Multi-SpatialMLLM: Multi-Frame Spatial Understanding with Multi-Modal Large Language Models
Pith reviewed 2026-05-25 08:35 UTC · model grok-4.3
The pith
A framework trains MLLMs on depth, correspondence and dynamic perception across frames using a 27-million-sample dataset to enable multi-frame spatial reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Integrating depth perception, visual correspondence, and dynamic perception into MLLM training on the MultiSPA dataset of more than 27 million samples from diverse 3D and 4D scenes produces Multi-SpatialMLLM, which delivers significant gains over baselines and proprietary systems while exhibiting multi-task benefits, emergent spatial capabilities, and the ability to annotate multi-frame rewards for robotics.
What carries the argument
The data pipeline that generates the MultiSPA dataset to train the three spatial skills across multiple frames inside an MLLM.
If this is right
- Multi-frame perception becomes scalable and generalizable across 3D and 4D scenes.
- Multi-task benefits and emergent spatial capabilities appear in challenging scenarios.
- The model functions as a multi-frame reward annotator for robotics applications.
- A single benchmark with uniform metrics now evaluates a wide spectrum of spatial tasks.
Where Pith is reading between the lines
- The same skill-integration approach could transfer to other temporal reasoning domains such as action prediction.
- Reducing reliance on the full 27 million samples while preserving gains would make the method more practical.
- The benchmark could serve as a shared testbed for comparing future multi-frame MLLM variants.
Load-bearing premise
The MultiSPA dataset of synthetic and collected samples covers the full diversity and complexity of real-world multi-frame spatial tasks without distribution shifts that would invalidate the reported gains.
What would settle it
A sharp drop in performance when the trained model is tested on real-world multi-frame video data collected independently of the described pipeline would falsify the generalizability claim.
Figures











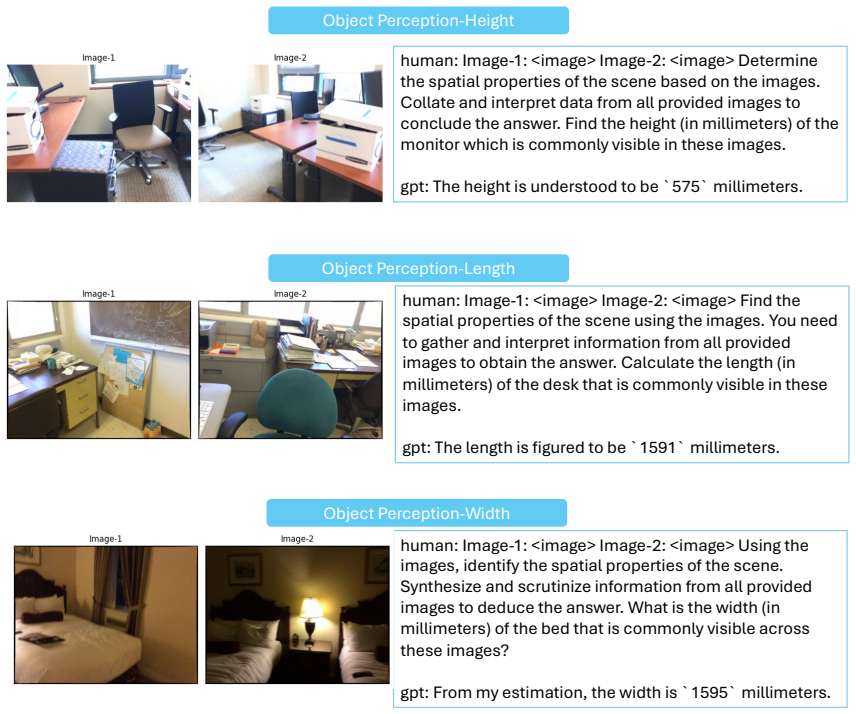


read the original abstract
Multi-modal large language models (MLLMs) have rapidly advanced in visual tasks, yet their spatial understanding remains limited to single images, leaving them ill-suited for physical-world applications that require multi-frame reasoning. In this paper, we propose a framework to equip MLLMs with multi-frame spatial understanding by integrating fundamental spatial skills, including depth perception, visual correspondence, and dynamic perception. We design a novel data pipeline and collect the MultiSPA dataset of more than 27 million samples spanning diverse 3D and 4D scenes to enable training. Alongside MultiSPA, we introduce a comprehensive benchmark that tests a wide spectrum of spatial tasks under uniform metrics. Our resulting model, Multi-SpatialMLLM, achieves significant gains over baselines and proprietary systems, demonstrating scalable and generalizable multi-frame perception. We further observe multi-task benefits and emergent spatial capabilities in challenging scenarios, and showcase how our model can serve as a multi-frame reward annotator for robotics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework to extend multi-modal large language models (MLLMs) to multi-frame spatial understanding by integrating depth perception, visual correspondence, and dynamic perception. It introduces a data pipeline to create the MultiSPA dataset (>27M samples across diverse 3D/4D scenes) and an accompanying benchmark, resulting in the Multi-SpatialMLLM model that reports significant gains over baselines and proprietary systems, plus multi-task benefits, emergent capabilities, and use as a robotics reward annotator.
Significance. If the reported gains prove robust and generalizable beyond the training distribution, the work would address a clear limitation in current MLLMs for physical-world applications. The scale of the MultiSPA dataset and the unified benchmark are notable contributions that could support further research in multi-frame perception.
major comments (2)
- [Abstract (data pipeline and benchmark description)] The central claim of 'significant gains' demonstrating 'scalable and generalizable multi-frame perception' rests on the MultiSPA dataset and benchmark being representative of real-world conditions. The abstract provides no details on how the synthetic data pipeline accounts for variations such as sensor noise, complex lighting, long-term occlusions, or non-rigid motion, nor does it reference any external real-world multi-frame benchmark for validation.
- [Abstract (model and results description)] Without ablations, error bars, or explicit integration details for the three spatial skills (depth, correspondence, dynamic perception), it is impossible to determine whether the performance improvements are additive, whether post-hoc filtering was applied, or whether the gains could be reproduced on held-out real data.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the abstract and related sections to improve clarity on the data pipeline and experimental details.
read point-by-point responses
-
Referee: [Abstract (data pipeline and benchmark description)] The central claim of 'significant gains' demonstrating 'scalable and generalizable multi-frame perception' rests on the MultiSPA dataset and benchmark being representative of real-world conditions. The abstract provides no details on how the synthetic data pipeline accounts for variations such as sensor noise, complex lighting, long-term occlusions, or non-rigid motion, nor does it reference any external real-world multi-frame benchmark for validation.
Authors: We agree the abstract is concise and omits these specifics. The full manuscript (Section 3) describes the data pipeline, which draws from multiple 3D/4D sources to incorporate simulated variations in lighting, occlusions, non-rigid motion, and sensor-like noise. The benchmark is designed to test generalizability across diverse scenes. To address the concern directly, we will revise the abstract to briefly note these pipeline elements and the benchmark's scope. We will also add a short discussion referencing comparisons to available real-world multi-frame tasks. revision: yes
-
Referee: [Abstract (model and results description)] Without ablations, error bars, or explicit integration details for the three spatial skills (depth, correspondence, dynamic perception), it is impossible to determine whether the performance improvements are additive, whether post-hoc filtering was applied, or whether the gains could be reproduced on held-out real data.
Authors: The abstract summarizes outcomes due to length constraints; the full paper provides the requested details. Section 4 includes ablations on skill integration (showing additive benefits), error bars in all result tables, and explicit model architecture descriptions for combining depth, correspondence, and dynamic perception without post-hoc filtering. Held-out evaluations are reported within the benchmark splits. We will revise the abstract to reference these analyses for better context. revision: partial
Circularity Check
No circularity: empirical training on generated dataset with independent benchmark evaluation
full rationale
The paper's central claims rest on collecting/generating the MultiSPA dataset via a described pipeline, training an MLLM, and reporting empirical gains on an introduced benchmark. No equations, fitted parameters renamed as predictions, or self-citation chains are present that would make results equivalent to inputs by construction. The work is self-contained as standard supervised training plus evaluation; benchmark gains are not forced by definition or prior author results. This matches the default expectation for non-circular empirical ML papers.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 8 Pith papers
-
Token Warping Helps MLLMs Look from Nearby Viewpoints
Backward token warping in ViT-based MLLMs enables reliable reasoning from nearby viewpoints by preserving semantic coherence better than pixel-wise warping or fine-tuning baselines.
-
SpatialMosaic: A Multiview VLM Dataset for Partial Visibility
SpatialMosaic introduces a 2M-pair multi-view QA dataset and 1M-pair benchmark for MLLMs on spatial reasoning under partial visibility, plus a hybrid baseline that integrates 3D reconstruction models as geometry encoders.
-
4D-RGPT: Toward Region-level 4D Understanding via Perceptual Distillation
4D-RGPT uses perceptual 4D distillation to boost region-level 4D perception in multimodal LLMs and reports gains on existing and new video QA benchmarks.
-
Unlocking Dense Metric Depth Estimation in VLMs
DepthVLM attaches a depth head to VLMs for native dense metric depth prediction alongside language outputs using a two-stage unified training schedule and a new indoor-outdoor benchmark.
-
Unlocking Dense Metric Depth Estimation in VLMs
DepthVLM converts a standard VLM into a dense metric depth predictor by attaching a lightweight head and training under unified vision-text supervision, outperforming prior VLMs and some pure vision models on a new in...
-
Cambrian-S: Towards Spatial Supersensing in Video
Cambrian-S introduces VSI-SUPER benchmarks for long-horizon spatial recall and counting, shows data scaling yields 30% gains on existing tests, and demonstrates a self-supervised next-latent predictor using surprise o...
-
From Where Things Are to What They Are For: Benchmarking Spatial-Functional Intelligence in Multimodal LLMs
SFI-Bench shows current multimodal LLMs struggle to integrate spatial memory with functional reasoning and external knowledge in video tasks.
-
OpenSpatial: A Principled Data Engine for Empowering Spatial Intelligence
OpenSpatial supplies a principled open-source data engine and 3-million-sample dataset that raises spatial-reasoning model performance by an average of 19 percent on benchmarks.
Reference graph
Works this paper leans on
-
[1]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. In NeurIPS,
-
[2]
anthropic. Claude 3.5 sonnet. https : / / www . anthropic . com / news / claude - 3 - 5 - sonnet,
-
[3]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xi- aodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Day- iheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfe...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jin- gren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv:2308.12966, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Drivetrack: A benchmark for long-range point tracking in real-world videos
Arjun Balasingam, Joseph Chandler, Chenning Li, Zhoutong Zhang, and Hari Balakrishnan. Drivetrack: A benchmark for long-range point tracking in real-world videos. In CVPR,
-
[6]
Per- ception tokens enhance visual reasoning in multimodal lan- guage models
Mahtab Bigverdi, Zelun Luo, Cheng-Yu Hsieh, Ethan Shen, Dongping Chen, Linda G Shapiro, and Ranjay Krishna. Per- ception tokens enhance visual reasoning in multimodal lan- guage models. arXiv:2412.03548, 2024. 3
-
[7]
Pi0: A vision-language- action flow model for general robot control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mo- hith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Hao- huan Wang, and Ury Zhilinsky. Pi0: A...
-
[8]
Spatialbot: Pre- cise spatial understanding with vision language models
Wenxiao Cai, Iaroslav Ponomarenko, Jianhao Yuan, Xiaoqi Li, Wankou Yang, Hao Dong, and Bo Zhao. Spatialbot: Pre- cise spatial understanding with vision language models. In ICRA, 2025. 3
work page 2025
-
[9]
Spatialvlm: Endow- ing vision-language models with spatial reasoning capabili- ties
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endow- ing vision-language models with spatial reasoning capabili- ties. In CVPR, 2024. 1, 2, 3, 8
work page 2024
-
[10]
Sharegpt4v: Improving large multi-modal models with better captions
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. Sharegpt4v: Improving large multi-modal models with better captions. In ECCV, 2024. 2
work page 2024
-
[11]
Are We on the Right Way for Evaluating Large Vision-Language Models?
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision-language models? arXiv:2403.20330, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhang- wei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites. Science China Information Sciences , 2024. 2, 4
work page 2024
-
[13]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. In CVPR,
-
[14]
Spatial- rgpt: Grounded spatial reasoning in vision-language models
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Rui- han Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatial- rgpt: Grounded spatial reasoning in vision-language models. In NeurIPS, 2024. 1, 2, 3, 8
work page 2024
-
[15]
Erfei Cui, Yinan He, Zheng Ma, Zhe Chen, Hao Tian, Weiyun Wang, Kunchang Li, Yi Wang, Wenhai Wang, Xizhou Zhu, Lewei Lu, Tong Lu, Yali Wang, Limin Wang, Yu Qiao, and Jifeng Dai. sharegpt4o. https : / / sharegpt4o.github.io/, 2024. 2
work page 2024
-
[16]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In CVPR, 2017. 2, 4, 5, 7, 9
work page 2017
-
[17]
Instructblip: Towards general- purpose vision-language models with instruction tuning
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructblip: Towards general- purpose vision-language models with instruction tuning. NeurIPS, 20243. 1, 2, 4
-
[18]
Gemini 2.0: our new ai model for the agentic era
Google Deepmind. Gemini 2.0: our new ai model for the agentic era. https://blog.google/technology/ google - deepmind / google - gemini - ai - update - december - 2024 / ceo - message, 2024. 6
work page 2024
-
[19]
PaLM-E: An Embodied Multimodal Language Model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model. arXiv:2303.03378, 2023. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Mengfei Du, Binhao Wu, Zejun Li, Xuanjing Huang, and Zhongyu Wei. Embspatial-bench: Benchmarking spatial un- derstanding for embodied tasks with large vision-language models. arXiv:2406.05756, 2024. 3
-
[21]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. In ECCV, 2024. 2, 3, 7
work page 2024
-
[22]
Multimodal-gpt: A vision and language model for dialogue with humans
Tao Gong, Chengqi Lyu, Shilong Zhang, Yudong Wang, Miao Zheng, Qian Zhao, Kuikun Liu, Wenwei Zhang, Ping Luo, and Kai Chen. Multimodal-gpt: A vision and language model for dialogue with humans. arXiv:2305.04790, 2023. 2
-
[23]
22 Vizwiz grand challenge: Answering visual questions from blind people
Danna Gurari, Qing Li, Abigale J Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P Bigham. 22 Vizwiz grand challenge: Answering visual questions from blind people. In CVPR, 2018. 7
work page 2018
-
[24]
Imagebind-llm: Multi-modality instruction tun- ing
Jiaming Han, Renrui Zhang, Wenqi Shao, Peng Gao, Peng Xu, Han Xiao, Kaipeng Zhang, Chris Liu, Song Wen, Ziyu Guo, et al. Imagebind-llm: Multi-modality instruction tun- ing. arXiv:2309.03905, 2023. 2
-
[25]
R. Hartley and A. Zisserman. Multiple View Geometry in Computer Vision. Cambridge University Press, 2003. 2
work page 2003
-
[26]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. ICLR,
-
[27]
Mu Hu, Wei Yin, Chi Zhang, Zhipeng Cai, Xiaoxiao Long, Hao Chen, Kaixuan Wang, Gang Yu, Chunhua Shen, and Shaojie Shen. Metric3d v2: A versatile monocular geomet- ric foundation model for zero-shot metric depth and surface normal estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 2
work page 2024
-
[28]
Language Is Not All You Need: Aligning Perception with Language Models
Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv, Lei Cui, Owais Khan Mohammed, Qiang Liu, et al. Language is not all you need: Aligning perception with language mod- els. arXiv:2302.14045, 2023. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Han- naneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. Open- clip, 2021. 2
work page 2021
-
[30]
Clevr: A diagnostic dataset for compositional language and elementary visual reasoning
Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. In CVPR, 2017. 3
work page 2017
-
[31]
Panoptic studio: A massively multiview system for social motion capture
Hanbyul Joo, Hao Liu, Lei Tan, Lin Gui, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh. Panoptic studio: A massively multiview system for social motion capture. In Proceedings of the IEEE interna- tional conference on computer vision , 2015. 2, 4, 5, 7, 9
work page 2015
-
[32]
Openvla: An open- source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Fos- ter, Grace Lam, Pannag Sanketi, et al. Openvla: An open- source vision-language-action model. In CoRL, 2024. 3
work page 2024
-
[33]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. In ICCV, 2023. 3
work page 2023
-
[34]
Tapvid-3d: A benchmark for tracking any point in 3d
Skanda Koppula, Ignacio Rocco, Yi Yang, Joe Heyward, Jo˜ao Carreira, Andrew Zisserman, Gabriel Brostow, and Carl Doersch. Tapvid-3d: A benchmark for tracking any point in 3d. arXiv preprint arXiv:2407.05921, 2024. 2, 4, 5
-
[35]
Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Ui- jlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. IJCV,
-
[36]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv:2408.03326, 2024. 1, 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
What Matters in Building Vision-Language-Action Models for Generalist Robots
Xinghang Li, Peiyan Li, Minghuan Liu, Dong Wang, Jirong Liu, Bingyi Kang, Xiao Ma, Tao Kong, Hanbo Zhang, and Huaping Liu. Towards generalist robot policies: What matters in building vision-language-action models. arXiv preprint arXiv:2412.14058, 2024. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. In EMNLP, 2023. 7
work page 2023
-
[39]
Yuan-Hong Liao, Rafid Mahmood, Sanja Fidler, and David Acuna. Reasoning paths with reference objects elicit quan- titative spatial reasoning in large vision-language models. arXiv:2409.09788, 2024. 2, 3
-
[40]
Vila: On pre-training for visual language models
Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Moham- mad Shoeybi, and Song Han. Vila: On pre-training for visual language models. In CVPR, 2024. 2, 5
work page 2024
-
[41]
Fangyu Liu, Guy Emerson, and Nigel Collier. Visual spatial reasoning. TACL, 2023. 2, 3
work page 2023
-
[42]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In NeurIPS, 2023. 2
work page 2023
-
[43]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In CVPR,
-
[44]
MMBench: Is Your Multi-modal Model an All-around Player?
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. Mmbench: Is your multi-modal model an all-around player? arXiv:2307.06281,
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. ICLR, 2019. 6
work page 2019
-
[46]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, et al. Deepseek-vl: towards real-world vision- language understanding. arXiv:2403.05525, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Mathvista: Evaluating mathemat- ical reasoning of foundation models in visual contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathemat- ical reasoning of foundation models in visual contexts. In ICLR, 2024. 7
work page 2024
-
[48]
Chenyang Ma, Kai Lu, Ta-Ying Cheng, Niki Trigoni, and Andrew Markham. Spatialpin: Enhancing spatial reason- ing capabilities of vision-language models through prompt- ing and interacting 3d priors. In NeurIPS, 2024. 3
work page 2024
-
[49]
Ocr-vqa: Visual question answering by reading text in images
Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty. Ocr-vqa: Visual question answering by reading text in images. In ICDAR, 2019. 7
work page 2019
-
[50]
OpenAI. Gpt-4o. https://openai.com/index/ hello-gpt-4o/, 2024. 1, 4, 6
work page 2024
-
[51]
Aria digital twin: A new benchmark dataset for egocentric 3d machine perception
Xiaqing Pan, Nicholas Charron, Yongqian Yang, Scott Pe- ters, Thomas Whelan, Chen Kong, Omkar Parkhi, Richard Newcombe, and Yuheng Carl Ren. Aria digital twin: A new benchmark dataset for egocentric 3d machine perception. In ICCV, 2023. 2, 4, 5, 7, 9 23
work page 2023
-
[52]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. In ICML, 2021. 2
work page 2021
-
[53]
Does spatial cognition emerge in frontier models? arXiv:2410.06468, 2024
Santhosh Kumar Ramakrishnan, Erik Wijmans, Philipp Kraehenbuehl, and Vladlen Koltun. Does spatial cognition emerge in frontier models? arXiv:2410.06468, 2024. 3
-
[54]
Sat: Spa- tial aptitude training for multimodal language models
Arijit Ray, Jiafei Duan, Reuben Tan, Dina Bashkirova, Rose Hendrix, Kiana Ehsani, Aniruddha Kembhavi, Bryan A Plummer, Ranjay Krishna, Kuo-Hao Zeng, et al. Sat: Spa- tial aptitude training for multimodal language models. arXiv preprint arXiv:2412.07755, 2024. 3
-
[55]
Grounding dino 1.5: Advance the” edge” of open-set object detection, 2024
Tianhe Ren, Qing Jiang, Shilong Liu, Zhaoyang Zeng, Wen- long Liu, Han Gao, Hongjie Huang, Zhengyu Ma, Xiaoke Jiang, Yihao Chen, et al. Grounding dino 1.5: Advance the” edge” of open-set object detection, 2024. 2
work page 2024
-
[56]
Laion-5b: An open large-scale dataset for training next generation image-text models
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Worts- man, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. NeurIPS, 2022. 2
work page 2022
-
[57]
Laion coco: 600m syn- thetic captions from laion2b-en, 2022
Christoph Schuhmann, Andreas K ¨opf, Richard Vencu, Theo Coombes, and Romain Beaumont. Laion coco: 600m syn- thetic captions from laion2b-en, 2022. 2
work page 2022
-
[58]
An empirical analysis on spatial reason- ing capabilities of large multimodal models
Fatemeh Shiri, Xiao-Yu Guo, Mona Far, Xin Yu, Reza Haf, and Yuan-Fang Li. An empirical analysis on spatial reason- ing capabilities of large multimodal models. In EMNLP,
-
[59]
Drivelm: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering. In ECCV, 2024. 1, 3
work page 2024
-
[60]
Robospatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics
Chan Hee Song, Valts Blukis, Jonathan Tremblay, Stephen Tyree, Yu Su, and Stan Birchfield. Robospatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics. arXiv:2411.16537, 2024. 3
-
[61]
Internlm: A multilingual language model with progressively enhanced capabilities
InternLM Team. Internlm: A multilingual language model with progressively enhanced capabilities. https : / / github.com/InternLM/InternLM, 2023. 1, 2, 5, 6
work page 2023
-
[62]
Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai Charitha Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, et al. Cambrian- 1: A fully open, vision-centric exploration of multimodal llms. arXiv preprint arXiv:2406.16860, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv:2302.13971, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[64]
Continuous 3d perception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. arXiv preprint arXiv:2501.12387, 2025. 2
-
[65]
Emergent Abilities of Large Language Models
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. Emergent abilities of large language models. arXiv:2206.07682, 2022. 8
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[66]
Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How mul- timodal large language models see, remember, and recall spaces. arXiv:2412.14171, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass
Jianing Yang, Alexander Sax, Kevin J Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. In Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition , 2025. 2
work page 2025
-
[68]
Sphere: A hierarchical evaluation on spatial perception and reasoning for vision- language models
Wenyu Zhang, Wei En Ng, Lixin Ma, Yuwen Wang, Jungqi Zhao, Boyang Li, and Lu Wang. Sphere: A hierarchical evaluation on spatial perception and reasoning for vision- language models. arXiv preprint arXiv:2412.12693 , 2024. 3
-
[69]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision- language understanding with advanced large language mod- els. arXiv:2304.10592, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[70]
Towards foundation mod- els for 3d vision: How close are we? arXiv preprint arXiv:2410.10799, 2024
Yiming Zuo, Karhan Kayan, Maggie Wang, Kevin Jeon, Jia Deng, and Thomas L Griffiths. Towards foundation mod- els for 3d vision: How close are we? arXiv preprint arXiv:2410.10799, 2024. 2, 3 24
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.