EverAnimate: Minute-Scale Human Animation via Latent Flow Restoration
Pith reviewed 2026-06-30 21:19 UTC · model grok-4.3
The pith
EverAnimate generates minute-scale human animations without accumulating quality or identity drift by restoring latent flow trajectories across chunks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
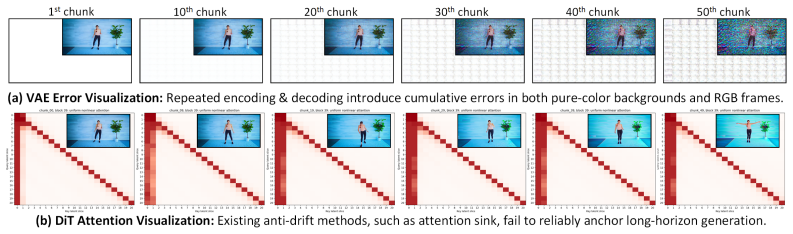
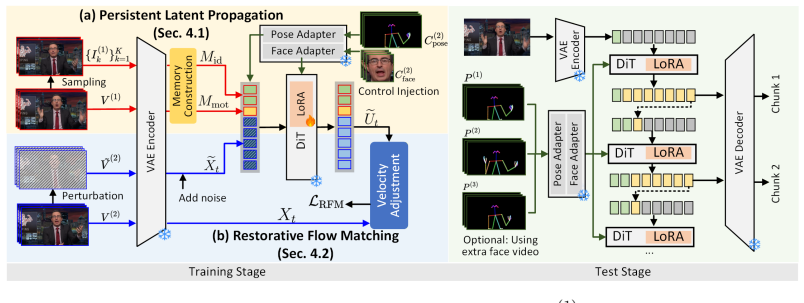
EverAnimate restores drifted flow trajectories by anchoring generation to a persistent latent context memory, consisting of Persistent Latent Propagation that maintains identity and motion across chunks and Restorative Flow Matching that applies velocity adjustment during sampling to improve within-chunk fidelity.
What carries the argument
Persistent latent context memory that propagates identity and motion across generation chunks while Restorative Flow Matching adjusts sampling velocities to restore fidelity.
If this is right
- Static background elements remain stable for the full duration of the animation.
- Character appearance and viewpoint attributes stay consistent without additional identity-preserving losses.
- The same base model can be adapted to long sequences with only a few thousand training steps.
- Gains in perceptual metrics widen as sequence length increases from 10 to 90 seconds.
Where Pith is reading between the lines
- The same latent-memory anchoring could be tested on non-human subjects or scene-only videos to check generality.
- Combining the approach with existing temporal attention layers might further reduce the need for any fine-tuning.
- If the velocity adjustment proves robust, it could be applied at inference time to other chunked diffusion pipelines without retraining.
Load-bearing premise
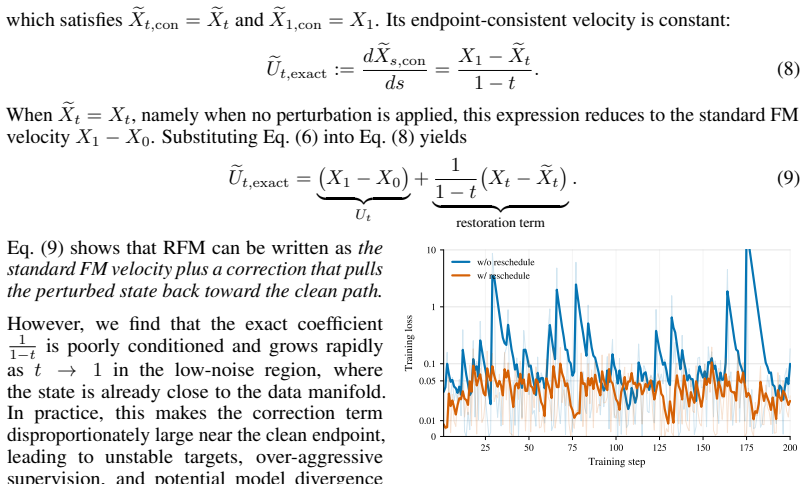
Maintaining a persistent latent context memory across chunks together with velocity adjustment during sampling is enough to stop both quality and semantic drift without creating fresh inconsistencies.
What would settle it
Generate a 3-minute animation with the method and measure whether background PSNR or character identity metrics begin to decline after the 90-second mark.
Figures




read the original abstract
We propose EverAnimate, an efficient post-training method for long-horizon animated video generation that preserves visual quality and character identity. Long-form animation remains challenging because highly dynamic human motion must be synthesized against relatively static environments, making chunk-based generation prone to accumulated drift: (i) low-level quality drift, such as progressive degradation of static backgrounds, and (ii) high-level semantic drift, such as inconsistent character identity and view-dependent attributes. To address this issue, EverAnimate restores drifted flow trajectories by anchoring generation to a persistent latent context memory, consisting of two complementary mechanisms. (i) Persistent Latent Propagation maintains a context memory across chunks to propagate identity and motion in latent space while mitigating temporal forgetting. (ii) Restorative Flow Matching introduces an implicit restoration objective during sampling through velocity adjustment, improving within-chunk fidelity. With only lightweight LoRA tuning, EverAnimate outperforms state-of-the-art long-animation methods in both short- and long-horizon settings: at 10 seconds, it improves PSNR/SSIM by 8%/7% and reduces LPIPS/FID by 22%/11%; at 90 seconds, the gains increase to 15%/15% and 32%/27%, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EverAnimate, a post-training method for minute-scale human video animation that uses Persistent Latent Propagation (maintaining context memory across chunks) and Restorative Flow Matching (velocity adjustment during sampling) with lightweight LoRA tuning to mitigate low-level quality drift and high-level semantic drift. It claims consistent outperformance over SOTA long-animation methods, with metric gains (PSNR/SSIM up 8%/7%, LPIPS/FID down 22%/11% at 10s; larger gains of 15%/15% and 32%/27% at 90s).
Significance. If the reported gains are robust, the work would offer a practical, low-cost route to long-horizon animation without full retraining, addressing a recognized bottleneck in chunked video generation. The combination of persistent latent memory and implicit restoration during sampling is a plausible direction, though its independence from the base model parameters remains to be demonstrated.
major comments (2)
- [Abstract] Abstract: the central quantitative claim (specific PSNR/SSIM/LPIPS/FID deltas at 10 s and 90 s) is presented without any description of dataset composition, number of test sequences, random-seed statistics, or baseline re-implementations, rendering the outperformance claim unverifiable from the supplied material.
- [Abstract] Abstract / Methods: no equations, pseudocode, or ablation isolating Persistent Latent Propagation versus Restorative Flow Matching are supplied, so it is impossible to determine whether the two mechanisms are independent or whether the velocity adjustment reduces to quantities already fitted by the base model.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve verifiability and technical detail.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central quantitative claim (specific PSNR/SSIM/LPIPS/FID deltas at 10 s and 90 s) is presented without any description of dataset composition, number of test sequences, random-seed statistics, or baseline re-implementations, rendering the outperformance claim unverifiable from the supplied material.
Authors: We agree that the abstract should include sufficient context to support the quantitative claims. In the revision we will expand the abstract with a brief description of the evaluation dataset, number of test sequences, statistical protocol (including random seeds), and confirmation that baselines were re-implemented from their original publications, while retaining full details in the Experiments section. revision: yes
-
Referee: [Abstract] Abstract / Methods: no equations, pseudocode, or ablation isolating Persistent Latent Propagation versus Restorative Flow Matching are supplied, so it is impossible to determine whether the two mechanisms are independent or whether the velocity adjustment reduces to quantities already fitted by the base model.
Authors: The current manuscript provides textual descriptions of the two mechanisms but lacks formal equations, pseudocode, and isolating ablations. We will add the mathematical formulations for Persistent Latent Propagation and Restorative Flow Matching, include pseudocode for the overall procedure, and insert an ablation study that isolates the contribution of each component. This will demonstrate that the velocity adjustment introduces an additional term during sampling that is independent of the base model. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical post-training method (Persistent Latent Propagation + Restorative Flow Matching with lightweight LoRA) whose performance claims are supported by reported metric improvements on short- and long-horizon video generation tasks. No equations, derivations, or first-principles results are supplied that reduce the claimed gains to quantities defined by the method's own fitted parameters or by self-citation chains. The central mechanisms are described as independent additions to an existing generation pipeline rather than tautological redefinitions of the evaluation targets. Because the manuscript contains no load-bearing self-citations, fitted-input predictions, or ansatz smuggling, the derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Drift-Resistant Navigation World Model with Anchored Epipolar Guidance
A generative navigation world model that uses sparse anchored rollout with epipolar constraints to reduce perceptual and geometric drift.
Reference graph
Works this paper leans on
-
[2]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, Kathrina Wu, Qin Lin, Junkun Yuan, Yanxin Long, Aladdin Wang, Andong Wang, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Hongmei Wang, Jacob Song, Jiawang Bai, Jianbing Wu, Jinbao Xue, Joey Wang, Kai Wang, Mengyang Liu, Pengyu Li, Shuai Li, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Everybody dance now
Caroline Chan, Shiry Ginosar, Tinghui Zhou, and Alexei A Efros. Everybody dance now. In Proceedings of the IEEE/CVF international conference on computer vision, pages 5933–5942, 2019
2019
-
[4]
Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Guilin Liu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. Video-to-video synthesis.arXiv preprint arXiv:1808.06601, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning.arXiv preprint arXiv:2307.04725, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Magicanimate: Temporally consistent human image animation using diffusion model
Zhongcong Xu, Jianfeng Zhang, Jun Hao Liew, Hanshu Yan, Jia-Wei Liu, Chenxu Zhang, Jiashi Feng, and Mike Zheng Shou. Magicanimate: Temporally consistent human image animation using diffusion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1481–1490, 2024
2024
-
[7]
Li Hu, Xin Gao, Peng Zhang, Ke Sun, Bang Zhang, and Liefeng Bo. Animate anyone: Consistent and controllable image-to-video synthesis for character animation.arXiv preprint arXiv:2311.17117, 2023
arXiv 2023
-
[8]
Jeongho Kim, Min-Jung Kim, Junsoo Lee, and Jaegul Choo. Tcan: Animating human images with temporally consistent pose guidance using diffusion models.arXiv preprint arXiv:2407.09012, 2024
-
[9]
Posecrafter: One-shot personalized video synthesis following flexible pose control
Yong Zhong, Min Zhao, Zebin You, Xiaofeng Yu, Changwang Zhang, and Chongxuan Li. Posecrafter: One-shot personalized video synthesis following flexible pose control. InEuropean conference on computer vision, pages 243–260. Springer, 2024
2024
-
[10]
Qijun Gan, Yi Ren, Chen Zhang, Zhenhui Ye, Pan Xie, Xiang Yin, Zehuan Yuan, Bingyue Peng, and Jianke Zhu. Humandit: Pose-guided diffusion transformer for long-form human motion video generation.arXiv preprint arXiv:2502.04847, 2025. 10
-
[11]
One-to-all animation: Alignment-free character animation and image pose transfer
Shijun Shi, Jing Xu, Zhihang Li, Chunli Peng, Xiaoda Yang, Lijing Lu, Kai Hu, and Jiangning Zhang. One-to-all animation: Alignment-free character animation and image pose transfer. arXiv preprint arXiv:2511.22940, 2025
Pith/arXiv arXiv 2025
-
[12]
SteadyDancer: Harmonized and Coherent Human Image Animation with First-Frame Preservation
Jiaming Zhang, Shengming Cao, Rui Li, Xiaotong Zhao, Yutao Cui, Xinglin Hou, Gangshan Wu, Haolan Chen, Yu Xu, Limin Wang, and Kai Ma. Steadydancer: Harmonized and coherent human image animation with first-frame preservation.arXiv preprint arXiv:2511.19320, 2025. URLhttps://arxiv.org/abs/2511.19320
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Shuai Tan, Biao Gong, Xiang Wang, Shiwei Zhang, Dandan Zheng, Ruobing Zheng, Kecheng Zheng, Jingdong Chen, and Ming Yang. Animate-x: Universal character image animation with enhanced motion representation.arXiv preprint arXiv:2410.10306, 2024
-
[15]
Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453, 2023
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453, 2023
Pith/arXiv arXiv 2023
-
[16]
Wuyang Li, Wentao Pan, Po-Chien Luan, Yang Gao, and Alexandre Alahi. Stable video infinity: Infinite-length video generation with error recycling.arXiv preprint arXiv:2510.09212, 2025
arXiv 2025
-
[17]
First order motion model for image animation.Advances in neural information processing systems, 32, 2019
Aliaksandr Siarohin, Stéphane Lathuilière, Sergey Tulyakov, Elisa Ricci, and Nicu Sebe. First order motion model for image animation.Advances in neural information processing systems, 32, 2019
2019
-
[19]
Yuang Zhang, Jiaxi Gu, Li-Wen Wang, Han Wang, Junqi Cheng, Yuefeng Zhu, and Fangyuan Zou. Mimicmotion: High-quality human motion video generation with confidence-aware pose guidance.arXiv preprint arXiv:2406.19680, 2024
arXiv 2024
-
[20]
Xiang Wang, Shiwei Zhang, Longxiang Tang, Yingya Zhang, Changxin Gao, Yuehuan Wang, and Nong Sang. Unianimate-dit: Human image animation with large-scale video diffusion transformer.arXiv preprint arXiv:2504.11289, 2025
-
[21]
Jingkai Zhou, Yifan Wu, Shikai Li, Min Wei, Chao Fan, Weihua Chen, Wei Jiang, and Fan Wang. RealisDance-DiT: Simple yet strong baseline towards controllable character animation in the wild.arXiv preprint arXiv:2504.14977, 2025
-
[22]
StableAnimator: High-quality identity-preserving human image animation
Shuyuan Tu, Zhen Xing, Xintong Han, Zhi-Qi Cheng, Qi Dai, Chong Luo, and Zuxuan Wu. StableAnimator: High-quality identity-preserving human image animation. InCVPR, 2025
2025
-
[23]
Gang Cheng, Xin Gao, Li Hu, Siqi Hu, Mingyang Huang, Chaonan Ji, et al. Wan- Animate: Unified character animation and replacement with holistic replication.arXiv preprint arXiv:2509.14055, 2025
-
[24]
Wenhao Yan, Sheng Ye, Zhuoyi Yang, Jiayan Teng, ZhenHui Dong, Kairui Wen, Xiaotao Gu, Yong-Jin Liu, and Jie Tang. Scail: Towards studio-grade character animation via in-context learning of 3d-consistent pose representations.arXiv preprint arXiv:2512.05905, 2025
-
[25]
Videox-fun: A video generation pipeline for diffusion transformer, 2026
aigc apps. Videox-fun: A video generation pipeline for diffusion transformer, 2026. URL https://github.com/aigc-apps/VideoX-Fun
2026
-
[26]
Deformable gaussian occupancy: Decoupling rigid and nonrigid motion with factorized distillation
Yang Gao, Wuyang Li, Po-Chien Luan, and Alexandre Alahi. Deformable gaussian occupancy: Decoupling rigid and nonrigid motion with factorized distillation. InCVPR, 2026
2026
-
[27]
Rang Meng, Xingyu Zhang, Yuming Li, and Chenguang Ma. Echomimicv2: Towards striking, simplified, and semi-body human animation.arXiv preprint arXiv:2411.10061, 2024. URL https://arxiv.org/abs/2411.10061. 11
-
[28]
Gaojie Lin, Jianwen Jiang, Jiaqi Yang, Zerong Zheng, and Chao Liang. Omnihuman-1: Rethinking the scaling-up of one-stage conditioned human animation models.arXiv preprint arXiv:2502.01061, 2025
-
[29]
Yi Chen, Sen Liang, Zixiang Zhou, Ziyao Huang, Yifeng Ma, Junshu Tang, Qin Lin, Yuan Zhou, and Qinglin Lu. HunyuanVideo-Avatar: High-fidelity audio-driven human animation for multiple characters.arXiv preprint arXiv:2505.20156, 2025
-
[30]
PoseGen: In-Context LoRA Finetuning for Pose-Controllable Long Human Video Generation
Jingxuan He, Busheng Su, and Finn Wong. PoseGen: In-context LoRA finetuning for pose- controllable long human video generation.arXiv preprint arXiv:2508.05091, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Shen Zheng, Jiaran Cai, Yuansheng Guan, Shenneng Huang, Xingpei Ma, Junjie Cao, Hanfeng Zhao, Qiang Zhang, Shunsi Zhang, and Xiao-Ping Zhang. High-fidelity and long-duration human image animation with diffusion transformer.arXiv preprint arXiv:2512.21905, 2025
-
[32]
Junyoung Seo, Rodrigo Mira, Alexandros Haliassos, Stella Bounareli, Honglie Chen, Linh Tran, Seungryong Kim, Zoe Landgraf, and Jie Shen. Lookahead anchoring: Preserving character identity in audio-driven human animation.arXiv preprint arXiv:2510.23581, 2025
-
[33]
AnimateAnywhere: Rouse the background in human image animation
Xiaoyu Liu, Mingshuai Yao, Yabo Zhang, Xianhui Lin, Peiran Ren, Xiaoming Li, Ming Liu, and Wangmeng Zuo. AnimateAnywhere: Rouse the background in human image animation. arXiv preprint arXiv:2504.19834, 2025
-
[34]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, Varun Jampani, and Robin Rombach. Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan Team. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih-Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
MAGI-1: Autoregressive Video Generation at Scale
Sand.ai. MAGI-1: Autoregressive video generation at scale.arXiv preprint arXiv:2505.13211, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
SkyReels-V2: Infinite-length Film Generative Model
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, et al. SkyReels-V2: Infinite-length film generative model.arXiv preprint arXiv:2504.13074, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [41]
-
[42]
Social-mamba: Efficient human trajectory forecasting with state-space models
Po-Chien Luan, Wuyang Li, Yang Gao, and Alexandre Alahi. Social-mamba: Efficient human trajectory forecasting with state-space models. 2025
2025
-
[43]
Diffusion forcing: Next-token prediction meets full-sequence diffusion
Boyuan Chen, Diego Marti Monso, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion. InNeurIPS, 2024
2024
-
[44]
Freeman, Frédo Durand, Eli Shechtman, and Xun Huang
Tianwei Yin, Qiang Zhang, Richard Zhang, William T. Freeman, Frédo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. In CVPR, 2025
2025
-
[45]
Self forcing: Bridging the train-test gap in autoregressive video diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion. InNeurIPS, 2025
2025
-
[46]
Rolling forcing: Autoregressive long video diffusion in real time
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling forcing: Autoregressive long video diffusion in real time. InICLR, 2026. 12
2026
-
[47]
LongLive: Real-time Interactive Long Video Generation
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, Song Han, and Yukang Chen. Longlive: Real-time interactive long video generation.arXiv preprint arXiv:2509.22622, 2025. URL https://arxiv.org/abs/2509.22622
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Packing input frame context in next-frame prediction models for video generation
Lvmin Zhang, Shengqu Cai, Muyang Li, Gordon Wetzstein, and Maneesh Agrawala. Packing input frame context in next-frame prediction models for video generation. InNeurIPS, 2025
2025
-
[49]
Stable video infinity: Infinite-length video generation with error recycling
Wuyang Li, Wentao Pan, Po-Chien Luan, Yang Gao, and Alexandre Alahi. Stable video infinity: Infinite-length video generation with error recycling. InICLR, 2026
2026
-
[50]
Helios: Real real-time long video generation model.arXiv preprint arXiv:2603.04379, 2026
Shenghai Yuan, Yuanyang Yin, Zongjian Li, Xinwei Huang, Xiao Yang, and Li Yuan. Helios: Real real-time long video generation model.arXiv preprint arXiv:2603.04379, 2026
-
[51]
Matrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
Zile Wang, Zexiang Liu, Jaixing Li, Kaichen Huang, Baixin Xu, Fei Kang, Mengyin An, Peiyu Wang, Biao Jiang, Yichen Wei, et al. Matrix-game 3.0: Real-time and streaming interactive world model with long-horizon memory.arXiv preprint arXiv:2604.08995, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
LongCat-Video technical report.arXiv preprint arXiv:2510.22200, 2025
Meituan LongCat Team. LongCat-Video technical report.arXiv preprint arXiv:2510.22200, 2025
-
[53]
Sihyun Yu, Meera Hahn, Dan Kondratyuk, Jinwoo Shin, Agrim Gupta, Jose Lezama, Irfan Essa, David Ross, and Jonathan Huang. Malt diffusion: Memory-augmented latent transformers for any-length video generation.arXiv preprint arXiv:2502.12632, 2025
-
[54]
TinyHistory: Lightweight Video History Embeddings via Two-Stage Context Learning
Lvmin Zhang, Shengqu Cai, Muyang Li, Chong Zeng, Beijia Lu, Anyi Rao, Song Han, Gordon Wetzstein, and Maneesh Agrawala. Pretraining frame preservation in autoregressive video memory compression.arXiv preprint arXiv:2512.23851, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
WorldMem: Long-term consistent world simulation with memory.arXiv preprint arXiv:2504.12369, 2025
Zeqi Xiao, Yushi Lan, Yifan Zhou, Wenqi Ouyang, Shuai Yang, Yanhong Zeng, and Xingang Pan. WorldMem: Long-term consistent world simulation with memory.arXiv preprint arXiv:2504.12369, 2025
-
[56]
Context forcing: Consistent autoregressive video generation with long context,
Shuo Chen, Cong Wei, Sun Sun, Ping Nie, Kai Zhou, Ge Zhang, Ming-Hsuan Yang, and Wenhu Chen. Context forcing: Consistent autoregressive video generation with long context.arXiv preprint arXiv:2602.06028, 2026
-
[57]
Diffsynth-studio
ModelScope Team. Diffsynth-studio. GitHub repository, 2024. URL https://github.com/ modelscope/DiffSynth-Studio. Accessed: 2026-05-04
2024
-
[58]
Champ: Controllable and consistent human image animation with 3d parametric guidance
Shenhao Zhu, Junming Leo Chen, Zuozhuo Dai, Zilong Dong, Yinghui Xu, Xun Cao, Yao Yao, Hao Zhu, and Siyu Zhu. Champ: Controllable and consistent human image animation with 3d parametric guidance. InEuropean Conference on Computer Vision, pages 145–162. Springer, 2024
2024
-
[59]
Polina Zablotskaia, Aliaksandr Siarohin, Bo Zhao, and Leonid Sigal. Dwnet: Dense warp-based network for pose-guided human video generation.arXiv preprint arXiv:1910.09139, 2019
-
[60]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Yu Gao, Haoyuan Guo, Tuyen Hoang, Weilin Huang, Lu Jiang, Fangyuan Kong, Huixia Li, Jiashi Li, Liang Li, Xiaojie Li, et al. Seedance 1.0: Exploring the boundaries of video generation models.arXiv preprint arXiv:2506.09113, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training. InAdvances in Neural Information Processing Systems, 2022. 13
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.