Learning from Failure: Inference-Time Self-Improvement for Computer-Use Agents
Pith reviewed 2026-07-01 06:14 UTC · model grok-4.3
The pith
Agents improve at inference time by learning from their own failed trajectories through LLM-generated code patches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
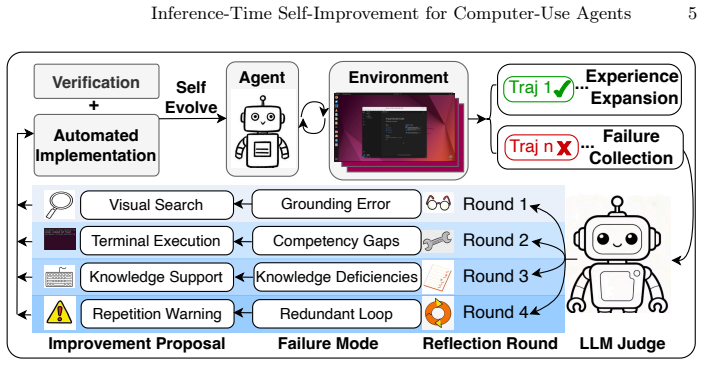
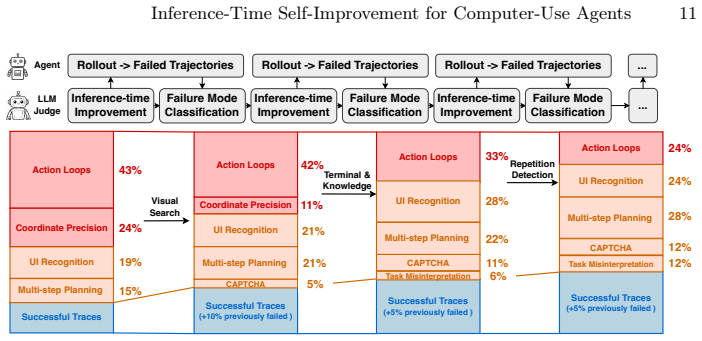
By using an LLM to diagnose failure modes from agent trajectories, propose solutions, and generate code patches that are lightly verified by humans, the success rate of the OpenCUA-72B model on the OSWorld benchmark is improved from 42.3% to 48.9%, a gain of 6.6 percentage points, without additional training cost and with only modest inference overhead.
What carries the argument
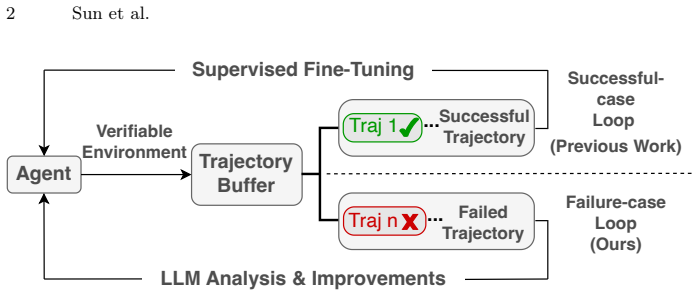
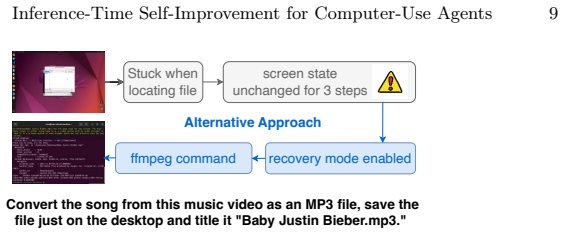
The failure-driven self-improvement loop that turns failed trajectories into inference-time code patches via LLM diagnosis.
If this is right
- Failed trajectories can be converted into effective agent upgrades at inference time.
- Performance gains occur without collecting new successful data or retraining.
- The approach requires only modest additional computation during inference.
- Light human verification ensures patch quality.
Where Pith is reading between the lines
- This method could be combined with success-based self-improvement for faster gains.
- It may apply to other multimodal agent tasks if failure diagnosis generalizes well.
Load-bearing premise
An LLM can reliably diagnose why the agent failed and create code patches that fix the issues in a general way.
What would settle it
Applying the generated patches to the agent and measuring success rate on OSWorld, which would need to show no gain or a loss to disprove the claim.
Figures




read the original abstract
Computer-use agents, which leverage multimodal large language models (MLLMs) to operate computers and complete tasks, have attracted significant attention for their utility and versatility. A major challenge in developing these agents is collecting large-scale, high-quality trajectories. The standard approach generates synthetic data through a self-improving loop: an agent is placed in a verifiable environment and iteratively fine-tuned on its successful trajectories. Despite its effectiveness, this paradigm exploits only successful trajectories and discards the failed ones, even though failures carry rich information about a model's weaknesses. In this work, we explore a complementary failure-driven self-improvement loop, a data-centric paradigm that turns failed trajectories into agent improvements. Specifically, we employ an LLM to diagnose failure modes, propose inference-time solutions, and generate code patches -- lightly verified by humans -- that upgrade the agent. We validate this approach with the state-of-the-art OpenCUA-72B model on the OSWorld benchmark, improving the success rate from 42.3% to 48.9%, a gain of 6.6 percentage points, without any additional training cost and with only modest inference overhead. Our results demonstrate that failure-driven self-improvement is a viable complement to success-based pipelines, enabling more efficient agent improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a failure-driven self-improvement paradigm for computer-use agents that uses an LLM to diagnose failure modes in trajectories, propose inference-time solutions, and generate code patches (lightly verified by humans) to upgrade the agent without additional training. It validates the approach on the OpenCUA-72B model using the OSWorld benchmark, reporting an improvement in success rate from 42.3% to 48.9%.
Significance. If the central result holds, the work demonstrates a practical complement to success-only self-improvement loops by extracting value from discarded failure trajectories at inference time, with the reported 6.6pp gain on a known benchmark and absence of training cost as concrete strengths.
major comments (2)
- [Abstract] Abstract: the reported 6.6pp gain is presented without any quantification of patches generated versus accepted, the human verification protocol (e.g., what constitutes 'light' verification), or an ablation isolating the patches from other inference-time factors such as extra LLM calls or prompt changes; this directly undermines attribution of the improvement to the failure-driven method.
- [Results] Results section (validation on OSWorld): no statistical significance, variance estimates, or controls are described for the 42.3% to 48.9% comparison, leaving open whether the gain exceeds baseline variability or depends on the specific set of inspected failures.
minor comments (1)
- [Abstract] The abstract could more explicitly state the number of trajectories or tasks involved in the failure analysis to contextualize the scale of the improvement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental attribution and statistical robustness. We address each major comment below and will revise the manuscript accordingly where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported 6.6pp gain is presented without any quantification of patches generated versus accepted, the human verification protocol (e.g., what constitutes 'light' verification), or an ablation isolating the patches from other inference-time factors such as extra LLM calls or prompt changes; this directly undermines attribution of the improvement to the failure-driven method.
Authors: We agree that the abstract omits these details, which are necessary for clear attribution. In the revision we will expand the abstract to report the number of patches generated versus accepted, provide a precise description of the light human verification protocol (including criteria for acceptance), and explicitly reference the ablation study in the results section that isolates the contribution of the generated code patches from additional LLM calls and prompt modifications. revision: yes
-
Referee: [Results] Results section (validation on OSWorld): no statistical significance, variance estimates, or controls are described for the 42.3% to 48.9% comparison, leaving open whether the gain exceeds baseline variability or depends on the specific set of inspected failures.
Authors: We acknowledge that the current results section lacks statistical analysis. We will add variance estimates (e.g., standard deviation across multiple evaluation seeds where feasible) and controls to assess whether the observed gain exceeds baseline variability. We will also clarify that the inspected failures are drawn from the full OSWorld test set rather than a curated subset. Due to the high computational cost of repeated full-benchmark runs, the added analysis will be partial but sufficient to address the concern. revision: partial
Circularity Check
No circularity; empirical benchmark result only
full rationale
The paper reports an empirical improvement (42.3% to 48.9% on OSWorld) via LLM-generated patches from failed trajectories, with light human verification. No equations, derivations, fitted parameters presented as predictions, or self-citation chains for uniqueness theorems appear in the abstract or described method. The central claim is a direct benchmark measurement, independent of any self-referential construction or renaming of known results. This matches the default expectation of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2410.08164 (2024)
Agashe, S., Han, J., Gan, S., Yang, J., Li, A., Wang, X.E.: Agent s: An open agentic framework that uses computers like a human. arXiv preprint arXiv:2410.08164 (2024)
-
[2]
Agent S2: A Compositional Generalist-Specialist Framework for Computer Use Agents
Agashe, S., Wong, K., Tu, V., Yang, J., Li, A., Wang, X.E.: Agent s2: A com- positional generalist-specialist framework for computer use agents. arXiv preprint arXiv:2504.00906 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Technical report, Anthropic (2025), https://www.anthropic.com/news/claude-3-7-sonnet, system Card
Anthropic: Claude 3.7 sonnet and claude code. Technical report, Anthropic (2025), https://www.anthropic.com/news/claude-3-7-sonnet, system Card
2025
-
[4]
Deng, X., Gu, Y., Zheng, B., Chen, S., Stevens, S., Wang, B., Sun, H., Su, Y.: Mind2web: Towards a generalist agent for the web (2023),https://arxiv.org/ abs/2306.06070
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Grounding Computer Use Agents on Human Demonstrations
Feizi, A.: Grounding computer use agents on human demonstrations. arXiv 2511.07332(Nov 2025).https://doi.org/10.48550/arXiv.2511.07332,https: //arxiv.org/abs/2511.07332, v1
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.07332 2025
-
[6]
He, H., Yao, W., Ma, K., Yu, W., Dai, Y., Zhang, H., Lan, Z., Yu, D.: Webvoyager: Building an end-to-end web agent with large multimodal models (2024),https: //arxiv.org/abs/2401.13919
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
arXiv preprint arXiv:2505.13909 (2025).https://doi.org/10.48550/arXiv.2505.13909, arXiv:2505.13909v1
He, Y.: Efficient agent training for computer use. arXiv preprint arXiv:2505.13909 (2025).https://doi.org/10.48550/arXiv.2505.13909, arXiv:2505.13909v1
-
[8]
Hu, X.: Os agents: A survey on mllm-based agents for general computing devices use. arXiv preprint arXiv:2508.04482 (2025),https://doi.org/10.48550/arXiv. 2508.04482, accepted by ACL 2025 (Oral)
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[9]
In: Che, W., Nabende, J., Shutova, E., Pilehvar,M.T.(eds.)Proceedingsofthe63rdAnnualMeetingoftheAssociationfor Computational Linguistics (Volume 1: Long Papers)
Hu, X., Xiong, T., Yi, B., Wei, Z., Xiao, R., Chen, Y., Ye, J., Tao, M., Zhou, X., Zhao, Z., Li, Y., Xu, S., Wang, S., Xu, X., Qiao, S., Wang, Z., Kuang, K., Zeng, T., Wang, L., Li, J., Jiang, Y.E., Zhou, W., Wang, G., Yin, K., Zhao, Z., Yang, H., Wu, F., Zhang, S., Wu, F.: OS agents: A survey on MLLM-based agents for computer, phone and browser use. In: ...
2025
-
[10]
arXiv (Aug 2025),https://arxiv.org/abs/2508.04037, arXiv:2508.04037 [cs.AI]
Huo, Y.: Sea: Self-evolution agent with step-wise reward for computer use. arXiv (Aug 2025),https://arxiv.org/abs/2508.04037, arXiv:2508.04037 [cs.AI]
-
[11]
Juan, X.: A survey of self-evolving agents: On path to artificial super intelligence. arXiv2507.21046(2025).https://doi.org/10.48550/arXiv.2507.21046, v3
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.21046 2025
- [12]
- [13]
-
[14]
Li, W., Bishop, W., Li, A., Rawles, C., Campbell-Ajala, F., Tyamagundlu, D., Riva, O.: On the effects of data scale on ui control agents (2024),https://arxiv. org/abs/2406.03679
-
[15]
InfiGUI-R1: Advancing Multimodal GUI Agents from Reactive Actors to Deliberative Reasoners
Liu, Y., Li, P., Xie, C., Hu, X., Han, X., Zhang, S., Yang, H., Wu, F.: Infigui-r1: Advancing multimodal gui agents from reactive actors to deliberative reasoners. arXiv preprint arXiv:2504.14239 (2025) Inference-Time Self-Improvement for Computer-Use Agents 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Technical report, OpenAI (2025), https://cdn.openai.com/pdf/2221c875- 02dc- 4789- 800b- e7758f3722c1/o3- and-o4-mini-system-card.pdf, system Card
OpenAI: Openai o3 and o4-mini system card. Technical report, OpenAI (2025), https://cdn.openai.com/pdf/2221c875- 02dc- 4789- 800b- e7758f3722c1/o3- and-o4-mini-system-card.pdf, system Card
2025
-
[18]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Qin, Y., Ye, Y., Fang, J., Wang, H., Liang, S., Tian, S., Zhang, J., Li, J., Li, Y., Huang, S., et al.: Ui-tars: Pioneering automated gui interaction with native agents. arXiv preprint arXiv:2501.12326 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Coact-1: Computer-using agents with coding as actions.arXiv preprint arXiv:2508.03923, 2025
Song, L.: Coact-1: Computer-using agents with coding as actions. arXiv 2508.03923(2025).https://doi.org/10.48550/arXiv.2508.03923, v2
-
[20]
arXiv2508(2025),https : / / arxiv
Sun, Z.: Seagent: Self-evolving computer use agent with autonomous learning from experience. arXiv2508(2025),https : / / arxiv . org / abs / 2508 . 04700, arXiv:2508.04700 [cs.AI]
- [21]
-
[22]
Wang, X., Wang, B., Lu, D., Yang, J., Xie, T., Wang, J., Deng, J., Guo, X., Xu, Y., Wu, C.H., Shen, Z., Li, Z., Li, R., Li, X., Chen, J., Zheng, B., Li, P., Lei, F., Cao, R., Fu, Y., Shin, D., Shin, M., Hu, J., Wang, Y., Chen, J., Ye, Y., Zhang, D., Du, D., Hu, H., Chen, H., Zhou, Z., Yao, H., Chen, Z., Gu, Q., Wang, Y., Wang, H., Yang, D., Zhong, V., Sun...
-
[23]
In: The 34th Annual ACM Symposium on User Interface Software and Technology
Wu, J., Zhang, X., Nichols, J., Bigham, J.P.: Screen parsing: Towards reverse engineering of ui models from screenshots. In: The 34th Annual ACM Symposium on User Interface Software and Technology. p. 470–483. UIST ’21, ACM (Oct 2021).https://doi.org/10.1145/3472749.3474763,http://dx.doi.org/10. 1145/3472749.3474763
-
[24]
Wu, Z.: See, think, act: Teaching multimodal agents to effectively interact with gui by identifying toggles (09 2025).https://doi.org/10.48550/arXiv.2509.13615, https://arxiv.org/abs/2509.13615
-
[25]
arXiv preprint arXiv:2505.13227 (2025)
Xie, T., Deng, J., Li, X., Yang, J., Wu, H., Chen, J., Hu, W., Wang, X., Xu, Y., Wang, Z., et al.: Scaling computer-use grounding via user interface decomposition and synthesis. arXiv preprint arXiv:2505.13227 (2025)
-
[26]
Advances in Neural Information Processing Systems37, 52040–52094 (2024)
Xie, T., Zhang, D., Chen, J., Li, X., Zhao, S., Cao, R., Hua, T.J., Cheng, Z., Shin, D., Lei, F., et al.: Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. Advances in Neural Information Processing Systems37, 52040–52094 (2024)
2024
-
[27]
Xie, T., Zhang, D., Chen, J., Li, X., Zhao, S., Cao, R., Hua, T.J., Cheng, Z., Shin, D., Lei, F., Liu, Y., Xu, Y., Zhou, S., Savarese, S., Xiong, C., Zhong, V., Yu, T.: Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments (2024),https://arxiv.org/abs/2404.07972
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction
Xu, Y., Wang, Z., Wang, J., Lu, D., Xie, T., Saha, A., Sahoo, D., Yu, T., Xiong, C.: Aguvis: Unified pure vision agents for autonomous gui interaction. arXiv preprint arXiv:2412.04454 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Aria-ui: Visual grounding for gui instruc- tions.arXiv preprint arXiv:2412.16256, 2024
Yang, Y., Wang, Y., Li, D., Luo, Z., Chen, B., Huang, C., Li, J.: Aria-ui: Visual grounding for gui instructions. arXiv preprint arXiv:2412.16256 (2024) 18 Sun et al
-
[30]
A Survey on Agentic Multimodal Large Language Models,
Yao,H.:Asurveyonagenticmultimodallargelanguagemodels.arXiv2510.10991 (Oct 2025).https://doi.org/10.48550/arXiv.2510.10991,https://arxiv. org/abs/2510.10991
-
[31]
Ye, J., Zhang, X., Xu, H., Liu, H., Wang, J., Zhu, Z., Zheng, Z., Gao, F., Cao, J., Lu, Z., Liao, J., Zheng, Q., Huang, F., Zhou, J., Yan, M.: Mobile-agent-v3: Fundamental agents for gui automation (2025),https://arxiv.org/abs/2508. 15144
2025
-
[32]
arXiv2510.19949(2025).https : / / doi
Yuan, K.: Surfer 2: The next generation of cross-platform computer use agents. arXiv2510.19949(2025).https : / / doi . org / 10 . 48550 / arXiv . 2510 . 19949, https://arxiv.org/abs/2510.19949, v2
-
[34]
Large Language Model-Brained GUI Agents: A Survey
Zhang, C.: Large language model-brained gui agents: A survey. arXiv preprint arXiv:2411.18279 (May 2025).https://doi.org/10.48550/arXiv.2411.18279, https://arxiv.org/abs/2411.18279
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.18279 2025
-
[35]
Zheng, B., Gou, B., Kil, J., Sun, H., Su, Y.: Gpt-4v(ision) is a generalist web agent, if grounded (2024),https://arxiv.org/abs/2401.01614
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
arXiv (May 2025).https://doi.org/10.48550/arXiv.2505
Zhou, A.: Ui-genie: A self-improving approach for iteratively boosting mllm-based mobile gui agents. arXiv (May 2025).https://doi.org/10.48550/arXiv.2505. 21496,https://arxiv.org/abs/2505.21496, version 1
-
[37]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Zhou, S., Xu, F.F., Zhu, H., Zhou, X., Lo, R., Sridhar, A., Cheng, X., Ou, T., Bisk, Y., Fried, D., Alon, U., Neubig, G.: Webarena: A realistic web environment for building autonomous agents (2024),https://arxiv.org/abs/2307.13854 Supplementary Materials for Learning from Failure: Inference-Time Self-Improvement for Computer-Use Agents Xueqiao Sun1,2, Xia...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
**Analyze the Goal:** First, state what the user wants to accomplish in this final step
-
[39]
What is its function?
**Analyze the Visuals:** Identify the UI element located inside the red circle. What is its function?
-
[40]
**Consider History:** Review your previous actions to understand the task progression and ensure this action aligns with the overall goal
-
[41]
ctrl", "alt
**Synthesize and Decide:** Based on the goal, visual evidence, and action history, was this the correct element to click? If not, what element *should* have been clicked, and where is it? ## Action Space con firm_coordinates() # Confirm that the coordinates are correct adjust_coordinates(coordinate=[x, y]) # Provide corrected coordinates if needed ## Note -...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.