraining via masked reconstruction plus image-text alignment on the curated multi-organism LSM collection produces representations that transfer effectively to new LSM datasets and tasks with only few-shot labels.
What would settle it
A test on an independent LSM dataset in which few-shot fine-tuning of the pretrained model shows no improvement over training from scratch or standard baselines on segmentation Dice scores, classification accuracy, or expert preference rankings.
Figures
read the original abstract
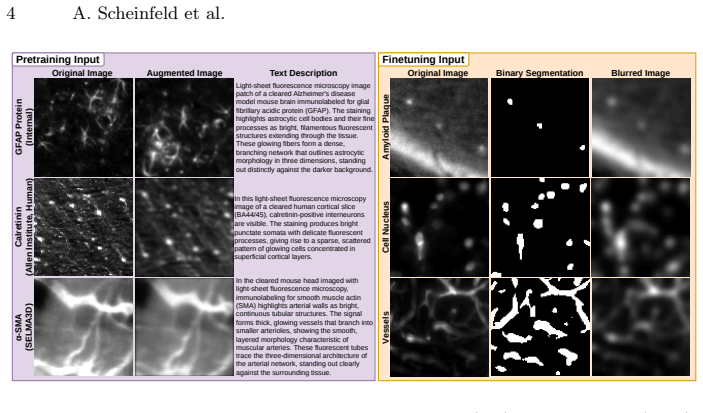
Light sheet fluorescence microscopy (LSM) enables high-resolution, three-dimensional (3D) imaging of biological specimens, providing rich volumetric data for studying cellular organization, pathology, and vascular networks. However, the size, dimensionality, and annotation burden of LSM data make supervised deep learning approaches costly and difficult to scale. Additionally, despite the abundance of unannotated LSM volumes, foundation models for this modality remain underexplored due to computational challenges and the complexity of volumetric representation learning. In this work, we introduce a 3D foundation model for LSM data, pretrained on a large curated collection of 3D images spanning multiple organisms, stains, and imaging protocols. We learn transferable volumetric representations by jointly optimizing for masked reconstruction and image-text alignment. The pretrained backbone drastically reduces the annotation burden, enabling efficient, few-shot adaptation for varied downstream tasks. We evaluate this approach on downstream segmentation, classification, and deblurring. Our results demonstrate consistent improvements over baselines, (1) when measured using standard evaluation metrics and (2) when rigorously assessed by domain experts. This highlights the potential of foundation model pretraining to reduce annotation requirements while improving performance across diverse LSM analysis tasks. Pretrained model weights and code for pretraining and finetuning are publicly available: https://github.com/AdinaScheinfeld/lsm_fm_public_repo.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a 3D foundation model for light sheet fluorescence microscopy (LSM) pretrained on a large curated collection of volumetric images spanning multiple organisms, stains, and protocols. Representations are learned via joint masked reconstruction and image-text alignment objectives. The pretrained backbone is shown to support few-shot adaptation on downstream tasks of segmentation, classification, and deblurring, yielding consistent gains over baselines according to standard metrics and domain-expert assessment. Pretrained weights and code are released publicly.
Significance. If the reported transfer results hold under the detailed evaluation protocols, the work provides a concrete demonstration that multimodal self-supervised pretraining can materially reduce annotation burden for 3D LSM analysis across organisms and tasks. The public release of weights and code is a clear strength that supports reproducibility and downstream use.
minor comments (3)
- [Abstract] Abstract: the claim of 'consistent improvements' is stated without reference to specific metric values, dataset sizes, or table numbers; adding one or two quantitative anchors would strengthen the summary paragraph.
- [Methods] The manuscript would benefit from an explicit statement of the total number of volumes, organisms, and imaging protocols in the pretraining collection (Methods section) to allow readers to gauge scale and diversity.
- Figure captions and table legends should consistently indicate whether error bars represent standard deviation across runs or across datasets; this is needed for interpreting the few-shot results.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the manuscript, recognition of its significance in demonstrating multimodal self-supervised pretraining for 3D LSM data, and recommendation for minor revision. The public release of weights and code is indeed intended to support reproducibility.
Circularity Check
No significant circularity identified
full rationale
The paper is an empirical ML study describing pretraining of a 3D foundation model via masked reconstruction and image-text alignment on a curated LSM dataset, followed by few-shot finetuning and evaluation on held-out segmentation, classification, and deblurring tasks. No equations, derivations, or self-referential fitting steps are present; performance claims rest on standard held-out metrics and domain-expert review against baselines. The work is self-contained against external benchmarks with no load-bearing self-citation chains or ansatz smuggling.
Axiom & Free-Parameter Ledger
free parameters (1)
- pretraining objective weights and hyperparameters
Reference graph
Works this paper leans on
-
[1]
eLife13, RP99848 (2025)
Achard, C., Kousi, T., Frey, M., Vidal, M., Paychère, Y., Hofmann, C., Iqbal, A., et al.: CellSeg3D: self-supervised 3D cell segmentation for microscopy. eLife13, RP99848 (2025)
2025
-
[2]
Scheinfeld et al
Allen Institute for Brain Science: Developing Mouse Brain Imaging and Common Coordinate Framework,https://knowledge.brain-map.org/data/ NUM7DTHI95ECV27X5RV 10 A. Scheinfeld et al
-
[3]
Allen Institute for Brain Science: Viral sparse labeling of connectionally-unique projection neurons for morphological assessment,https://knowledge.brain-map.org/ data/VJGWTBZLG77YG5NKLKI
-
[4]
Nature Methods22, 579–591 (2025)
Archit, A., Freckmann, L., Nair, S., Khalid, N., Hilt, P., Rajashekar, V., Freitag, M., et al.: Segment Anything for Microscopy. Nature Methods22, 579–591 (2025)
2025
-
[5]
On the Opportunities and Risks of Foundation Models
Bommasani, R., Hudson, D.A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M.S., et al.: On the opportunities and risks of foundation models. arXiv:2108.07258 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
ChatGPT,https://chatgpt.com/
-
[7]
Nature Methods21, 1470–1480 (2024)
Cui, H., Wang, C., Maan, H., Pang, K., Luo, F., Duan, N., Wang, B.: scGPT: toward building a foundation model for single-cell multi-omics using generative AI. Nature Methods21, 1470–1480 (2024)
2024
-
[8]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, J., Chang, M.-W., Lee, K., Toutanova, K.: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[9]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Let- man, A., et al.: The Llama 3 Herd of Models. arXiv 2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Hatamizadeh, A., Nath, V., Tang, Y, Yang, D., Roth, H., Xu, D.: Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images. arXiv:2201.01266 (2022)
-
[11]
Deep Residual Learning for Image Recognition
He, K., Zhang, X., Ren, S., Sun, J.: Deep Residual Learning for Image Recognition. arXiv 1512.03385 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[12]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., Dean, J.: Distilling the Knowledge in a Neural Network. arXiv:1503.02531 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
Same pre-training loss, better downstream: Implicit bias matters for language models, 2022
Hong, L., Xie, S.M., Li, Z., Ma, T.: Same Pre-training Loss, Better Downstream: Implicit Bias Matters for Language Models. arXiv:2210.14199 (2022)
-
[14]
Nature Methods21(7), 1306–1315 (2024)
Kaltenecker, D., Al-Maskari, R., Negwer, M., Hoeher, L., Kofler, F., Zhao, S., Todorov, M., et al.: Virtual reality-empowered deep-learning analysis of brain cells. Nature Methods21(7), 1306–1315 (2024)
2024
-
[15]
DANDI Archive (2023)
Kamentsky, L., Slayton, M., Park, J., Su-Arcaro, C., Moukheiber, M., Zhao, V.: Light sheet imaging of the human brain (Version draft) [Data set]. DANDI Archive (2023)
2023
-
[16]
IEEE/CVF International Conference on Computer Vision (ICCV), pp
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., et al.: Segment anything. IEEE/CVF International Conference on Computer Vision (ICCV), pp. 3992–4003 (2023)
2023
-
[17]
Nature Communications15, 654 (2024)
Ma, J., He, Y., Li, F., Han, L., You, C., Wang, B.: Segment anything in medical images. Nature Communications15, 654 (2024)
2024
-
[18]
Nature Methods 21, 1103–1113 (2024)
Ma,J.,Xie,R.,Ayyadhury,S.,Ge,C.,Gupta,A.,Gupta,R.,Gu,S.,etal.Themut- limodality cell segmentation challenge: toward universal solutions. Nature Methods 21, 1103–1113 (2024)
2024
-
[19]
Nature Biotechnology42(4), 617–627 (2024)
Mai, H., Luo, J., Hoeher, L., Al-Maskari, R., Horvath, I., Chen, Y., Kofler, F., et al.: Whole-body cellular mapping in mouse using standard IgG antibodies. Nature Biotechnology42(4), 617–627 (2024)
2024
-
[20]
DANDI archive (2022)
Mazzamuto, G., Costantini, I., Gavryusev, V., Castelli, F.M., Pesce, L., Scardigli, M., Pavone, F.S., et al.: Human brain cell census for BA 44/45 (Version draft) [Data set]. DANDI archive (2022)
2022
-
[21]
readthedocs.io/en/fixes-sphinx/networks.html
MONAI Documentation: Neural Network Architectures,https://monai-dev. readthedocs.io/en/fixes-sphinx/networks.html
-
[22]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fer- nandez, P., et al.: DINOv2: Learning Robust Visual Features without Supervision. arXiv:2304.07193 (2024) A Multimodal 3D Foundation Model for Light Sheet Microscopy 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
bioRxiv 2025.04.28.651001 (2025)
Pachitariu, M., Rariden, M., Stringer, C.: Cellpose-SAM: superhuman generaliza- tion for cellular segmentation. bioRxiv 2025.04.28.651001 (2025)
2025
-
[24]
In: Proceedings of the 38th International Conference on Machine Learning, pp.8748– 8763 (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., et al.: Learning Transferable Visual Models for Natural Language Supervision. In: Proceedings of the 38th International Conference on Machine Learning, pp.8748– 8763 (2021)
2021
-
[25]
U-Net: Convolutional Networks for Biomedical Image Segmentation
Ronneberger, O., Fischer, P., Brox, T.: U-Net: Convolutional Networks for Biomed- ical Image Segmentation. arXiv:1505.04597 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[26]
SELMA3D 2024 Grand Challenge Dataset, https://selma3d.grand-challenge.org/
2024
-
[27]
SELMA3D 2025 Grand Challenge Dataset, https://selma3d2025.grand-challenge. org/
2025
-
[28]
Shit, S., Paetzold, J.C., Sekuboyina, A., Ezhov, I., Unger, A., Zhylka, A., Pluim, J.P.W., et al.: clDice - a Novel Topology-Preserving Loss Function for Tubular Structure Segmentation. arXiv:2003.07311 (2022)
-
[29]
Nature Reviews Methods Primers 1, 73 (2021)
Stelzer, E.H.K., Strobl, F., Chang, BJ., Preusser, F., Preibisch, S., McDole, K., Fiolka, R.: Light sheet fluorescence microscopy. Nature Reviews Methods Primers 1, 73 (2021)
2021
-
[30]
VERITAS: Verifiable Epistemic Reasoning for Image-Derived Hypothesis Testing via Agentic Systems
Stoffl, L., Wiestler, B., Paetzold, J.C.: VERITAS: Verifiable Epistemic Reasoning for Image-Derived Hypothesis Testing via Agentic Systems. arXiv:2604.12144 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Nature Methods17(4), 442–449 (2020)
Todorov, M.I., Paetzold, J.C., Schoppe, O., Tetteh, G., Shit, S., Efremov, V., Todorov-Völgyi, K., et al.: Machine learning analysis of whole mouse brain vascu- lature. Nature Methods17(4), 442–449 (2020)
2020
-
[32]
Nature Methods16(11), 1105–1108 (2019)
Voigt, F.F., Kirschenbaum, D., Platonova, E., Pagès, S., Campbell, R.A.A., Kastli, R., Schaettin, M., et al.: The mesoSPIM initiative: open-source light-sheet micro- scopes for imaging cleared tissue. Nature Methods16(11), 1105–1108 (2019)
2019
-
[33]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 14408–14419 (2023)
Wang, W., Dai, J., Chen, Z., Huang, Z., Li, Z., Zhu, X., Hu, X., et al.: Internim- age: Exploring large-scale vision foundation models with deformable convolutions. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 14408–14419 (2023)
2023
-
[34]
In: Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), pp
Weigert, M., Schmidt, U., Haase, R., Sugawara, K., Myers, G.: Star-convex Poly- hedra for 3D Object Detection and Segmentation in Microscopy. In: Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), pp. 3666–3673 (2020)
2020
-
[35]
Cell180(4), 796–812 (2020)
Zhao, S., Todorov, M.I., Cai, R., Al-Maskari, R., Steinke, H., Kemter, E., Mai, H., et al.: Cellular and Molecular Probing of Intact Human Organs. Cell180(4), 796–812 (2020)
2020
-
[36]
Nature Methods22, 166–176 (2025)
Zhao, T., Gu, Y., Yang, J., Usuyama, N., Lee, H.H., Kiblawi, S., Naumann, T., et al.: A foundation model for joint segmentation, detection and recognition of biomedical objects across nine modalities. Nature Methods22, 166–176 (2025)
2025
-
[37]
iBOT: Image BERT Pre-Training with Online Tokenizer
Zhou, J., Wei, C., Wang, H., Shen, W., Xie, C., Yuille, A., Kong, T.: iBOT: Image BERT Pre-Training with Online Tokenizer. arXiv:2111.07832 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
Nature622, 156–163 (2023)
Zhou, Y., Chia, M.A., Wagner, S.K., Ayhan, M.S., Williamson, D.J., Struyven, R.R., Liu, T., et al.: A foundation model for generalizable disease detection from retinal images. Nature622, 156–163 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.