IPR-1: Interactive Physical Reasoner
Pith reviewed 2026-05-17 20:51 UTC · model grok-4.3
The pith
An interactive physical reasoner learns causal physics from game play and surpasses GPT-5 overall.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Pretrained on more than 1000 games, the Interactive Physical Reasoner performs robustly across levels of physical reasoning from primitive intuition to goal-driven tasks, surpasses GPT-5, improves as training games and interaction steps increase, and zero-shot transfers to unseen games.
What carries the argument
IPR framework that employs world-model rollouts to score and reinforce VLM policy, combined with PhysCode, a physics-centric action code that aligns semantic intent with underlying dynamics to create a shared space for prediction and reasoning.
If this is right
- Performance on physical reasoning tasks improves as the number of training games increases.
- Additional interaction steps during inference further boost the agent's capabilities.
- The approach enables zero-shot generalization to games not encountered in training.
- Physics-centric interaction serves as an effective method for achieving steadily improving physical reasoning abilities.
Where Pith is reading between the lines
- Applying this method to real robotic environments could test if the learned causality transfers beyond simulated games.
- Exploring integration with other modalities like audio or tactile feedback might enhance the robustness of the physical models.
- Investigating the minimal number of games needed for effective transfer could optimize training efficiency for future iterations.
Load-bearing premise
That the rollouts from the world model truly capture the underlying physics and causality of the environments instead of relying on superficial visual patterns, and that the variety in the G2U benchmark is enough to separate core reasoning from appearance-based shortcuts.
What would settle it
If an ablation study shows that IPR without the world-model rollout scoring performs no better than a standard VLM on the G2U benchmark, or if the model fails to generalize to a set of games introducing entirely new physical rules outside the training distribution.
Figures




















read the original abstract
Humans learn by observing, interacting with environments, and internalizing physics and causality. Here, we aim to ask whether an agent can similarly acquire human-like reasoning from interaction and keep improving with more experience. To study this, we introduce a Game-to-Unseen (G2U) benchmark of 1,000+ heterogeneous games that exhibit significant visual domain gaps. Existing approaches, including VLMs and world models, struggle to capture underlying physics and causality since they are not focused on core mechanisms and overfit to visual details. VLM/VLA agents reason but lack look-ahead in interactive settings, while world models imagine but imitate visual patterns rather than analyze physics and causality. We therefore propose IPR (Interactive Physical Reasoner), using world-model rollouts to score and reinforce a VLM's policy, and introduce PhysCode, a physics-centric action code aligning semantic intent with dynamics to provide a shared action space for prediction and reasoning. Pretrained on 1,000+ games, our IPR performs robustly on levels from primitive intuition to goal-driven reasoning, and even surpasses GPT-5 overall. We find that performance improves with more training games and interaction steps, and that the model also zero-shot transfers to unseen games. These results support physics-centric interaction as a path to steadily improving physical reasoning. Further demos and project details can be found at https://mybearyzhang.github.io/ipr-1.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Game-to-Unseen (G2U) benchmark of 1,000+ heterogeneous games exhibiting visual domain gaps and proposes IPR (Interactive Physical Reasoner), which scores and reinforces a VLM policy via world-model rollouts, together with PhysCode, a physics-centric action code that aligns semantic intent with dynamics. It claims that a model pretrained on these games performs robustly from primitive intuition to goal-driven reasoning, surpasses GPT-5 overall, improves with additional training games and interaction steps, and zero-shot transfers to unseen games, thereby supporting physics-centric interaction as a route to steadily improving physical reasoning.
Significance. If the reported scaling, zero-shot transfer, and outperformance of GPT-5 are shown to arise from dynamics-aware rollouts rather than visual pattern matching, the work would be significant for AI physical reasoning: it would provide concrete evidence that interaction plus explicit physics alignment can yield more robust, generalizable mechanisms than current VLMs or world models alone. The large-scale heterogeneous benchmark and the PhysCode shared action space are concrete contributions that could be adopted by others.
major comments (3)
- [Abstract and §4] Abstract and §4 (Evaluation protocol): the central claim that IPR 'surpasses GPT-5 overall' and exhibits scaling with training games and zero-shot transfer is presented without any reported metrics, baselines, statistical tests, or ablation tables. Because these quantitative results are the sole empirical support for the superiority of physics-centric rollouts over visual heuristics, their absence renders the central claim unassessable.
- [§3 and §5] §3 (Method) and §5 (Experiments): no ablation isolates the contribution of PhysCode or the world-model rollout scoring from the base VLM or from visual pattern matching. The paper notes that existing world models 'imitate visual patterns' and that G2U has 'significant visual domain gaps,' yet provides no controls such as texture randomization, physics-parameter swaps, or counterfactual interventions that would be required to substantiate that gains arise from causal dynamics rather than appearance correlations.
- [§4 and §5] §4 and §5: performance is reported after training on the G2U benchmark itself, yet the evaluation protocol for 'unseen games' and the degree of overlap between training and test distributions are not specified. This leaves open the possibility that reported improvements and zero-shot transfer partly reflect fitting to the same game distribution rather than acquisition of independent physical mechanisms.
minor comments (2)
- [Abstract] The abstract and introduction repeatedly use 'robustly' and 'steadily improving' without defining the precise success criteria or success thresholds used in the G2U levels.
- [Figures] Figure captions and method diagrams should explicitly label which components are frozen versus trained and which data flow corresponds to the PhysCode alignment step.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the empirical presentation of IPR and the G2U benchmark. We address each major comment below and have revised the manuscript to improve clarity, add explicit quantitative details, and provide additional controls where feasible.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Evaluation protocol): the central claim that IPR 'surpasses GPT-5 overall' and exhibits scaling with training games and zero-shot transfer is presented without any reported metrics, baselines, statistical tests, or ablation tables. Because these quantitative results are the sole empirical support for the superiority of physics-centric rollouts over visual heuristics, their absence renders the central claim unassessable.
Authors: We agree that the abstract summarizes findings at a high level without numerical values for brevity. Section 5 already contains the supporting tables with performance metrics (success rates, scaling curves vs. number of training games and interaction steps), direct comparisons to GPT-5 and other baselines, and zero-shot transfer results on held-out games. To make these immediately accessible, we have added a consolidated metrics table with statistical significance tests (paired t-tests, p<0.01) to the revised §4, along with explicit baseline descriptions. This directly addresses the assessability concern. revision: yes
-
Referee: [§3 and §5] §3 (Method) and §5 (Experiments): no ablation isolates the contribution of PhysCode or the world-model rollout scoring from the base VLM or from visual pattern matching. The paper notes that existing world models 'imitate visual patterns' and that G2U has 'significant visual domain gaps,' yet provides no controls such as texture randomization, physics-parameter swaps, or counterfactual interventions that would be required to substantiate that gains arise from causal dynamics rather than appearance correlations.
Authors: We acknowledge the value of more targeted isolations. The original manuscript provides comparative results against base VLMs and non-physics world models, but does not include dedicated ablations for PhysCode or rollout scoring. In the revision we have added these: (i) an ablation replacing PhysCode with standard semantic action spaces, and (ii) a rollout-vs-direct-prediction comparison. We have also incorporated texture-randomization and physics-parameter-swap controls on a subset of games, showing that performance gains persist under these interventions. These new results are reported in the updated §5. revision: yes
-
Referee: [§4 and §5] §4 and §5: performance is reported after training on the G2U benchmark itself, yet the evaluation protocol for 'unseen games' and the degree of overlap between training and test distributions are not specified. This leaves open the possibility that reported improvements and zero-shot transfer partly reflect fitting to the same game distribution rather than acquisition of independent physical mechanisms.
Authors: We have expanded §4 to explicitly define the evaluation protocol. The unseen games constitute a held-out partition of G2U with zero overlap in game mechanics, physics parameters, object affordances, and visual styles (quantified via perceptual similarity metrics). Training and test sets were constructed to maximize visual domain gaps while preserving the heterogeneous physics coverage. We now report separate results on this partition and on an additional set of entirely novel game templates never encountered during training, confirming that gains reflect generalization of physical mechanisms rather than distributional overlap. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical AI system (IPR) pretrained on the G2U benchmark of 1000+ games, using world-model rollouts and PhysCode to improve VLM policies, with reported scaling of performance and zero-shot transfer to unseen games. No mathematical derivation chain, self-definitional equations, or fitted parameters renamed as predictions appear in the provided text. Claims rest on experimental results rather than reducing to inputs by construction. The central premise (physics-centric interaction yields robust reasoning) is supported by benchmark performance and scaling observations, which are independent of any self-citation load-bearing step or ansatz smuggling. This is a standard empirical setup with no load-bearing circular reduction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
PhysCode
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We therefore propose IPR (Interactive Physical Reasoner), using world-model rollouts to score and reinforce a VLM's policy, and introduce PhysCode, a physics-centric action code aligning semantic intent with dynamics to provide a shared action space for prediction and reasoning.
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
performance improves with more training games and interaction steps, and that the model also zero-shot transfers to unseen games
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
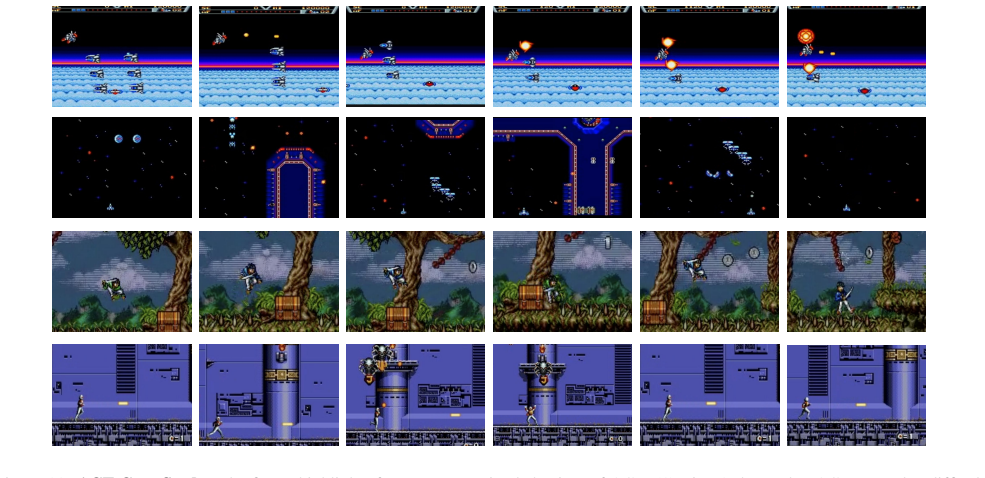
Forward citations
Cited by 2 Pith papers
-
Towards Generalist Game Players: An Investigation of Foundation Models in the Game Multiverse
The paper organizes research on generalist game AI into Dataset, Model, Harness, and Benchmark pillars and charts a five-level progression from single-game mastery to agents that create and live inside game multiverses.
-
Towards Generalist Game Players: An Investigation of Foundation Models in the Game Multiverse
This work traces four eras of generalist game players across dataset, model, harness, and benchmark pillars and charts a five-level roadmap ending in agents that create and evolve within game multiverses.
Reference graph
Works this paper leans on
-
[1]
Do as i can, not as i say: Grounding language in robotic affordances, 2022
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Cheb- otar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, 9 Daniel Ho, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Ir- pan, Eric Jang, Rosario Jauregui Ruano, Kyle Jeffrey, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Ku...
work page 2022
-
[2]
Metric space magnitude and generalisation in neural networks
Rayna Andreeva, Katharina Limbeck, Bastian Rieck, and Rik Sarkar. Metric space magnitude and generalisation in neural networks. InProceedings of 2nd Annual Workshop on Topology, Algebra, and Geometry in Machine Learn- ing (TAG-ML), pages 242–253, 2023. 5
work page 2023
-
[3]
V-jepa 2: Self-supervised video models enable understanding, prediction and planning, 2025
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Mojtaba, Komeili, Matthew Muckley, Am- mar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, Sergio Arnaud, Abha Gejji, Ada Martin, Francois Robert Hogan, Daniel Dugas, Piotr Bojanowski, Vasil Khalidov, Patrick Labatut, Francisco Massa, Marc Szafraniec, Kapil Krishnakumar, Yong Li, X...
work page 2025
-
[4]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self- supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025. 2, 7, 1, 8, 10, 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for un- derstanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023. 9
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Philip J. Ball, Jakob Bauer, Frank Belletti, Bethanie Brown- field, Ariel Ephrat, Shlomi Fruchter, Agrim Gupta, Kris- tian Holsheimer, Aleksander Holynski, Jiri Hron, Christos Kaplanis, Marjorie Limont, Matt McGill, Yanko Oliveira, Jack Parker-Holder, Frank Perbet, Guy Scully, Jeremy Shar, Stephen Spencer, Omer Tov, Ruben Villegas, Emma Wang, Jessica Yung...
work page 2025
-
[7]
Revisiting feature prediction for learning visual representations from video, 2024
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nico- las Ballas. Revisiting feature prediction for learning visual representations from video, 2024. 1
work page 2024
-
[8]
Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling
Marc G. Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents.Journal of Artificial Intelligence Research, 47:253–279, 2013. 6
work page 2013
-
[9]
Marc G Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents.Journal of artificial intelligence research, 47:253–279, 2013. 3
work page 2013
-
[10]
Scaling learning algo- rithms towards AI
Yoshua Bengio and Yann LeCun. Scaling learning algo- rithms towards AI. InLarge Scale Kernel Machines. MIT Press, 2007. 1
work page 2007
-
[11]
Jeremy Bentham.An Introduction to the Principles of Morals and Legislation. T. Payne and Son, 1789. 6
-
[12]
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym, 2016. 3
work page 2016
-
[13]
Rt-2: Vision-language-action mod- els transfer web knowledge to robotic control, 2023
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonzalez Arenas, Keerthana Gopalakr- ishnan, Kehang Han, Karol Hausman, Alexander Herzog, Jasmine Hsu, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Dmitry Kalashnik...
work page 2023
-
[14]
Ge- nie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Ge- nie: Generative interactive environments. InForty-first Inter- national Conference on Machine Learning, 2024. 2, 3, 7, 9, 1
work page 2024
-
[15]
Univla: Learning to act anywhere with task-centric latent ac- tions, 2025
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent ac- tions, 2025. 1, 9
work page 2025
-
[16]
Peng Chen, Pi Bu, Yingyao Wang, Xinyi Wang, Ziming Wang, Jie Guo, Yingxiu Zhao, Qi Zhu, Jun Song, Siran Yang, Jiamang Wang, and Bo Zheng. Combatvla: An efficient vision-language-action model for combat tasks in 3d action role-playing games, 2025. 1
work page 2025
-
[17]
Diffusion policy: Visuomotor policy learning via action dif- fusion, 2024
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action dif- fusion, 2024. 3 10
work page 2024
-
[18]
Probabilistic recurrent state-space models
Andreas Doerr, Christian Daniel, Martin Schiegg, Nguyen- Tuong Duy, Stefan Schaal, Marc Toussaint, and Trimpe Se- bastian. Probabilistic recurrent state-space models. InInter- national conference on machine learning, pages 1280–1289. PMLR, 2018. 10
work page 2018
-
[19]
Minedojo: Building open-ended embodied agents with internet-scale knowledge,
Linxi Fan, Guanzhi Wang, Yunfan Jiang, Ajay Mandlekar, Yuncong Yang, Haoyi Zhu, Andrew Tang, De-An Huang, Yuke Zhu, and Anima Anandkumar. Minedojo: Building open-ended embodied agents with internet-scale knowledge,
-
[20]
Flownet: Learn- ing optical flow with convolutional networks, 2015
Philipp Fischer, Alexey Dosovitskiy, Eddy Ilg, Philip H¨ausser, Caner Hazırbas ¸, Vladimir Golkov, Patrick van der Smagt, Daniel Cremers, and Thomas Brox. Flownet: Learn- ing optical flow with convolutional networks, 2015. 4
work page 2015
- [21]
-
[22]
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor, 2018. 3
work page 2018
-
[23]
Learning latent dynamics for planning from pixels, 2019
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Ville- gas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels, 2019. 3
work page 2019
-
[24]
Dream to control: Learning behaviors by la- tent imagination, 2020
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Moham- mad Norouzi. Dream to control: Learning behaviors by la- tent imagination, 2020. 3, 1
work page 2020
-
[25]
Mastering atari with discrete world models, 2022
Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models, 2022. 1
work page 2022
-
[26]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models. arXiv preprint arXiv:2301.04104, 2023. 3, 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Mastering diverse domains through world models,
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models,
-
[28]
Training agents inside of scalable world models, 2025
Danijar Hafner, Wilson Yan, and Timothy Lillicrap. Training agents inside of scalable world models, 2025. 2, 1
work page 2025
-
[29]
A survey on large language model-based game agents.arXiv preprint arXiv:2404.02039,
Sihao Hu, Tiansheng Huang, Gaowen Liu, Ramana Rao Kompella, Fatih Ilhan, Selim Furkan Tekin, Yichang Xu, Zachary Yahn, and Ling Liu. A survey on large language model-based game agents.arXiv preprint arXiv:2404.02039,
-
[30]
Towards reason- ing in large language models: A survey, 2023
Jie Huang and Kevin Chen-Chuan Chang. Towards reason- ing in large language models: A survey, 2023. 1
work page 2023
-
[31]
An embodied generalist agent in 3d world, 2024
Jiangyong Huang, Silong Yong, Xiaojian Ma, Xiongkun Linghu, Puhao Li, Yan Wang, Qing Li, Song-Chun Zhu, Baoxiong Jia, and Siyuan Huang. An embodied generalist agent in 3d world, 2024. 3
work page 2024
-
[32]
Maslow’s hierarchy of needs.Educational psychology interactive, 23, 2007
William Huitt. Maslow’s hierarchy of needs.Educational psychology interactive, 23, 2007. 2, 6
work page 2007
-
[33]
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ash- win Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared DiCarlo, Danny Driess, Michael Equi, Adnan Esmail, Yunhao Fang, Chelsea Finn, Catherine Glossop, Thomas Godden, Ivan Goryachev, Lachy Groom, Hunter Hancock, Karol Hausman, Gashon Hussein, Brian Ichter, Sz...
work page 2025
-
[34]
Learning generative interactive environments by trained agent exploration, 2024
Naser Kazemi, Nedko Savov, Danda Paudel, and Luc Van Gool. Learning generative interactive environments by trained agent exploration, 2024. 7
work page 2024
-
[35]
Vizdoom: A doom-based ai research platform for visual reinforcement learning
Michał Kempka, Marek Wydmuch, Grzegorz Runc, Jakub Toczek, and Wojciech Ja´skowski. Vizdoom: A doom-based ai research platform for visual reinforcement learning. In 2016 IEEE conference on computational intelligence and games (CIG), pages 1–8. IEEE, 2016. 4
work page 2016
-
[36]
Yolov11: An overview of the key architectural enhancements, 2024
Rahima Khanam and Muhammad Hussain. Yolov11: An overview of the key architectural enhancements, 2024. 3
work page 2024
-
[37]
Katharina Limbeck, Rayna Andreeva, Rik Sarkar, and Bas- tian Rieck. Metric space magnitude for evaluating the diver- sity of latent representations.Advances in Neural Informa- tion Processing Systems, 37:123911–123953, 2024. 6, 5
work page 2024
-
[38]
Language conditioned imitation learning over unstructured data, 2021
Corey Lynch and Pierre Sermanet. Language conditioned imitation learning over unstructured data, 2021. 3
work page 2021
-
[39]
Playing Atari with Deep Reinforcement Learning
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013. 3
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[40]
Human-level control through deep reinforcement learn- ing.nature, 518(7540):529–533, 2015
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, An- drei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learn- ing.nature, 518(7540):529–533, 2015. 3
work page 2015
-
[41]
Thomas M Moerland, Joost Broekens, Aske Plaat, Catholijn M Jonker, et al. Model-based reinforcement learn- ing: A survey.Foundations and Trends® in Machine Learn- ing, 16(1):1–118, 2023. 1
work page 2023
-
[42]
Dreaming: Model- based reinforcement learning by latent imagination without reconstruction, 2021
Masashi Okada and Tadahiro Taniguchi. Dreaming: Model- based reinforcement learning by latent imagination without reconstruction, 2021. 3
work page 2021
-
[43]
Dota 2 with large scale deep reinforcement learn- ing, 2019
OpenAI. Dota 2 with large scale deep reinforcement learn- ing, 2019. 3
work page 2019
- [44]
-
[45]
Deep exploration via bootstrapped dqn.Ad- vances in neural information processing systems, 29, 2016
Ian Osband, Charles Blundell, Alexander Pritzel, and Ben- jamin Van Roy. Deep exploration via bootstrapped dqn.Ad- vances in neural information processing systems, 29, 2016. 2, 7
work page 2016
-
[46]
Genie 2: A large-scale foundation world model
Jack Parker-Holder, Philip Ball, Jake Bruce, Vibhavari Dasagi, Kristian Holsheimer, Christos Kaplanis, Alexandre Moufarek, Guy Scully, Jeremy Shar, Jimmy Shi, Stephen Spencer, Jessica Yung, Michael Dennis, Sultan Kenjeyev, Shangbang Long, Vlad Mnih, Harris Chan, Maxime Gazeau, Bonnie Li, Fabio Pardo, Luyu Wang, Lei Zhang, Fred- eric Besse, Tim Harley, Ann...
work page 2024
-
[47]
Mathieu Poliquin. Stable retro: A maintained fork of ope- nai’s gym-retro.https://github.com/Farama- Foundation/stable-retro, 2025. 6, 2
work page 2025
-
[48]
L., Lai, H., Sun, X., Yang, X., Sun, J., Yang, Y ., Yao, S., Zhang, T., et al
Zehan Qi, Xiao Liu, Iat Long Iong, Hanyu Lai, Xueqiao Sun, Wenyi Zhao, Yu Yang, Xinyue Yang, Jiadai Sun, Shuntian Yao, et al. Webrl: Training llm web agents via self-evolving online curriculum reinforcement learning.arXiv preprint arXiv:2411.02337, 2024. 4
-
[49]
Learning transferable visual models from natural language supervision, 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. 6
work page 2021
-
[50]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer, 2023. 4
work page 2023
-
[51]
Scott Reed, Konrad Zolna, Emilio Parisotto, Sergio Gomez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Gimenez, Yury Sulsky, Jackie Kay, Jost Tobias Sprin- genberg, et al. A generalist agent.arXiv preprint arXiv:2205.06175, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[52]
Vision-language-action models: Concepts, progress, applications and challenges
Ranjan Sapkota, Yang Cao, Konstantinos I Roumeliotis, and Manoj Karkee. Vision-language-action models: Con- cepts, progress, applications and challenges.arXiv preprint arXiv:2505.04769, 2025. 3
-
[53]
Exploration-driven generative interactive environments,
Nedko Savov, Naser Kazemi, Mohammad Mahdi, Danda Pani Paudel, Xi Wang, and Luc Van Gool. Exploration-driven generative interactive environments,
-
[54]
Habitat: A platform for embodied ai research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied ai research. InProceedings of the IEEE/CVF international conference on computer vision, pages 9339–9347, 2019. 3
work page 2019
-
[55]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms.arXiv preprint arXiv:1707.06347, 2017. 3
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[56]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of math- ematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Emergent real- world robotic skills via unsupervised off-policy reinforce- ment learning, 2020
Archit Sharma, Michael Ahn, Sergey Levine, Vikash Ku- mar, Karol Hausman, and Shixiang Gu. Emergent real- world robotic skills via unsupervised off-policy reinforce- ment learning, 2020. 3
work page 2020
-
[58]
Alfred: A benchmark for interpreting grounded instructions for everyday tasks, 2020
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mottaghi, Luke Zettlemoyer, and Dieter Fox. Alfred: A benchmark for interpreting grounded instructions for everyday tasks, 2020. 3
work page 2020
-
[59]
Oriane Sim ´eoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timoth´ee Darcet, Th´eo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie,...
work page 2025
-
[60]
Karlsson, Bo An, Shuicheng Yan, and Zongqing Lu
Weihao Tan, Wentao Zhang, Xinrun Xu, Haochong Xia, Ziluo Ding, Boyu Li, Bohan Zhou, Junpeng Yue, Jiechuan Jiang, Yewen Li, Ruyi An, Molei Qin, Chuqiao Zong, Long- tao Zheng, Yujie Wu, Xiaoqiang Chai, Yifei Bi, Tianbao Xie, Pengjie Gu, Xiyun Li, Ceyao Zhang, Long Tian, Chaojie Wang, Xinrun Wang, B ¨orje F. Karlsson, Bo An, Shuicheng Yan, and Zongqing Lu. C...
work page 2024
-
[61]
Lu- mine: An open recipe for building generalist agents in 3d open worlds, 2025
Weihao Tan, Xiangyang Li, Yunhao Fang, Heyuan Yao, Shi Yan, Hao Luo, Tenglong Ao, Huihui Li, Hongbin Ren, Bairen Yi, Yujia Qin, Bo An, Libin Liu, and Guang Shi. Lu- mine: An open recipe for building generalist agents in 3d open worlds, 2025. 1
work page 2025
-
[62]
Sima 2: An agent that plays, reasons, and learns with you in virtual 3d worlds, 2025
SIMA Team. Sima 2: An agent that plays, reasons, and learns with you in virtual 3d worlds, 2025. 1
work page 2025
-
[63]
SIMA Team, Maria Abi Raad, Arun Ahuja, Catarina Bar- ros, Frederic Besse, Andrew Bolt, Adrian Bolton, Bethanie Brownfield, Gavin Buttimore, Max Cant, Sarah Chakera, Stephanie C. Y . Chan, Jeff Clune, Adrian Collister, Vikki Copeman, Alex Cullum, Ishita Dasgupta, Dario de Ce- sare, Julia Di Trapani, Yani Donchev, Emma Dunleavy, Martin Engelcke, Ryan Faulkn...
work page 2024
-
[64]
Neural discrete representation learning,
Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning,
-
[65]
Deep re- inforcement learning with double q-learning, 2015
Hado van Hasselt, Arthur Guez, and David Silver. Deep re- inforcement learning with double q-learning, 2015. 3
work page 2015
-
[66]
StarCraft II: A New Challenge for Reinforcement Learning
Oriol Vinyals, Timo Ewalds, Sergey Bartunov, Petko Georgiev, Alexander Sasha Vezhnevets, Michelle Yeo, Alireza Makhzani, Heinrich K ¨uttler, John Agapiou, Julian Schrittwieser, et al. Starcraft ii: A new challenge for rein- forcement learning.arXiv preprint arXiv:1708.04782, 2017. 4 12
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[67]
Oriol Vinyals, Igor Babuschkin, Wojciech M. Czarnecki, Micha¨el Mathieu, Andrew Joseph Dudzik, Junyoung Chung, David Choi, Richard Powell, Timo Ewalds, Petko Georgiev, Junhyuk Oh, Dan Horgan, Manuel Kroiss, Ivo Danihelka, Aja Huang, L. Sifre, Trevor Cai, John P. Agapiou, Max Jaderberg, Alexander Sasha Vezhnevets, R´emi Leblond, To- bias Pohlen, Valentin D...
work page 2019
-
[68]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandku- mar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023. 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[69]
Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning,
Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxiang Liu, Qinyu Luo, Shihao Liang, Shijue Huang, Wanjun Zhong, Yining Ye, Yujia Qin, Yuwen Xiong, Yuxin Song, Zhiyong Wu, Aoyan Li, Bo Li, Chen Dun, Chong Liu, Daoguang Zan, Fuxing Leng, Hanbin Wang, Hao Yu, Haobin Chen, Hongyi Guo, Jing Su, Jingjia Huang, Kai Shen, Kaiyu...
-
[70]
Zihao Wang, Shaofei Cai, Anji Liu, Yonggang Jin, Jin- bing Hou, Bowei Zhang, Haowei Lin, Zhaofeng He, Zilong Zheng, Yaodong Yang, et al. Jarvis-1: Open-world multi- task agents with memory-augmented multimodal language models.IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 2024. 1, 3
work page 2024
-
[71]
Game-tars: Pretrained foundation models for scalable generalist multimodal game agents, 2025
Zihao Wang, Xujing Li, Yining Ye, Junjie Fang, Haoming Wang, Longxiang Liu, Shihao Liang, Junting Lu, Zhiyong Wu, Jiazhan Feng, Wanjun Zhong, Zili Li, Yu Wang, Yu Miao, Bo Zhou, Yuanfan Li, Hao Wang, Zhongkai Zhao, Faming Wu, Zhengxuan Jiang, Weihao Tan, Heyuan Yao, Shi Yan, Xiangyang Li, Yitao Liang, Yujia Qin, and Guang Shi. Game-tars: Pretrained founda...
work page 2025
-
[72]
Norbert Wiener.Cybernetics or Control and Communication in the Animal and the Machine. MIT press, 2019. 1
work page 2019
-
[73]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
Meta- world: A benchmark and evaluation for multi-task and meta reinforcement learning
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta- world: A benchmark and evaluation for multi-task and meta reinforcement learning. InConference on robot learning, pages 1094–1100. PMLR, 2020. 2, 7
work page 2020
-
[75]
Zhecheng Yuan, Sizhe Yang, Pu Hua, Can Chang, Kaizhe Hu, and Huazhe Xu. Rl-vigen: A reinforcement learning benchmark for visual generalization.Advances in Neural Information Processing Systems, 36:6720–6747, 2023. 4
work page 2023
-
[76]
Alex L. Zhang, Thomas L. Griffiths, Karthik R. Narasimhan, and Ofir Press. Videogamebench: Can vision-language mod- els complete popular video games?, 2025. 9
work page 2025
-
[77]
Take a step back: Rethinking the two stages in visual reasoning, 2024
Mingyu Zhang, Jiting Cai, Mingyu Liu, Yue Xu, Cewu Lu, and Yong-Lu Li. Take a step back: Rethinking the two stages in visual reasoning, 2024. 1
work page 2024
-
[78]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023. 7 13 IPR-1: Interactive Physical Reasoner Supplementary Material In this supplementary, we further provide the additional contents as follows: Sec. 8: Further Discussion. Sec. 9: Benchmark De...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[79]
Further Discussion Recent progress in world models and interactive agents has produced systems that can predict future states, learn latent dynamics, and act across large numbers of games. While we share certain design choices with these systems—such as learning latent dynamics, adopting multimodal interfaces, and scaling across diverse environments—our m...
-
[80]
Benchmark Details 9.1. Game Sources Retro games.We curate 863 open-source retro titles via STABLE-RETRO[47], covering NES, SNES, GENESIS, SMS consoles,etc. These environments provide frame- perfect emulation with discrete controller actions (D-pad directions, up to four face buttons, and start/select), and span a wide range of genres includingplatformers,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.