How Well Does GPT-4o Understand Vision? Evaluating Multimodal Foundation Models on Standard Computer Vision Tasks
Pith reviewed 2026-05-19 05:51 UTC · model grok-4.3
The pith
Multimodal foundation models like GPT-4o serve as respectable generalists on standard computer vision tasks but lag behind specialist models and perform semantic tasks better than geometric ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The MFMs are not close to the state-of-the-art specialist models at any task yet remain respectable generalists, performing semantic tasks notably better than geometric ones, with GPT-4o topping non-reasoning models in 4 out of 6 tasks. Reasoning models show improvements in geometric tasks. While prompt chaining affects performance, better models are less sensitive to variations. Models with native image generation exhibit failure modes such as hallucinated objects or misalignment between input and output.
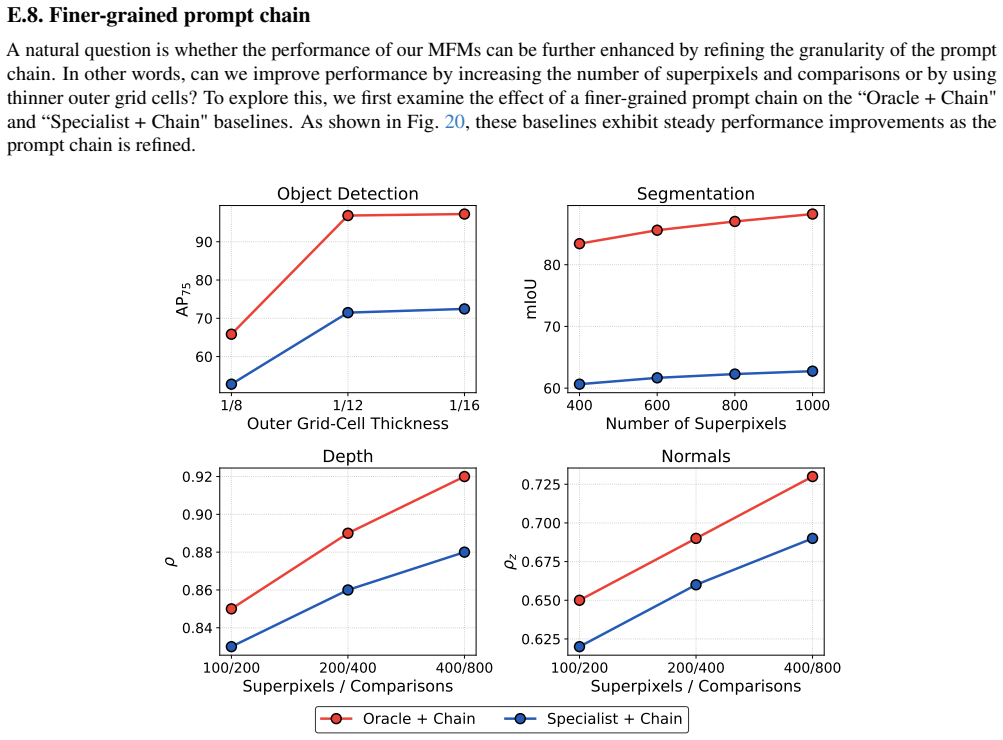
What carries the argument
Prompt chaining technique that translates vision tasks into text-promptable formats for API access, enabling standardized evaluation of proprietary multimodal models on segmentation, detection, and 3D geometry tasks.
If this is right
- MFMs remain useful as general-purpose vision tools despite not matching specialist accuracy.
- Semantic capabilities in MFMs exceed their geometric and spatial reasoning abilities.
- Adding reasoning capabilities improves performance on geometric vision tasks.
- Stronger base models show reduced sensitivity to prompt variations in these tasks.
- Image generation features in MFMs introduce specific failure modes like object hallucination and input-output misalignment.
Where Pith is reading between the lines
- Training data for future multimodal models should incorporate more explicit geometric supervision to close the performance gap.
- Hybrid systems could combine generalist MFMs for broad analysis with specialists for high-precision geometric outputs.
- The observed semantic advantage suggests that current pretraining objectives favor categorical understanding over precise 3D structure.
- Further benchmarks on additional datasets would test if the semantic-geometric disparity holds broadly.
Load-bearing premise
Converting vision tasks into text-promptable formats via prompt chaining produces measurements that faithfully reflect the models' underlying visual understanding rather than artifacts from the text interface or prompt sensitivity.
What would settle it
Re-evaluating the tasks with models that output native vision formats such as masks or depth maps directly, or observing that optimized prompting allows MFMs to match specialist performance on any task.
Figures

























read the original abstract
Multimodal foundation models (MFMs), such as GPT-4o, have recently made remarkable progress. However, their detailed visual understanding beyond question answering remains unclear. In this paper, we benchmark popular MFMs (GPT-4o, o4-mini, Gemini 1.5 Pro and Gemini 2.0 Flash, Claude 3.5 Sonnet, Qwen2-VL, Llama 3.2) on standard computer vision tasks (semantic segmentation, object detection, image classification, depth and surface normal prediction) using established datasets (e.g., COCO, ImageNet, etc). The main challenges in performing this analysis are: 1) most models are trained to output text and cannot natively express versatile domains, such as segments or 3D geometry, and 2) many leading models are proprietary and accessible only at an API level, i.e., there is no weight access to adapt them. We address these by translating vision tasks into text-promptable, API-compatible formats via prompt chaining, creating a standardized benchmarking framework. We observe that: 1) The MFMs are not close to the state-of-the-art specialist models at any task. 2) They are respectable generalists; this is remarkable, as they are presumably trained on image-text-based tasks. 3) They perform semantic tasks notably better than geometric ones. 4) GPT-4o performs the best among non-reasoning models, securing the top position in 4 out of 6 tasks. 5) Reasoning models, e.g., o3, show improvements in geometric tasks. 6) While prompt chaining techniques affect performance, better models are less sensitive to prompt variations. 7) An analysis of models with native image generation, such as the latest GPT-4o, shows they exhibit failure modes, such as hallucinated objects or misalignment between input and output.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper benchmarks multimodal foundation models (GPT-4o, o4-mini, Gemini 1.5 Pro, Gemini 2.0 Flash, Claude 3.5 Sonnet, Qwen2-VL, Llama 3.2) on standard CV tasks—semantic segmentation, object detection, image classification, depth estimation, and surface normal prediction—using public datasets such as COCO and ImageNet. Because these models output only text and lack weight access, the authors introduce a prompt-chaining framework that converts each task into a sequence of text prompts. They report that MFMs lag far behind specialist SOTA models on every task, yet function as respectable generalists; semantic tasks are solved markedly better than geometric ones; GPT-4o leads among non-reasoning models; reasoning models improve geometric performance; and better models are less sensitive to prompt wording.
Significance. If the prompt-based measurements are shown to isolate visual understanding rather than linguistic facility, the work supplies a much-needed standardized, API-compatible evaluation protocol for tracking MFM progress on dense vision tasks. The semantic-versus-geometric performance gap and the prompt-sensitivity analysis are useful signals for the community. The explicit comparison against specialist baselines and the inclusion of native image-generation failure modes add concrete value.
major comments (2)
- [§3] §3 (Prompt Chaining Framework), geometric-task subsection: converting depth and surface-normal prediction into text or JSON outputs necessarily discretizes continuous geometry and allows language-model priors to substitute for pixel-level inference. The observed semantic-geometric gap could therefore reflect relative difficulty of verbalizing geometry rather than differences in visual extraction; an oracle-text ablation (providing ground-truth descriptions and measuring only the downstream reasoning step) is required to support the central claim.
- [§4] §4 (Experimental Results), Tables 2–4 and associated text: headline rankings (GPT-4o topping four of six tasks) and the “respectable generalist” conclusion rest on single-prompt scores without reported variance across prompt templates or output formats. Because the paper itself notes prompt sensitivity, the absence of these controls makes the quantitative comparisons load-bearing yet fragile.
minor comments (2)
- [Abstract / §2] Clarify the exact model list and version numbers (o4-mini vs. o3) between abstract and §2; inconsistent naming appears in the provided text.
- [§4] Add error bars or multiple-run statistics to all quantitative tables to reflect acknowledged prompt variability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing our honest assessment and indicating the revisions we will incorporate.
read point-by-point responses
-
Referee: [§3] §3 (Prompt Chaining Framework), geometric-task subsection: converting depth and surface-normal prediction into text or JSON outputs necessarily discretizes continuous geometry and allows language-model priors to substitute for pixel-level inference. The observed semantic-geometric gap could therefore reflect relative difficulty of verbalizing geometry rather than differences in visual extraction; an oracle-text ablation (providing ground-truth descriptions and measuring only the downstream reasoning step) is required to support the central claim.
Authors: We thank the referee for this insightful observation. We agree that text-based outputs for geometric tasks inherently involve discretization and that language-model priors could influence results. Our framework evaluates the end-to-end ability of MFMs to extract and articulate visual information via prompts, and the semantic-geometric gap appears consistently across models, suggesting it captures real differences in visual processing rather than purely verbalization challenges. Nevertheless, to more rigorously isolate visual extraction from downstream reasoning, we will add an oracle-text ablation in the revised manuscript: we will provide ground-truth textual scene descriptions and separately measure model performance on the reasoning step for geometric tasks. revision: yes
-
Referee: [§4] §4 (Experimental Results), Tables 2–4 and associated text: headline rankings (GPT-4o topping four of six tasks) and the “respectable generalist” conclusion rest on single-prompt scores without reported variance across prompt templates or output formats. Because the paper itself notes prompt sensitivity, the absence of these controls makes the quantitative comparisons load-bearing yet fragile.
Authors: We acknowledge the validity of this concern. Although the manuscript discusses prompt sensitivity and states that stronger models are less affected by variations, we did not report quantitative variance (e.g., standard deviations or ranges) across multiple prompt templates and output formats in Tables 2–4. This does render the specific headline rankings somewhat dependent on the chosen prompts. We will revise the experimental results section to include multi-prompt evaluations, reporting means and variances for the primary metrics to make the quantitative comparisons and the “respectable generalist” conclusion more robust. revision: yes
Circularity Check
No circularity: results are direct empirical measurements on external public datasets
full rationale
The paper presents an empirical benchmarking study that translates standard CV tasks into text-promptable formats and reports measured performance scores for MFMs against established datasets (COCO, ImageNet, etc.). No equations, fitted parameters, or derived quantities are defined in terms of the target results. Central observations (MFMs not close to SOTA, semantic vs. geometric gap, GPT-4o ranking) are outcomes of running the evaluation framework rather than quantities that reduce to the framework inputs by construction. No load-bearing self-citations or uniqueness theorems from prior author work are invoked to justify the claims. The analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prompt chaining can translate pixel-level vision tasks into text outputs that preserve task semantics for API-only models.
Forward citations
Cited by 1 Pith paper
-
Symbolic Grounding Reveals Representational Bottlenecks in Abstract Visual Reasoning
LLMs given symbolic image descriptions reach mid-90s accuracy on abstract visual reasoning tasks where end-to-end VLMs stay near chance, showing representation as the primary bottleneck.
Reference graph
Works this paper leans on
-
[1]
Slic superpixels compared to state-of-the-art superpixel methods
Radhakrishna Achanta, Appu Shaji, Kevin Smith, Aurelien Lucchi, Pascal Fua, and Sabine Süsstrunk. Slic superpixels compared to state-of-the-art superpixel methods. IEEE trans- actions on pattern analysis and machine intelligence, 34(11): 2274–2282, 2012. 3
work page 2012
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko 9 Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [3]
-
[4]
Unibench: Visual reasoning requires rethinking vision- language beyond scaling
Haider Al-Tahan, Quentin Garrido, Randall Balestriero, Diane Bouchacourt, Caner Hazirbas, and Mark Ibrahim. Unibench: Visual reasoning requires rethinking vision- language beyond scaling. arXiv preprint arXiv:2408.04810,
-
[5]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing Systems , 35:23716–23736,
-
[6]
Anthropic. Introducing claude 3.5 sonnet. https : / / www . anthropic . com / news / claude - 3 - 5 - sonnet, 2024. Accessed: 2024-09-23. 1, 2, 4
work page 2024
-
[7]
4m-21: An any-to-any vision model for tens of tasks and modalities
Roman Bachmann, O˘guzhan Fatih Kar, David Mizrahi, Ali Garjani, Mingfei Gao, David Griffiths, Jiaming Hu, Afshin Dehghan, and Amir Zamir. 4m-21: An any-to-any vision model for tens of tasks and modalities. arXiv preprint arXiv:2406.09406, 2024. 6, 7, 36, 37
-
[8]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xi- aodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report. arXiv preprint arXiv:2309.16609 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexan- der Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer. arXiv preprint arXiv:2407.07726, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Omni3d: A large benchmark and model for 3d object detection in the wild
Garrick Brazil, Abhinav Kumar, Julian Straub, Nikhila Ravi, Justin Johnson, and Georgia Gkioxari. Omni3d: A large benchmark and model for 3d object detection in the wild. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13154–13164, 2023. 2
work page 2023
-
[11]
End-to- end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to- end object detection with transformers. In Computer Vision– ECCV 2020: 16th European Conference, Glasgow, UK, Au- gust 23–28, 2020, Proceedings, Part I 16 , pages 213–229. Springer, 2020. 6, 7
work page 2020
-
[12]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Hen- rique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evalu- ating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021. 2
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
An empirical study of gpt-4o image generation capabilities
Sixiang Chen, Jinbin Bai, Zhuoran Zhao, Tian Ye, Qingyu Shi, Donghao Zhou, Wenhao Chai, Xin Lin, Jianzong Wu, Chao Tang, et al. An empirical study of gpt-4o image generation capabilities. arXiv preprint arXiv:2504.05979, 2025. 8
-
[14]
Self-icl: Zero-shot in-context learning with self- generated demonstrations, 2023
Wei-Lin Chen, Cheng-Kuang Wu, Yun-Nung Chen, and Hsin- Hsi Chen. Self-icl: Zero-shot in-context learning with self- generated demonstrations, 2023. 28
work page 2023
-
[15]
Reproducible scal- ing laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuh- mann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scal- ing laws for contrastive language-image learning. In Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2818–2829, 2023. 6
work page 2023
-
[16]
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anasta- sios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E Gonzalez, et al. Chatbot arena: An open platform for evaluating llms by human preference. arXiv preprint arXiv:2403.04132, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Robustbench: a standardized adversarial robustness benchmark.arXiv preprint arXiv:2010.09670,
Francesco Croce, Maksym Andriushchenko, Vikash Sehwag, Edoardo Debenedetti, Nicolas Flammarion, Mung Chiang, Prateek Mittal, and Matthias Hein. Robustbench: a stan- dardized adversarial robustness benchmark. arXiv preprint arXiv:2010.09670, 2020. 5
-
[18]
InstructBLIP: Towards general-purpose vision-language models with instruction tuning
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. InstructBLIP: Towards general-purpose vision-language models with instruction tuning. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. 2
work page 2023
-
[19]
Omnidata: A scalable pipeline for making multi-task mid-level vision datasets from 3d scans
Ainaz Eftekhar, Alexander Sax, Roman Bachmann, Jiten- dra Malik, and Amir Roshan Zamir. Omnidata: A scalable pipeline for making multi-task mid-level vision datasets from 3d scans. 2021 IEEE/CVF International Conference on Com- puter Vision (ICCV), pages 10766–10776, 2021. 7, 38
work page 2021
-
[20]
Flickr. Find your inspiration. https://www.flickr. com/, 2024. Accessed: 2024-09-23. 9, 28, 36, 37, 38
work page 2024
-
[21]
BLINK: Multimodal Large Language Models Can See but Not Perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. arXiv preprint arXiv:2404.12390,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Explore vision capabilities with the gemini api
Google. Explore vision capabilities with the gemini api. https://ai.google.dev/gemini- api/docs/ vision?lang=python , 2024. Accessed: 2024-09-23. 22
work page 2024
-
[23]
Google DeepMind. Gemini 2.0 flash. https : / / deepmind . google / technologies / gemini / flash/, 2024. 4
work page 2024
-
[24]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
Dan Hendrycks and Thomas Dietterich. Benchmarking neural network robustness to common corruptions and perturbations. arXiv preprint arXiv:1903.12261, 2019. 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[25]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Man- tas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[26]
The many faces of robust- ness: A critical analysis of out-of-distribution generalization
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kada- vath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, et al. The many faces of robust- ness: A critical analysis of out-of-distribution generalization. In Proceedings of the IEEE/CVF international conference on computer vision, pages 8340–8349, 2021. 2, 5
work page 2021
-
[27]
Visual sketchpad: Sketching as a visual chain of thought for multimodal language models
Yushi Hu, Weijia Shi, Xingyu Fu, Dan Roth, Mari Ostendorf, Luke Zettlemoyer, Noah A Smith, and Ranjay Krishna. Visual sketchpad: Sketching as a visual chain of thought for multi- modal language models. arXiv preprint arXiv:2406.09403,
-
[28]
Huggingface. Llama multiple images. https : / / huggingface.co/meta-llama/Llama-3.2-11B- Vision-Instruct/discussions/43. 26 10
-
[29]
Alon Jacovi, Avi Caciularu, Omer Goldman, and Yoav Gold- berg. Stop uploading test data in plain text: Practical strategies for mitigating data contamination by evaluation benchmarks. arXiv preprint arXiv:2305.10160, 2023. 8
-
[30]
Oneformer: One transformer to rule universal image segmentation, 2022
Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, and Humphrey Shi. Oneformer: One transformer to rule universal image segmentation, 2022. 7
work page 2022
-
[31]
Many-shot in-context learning in multimodal foundation models
Yixing Jiang, Jeremy Irvin, Ji Hun Wang, Muhammad Ahmed Chaudhry, Jonathan H Chen, and Andrew Y Ng. Many-shot in-context learning in multimodal foundation models. arXiv preprint arXiv:2405.09798, 2024. 2, 3
-
[32]
Yixing Jiang, Jeremy Irvin, Ji Hun Wang, Muhammad Ahmed Chaudhry, Jonathan H. Chen, and Andrew Y . Ng. Many-shot in-context learning in multimodal foundation models, 2024. 28
work page 2024
-
[33]
3d common corruptions and data augmentation
O˘guzhan Fatih Kar, Teresa Yeo, Andrei Atanov, and Amir Zamir. 3d common corruptions and data augmentation. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 18963–18974, 2022. 7
work page 2022
-
[34]
3d com- mon corruptions for object recognition
O˘guzhan Fatih Kar, Teresa Yeo, and Amir Zamir. 3d com- mon corruptions for object recognition. In ICML 2022 Shift Happens Workshop, 2022. 2, 5
work page 2022
-
[35]
Decomposed Prompting: A Modular Approach for Solving Complex Tasks
Tushar Khot, Harsh Trivedi, Matthew Finlayson, Yao Fu, Kyle Richardson, Peter Clark, and Ashish Sabharwal. Decomposed prompting: A modular approach for solving complex tasks. arXiv preprint arXiv:2210.02406, 2022. 2
work page internal anchor Pith review arXiv 2022
-
[37]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. arXiv preprint arXiv:2304.02643, 2023. 2, 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip- 2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Evaluating Object Hallucination in Large Vision-Language Models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucina- tion in large vision-language models. arXiv preprint arXiv:2305.10355, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C
Tsung-Yi Lin, Michael Maire, Serge J. Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft COCO: Common objects in context. In European Conference on Computer Vision, 2014. 2, 5
work page 2014
-
[41]
Llava-next: Improved reason- ing, ocr, and world knowledge, 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reason- ing, ocr, and world knowledge, 2024. 2
work page 2024
- [42]
-
[43]
4M: Massively multimodal masked modeling
David Mizrahi, Roman Bachmann, O˘guzhan Fatih Kar, Teresa Yeo, Mingfei Gao, Afshin Dehghan, and Amir Zamir. 4M: Massively multimodal masked modeling. In Advances in Neural Information Processing Systems, 2023. 6
work page 2023
-
[44]
OpenAI. Introducing openai o1. https://openai.com/ o1/, 2024. 2, 5
work page 2024
-
[45]
OpenAI. Hello gpt-4o. https://openai.com/index/ hello-gpt-4o/, 2024. Accessed: 2024-09-23. 1, 2, 4
work page 2024
-
[46]
Introducing 4o image generation, 2025
OpenAI. Introducing 4o image generation, 2025. 8
work page 2025
-
[47]
Introducing openai o3 and o4-mini
OpenAI. Introducing openai o3 and o4-mini. https:// openai.com/index/introducing- o3- and- o4- mini/, 2025. 2, 5
work page 2025
-
[48]
Vision language models are blind
Pooyan Rahmanzadehgervi, Logan Bolton, Mohammad Reza Taesiri, and Anh Totti Nguyen. Vision language models are blind. arXiv preprint arXiv:2407.06581, 2024. 2
-
[49]
Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do imagenet classifiers generalize to im- agenet? In International conference on machine learning , pages 5389–5400. PMLR, 2019. 2, 5
work page 2019
-
[50]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Machel Reid, Nikolay Savinov, Denis Teplyashin, Dmitry Lepikhin, Timothy Lillicrap, Jean-baptiste Alayrac, Radu Soricut, Angeliki Lazaridou, Orhan Firat, Julian Schrit- twieser, et al. Gemini 1.5: Unlocking multimodal under- standing across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024. 1, 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. arXiv preprint arXiv:2311.12022, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Ku- mar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. In Proceed- ings of the IEEE/CVF international conference on computer vision, pages 10912–10922, 2021. 2, 5
work page 2021
-
[53]
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San- jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael S. Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet large scale visual recognition chal- lenge. International Journal of Computer Vision, 115:211– 252, 2014. 2, 5
work page 2014
-
[54]
Super- pixels: An evaluation of the state-of-the-art
David Stutz, Alexander Hermans, and Bastian Leibe. Super- pixels: An evaluation of the state-of-the-art. Computer Vision and Image Understanding, 166:1–27, 2018. 3
work page 2018
-
[55]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models. arXiv preprint arXiv:2405.09818, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai Charitha Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, et al. Cambrian-1: A fully open, vision-centric exploration of multimodal llms. arXiv preprint arXiv:2406.16860, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Eyes wide shut? exploring the visual shortcomings of multimodal llms
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms. arXiv preprint arXiv:2401.06209, 2024. 2 11
-
[59]
The internet’s source for visuals
Unsplash. The internet’s source for visuals. https:// unsplash.com/, 2024. Accessed: 2024-09-23. 9, 28, 36, 37, 38
work page 2024
-
[60]
Learning robust global representations by penalizing local predictive power
Haohan Wang, Songwei Ge, Zachary Lipton, and Eric P Xing. Learning robust global representations by penalizing local predictive power. Advances in Neural Information Processing Systems, 32, 2019. 2, 5
work page 2019
-
[61]
GIT: A Generative Image-to-text Transformer for Vision and Language
Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, and Lijuan Wang. Git: A generative image-to-text transformer for vision and language. arXiv preprint arXiv:2205.14100, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[62]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191, 2024. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
Chain-of- thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of- thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824– 24837, 2022. 2, 8
work page 2022
-
[64]
Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, and Ludwig Schmidt
Mitchell Wortsman, Gabriel Ilharco, Samir Yitzhak Gadre, Rebecca Roelofs, Raphael Gontijo-Lopes, Ari S. Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, and Ludwig Schmidt. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time, 2022. 6
work page 2022
-
[65]
V*: Guided visual search as a core mechanism in multimodal llms
Penghao Wu and Saining Xie. V*: Guided visual search as a core mechanism in multimodal llms. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13084–13094, 2024. 2, 3
work page 2024
-
[66]
Dettoolchain: A new prompting paradigm to unleash detection ability of mllm
Yixuan Wu, Yizhou Wang, Shixiang Tang, Wenhao Wu, Tong He, Wanli Ouyang, Jian Wu, and Philip Torr. Dettoolchain: A new prompting paradigm to unleash detection ability of mllm. arXiv preprint arXiv:2403.12488, 2024. 2, 21
-
[67]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v. arXiv preprint arXiv:2310.11441, 2023. 2, 22, 23
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[68]
The dawn of lmms: Preliminary explorations with gpt-4v(ision), 2023
Zhengyuan Yang, Linjie Li, Kevin Lin, Jianfeng Wang, Chung-Ching Lin, Zicheng Liu, and Lijuan Wang. The dawn of lmms: Preliminary explorations with gpt-4v(ision), 2023. 3
work page 2023
-
[69]
Tree of thoughts: Deliberate problem solving with large language models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Grif- fiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. Ad- vances in Neural Information Processing Systems, 36, 2024. 2
work page 2024
-
[70]
A Survey on Multimodal Large Language Models
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models. arXiv preprint arXiv:2306.13549, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[71]
Mmmu: A massive multi-discipline multi- modal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multi- modal understanding and reasoning benchmark for expert agi. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9556–9567, 2024. 2
work page 2024
-
[72]
Mm-llms: Recent advances in multimodal large language models
Duzhen Zhang, Yahan Yu, Chenxing Li, Jiahua Dong, Dan Su, Chenhui Chu, and Dong Yu. Mm-llms: Recent ad- vances in multimodal large language models. arXiv preprint arXiv:2401.13601, 2024. 2
-
[73]
Scene parsing through ADE20K dataset
Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Bar- riuso, and Antonio Torralba. Scene parsing through ADE20K dataset. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 5122–5130, 2017. 2
work page 2017
-
[74]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, et al. Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[75]
Detrs with collab- orative hybrid assignments training, 2023
Zhuofan Zong, Guanglu Song, and Yu Liu. Detrs with collab- orative hybrid assignments training, 2023. 6, 7
work page 2023
-
[76]
Learning ordinal relationships for mid-level vi- sion
Daniel Zoran, Phillip Isola, Dilip Krishnan, and William T Freeman. Learning ordinal relationships for mid-level vi- sion. In Proceedings of the IEEE international conference on computer vision, pages 388–396, 2015. 3, 19 12 Appendix Table of Contents A . Overview Video & Interactive Visualizations 13 B . Code & Full Prompts 13 C . Qualitative Examples 13...
work page 2015
-
[77]
The predicted mask when no crops are given, and markings on the full image are directly used. The model is unable to make out fine details. 3. The predicted mask when the top of the semantic pyramid is removed. The model misses out on predicting some finer details (for instance, the gaps in the bench and the handbag). 4. The predicted mask when the middle...
-
[78]
- Produce a raw image (same dimensions as input) whose pixel colors encode the normals as above
**Output format ** - Directly generate an image. - Produce a raw image (same dimensions as input) whose pixel colors encode the normals as above. - Do **not** add any annotations, text overlays, or alpha channels: only the RGB channels
-
[79]
**Normal-map encoding ** - For each pixel estimate its surface normal vector - Display the orientation of the surface normal vector using the standard color scheme used in computer graphics. Listing 3. Normals prediction prompt for GPT-4o image generation G.1.1. Prompt sensitivity We observe that GPT-4o’s image generation is susceptible to changes in the ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.