Human2Any: Human-to-Robot Transfer via Constraint-Aware Compositional Planning
Pith reviewed 2026-06-30 09:57 UTC · model grok-4.3
The pith
Human videos supply reusable object interaction knowledge that robots can apply to new tasks by combining with their own feasibility planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
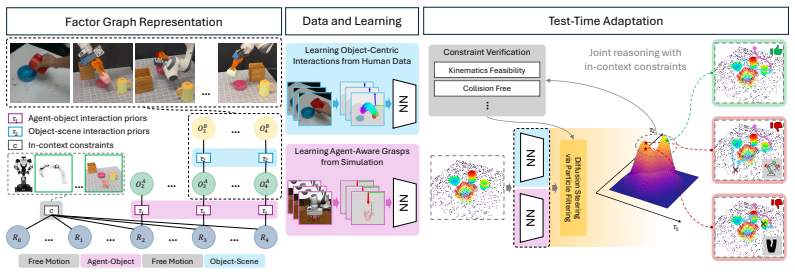
Human2Any represents manipulation tasks through object-object interaction motion extracted from human videos. These priors are then composed with robot-side feasibility reasoning and motion planning to generate actions that adapt to different robot embodiments and scene geometries, enabling transfer without real-world robot training data in the target contexts.
What carries the argument
Object-object interaction motion, which captures task-relevant scene changes while ignoring embodiment-specific details.
If this is right
- Human-derived interaction knowledge applies directly to a Franka arm and an RBY-1 humanoid without retraining on robot data.
- The same priors handle variations in scene geometry and task contexts through compositional planning.
- Robots can perform manipulation in settings where collecting robot demonstrations is difficult or unsafe.
Where Pith is reading between the lines
- This method could lower the barrier for deploying robots in new environments by leveraging existing video data.
- It opens the possibility of scaling robot learning to the volume of human video available online.
- The compositional nature suggests it could be combined with other planning methods for more complex behaviors.
Load-bearing premise
The motion of objects interacting in human videos contains the essential information needed for successful robot execution once feasibility is checked.
What would settle it
Demonstrating that the composed plans frequently fail on tasks where human videos show clear interactions but robot execution misses key constraints or details would falsify the approach.
Figures












read the original abstract
Human videos are a scalable source of supervision for robot manipulation, as they are abundant and naturally capture rich object interactions. However, transferring human demonstrations to robots remains challenging due to embodiment mismatch, scene variation, and robot-specific feasibility constraints. We present Human2Any, a framework for learning reusable object-centric interaction priors from human videos without requiring real-world robot demonstrations in the target task contexts. Human2Any represents manipulation through object-object interaction motion, capturing task-relevant scene changes while abstracting away embodiment-specific details. It composes learned interaction priors with robot-side feasibility reasoning and motion planning, allowing the same human-derived knowledge to adapt to different embodiments, scene geometries, and task contexts. We validate Human2Any across diverse manipulation settings, including real-world experiments on a Franka tabletop setup and an RBY-1 humanoid mobile robot, demonstrating robust interaction-centric manipulation without real-world robot training data. Project website: https://human2any.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Human2Any, a framework for human-to-robot transfer in manipulation that learns reusable object-centric interaction priors from human videos. It represents tasks via object-object interaction motions to abstract embodiment details, then composes these priors with robot-side feasibility reasoning and motion planning to adapt to new embodiments, scenes, and contexts. Validation is claimed via real-world experiments on a Franka arm and RBY-1 humanoid without target-task robot demonstrations.
Significance. If the compositional transfer mechanism holds, the work could meaningfully advance scalable robot learning by reducing reliance on robot-specific data collection. The emphasis on object-object interactions and constraint-aware planning addresses embodiment mismatch in a potentially generalizable way, though the absence of technical details limits assessment of novelty relative to prior video-to-robot methods.
major comments (2)
- [Abstract] Abstract: The central claim that object-object interaction motion captures task-relevant scene changes while abstracting embodiment details is stated at a high level without any formal representation, equations, or pseudocode for the prior learning or composition step, making it impossible to evaluate internal consistency or how feasibility constraints are enforced.
- [Abstract] Abstract: No quantitative metrics, baselines, success rates, or ablation results are reported for the Franka tabletop or RBY-1 experiments, so the claim of 'robust interaction-centric manipulation without real-world robot training data' cannot be assessed for support by the data.
Simulated Author's Rebuttal
We thank the referee for their comments. We address each point below and will revise the abstract to better support evaluation of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that object-object interaction motion captures task-relevant scene changes while abstracting embodiment details is stated at a high level without any formal representation, equations, or pseudocode for the prior learning or composition step, making it impossible to evaluate internal consistency or how feasibility constraints are enforced.
Authors: The abstract is intentionally high-level due to length constraints. The manuscript provides the formal representation of the object-object interaction prior, its learning objective, the composition with robot-side feasibility constraints, and pseudocode in Sections 3 and 4. To improve accessibility from the abstract alone, we will add a concise reference to the key formulation and constraint enforcement mechanism. revision: yes
-
Referee: [Abstract] Abstract: No quantitative metrics, baselines, success rates, or ablation results are reported for the Franka tabletop or RBY-1 experiments, so the claim of 'robust interaction-centric manipulation without real-world robot training data' cannot be assessed for support by the data.
Authors: We agree that the abstract lacks specific quantitative results. The manuscript reports these details, including success rates, baseline comparisons, and ablations for the Franka and RBY-1 experiments, in Section 5. We will revise the abstract to include key metrics that support the central claim. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided manuscript text consists of a high-level description of a compositional framework that learns object-centric interaction priors from human videos and composes them with robot feasibility reasoning and motion planning. No equations, derivations, fitted parameters, or load-bearing self-citations are present in the abstract or summary. The central claim is a methodological composition rather than a mathematical reduction, and the validation is described as empirical across robot platforms without any indication that results are forced by construction from inputs. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Firoozi, J
R. Firoozi, J. Tucker, S. Tian, A. Majumdar, J. Sun, W. Liu, Y . Zhu, S. Song, A. Kapoor, K. Hausman, et al. Foundation models in robotics: Applications, challenges, and the fu- ture.The International Journal of Robotics Research, 2024. doi:https://doi.org/10.1177/ 02783649241281508
2024
-
[2]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[3]
Z. Zhao, S. Cheng, Y . Ding, Z. Zhou, S. Zhang, D. Xu, and Y . Zhao. A survey of optimization- based task and motion planning: From classical to learning approaches.IEEE/ASME Transac- tions on Mechatronics, 30(4):2799–2825, Aug. 2025. ISSN 1941-014X. doi:10.1109/tmech. 2024.3452509. URLhttp://dx.doi.org/10.1109/TMECH.2024.3452509
-
[4]
T. L. Team, J. Barreiros, A. Beaulieu, A. Bhat, R. Cory, E. Cousineau, H. Dai, C.-H. Fang, K. Hashimoto, M. Z. Irshad, M. Itkina, N. Kuppuswamy, K.-H. Lee, K. Liu, D. McConachie, I. McMahon, H. Nishimura, C. Phillips-Grafflin, C. Richter, P. Shah, K. Srinivasan, B. Wulfe, C. Xu, M. Zhang, A. Alspach, M. Angeles, K. Arora, V . C. Guizilini, A. Castro, D. C...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InProceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[6]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın. What matters in learning from offline human demonstrations for robot manipulation. InarXiv preprint arXiv:2108.03298, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, P. Florence, C. Fu, M. G. Arenas, K. Gopalakrishnan, K. Han, K. Hausman, A. Herzog, J. Hsu, B. Ichter, A. Irpan, N. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, L. Lee, T.-W. E. Lee, S. Levine, Y . Lu, H. Michalewski, I. Mordatch, K. Pe...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Florence, C
P. Florence, C. Lynch, A. Zeng, O. Ramirez, A. Wahid, L. Downs, A. Wong, J. Lee, I. Mor- datch, and J. Tompson. Implicit behavioral cloning.Conference on Robot Learning (CoRL), 2021
2021
-
[9]
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations. InProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[10]
Saxena, M
V . Saxena, M. Bronars, N. R. Arachchige, K. Wang, W. C. Shin, S. Nasiriany, A. Mandlekar, and D. Xu. What matters in learning from large-scale datasets for robot manipulation. In The Thirteenth International Conference on Learning Representations, 2025. URLhttps: //openreview.net/forum?id=LqhorpRLIm. 9
2025
-
[11]
O. X.-E. Collaboration, A. O’Neill, A. Rehman, A. Gupta, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, A. Tung, A. Bewley, A. Her- zog, A. Irpan, A. Khazatsky, A. Rai, A. Gupta, A. Wang, A. Kolobov, A. Singh, A. Garg, A. Kembhavi, A. Xie, A. Brohan, A. Raffin, A. Sharma, A. Yavary, A. Jain, A. Balakr- ishna, A. W...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Kareer, D
S. Kareer, D. Patel, R. Punamiya, P. Mathur, S. Cheng, C. Wang, J. Hoffman, and D. Xu. Egomimic: Scaling imitation learning via egocentric video. In2025 IEEE International Con- ference on Robotics and Automation (ICRA), pages 13226–13233. IEEE, 2025
2025
- [14]
-
[15]
Bharadhwaj, R
H. Bharadhwaj, R. Mottaghi, A. Gupta, and S. Tulsiani. Track2act: Predicting point tracks from internet videos enables generalizable robot manipulation. InEuropean Conference on Computer Vision, pages 306–324. Springer, 2024
2024
-
[16]
EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video
R. Hoque, P. Huang, D. J. Yoon, M. Sivapurapu, and J. Zhang. Egodex: Learning dexterous manipulation from large-scale egocentric video.arXiv preprint arXiv:2505.11709, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Bharadhwaj, A
H. Bharadhwaj, A. Gupta, V . Kumar, and S. Tulsiani. Towards generalizable zero-shot manip- ulation via translating human interaction plans, 2023. 10
2023
-
[18]
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R ¨adle, C. Rolland, L. Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Y . Xiao, J. Wang, N. Xue, N. Karaev, Y . Makarov, B. Kang, X. Zhu, H. Bao, Y . Shen, and X. Zhou. Spatialtrackerv2: 3d point tracking made easy. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025. URLhttps://arxiv.org/abs/2507. 12462
2025
-
[20]
B. Wen, W. Yang, J. Kautz, and S. Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17868–17879, 2024
2024
- [21]
- [22]
- [23]
- [24]
- [25]
-
[26]
Punamiya, D
R. Punamiya, D. Patel, P. Aphiwetsa, P. Kuppili, L. Y . Zhu, S. Kareer, J. Hoffman, and D. Xu. Egobridge: Domain adaptation for generalizable imitation from egocentric human data. In Human to Robot: Workshop on Sensorizing, Modeling, and Learning from Humans, 2025
2025
-
[27]
S. Nair, A. Rajeswaran, V . Kumar, C. Finn, and A. Gupta. R3m: A universal visual represen- tation for robot manipulation.arXiv preprint arXiv:2203.12601, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Radosavovic, T
I. Radosavovic, T. Xiao, S. James, P. Abbeel, J. Malik, and T. Darrell. Real-world robot learning with masked visual pre-training. InConference on Robot Learning, pages 416–426. PMLR, 2023
2023
-
[29]
Y . J. Ma, S. Sodhani, D. Jayaraman, O. Bastani, V . Kumar, and A. Zhang. Vip: Towards universal visual reward and representation via value-implicit pre-training.arXiv preprint arXiv:2210.00030, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
D. Xu, A. Mandlekar, R. Mart ´ın-Mart´ın, Y . Zhu, S. Savarese, and L. Fei-Fei. Deep affor- dance foresight: Planning through what can be done in the future. In2021 IEEE international conference on robotics and automation (ICRA), pages 6206–6213. IEEE, 2021
2021
-
[31]
H.-S. Fang, C. Wang, H. Fang, M. Gou, J. Liu, H. Yan, W. Liu, Y . Xie, and C. Lu. Anygrasp: Robust and efficient grasp perception in spatial and temporal domains.IEEE Transactions on Robotics (T-RO), 2023
2023
- [32]
-
[33]
Eppner, A
C. Eppner, A. Mousavian, and D. Fox. Acronym: A large-scale grasp dataset based on sim- ulation. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 6222–6227. IEEE, 2021
2021
-
[34]
S. Song, A. Zeng, J. Lee, and T. Funkhouser. Grasping in the wild: Learning 6dof closed-loop grasping from low-cost demonstrations.Robotics and Automation Letters, 2020
2020
-
[35]
B. Eisner, H. Zhang, and D. Held. FlowBot3D: Learning 3D Articulation Flow to Manipulate Articulated Objects. InProceedings of Robotics: Science and Systems, New York City, NY , USA, June 2022. doi:10.15607/RSS.2022.XVIII.018
-
[36]
C.-C. Hsu, B. Wen, J. Xu, Y . Narang, X. Wang, Y . Zhu, J. Biswas, and S. Birchfield. Spot: Se (3) pose trajectory diffusion for object-centric manipulation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 4853–4860. IEEE, 2025
2025
-
[37]
Seita, Y
D. Seita, Y . Wang, S. J. Shetty, E. Y . Li, Z. Erickson, and D. Held. Toolflownet: Robotic manipulation with tools via predicting tool flow from point clouds. InConference on Robot Learning, pages 1038–1049. PMLR, 2023
2023
- [38]
- [39]
- [40]
-
[41]
Y . Su, X. Zhan, H. Fang, Y .-L. Li, C. Lu, and L. Yang. Motion before action: Diffusing object motion as manipulation condition.IEEE Robotics and Automation Letters, 2025
2025
- [42]
- [43]
-
[44]
Dreczkowski, P
K. Dreczkowski, P. Vitiello, V . V osylius, and E. Johns. Learning a thousand tasks in a day. Science Robotics, 10(108):eadv7594, 2025
2025
-
[45]
L. P. Kaelbling and T. Lozano-P ´erez. Hierarchical task and motion planning in the now. In 2011 IEEE international conference on robotics and automation, pages 1470–1477. IEEE, 2011
2011
-
[46]
C. R. Garrett, R. Chitnis, R. Holladay, B. Kim, T. Silver, L. P. Kaelbling, and T. Lozano-P´erez. Integrated task and motion planning.Annual review of control, robotics, and autonomous systems, 4(1):265–293, 2021
2021
-
[47]
C. R. Garrett, T. Lozano-P´erez, and L. P. Kaelbling. Pddlstream: Integrating symbolic planners and blackbox samplers via optimistic adaptive planning. InProceedings of the international conference on automated planning and scheduling, volume 30, pages 440–448, 2020
2020
-
[48]
Cheng and D
S. Cheng and D. Xu. League: Guided skill learning and abstraction for long-horizon manipu- lation.IEEE Robotics and Automation Letters, 8(10):6451–6458, 2023
2023
- [49]
-
[50]
Mandlekar, C
A. Mandlekar, C. Garrett, D. Xu, and D. Fox. Human-in-the-loop task and motion planning for imitation learning. In7th Annual Conference on Robot Learning, 2023. 12
2023
- [51]
-
[52]
Mandalika, S
A. Mandalika, S. Choudhury, O. Salzman, and S. Srinivasa. Generalized lazy search for robot motion planning: Interleaving search and edge evaluation via event-based toggles. InPro- ceedings of the International Conference on Automated Planning and Scheduling, volume 29, pages 745–753, 2019
2019
-
[53]
Chitnis, D
R. Chitnis, D. Hadfield-Menell, A. Gupta, S. Srivastava, E. Groshev, C. Lin, and P. Abbeel. Guided search for task and motion plans using learned heuristics. In2016 IEEE International Conference on Robotics and Automation (ICRA), pages 447–454. IEEE, 2016
2016
-
[54]
Chitnis, L
R. Chitnis, L. P. Kaelbling, and T. Lozano-P ´erez. Learning quickly to plan quickly using modular meta-learning. In2019 International Conference on Robotics and Automation (ICRA), pages 7865–7871. IEEE, 2019
2019
-
[55]
Z. Wang, C. R. Garrett, L. P. Kaelbling, and T. Lozano-P´erez. Learning compositional models of robot skills for task and motion planning.The International Journal of Robotics Research, 40(6-7):866–894, 2021
2021
-
[56]
Ortiz-Haro, J.-S
J. Ortiz-Haro, J.-S. Ha, D. Driess, and M. Toussaint. Structured deep generative models for sampling on constraint manifolds in sequential manipulation. InConference on Robot Learn- ing, pages 213–223. PMLR, 2022
2022
-
[57]
X. Fang, C. R. Garrett, C. Eppner, T. Lozano-P ´erez, L. P. Kaelbling, and D. Fox. Dimsam: Diffusion models as samplers for task and motion planning under partial observability. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1412–1419. IEEE, 2024
2024
-
[58]
Kumar, W
N. Kumar, W. Shen, F. Ramos, D. Fox, T. Lozano-P ´erez, L. P. Kaelbling, and C. R. Garrett. Open-world task and motion planning via vision-language model generated constraints.IEEE Robotics and Automation Letters, 2026
2026
-
[59]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[60]
J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[61]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based gen- erative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[62]
U. A. Mishra, S. Xue, Y . Chen, and D. Xu. Generative skill chaining: Long-horizon skill planning with diffusion models. InConference on Robot Learning, pages 2905–2925. PMLR, 2023
2023
-
[63]
U. A. Mishra, Y . Chen, and D. Xu. Generative factor chaining: Coordinated manipulation with diffusion-based factor graph. InICRA 2024 Workshop{\textemdash}Back to the Future: Robot Learning Going Probabilistic, 2024
2024
- [64]
- [65]
-
[66]
Q. Clark and F. Shkurti. What do you need for diverse trajectory stitching in diffusion plan- ning?arXiv preprint arXiv:2505.18083, 2025. 13
-
[67]
Lawrence, J
J. Lawrence, J. Bernal, and C. Witzgall. A purely algebraic justification of the kabsch- umeyama algorithm.Journal of research of the National Institute of Standards and Technology, 124:1, 2019
2019
-
[68]
M. A. Fischler and R. C. Bolles. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography.Communications of the ACM, 24(6):381–395, 1981
1981
-
[69]
R. K. Guo, X. Lin, M. Liu, J. Gu, and H. Su. Mplib: a lightweight motion planning library,
-
[70]
Software available at https://motion- planning-lib.readthedocs.io/latest/
URLhttps://github.com/haosulab/MPlib. Software available at https://motion- planning-lib.readthedocs.io/latest/
-
[71]
O. Khatib. A unified approach for motion and force control of robot manipulators: The opera- tional space formulation.IEEE Journal on Robotics and Automation, 3(1):43–53, 2003
2003
-
[72]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–
2012
-
[73]
Mu- JoCo: A physics engine for model-based control
IEEE, 2012. doi:10.1109/IROS.2012.6386109
-
[74]
B. Wen, M. Trepte, J. Aribido, J. Kautz, O. Gallo, and S. Birchfield. Foundationstereo: Zero- shot stereo matching.CVPR, 2025
2025
-
[75]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[76]
Eppner, A
C. Eppner, A. Mousavian, and D. Fox. ACRONYM: A large-scale grasp dataset based on simulation. In2021 IEEE Int. Conf. on Robotics and Automation, ICRA, 2020
2020
-
[77]
arXiv preprint arXiv:2507.13097 (2025)
A. Murali, B. Sundaralingam, Y .-W. Chao, J. Yamada, W. Yuan, M. Carlson, F. Ramos, S. Birchfield, D. Fox, and C. Eppner. Graspgen: A diffusion-based framework for 6- dof grasping with on-generator training.arXiv preprint arXiv:2507.13097, 2025. URL https://arxiv.org/abs/2507.13097
-
[78]
Z. Wei, Z. Xu, J. Guo, Y . Hou, C. Gao, Z. Cai, J. Luo, and L. Shao.D(R,O)grasp: A unified representation of robot and object interaction for cross-embodiment dexterous grasping. In 2025 IEEE International Conference on Robotics and Automation (ICRA), pages 4982–4988,
2025
-
[79]
doi:10.1109/ICRA55743.2025.11127754
-
[81]
14 Supplementary Material The supplementary material has the following contents: •Hardware Setup(Sec
URLhttps://arxiv.org/abs/2406.09509. 14 Supplementary Material The supplementary material has the following contents: •Hardware Setup(Sec. A): Describes camera, perception, planning, and control details for the Franka and RBY-1 real-world platforms; •Tasks and Baselines(Sec. B): Details simulation and real-world task semantics, reset ranges, evaluation pr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.