Drift-Resistant Navigation World Model with Anchored Epipolar Guidance
Pith reviewed 2026-06-30 13:05 UTC · model grok-4.3
The pith
Sparse future anchors and epipolar geometry mitigate drift in navigation world models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
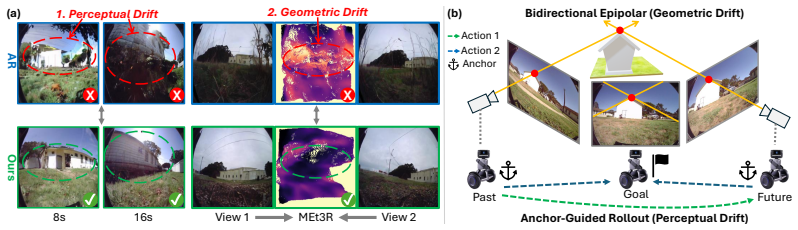
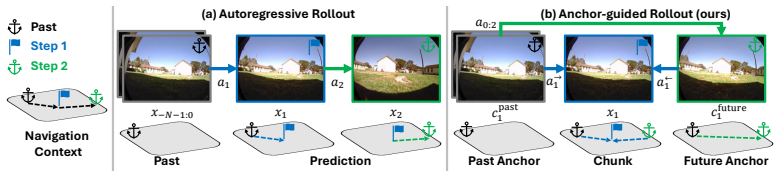
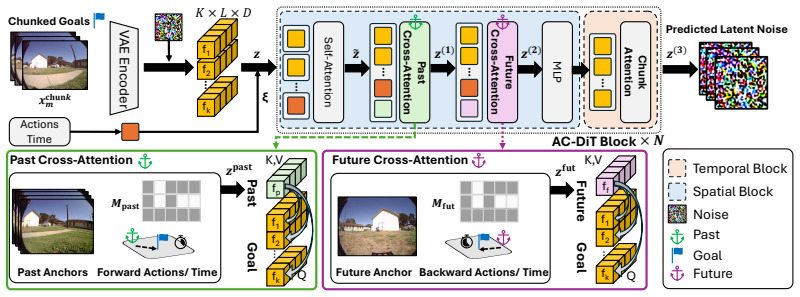
Redesigning world-model prediction as an anchor-guided rollout, where sparse future anchors serve as stable long-range targets and supply bidirectional epipolar geometric constraints for localizing content in intermediate frames, mitigates both perceptual drift from recursive generation and geometric drift from motion deviation.
What carries the argument
Anchor-guided rollout that predicts sparse anchors first and conditions intermediate-frame generation on both past context and future anchors via bidirectional epipolar geometry.
If this is right
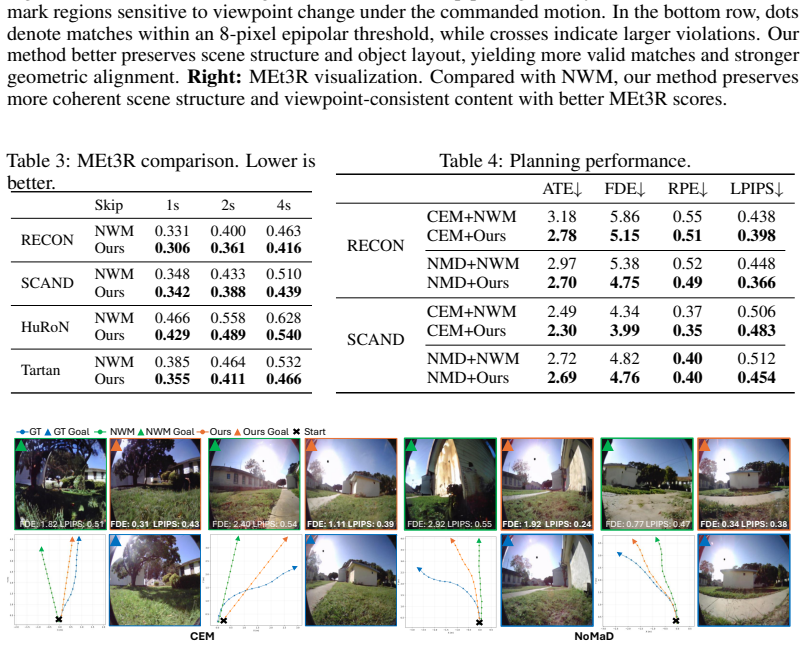
- Consistent gains in long-horizon visual quality across four benchmarks relative to strong baselines.
- Improved geometric consistency and multi-view coherence in the generated sequences.
- Higher downstream planning performance when the same planners are applied to the improved predictions.
- Reduced accumulation of noise that normally occurs in purely recursive frame generation.
Where Pith is reading between the lines
- The same two-stage anchor-then-fill structure could be tested in non-navigation video prediction settings where long-term coherence matters.
- Explicit future conditioning may reduce the frequency of model resets needed in extended simulation rollouts.
- Real-robot deployment data would reveal whether the reported planning gains survive sensor noise and unmodeled dynamics.
Load-bearing premise
The predicted sparse anchors must be accurate enough to serve as reliable conditioning targets without introducing new errors when they are themselves generated predictions.
What would settle it
A controlled test in which inaccurate predicted anchors are deliberately supplied and the model shows worse geometric consistency or visual quality than baselines that do not use anchors.
Figures








read the original abstract
We propose Drift-Resistant Navigation World Model, a generative model that mitigates both perceptual drift and geometric drift in conventional rollout-based navigation world models. Existing methods recursively feed generated content into subsequent steps, causing noise accumulation and degraded predictions, i.e., perceptual drift. Meanwhile, their predictions often deviate from the agent's motion, resulting in geometry drift. We address both types of drift by redesigning world-model prediction as an anchor-guided rollout. Instead of rolling out every frame sequentially, we first predict sparse future anchors that serve as stable long-range targets, and then generate intermediate frames within each chunk conditioned on both past context and future anchors. Importantly, these sparse anchors also provide geometric constraints, supported by bidirectional epipolar geometry, to localize where corresponding content should appear in the intermediate frames. Experiments on four benchmarks demonstrate consistent improvements over strong baselines in long-horizon visual quality, geometric consistency, and multi-view coherence. These gains further translate into improved downstream planning performance under the same planners, highlighting the importance of drift-resistant, geometry-aware prediction for reliable navigation world models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Drift-Resistant Navigation World Model that mitigates perceptual and geometric drift in rollout-based generative world models for navigation. It does so by first predicting sparse future anchors as long-range targets, then generating intermediate frames conditioned on both past context and these anchors, with bidirectional epipolar geometry providing geometric constraints to localize content across frames. Experiments on four benchmarks are claimed to show consistent gains in long-horizon visual quality, geometric consistency, multi-view coherence, and downstream planning performance.
Significance. If the central claims hold with rigorous validation, the anchored epipolar guidance could meaningfully advance reliable long-horizon prediction in navigation world models by reducing drift accumulation, with direct benefits for planning. The use of standard epipolar geometry as an external constraint rather than learned parameters is a strength, but the significance hinges on whether self-generated anchors remain stable conditioning signals.
major comments (3)
- [Method (anchor-guided rollout and epipolar constraints)] The central claim that bidirectional epipolar geometry localizes content correctly when both anchors and intermediate frames are model predictions (rather than observed data) is load-bearing, yet the manuscript provides no quantitative verification such as anchor reprojection error against ground-truth motion or an ablation removing the epipolar term. This directly addresses the feedback-loop concern in the method description.
- [Experiments] Experiments section reports improvements over strong baselines on four benchmarks but supplies no numerical values, error bars, baseline implementation details, or statistical significance tests. Without these, it is impossible to assess whether gains are consistent or attributable to post-hoc selection.
- [Introduction and Method] The assumption that predicted sparse anchors serve as stable long-range targets is stated without an analysis of how prediction error in anchors propagates through the epipolar rays to intermediate frames; a sensitivity study or failure-case analysis is needed to support the drift-resistance claim.
minor comments (2)
- [Abstract] The abstract claims 'consistent improvements' without any supporting numbers or figures; move at least one quantitative result (e.g., a table row or metric delta) into the abstract for clarity.
- [Method] Notation for anchors, epipolar lines, and conditioning is introduced without an explicit diagram or equation block summarizing the full conditioning objective.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects for strengthening the validation of our anchored epipolar guidance approach. We address each major comment below and will incorporate revisions to provide the requested quantitative support and analyses.
read point-by-point responses
-
Referee: The central claim that bidirectional epipolar geometry localizes content correctly when both anchors and intermediate frames are model predictions (rather than observed data) is load-bearing, yet the manuscript provides no quantitative verification such as anchor reprojection error against ground-truth motion or an ablation removing the epipolar term. This directly addresses the feedback-loop concern in the method description.
Authors: We agree that explicit quantitative verification is needed to substantiate the localization claim under predicted content. In the revised manuscript, we will add an ablation removing the epipolar term and report its effect on metrics. We will also include anchor reprojection error measurements against ground-truth motion to directly address the feedback-loop concern. revision: yes
-
Referee: Experiments section reports improvements over strong baselines on four benchmarks but supplies no numerical values, error bars, baseline implementation details, or statistical significance tests. Without these, it is impossible to assess whether gains are consistent or attributable to post-hoc selection.
Authors: We acknowledge the absence of detailed numerical results, error bars, implementation specifics, and significance tests in the current manuscript. The revised version will expand the Experiments section to include these elements for all four benchmarks, enabling proper evaluation of consistency and attribution of gains. revision: yes
-
Referee: The assumption that predicted sparse anchors serve as stable long-range targets is stated without an analysis of how prediction error in anchors propagates through the epipolar rays to intermediate frames; a sensitivity study or failure-case analysis is needed to support the drift-resistance claim.
Authors: We recognize that the manuscript lacks a dedicated sensitivity analysis on anchor error propagation. We will add a sensitivity study varying anchor prediction noise and its impact on intermediate frames, along with failure-case analysis, to better support the drift-resistance claims in the revision. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided manuscript text describes a generative modeling approach that predicts sparse anchors and applies bidirectional epipolar geometry for conditioning intermediate frames. No equations, parameter-fitting steps, or derivations are present that reduce any claimed prediction to its own inputs by construction. The method invokes standard epipolar geometry without self-citation chains or ansatz smuggling. Experimental claims rest on benchmark comparisons rather than a closed mathematical loop, satisfying the criteria for a self-contained, non-circular presentation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bidirectional epipolar geometry provides usable localization constraints between predicted anchor frames and intermediate frames.
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Met3r: Measuring multi-view consistency in generated images
Mohammad Asim, Christopher Wewer, Thomas Wimmer, Bernt Schiele, and Jan Eric Lenssen. Met3r: Measuring multi-view consistency in generated images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6034–6044, 2025
2025
-
[3]
Anurag Bagchi, Zhipeng Bao, Homanga Bharadhwaj, Yu-Xiong Wang, Pavel Tokmakov, and Martial Hebert. Walk through paintings: Egocentric world models from internet priors.arXiv preprint arXiv:2601.15284, 2026
-
[4]
Navigation world models
Amir Bar, Gaoyue Zhou, Danny Tran, Trevor Darrell, and Yann LeCun. Navigation world models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15791–15801, 2025
2025
-
[5]
Scheduled sampling for sequence prediction with recurrent neural networks.Advances in neural information processing systems, 28, 2015
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks.Advances in neural information processing systems, 28, 2015
2015
-
[6]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Yixiang Dai, Fan Jiang, Chiyu Wang, Mu Xu, and Yonggang Qi. Fantasyworld: Geometry- consistent world modeling via unified video and 3d prediction.arXiv preprint arXiv:2509.21657, 2025
-
[8]
DreamSim: Learning New Dimensions of Human Visual Similarity using Synthetic Data
Stephanie Fu, Netanel Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel, and Phillip Isola. Dreamsim: Learning new dimensions of human visual similarity using synthetic data.arXiv preprint arXiv:2306.09344, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Recurrent world models facilitate policy evolution.Ad- vances in neural information processing systems, 31, 2018
David Ha and Jürgen Schmidhuber. Recurrent world models facilitate policy evolution.Ad- vances in neural information processing systems, 31, 2018
2018
-
[10]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Cambridge university press, 2003
Richard Hartley and Andrew Zisserman.Multiple view geometry in computer vision. Cambridge university press, 2003
2003
-
[12]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[13]
Sacson: Scalable autonomous control for social navigation.IEEE Robotics and Automation Letters, 9(1):49–56, 2023
Noriaki Hirose, Dhruv Shah, Ajay Sridhar, and Sergey Levine. Sacson: Scalable autonomous control for social navigation.IEEE Robotics and Automation Letters, 9(1):49–56, 2023
2023
-
[14]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[15]
Socially compliant navigation dataset (scand): A large-scale dataset of demonstrations for social navigation.IEEE Robotics and Automation Letters, 7(4):11807–11814, 2022
Haresh Karnan, Anirudh Nair, Xuesu Xiao, Garrett Warnell, Sören Pirk, Alexander Toshev, Justin Hart, Joydeep Biswas, and Peter Stone. Socially compliant navigation dataset (scand): A large-scale dataset of demonstrations for social navigation.IEEE Robotics and Automation Letters, 7(4):11807–11814, 2022
2022
-
[16]
Dongwon Kim, Gawon Seo, Jinsung Lee, Minsu Cho, and Suha Kwak. Planning in 8 tokens: A compact discrete tokenizer for latent world model.arXiv preprint arXiv:2603.05438, 2026
-
[17]
Epipolar Geometry Improves Video Generation Models
Orest Kupyn, Fabian Manhardt, Federico Tombari, and Christian Rupprecht. Epipolar geometry improves video generation models.arXiv preprint arXiv:2510.21615, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Springer Science & Business Media, 2012
Jean-Claude Latombe.Robot motion planning, volume 124. Springer Science & Business Media, 2012
2012
-
[19]
A path towards autonomous machine intelligence version 0.9
Yann LeCun et al. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27. Open Review, 62(1):1–62, 2022
2022
-
[20]
EverAnimate: Minute-Scale Human Animation via Latent Flow Restoration
Wuyang Li, Yang Gao, Mariam Hassan, Lan Feng, Wentao Pan, Po-Chien Luan, and Alexandre Alahi. Everanimate: Minute-scale human animation via latent flow restoration.arXiv preprint arXiv:2605.15042, 2026. 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Wuyang Li, Wentao Pan, Po-Chien Luan, Yang Gao, and Alexandre Alahi. Stable video infinity: Infinite-length video generation with error recycling.arXiv preprint arXiv:2510.09212, 2025
-
[22]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
Plans and the structure of behaviour
George A Miller, Galanter Eugene, and Karl H Pribram. Plans and the structure of behaviour. InSystems research for behavioral science, pages 369–382. Routledge, 2017
2017
-
[24]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[25]
Gen3c: 3d-informed world- consistent video generation with precise camera control
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Müller, Alexander Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world- consistent video generation with precise camera control. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6121–6132, 2025
2025
-
[26]
Optimization of computer simulation models with rare events.European Journal of Operational Research, 99(1):89–112, 1997
Reuven Y Rubinstein. Optimization of computer simulation models with rare events.European Journal of Operational Research, 99(1):89–112, 1997
1997
-
[27]
very scattered
Paul D Sampson. Fitting conic sections to “very scattered” data: An iterative refinement of the bookstein algorithm.Computer graphics and image processing, 18(1):97–108, 1982
1982
-
[28]
Dhruv Shah, Benjamin Eysenbach, Gregory Kahn, Nicholas Rhinehart, and Sergey Levine. Rapid exploration for open-world navigation with latent goal models.arXiv preprint arXiv:2104.05859, 2021
-
[29]
Vint: A foundation model for visual navigation.arXiv preprint arXiv:2306.14846, 2023
Dhruv Shah, Ajay Sridhar, Nitish Dashora, Kyle Stachowicz, Kevin Black, Noriaki Hi- rose, and Sergey Levine. Vint: A foundation model for visual navigation.arXiv preprint arXiv:2306.14846, 2023
-
[30]
Wangtian Shen, Ziyang Meng, Jinming Ma, Mingliang Zhou, and Diyun Xiang. An efficient and multi-modal navigation system with one-step world model.arXiv preprint arXiv:2601.12277, 2026
-
[31]
Loftr: Detector-free local feature matching with transformers
Jiaming Sun, Zehong Shen, Yuang Wang, Hujun Bao, and Xiaowei Zhou. Loftr: Detector-free local feature matching with transformers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8922–8931, 2021
2021
-
[32]
Tartandrive: A large-scale dataset for learning off-road dynamics models
Samuel Triest, Matthew Sivaprakasam, Sean J Wang, Wenshan Wang, Aaron M Johnson, and Sebastian Scherer. Tartandrive: A large-scale dataset for learning off-road dynamics models. In 2022 International Conference on Robotics and Automation (ICRA), pages 2546–2552. IEEE, 2022
2022
-
[33]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024
2024
-
[34]
Motionctrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible motion controller for video generation. InACM SIGGRAPH 2024 Conference Papers, pages 1–11, 2024
2024
-
[35]
Geometry Forcing: Marrying Video Diffusion and 3D Representation for Consistent World Modeling
Haoyu Wu, Diankun Wu, Tianyu He, Junliang Guo, Yang Ye, Yueqi Duan, and Jiang Bian. Ge- ometry forcing: Marrying video diffusion and 3d representation for consistent world modeling. arXiv preprint arXiv:2507.07982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Han Yan, Zishang Xiang, Zeyu Zhang, and Hao Tang. Mwm: Mobile world models for action-conditioned consistent prediction.arXiv preprint arXiv:2603.07799, 2026
-
[37]
RAE-NWM: Navigation World Model in Dense Visual Representation Space
Mingkun Zhang, Wangtian Shen, Fan Zhang, Haijian Qin, Zihao Pei, and Ziyang Meng. Rae-nwm: Navigation world model in dense visual representation space.arXiv preprint arXiv:2603.09241, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018. 11 A Geometric Justification of Bidirectional Epipolar Intersection We briefly justify why the intersec...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.