ADR: An Agentic Detection System for Enterprise Agentic AI Security
Pith reviewed 2026-05-20 13:14 UTC · model grok-4.3
The pith
ADR detects attacks on enterprise AI agents by capturing reasoning and causal chains that standard tools miss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ADR combines high-fidelity agentic telemetry from the Sensor with systematic pre-deployment red teaming in the Explorer and scalable two-tier detection in the Detector to address observability gaps, lack of robustness, and high inference costs, delivering reliable security for MCP-based AI agents as shown by sustained production use and benchmark results.
What carries the argument
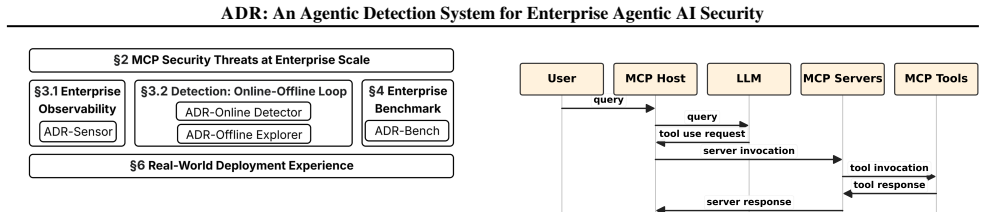
The ADR Sensor, which records high-fidelity agentic telemetry consisting of prompts, reasoning steps, and causal chains that connect agent intent to execution actions.
If this is right
- Enterprises gain the ability to add a shift-left prevention layer that catches issues before deployment with measured precision.
- Detection generalizes across attack techniques and enterprise contexts instead of relying on pre-defined static rules.
- Large-scale operation becomes feasible because the two-tier detector avoids running expensive inference on every session.
- Hundreds of credential exposures across multiple categories can be uncovered in live environments.
- A new benchmark set enables consistent comparison of agent security methods beyond the three baselines tested.
Where Pith is reading between the lines
- The same telemetry-plus-red-teaming pattern could apply to agent systems that use protocols other than MCP.
- ADR-Bench could become a standard test suite for measuring how well security tools generalize to new agent behaviors.
- Early integration of such detection during agent development might reduce the volume of issues that reach production.
- The production metrics suggest that observability improvements can drive measurable reductions in credential-related risks at company scale.
Load-bearing premise
The telemetry gathered by the Sensor contains enough detail on agent reasoning and intent-to-action links for the Explorer and Detector to identify attacks across different techniques without missing key connections.
What would settle it
An attack that reaches execution on a deployed AI agent while producing no detectable signal in the recorded prompts, reasoning steps, or causal chains, resulting in a missed detection by the ADR system.
Figures







read the original abstract
We present the Agentic AI Detection and Response (ADR) system, the first large-scale, production-proven enterprise framework for securing AI agents operating through the Model Context Protocol (MCP). We identify three persistent challenges in this domain: (1) limited observability -- existing Endpoint Detection and Response (EDR) tools see file writes but not the agent reasoning, prompts, or causal chains linking intent to execution; (2) insufficient robustness -- static defenses constrained by pre-defined rules fail to generalize across diverse attack techniques and enterprise contexts; and (3) high detection costs -- LLM-based inference is prohibitively expensive at scale. ADR addresses these challenges via three components: the ADR Sensor for high-fidelity agentic telemetry, the ADR Explorer for systematic pre-deployment red teaming and hard-example generation, and the ADR Detector for scalable, two-tier online detection combining fast triage with context-aware reasoning. Deployed at Uber for over ten months, ADR has sustained reliable detection in production with growing adoption reaching over 7,200 unique hosts and processing over 10,000 agent sessions daily, uncovering hundreds of credential exposures across 26 categories and enabling a shift-left prevention layer (97.2% precision, 206 detected credentials). To validate the approach and enable community adoption, we introduce ADR-Bench (302 tasks, 17 techniques, 133 MCP servers), where ADR achieves zero false positives while detecting 67% of attacks -- outperforming three state-of-the-art baselines (ALRPHFS, GuardAgent, LlamaFirewall) by 2--4x in F1-score. On AgentDojo (public prompt injection benchmark), ADR detects all attacks with only three false alarms out of 93 tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the Agentic AI Detection and Response (ADR) system as the first large-scale production-proven framework for securing AI agents via the Model Context Protocol (MCP). It identifies challenges in observability, robustness, and detection cost, addressed through three components: the ADR Sensor for high-fidelity agentic telemetry, the ADR Explorer for red teaming and hard-example generation, and the ADR Detector for two-tier scalable detection. The central claims include a ten-month deployment at Uber reaching 7,200 hosts and 10,000 daily sessions, detection of hundreds of credential exposures across 26 categories with 97.2% precision (206 credentials), and introduction of the ADR-Bench benchmark (302 tasks, 17 techniques, 133 MCP servers) where ADR achieves zero false positives and 67% attack detection, outperforming baselines by 2-4x in F1-score; it also reports perfect detection on AgentDojo with only three false alarms.
Significance. If the production and benchmark results hold after methodological clarification, this would represent a significant contribution as the first detailed enterprise-scale system for agentic AI security, directly addressing EDR limitations in observing reasoning and causal chains. The release of ADR-Bench and the reported real-world metrics (including shift-left prevention) provide concrete, deployable advances that could influence both research and industry practices in AI agent safety.
major comments (3)
- Production Evaluation section: the headline claims of 97.2% precision, 206 detected credentials, and reliable detection over ten months with 7,200 hosts and 10,000 daily sessions rest on undisclosed ground-truth labeling, sampling strategy, and false-negative estimation methods in the live Uber environment; without these details the metrics cannot be independently assessed as reflecting the Sensor-Explorer-Detector pipeline rather than Uber-specific logging or post-hoc filtering.
- ADR-Bench Evaluation: the 302-task benchmark reports zero false positives and 67% detection (outperforming ALRPHFS, GuardAgent, LlamaFirewall by 2-4x F1), yet provides no description of task construction, labeling process, or controls for selection effects, leaving the generalization claims across 17 techniques and 133 MCP servers only partially supported.
- System Design, ADR Sensor subsection: the assumption that the Sensor captures sufficient high-fidelity telemetry (prompts, reasoning, causal chains) to enable downstream generalization is load-bearing for the robustness claim but is not validated by ablation studies or explicit evidence that missing intent-to-execution links do not cause critical detection failures.
minor comments (2)
- The abstract and evaluation sections should explicitly state whether the zero false positives on ADR-Bench and the three false alarms on AgentDojo refer to held-out test data or include training-set results.
- Figure and table captions in the evaluation sections could be expanded to include exact definitions of precision, F1, and how false positives were measured in both production and benchmark settings.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The comments identify key areas where additional methodological transparency would strengthen the manuscript. We address each major comment below and indicate the revisions planned for the next version.
read point-by-point responses
-
Referee: Production Evaluation section: the headline claims of 97.2% precision, 206 detected credentials, and reliable detection over ten months with 7,200 hosts and 10,000 daily sessions rest on undisclosed ground-truth labeling, sampling strategy, and false-negative estimation methods in the live Uber environment; without these details the metrics cannot be independently assessed as reflecting the Sensor-Explorer-Detector pipeline rather than Uber-specific logging or post-hoc filtering.
Authors: We agree that further detail on the production evaluation methodology is warranted. In the revised manuscript we will expand the Production Evaluation section with a description of the ground-truth process (automated pattern matching followed by security-analyst review), the representative sampling approach across sessions, and the periodic red-teaming protocol used to bound false-negative rates. Certain enterprise-specific implementation thresholds will remain summarized for confidentiality reasons, but the core labeling and estimation procedures will be made explicit so readers can assess the contribution of the ADR pipeline. revision: yes
-
Referee: ADR-Bench Evaluation: the 302-task benchmark reports zero false positives and 67% detection (outperforming ALRPHFS, GuardAgent, LlamaFirewall by 2-4x F1), yet provides no description of task construction, labeling process, or controls for selection effects, leaving the generalization claims across 17 techniques and 133 MCP servers only partially supported.
Authors: We accept that the benchmark construction details require elaboration. The revised version will add a dedicated subsection describing how the 302 tasks were assembled from real MCP interactions and synthetic attacks spanning the 17 techniques, the expert labeling protocol employed, and the diversity-sampling controls used to ensure coverage across the 133 MCP servers. These additions will directly support the generalization claims. revision: yes
-
Referee: System Design, ADR Sensor subsection: the assumption that the Sensor captures sufficient high-fidelity telemetry (prompts, reasoning, causal chains) to enable downstream generalization is load-bearing for the robustness claim but is not validated by ablation studies or explicit evidence that missing intent-to-execution links do not cause critical detection failures.
Authors: The Sensor is engineered to record prompts, reasoning traces, and execution events through the MCP interface. While the original submission did not include dedicated ablations, we will add an ablation study in the revised manuscript quantifying detection performance as a function of telemetry completeness. The two-tier Detector and Explorer components are explicitly designed to compensate for any residual gaps; production results over ten months showed no critical failures traceable to missing causal links. We will clarify this mitigation strategy in the System Design section. revision: partial
- Certain quantitative parameters of the live Uber false-negative estimation protocol cannot be disclosed in full detail without revealing proprietary operational security practices.
Circularity Check
No circularity: empirical system performance and benchmark results do not reduce to self-defined inputs or fitted parameters
full rationale
The paper introduces the ADR system with Sensor, Explorer, and Detector components to address observability, robustness, and cost challenges in securing AI agents. It reports production metrics from a ten-month Uber deployment (7,200 hosts, 10k daily sessions, 97.2% precision, 206 credentials) and benchmark results on ADR-Bench (zero false positives, 67% attack detection) and AgentDojo (all attacks detected with three false alarms). These are presented as direct empirical outcomes from deployment logs and task evaluations, not as predictions derived from internal equations, parameter fits renamed as forecasts, or self-citation chains. No load-bearing steps in the abstract or description equate outputs to inputs by construction, such as defining a metric in terms of itself or smuggling an ansatz via prior self-work. The derivation chain is self-contained against external benchmarks and real-world logs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The Model Context Protocol exposes agent reasoning, prompts, and causal chains at a level sufficient for high-fidelity detection.
- domain assumption Systematic pre-deployment red teaming with 17 techniques generates representative hard examples that generalize to production attacks.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-tier online detection pipeline with Tier 1 triage ... Tier 2 analysis performing deep contextual reasoning
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
evolutionary algorithm ... fitness function F=ε×σ×τ^α
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Agent-SafetyBench: Evaluating the Safety of LLM Agents
Agent-safetybench: Evaluating the safety of llm agents , author=. arXiv preprint arXiv:2412.14470 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [2]
-
[3]
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
Identifying the risks of lm agents with an lm-emulated sandbox , author=. arXiv preprint arXiv:2309.15817 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Advances in Neural Information Processing Systems , volume=
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents
Agent security bench (asb): Formalizing and benchmarking attacks and defenses in llm-based agents , author=. arXiv preprint arXiv:2410.02644 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Simplified and Secure MCP Gateways for Enterprise AI Integration , author=. 2025 , eprint=
work page 2025
-
[7]
Beyond the Protocol: Unveiling Attack Vectors in the Model Context Protocol Ecosystem , author=. arXiv preprint arXiv:2506.02040 , year=
-
[8]
arXiv preprint arXiv:2506.15253 , year=
RAS-Eval: A Comprehensive Benchmark for Security Evaluation of LLM Agents in Real-World Environments , author=. arXiv preprint arXiv:2506.15253 , year=
-
[9]
MCP Guardian: A Security-First Layer for Safeguarding MCP-Based AI System , author=. 2025 , eprint=
work page 2025
-
[10]
MCP Safety Audit: LLMs with the Model Context Protocol Allow Major Security Exploits , author=. 2025 , eprint=
work page 2025
-
[11]
Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions , author=. 2025 , eprint=
work page 2025
-
[12]
ACM Computing Surveys , volume=
MITRE ATT&CK: State of the art and way forward , author=. ACM Computing Surveys , volume=. 2024 , publisher=
work page 2024
-
[13]
2025 , howpublished =
work page 2025
-
[14]
AgentFlayer: When a Jira Ticket Can Steal Your Secrets , author =. 2025 , howpublished =
work page 2025
-
[15]
GitHub MCP Exploited: Accessing private repositories via MCP , author =. 2025 , howpublished =
work page 2025
-
[16]
WhatsApp MCP Exploited: Exfiltrating your message history via MCP , author =. 2025 , howpublished =
work page 2025
-
[17]
Invariant Labs Exposes Novel Prompt Injection Attack Vulnerabilities, ``Toxic Flows,'' in Agentic Systems & MCP Servers , author =. 2025 , howpublished =
work page 2025
-
[18]
Why a Classic MCP Server Vulnerability Can Undermine Your Entire AI Agent , author =. 2025 , howpublished =
work page 2025
-
[19]
Critical RCE Vulnerability in mcp-remote: CVE-2025-6514 Threatens LLM Clients , author =. 2025 , howpublished =
work page 2025
-
[20]
MCP Security Notification: Tool Poisoning Attacks , author =. 2025 , howpublished =
work page 2025
-
[21]
The Security Risks of Model Context Protocol (MCP) , author =. 2025 , howpublished =
work page 2025
-
[22]
Deep Dive MCP and A2A Attack Vectors for AI Agents , author =. 2025 , howpublished =
work page 2025
-
[23]
Is your AI safe? Threat analysis of MCP (Model Context Protocol) , author =. 2025 , howpublished =
work page 2025
- [24]
-
[25]
Plug, Play, and Prey: The security risks of the Model Context Protocol , author =. 2025 , howpublished =
work page 2025
-
[26]
OWASP LLM Risk 06:2025 -- Excessive Agency , author =. 2025 , howpublished =
work page 2025
-
[27]
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training , author=. arXiv preprint arXiv:2401.05566 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents , author=. arXiv preprint arXiv:2410.09024 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
MCP-Guard: A Defense Framework for Model Context Protocol Integrity in Large Language Model Applications , author=. arXiv preprint arXiv:2508.10991 , year=
-
[30]
arXiv preprint arXiv:2505.03574 , year=
Llamafirewall: An open source guardrail system for building secure ai agents , author=. arXiv preprint arXiv:2505.03574 , year=
-
[31]
GuardAgent: Safeguard LLM Agents by a Guard Agent via Knowledge-Enabled Reasoning
Guardagent: Safeguard llm agents by a guard agent via knowledge-enabled reasoning , author=. arXiv preprint arXiv:2406.09187 , year=
work page internal anchor Pith review arXiv
-
[32]
arXiv preprint arXiv:2502.11448 , year=
Agrail: A lifelong agent guardrail with effective and adaptive safety detection , author=. arXiv preprint arXiv:2502.11448 , year=
-
[33]
arXiv preprint arXiv:2503.22738 , year=
Shieldagent: Shielding agents via verifiable safety policy reasoning , author=. arXiv preprint arXiv:2503.22738 , year=
-
[34]
arXiv preprint arXiv:2505.19260 , year=
ALRPHFS: Adversarially Learned Risk Patterns with Hierarchical Fast & Slow Reasoning for Robust Agent Defense , author=. arXiv preprint arXiv:2505.19260 , year=
-
[35]
arXiv preprint arXiv:2407.16667 , year=
Redagent: Red teaming large language models with context-aware autonomous language agent , author=. arXiv preprint arXiv:2407.16667 , year=
-
[36]
Advances in Neural Information Processing Systems , volume=
Ali-agent: Assessing llms' alignment with human values via agent-based evaluation , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
Advances in Neural Information Processing Systems , volume=
Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
Autodan-turbo: A lifelong agent for strategy self-exploration to jailbreak llms , author=. arXiv preprint arXiv:2410.05295 , year=
-
[39]
arXiv preprint arXiv:2503.15754 , year=
Autoredteamer: Autonomous red teaming with lifelong attack integration , author=. arXiv preprint arXiv:2503.15754 , year=
-
[40]
Jailbreaking ChatGPT via Prompt Engineering: An Empirical Study
Jailbreaking chatgpt via prompt engineering: An empirical study , author=. arXiv preprint arXiv:2305.13860 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Open sesame! universal black-box jailbreaking of large language models , author=. Applied Sciences , volume=. 2024 , publisher=
work page 2024
-
[42]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Advances in Neural Information Processing Systems , volume=
When llm meets drl: Advancing jailbreaking efficiency via drl-guided search , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
N e M o Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails
Rebedea, Traian and Dinu, Razvan and Sreedhar, Makesh Narsimhan and Parisien, Christopher and Cohen, Jonathan. N e M o Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2023. doi:10.18653/v1/2023.emnlp-demo.40
- [45]
- [46]
- [47]
-
[48]
Constitutional AI: Harmlessness from AI Feedback
Constitutional ai: Harmlessness from ai feedback , author=. arXiv preprint arXiv:2212.08073 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Securing AI Agents with Information-Flow Control
Securing AI Agents with Information-Flow Control , author=. arXiv preprint arXiv:2505.23643 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [50]
- [51]
- [52]
- [53]
-
[54]
Model Context Protocol Repositories , author =. 2025 , howpublished =
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.