MeshReGen: A Unified 3D Geometry Regeneration Framework
Pith reviewed 2026-05-21 00:44 UTC · model grok-4.3
The pith
MeshReGen regenerates 3D objects from initial shapes and images using a VecSet conditioning mechanism.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
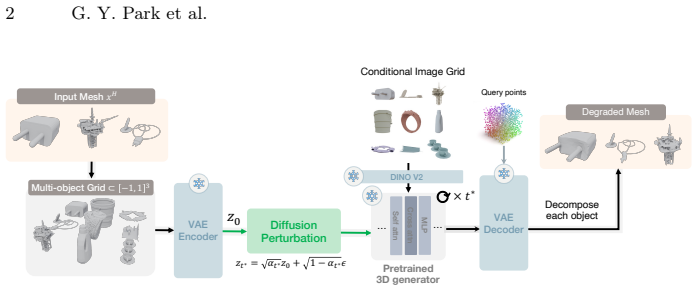
MeshReGen conditions a 3D regenerator on an initial 3D shape and employs a new VecSet-based conditioning mechanism to update or improve the input geometry with consistent fine-grained details. It learns a widely applicable regeneration prior from off-the-shelf 3D datasets via self-supervised pretext tasks and augmentations without additional annotations, and achieves state-of-the-art performance in controllable 3D generation across several tasks including enhancement, reconstruction, and editing.
What carries the argument
VecSet conditioning mechanism that enables the regenerator to refine the input 3D shape with consistent details.
Load-bearing premise
That a conceptually simple conditioning on an initial 3D shape together with VecSet will support many tasks and allow learning a general regeneration prior from self-supervised pretext tasks on off-the-shelf datasets.
What would settle it
Observing that the output meshes fail to maintain geometric consistency with the input shape or do not improve fine-grained quality on standard evaluation benchmarks would falsify the effectiveness of the conditioning approach.
Figures



















read the original abstract
We consider the problem of regenerating 3D objects from 2D images and initial 3D shapes. Most 3D generators operate in a one-shot fashion, converting text or images to a 3D object with limited controllability. We introduce instead MeshReGen, a 3D regenerator that is conditioned on an initial 3D shape. This conceptually simple formulation allows us to support numerous useful tasks, including 3D enhancement, reconstruction, and editing. MeshReGen uses a new conditioning mechanism based on VecSet, which allows the regenerator to update or improve the input geometry with consistent fine-grained details. MeshReGen learns a widely applicable regeneration prior from off-the-shelf 3D datasets via self-supervised pretext tasks and augmentations, without additional annotations. We evaluate both the geometric consistency and fine-grained quality of MeshReGen, achieving state-of-the-art performance in controllable 3D generation across several tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MeshReGen, a unified 3D geometry regeneration framework conditioned on an initial 3D shape. It proposes a VecSet-based conditioning mechanism to enable updating the input geometry while adding consistent fine-grained details. The model learns a regeneration prior via self-supervised pretext tasks and augmentations on off-the-shelf 3D datasets without extra annotations. This formulation supports multiple tasks including 3D enhancement, reconstruction, and editing. The authors evaluate geometric consistency and fine-grained quality, claiming state-of-the-art performance in controllable 3D generation across several tasks.
Significance. If the results hold, the work offers a conceptually simple unified approach to controllable 3D tasks that could reduce reliance on separate models for enhancement, reconstruction, and editing. The self-supervised training on existing datasets without annotations is a clear strength, as is the focus on geometric consistency through conditioning. This could advance practical 3D generation pipelines in computer vision and graphics.
major comments (2)
- [§3.3] §3.3: The self-supervised loss relies on reconstruction from pretext tasks and augmentations. Without an explicit term penalizing deviation from the input geometry on unchanged regions (e.g., a masked consistency loss between input and regenerated mesh), the model could alter input structure arbitrarily, undermining the central claim of preserving structure while adding consistent fine-grained details via VecSet conditioning.
- [§4.1, Table 2] §4.1, Table 2: The SOTA claims for controllable generation rest on quantitative comparisons, but the absence of error bars, statistical tests, or detailed ablation on the VecSet component versus standard conditioning makes it difficult to confirm that the improvements are robust and attributable to the proposed mechanism rather than dataset or training specifics.
minor comments (2)
- [§3] The VecSet conditioning is described at a high level in the method; adding a precise equation or pseudocode for the conditioning operation early in §3 would improve verifiability.
- [Figures] Figure captions for qualitative results could more explicitly label input mesh, regenerated output, and reference for each task to aid reader interpretation.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We have addressed each of the major comments in detail below and made corresponding revisions to the paper to enhance its clarity and the robustness of the presented results.
read point-by-point responses
-
Referee: [§3.3] §3.3: The self-supervised loss relies on reconstruction from pretext tasks and augmentations. Without an explicit term penalizing deviation from the input geometry on unchanged regions (e.g., a masked consistency loss between input and regenerated mesh), the model could alter input structure arbitrarily, undermining the central claim of preserving structure while adding consistent fine-grained details via VecSet conditioning.
Authors: We appreciate the referee's observation regarding the loss formulation. The VecSet conditioning is specifically engineered to enable localized updates by modeling geometric differences through its set-based attention, and the self-supervised pretext tasks (including reconstruction from augmented inputs) are designed to encourage fidelity to the original structure. Nevertheless, we acknowledge that an explicit term could provide additional safeguards. In the revised manuscript we have added a masked consistency loss that penalizes deviations exclusively on regions outside the augmentation masks. This term is integrated into the overall objective in Section 3.3, and we report its effect in a new ablation in the supplementary material. The core self-supervised framework remains unchanged. revision: yes
-
Referee: [§4.1, Table 2] §4.1, Table 2: The SOTA claims for controllable generation rest on quantitative comparisons, but the absence of error bars, statistical tests, or detailed ablation on the VecSet component versus standard conditioning makes it difficult to confirm that the improvements are robust and attributable to the proposed mechanism rather than dataset or training specifics.
Authors: We agree that error bars, statistical significance testing, and a targeted ablation would strengthen the quantitative claims. In the revised manuscript we have rerun the main experiments across five random seeds and added standard deviation error bars to Table 2. We have also inserted a new ablation subsection in §4.1 that directly compares VecSet conditioning against a standard concatenation baseline under identical training settings, confirming that the observed gains are attributable to the VecSet mechanism. Finally, we include paired t-test p-values to establish statistical significance of the improvements over prior methods. revision: yes
Circularity Check
No circularity: regeneration prior learned from external off-the-shelf data via self-supervision
full rationale
The abstract and provided text present MeshReGen as learning a regeneration prior directly from external 3D datasets using self-supervised pretext tasks and augmentations, without additional annotations. The VecSet conditioning is introduced as a new mechanism to support tasks like enhancement and editing, but no equations, fitted parameters, or self-citations are shown that reduce the central claims (consistent fine-grained details, unified tasks) to inputs defined inside the work. The derivation remains self-contained against external benchmarks, with no load-bearing steps that equate predictions to constructions or prior self-work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-supervised pretext tasks and augmentations on off-the-shelf 3D datasets suffice to learn a widely applicable regeneration prior without additional annotations.
invented entities (1)
-
VecSet
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Barda, A., Gadelha, M., Kim, V.G., Aigerman, N., Bermano, A.H., Groueix, T.: Instant3dit: Multiview inpainting for fast editing of 3d objects. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16273–16282 (2025) 13, 11
work page 2025
-
[2]
arXiv preprint arXiv:2403.12032 (2024) 13, 11
Chen, H., Shi, R., Liu, Y., Shen, B., Gu, J., Wetzstein, G., Su, H., Guibas, L.: Generic 3d diffusion adapter using controlled multi-view editing. arXiv preprint arXiv:2403.12032 (2024) 13, 11
-
[3]
In: Proceedings of the European Conference on Computer Vi- sion (ECCV) (2024) 11
Chen, M., Laina, I., Vedaldi, A.: DGE: Direct gaussian 3D editing by consistent multi-view editing. In: Proceedings of the European Conference on Computer Vi- sion (ECCV) (2024) 11
work page 2024
-
[4]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2025) 8
Chen, M., Shapovalov, R., Laina, I., Monnier, T., Wang, J., Novotny, D., Vedaldi, A.: PartGen: Part-level 3D generation and reconstruction with multi-view diffusion models. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2025) 8
work page 2025
-
[5]
Autopartgen: Autogres- sive 3d part generation and discovery.arXiv preprint arXiv:2507.13346, 2025
Chen, M., Wang, J., Shapovalov, R., Monnier, T., Jung, H., Wang, D., Ranjan, R., Laina, I., Vedaldi, A.: Autopartgen: Autogressive 3d part generation and discovery. arXiv preprint arXiv:2507.13346 (2025) 5, 8, 10
-
[6]
In: Proceedings of Advances in Neural Information Processing Systems (NeurIPS) (2025) 7
Chen, M., Wang, J., Shapovalov, R., Monnier, T., Jung, H., Wang, D., Ranjan, R., Laina, I., Vedaldi, A.: AutoPartGen: Autogressive 3D part generation and discovery. In: Proceedings of Advances in Neural Information Processing Systems (NeurIPS) (2025) 7
work page 2025
-
[7]
Dora: Sampling and benchmarking for 3d shape variational auto-encoders
Chen, R., Zhang, J., Liang, Y., Luo, G., Li, W., Liu, J., Li, X., Long, X., Feng, J., Tan, P.: Dora: Sampling and benchmarking for 3D shape variational auto-encoders. arXiv2412.17808(2024) 4
-
[8]
Objaverse-XL: A Universe of 10M+ 3D Objects
Deitke, M., Liu, R., Wallingford, M., Ngo, H., Michel, O., Kusupati, A., Fan, A., Laforte, C., Voleti, V., Gadre, S.Y., VanderBilt, E., Kembhavi, A., Vondrick, C., Gkioxari, G., Ehsani, K., Schmidt, L., Farhadi, A.: Objaverse-XL: A universe of 10M+ 3D objects. CoRRabs/2307.05663(2023) 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [9]
-
[11]
arXiv2411.16820(2024) 3, 4, 6, 13, 11
Deng, K., Guo, Y., Sun, J., Zou, Z., Li, Y., Cai, X., Cao, Y., Liu, Y., Liang, D.: DetailGen3D: generative 3D geometry enhancement via data-dependent flow. arXiv2411.16820(2024) 3, 4, 6, 13, 11
- [12]
-
[13]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Gao, W., Wang, D., Fan, Y., Bozic, A., Stuyck, T., Li, Z., Dong, Z., Ranjan, R., Sarafianos, N.: 3D mesh editing using masked LRMs. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 7154–7165 (2025) 9
work page 2025
-
[14]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Let- man, A., Mathur, A., Schelten, A., Vaughan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024) 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Journal of the Engineering Mechanics Division102(5), 749–756 (1976) 9, 3
Herrmann, L.R.: Laplacian-isoparametric grid generation scheme. Journal of the Engineering Mechanics Division102(5), 749–756 (1976) 9, 3
work page 1976
-
[16]
Advances in Neural Information Processing Systems33, 6840–6851 (2020) 2
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems33, 6840–6851 (2020) 2
work page 2020
- [17]
-
[18]
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Hunyuan3D, T., Yang, S., Yang, M., Feng, Y., Huang, X., Zhang, S., He, Z., Luo, D., Liu, H., Zhao, Y., Lin, Q., Lai, Z., Yang, X., Shi, H., Zhao, Z., Zhang, B., Yan, H., Wang, L., Liu, S., Zhang, J., Chen, M., Dong, L., Jia, Y., Cai, Y., Yu, J., Tang, Y., Guo, D., Yu, J., Zhang, H., Ye, Z., He, P., Wu, R., Wei, S., Zhang, C., Tan, Y., Sun, Y., Niu, L., Hu...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
arXiv preprint arXiv:2509.21245 (2025) 3, 4, 12, 14, 8, 11
Hunyuan3D, T., Zhang, B., Guo, C., Liu, H., Yan, H., Shi, H., Huang, J., Yu, J., Li, K., Wang, P., et al.: Hunyuan3d-omni: A unified framework for controllable generation of 3d assets. arXiv preprint arXiv:2509.21245 (2025) 3, 4, 12, 14, 8, 11
- [20]
-
[21]
In: Proceed- ings of the fourth Eurographics symposium on Geometry processing (2006) 11, 12
Kazhdan, M., Bolitho, M., Hoppe, H.: Poisson surface reconstruction. In: Proceed- ings of the fourth Eurographics symposium on Geometry processing (2006) 11, 12
work page 2006
-
[22]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Keetha, N., Müller, N., Schönberger, J., Porzi, L., Zhang, Y., Fischer, T., Knapitsch, A., Zauss, D., Weber, E., Antunes, N., Luiten, J., Lopez-Antequera, M., Bulò, S.R., Richardt, C., Ramanan, D., Scherer, S., Kontschieder, P.: Ma- pAnything: universal feed-forward metric 3D reconstruction. arXiv2509.13414 (2025) 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Labs,B.F.,Batifol,S.,Blattmann,A.,Boesel,F.,Consul,S.,Diagne,C.,Dockhorn, T., English, J., English, Z., Esser, P., Kulal, S., Lacey, K., Levi, Y., Li, C., Lorenz, D., Müller, J., Podell, D., Rombach, R., Saini, H., Sauer, A., Smith, L.: FLUX.1 kontext: Flow matching for in-context image generation and editing in latent space. arXiv2506.15742(2025) 4, 9, 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Lei, B., Li, Y., Liu, X., Yang, S., Xu, L., Huang, J., Tang, R., Weng, H., Liu, J., Xu, J., Zhou, Z., Zhu, Y., Xing, J., Xu, J., Ma, C., Yan, X., Yang, Y., Wang, C., Xu, D., Ma, X., Chen, Y., Li, J., Yang, M., Zhang, S., Feng, Y., Huang, X., Luo, 3D-ReGen: A Unified 3D Geometry Regeneration Framework 17 D., He, Z., Jiang, P., Hu, C., Qin, Z., Miao, S., Li...
-
[26]
arXiv preprint arXiv:2508.19247 , year=
Li, L., Huang, Z., Feng, H., Zhuang, G., Chen, R., Guo, C., Sheng, L.: Voxhammer: Training-free precise and coherent 3d editing in native 3d space. arXiv preprint arXiv:2508.19247 (2025) 9, 12, 13, 11
-
[28]
Li, W., Liu, J., Yan, H., Chen, R., Liang, Y., Chen, X., Tan, P., Long, X.: Crafts- man3d: High-fidelity mesh generation with 3d native generation and interactive geometry refiner (2024) 4
work page 2024
-
[29]
2025.doi:10.48550/arXiv.2405.14979
Li, W., Liu, J., Yan, H., Chen, R., Liang, Y., Chen, X., Tan, P., Long, X.: Crafts- man3d: High-fidelity mesh generation with 3d native generation and interactive geometry refiner. arXiv preprint arXiv:2405.14979 (2024) 11
-
[30]
TripoSG: High-Fidelity 3D Shape Synthesis using Large-Scale Rectified Flow Models
Li, Y., Zou, Z.X., Liu, Z., Wang, D., Liang, Y., Yu, Z., Liu, X., Guo, Y.C., Liang, D., Ouyang, W., Cao, Y.P.: TripoSG: high-fidelity 3D shape synthesis using large- scale rectified flow models. arXiv2502.06608(2025) 5, 6, 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Li, Z., Wang, Y., Zheng, H., Luo, Y., Wen, B.: Sparc3D: Sparse representation and construction for high-resolution 3d shapes modeling. arXiv2505.14521(2025) 6, 8, 10, 11
-
[33]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arXiv2511.10647(2025) 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Flow matching for generative modeling.arXiv preprint arXiv:2305.08891, 2023
Lin, S., Liu, B., Li, J., Yang, X.: Common diffusion noise schedules and sample steps are flawed. arXiv.csabs/2305.08891(2023) 1
-
[35]
Lipman, Y., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=PqvMRDCJT9t14
work page 2023
- [36]
-
[37]
In: European Conference on Computer Vision
Liu, F., Wang, H., Chen, W., Sun, H., Duan, Y.: Make-your-3d: Fast and consis- tent subject-driven 3d content generation. In: European Conference on Computer Vision. pp. 389–406. Springer (2024) 13, 11
work page 2024
-
[38]
Liu, X., Gong, C., qiang liu: Flow straight and fast: Learning to generate and trans- fer data with rectified flow. In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=XVjTT1nw5z14 18 G. Y. Park et al
work page 2023
-
[39]
ACM Computer Graphocs21(24) (1987) 4
Lorensen, W., Cline, H.: Marching cubes: A high resolution 3D surface construction algorithm. ACM Computer Graphocs21(24) (1987) 4
work page 1987
- [40]
- [41]
-
[42]
In: Proceedings of the nineteenth annual symposium on Computational geometry
Mitra, N.J., Nguyen, A.: Estimating surface normals in noisy point cloud data. In: Proceedings of the nineteenth annual symposium on Computational geometry. pp. 322–328 (2003) 9
work page 2003
-
[43]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023) 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [44]
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10684–10695 (2022) 1
work page 2022
- [46]
-
[47]
In: Proceedings of the 19th annual conference on Computer graphics and interactive techniques
Schroeder, W.J., Zarge, J.A., Lorensen, W.E.: Decimation of triangle meshes. In: Proceedings of the 19th annual conference on Computer graphics and interactive techniques. pp. 65–70 (1992) 9, 3
work page 1992
-
[48]
In: Proceedings of the IEEE/CVF international conference on computer vision
Sella, E., Fiebelman, G., Hedman, P., Averbuch-Elor, H.: Vox-e: Text-guided voxel editing of 3d objects. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 430–440 (2023) 13, 11
work page 2023
-
[49]
In: Proceedings of Advances in Neural Information Processing Systems (NeurIPS) (2024) 4, 11, 12
Siddiqui, Y., Kokkinos, F., Monnier, T., Kariya, M., Kleiman, Y., Garreau, E., Gafni, O., Neverova, N., Vedaldi, A., Shapovalov, R., Novotny, D.: Meta 3D As- set Gen: Text-to-mesh generation with high-quality geometry, texture, and PBR materials. In: Proceedings of Advances in Neural Information Processing Systems (NeurIPS) (2024) 4, 11, 12
work page 2024
-
[50]
Advances in Neural Information Processing Systems37, 9532–9564 (2024) 11
Siddiqui, Y., Monnier, T., Kokkinos, F., Kariya, M., Kleiman, Y., Garreau, E., Gafni, O., Neverova, N., Vedaldi, A., Shapovalov, R., et al.: Meta 3d assetgen: Text-to-mesh generation with high-quality geometry, texture, and pbr materials. Advances in Neural Information Processing Systems37, 9532–9564 (2024) 11
work page 2024
-
[51]
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- basedgenerativemodelingthroughstochasticdifferentialequations.In:Proc.ICLR (2021) 2
work page 2021
-
[52]
In: Proceedings of the 2004 Eurographics/ACM SIGGRAPH symposium on Geometry processing
Sorkine, O., Cohen-Or, D., Lipman, Y., Alexa, M., Rössl, C., Seidel, H.P.: Lapla- cian surface editing. In: Proceedings of the 2004 Eurographics/ACM SIGGRAPH symposium on Geometry processing. pp. 175–184 (2004) 9, 3
work page 2004
-
[53]
Tang, J., Chen, Z., Chen, X., Wang, T., Zeng, G., Liu, Z.: LGM: Large multi-view Gaussian model for high-resolution 3D content creation. arXiv2402.05054(2024) 11
-
[54]
In: Proceedings of IEEE international conference on computer vision
Taubin, G.: Curve and surface smoothing without shrinkage. In: Proceedings of IEEE international conference on computer vision. pp. 852–857. IEEE (1995) 3
work page 1995
-
[55]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023) 4 3D-ReGen: A Unified 3D Geometry Regeneration Framework 19
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
TripoAI: Tripo3D text-to-3D (2024),https://www.tripo3d.ai2, 4, 10
work page 2024
-
[57]
Wang, D., Jung, H., Monnier, T., Sohn, K., Zou, C., Xiang, X., Yeh, Y.Y., Liu, D., Huang, Z., Nguyen-Phuoc, T., Fan, Y., Oprea, S., Wang, Z., Shapovalov, R., Sarafianos, N., Groueix, T., Toisoul, A., Dhar, P., Chu, X., Chen, M., Park, G.Y., Ranjan, R., Vedaldi, A.: WorldGen: From text to traversable and interactive 3D worlds. In: Proc. CVPR (2026) 8
work page 2026
-
[58]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2025) 7, 9
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: VGGT: Visual geometry grounded transformer. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2025) 7, 9
work page 2025
-
[59]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5294–5306 (2025) 11
work page 2025
- [60]
-
[61]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Wang, Y., Zhou, J., Zhu, H., Chang, W., Zhou, Y., Li, Z., Chen, J., Pang, J., Shen, C., He, T.:π 3: Permutation-equivariant visual geometry learning. arXiv 2507.13347(2025) 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Meshlrm: Large reconstruction model for high- quality mesh
Wei, X., Zhang, K., Bi, S., Tan, H., Luan, F., Deschaintre, V., Sunkavalli, K., Su, H., Xu, Z.: Meshlrm: Large reconstruction model for high-quality meshes. arXiv preprint arXiv:2404.12385 (2024) 11, 12
-
[64]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Structured 3D Latents for Scalable and Versatile 3D Generation
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. arXiv preprint arXiv:2412.01506 (2024) 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21469–21480 (2025) 11, 12, 15
work page 2025
-
[69]
Xu, J., Cheng, W., Gao, Y., Wang, X., Gao, S., Shan, Y.: Instantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models. arXiv preprint arXiv:2404.07191 (2024) 11, 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
Advances in Neural Information Processing Systems36, 15903–15935 (2023) 11
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagere- ward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems36, 15903–15935 (2023) 11
work page 2023
-
[71]
Advances in Neural Information Processing Systems36(2024) 11
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagere- ward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems36(2024) 11
work page 2024
-
[72]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xue, L., Gao, M., Xing, C., Martín-Martín, R., Wu, J., Xiong, C., Xu, R., Niebles, J.C., Savarese, S.: Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1179–1189 (2023) 11 20 G. Y. Park et al
work page 2023
-
[73]
arXiv preprint arXiv:2506.21076 (2025) 4, 8
Yan, H., Luo, K., Li, W., Liang, Y., Li, S., Huang, J., Guo, C., Tan, P.: Posemaster: Generating 3d characters in arbitrary poses from a single image. arXiv preprint arXiv:2506.21076 (2025) 4, 8
-
[74]
Holopart: Generative 3d part amodal segmentation.arXiv preprint arXiv:2504.07943, 2025
Yang, Y., Guo, Y.C., Huang, Y., Zou, Z.X., Yu, Z., Li, Y., Cao, Y.P., Liu, X.: HoloPart: generative 3d part amodal segmentation. arXiv2504.07943(2025) 8
-
[75]
ACM Trans- actions on Graphics (TOG)43(6), 1–18 (2024) 11
Ye, C., Qiu, L., Gu, X., Zuo, Q., Wu, Y., Dong, Z., Bo, L., Xiu, Y., Han, X.: Sta- blenormal: Reducing diffusion variance for stable and sharp normal. ACM Trans- actions on Graphics (TOG)43(6), 1–18 (2024) 11
work page 2024
-
[76]
Yenphraphai, J., Mirzaei, A., Chen, J., Zou, J., Tulyakov, S., Yeh, R.A., Wonka, P., Wang, C.: Shapegen4d: Towards high quality 4d shape generation from videos. arXiv preprint (2025) 15
work page 2025
-
[77]
Yin, S., Zhang, Z., Tang, Z., Gao, K., Xu, X., Yan, K., Li, J., Chen, Y., Chen, Y., Shum, H.Y., et al.: Qwen-image-layered: Towards inherent editability via layer decomposition. arXiv preprint arXiv:2512.15603 (2025) 4
-
[78]
In: ACM Transactions on Graphics (2023) 2, 3, 5
Zhang, B., Tang, J., Niessner, M., Wonka, P.: 3DShape2VecSet: A 3D shape repre- sentation for neural fields and generative diffusion models. In: ACM Transactions on Graphics (2023) 2, 3, 5
work page 2023
-
[79]
ACM Transactions On Graphics (TOG)42(4), 1–16 (2023) 10
Zhang, B., Tang, J., Niessner, M., Wonka, P.: 3dshape2vecset: A 3d shape repre- sentation for neural fields and generative diffusion models. ACM Transactions On Graphics (TOG)42(4), 1–16 (2023) 10
work page 2023
-
[80]
Gs-lrm: Large reconstruction model for 3d gaussian splatting.ArXiv, abs/2404.19702, 2024
Zhang, K., Bi, S., Tan, H., Xiangli, Y., Zhao, N., Sunkavalli, K., Xu, Z.: GS-LRM: large reconstruction model for 3D Gaussian splatting. arXiv2404.19702(2024) 11
- [81]
- [82]
-
[83]
Zhang,Q.,Jian,X.,Zhang,X.,Wang,W.,Hou,J.:Supercarver:Texture-consistent 3d geometry super-resolution for high-fidelity surface detail generation. arXiv 2503.09439(2025) 11
-
[84]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018) 12
work page 2018
-
[86]
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Zhao, Z., Lai, Z., Lin, Q., Zhao, Y., Liu, H., Yang, S., Feng, Y., Yang, M., Zhang, S., Yang, X., et al.: Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation. arXiv preprint arXiv:2501.12202 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[87]
Zhao, Z., Liu, W., Chen, X., Zeng, X., Wang, R., Cheng, P., Fu, B., Chen, T., Yu, G., Gao, S.: Michelangelo: Conditional 3D shape generation based on shape- image-text aligned latent representation. In: Proc. NeurIPS (2023) 4 3D-ReGen: A Unified 3D Geometry Regeneration Framework 21
work page 2023
-
[88]
Zhuang, J., Kang, D., Cao, Y.P., Li, G., Lin, L., Shan, Y.: Tip-editor: An accurate 3d editor following both text-prompts and image-prompts. ACM Transactions on Graphics (TOG)43(4), 1–12 (2024) 13, 11 3D-ReGen: A Unified 3D Geometry Regeneration Framework 1 Supplementary Material of 3D-ReGen: A Unified 3D Geometry Regeneration Framework The supplementary ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.