Bayesian Social Deduction with Graph-Informed Language Models
Pith reviewed 2026-05-19 07:24 UTC · model grok-4.3
The pith
Externalizing belief inference to a graph-informed probabilistic model lets smaller language agents match large models and defeat humans in Avalon.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
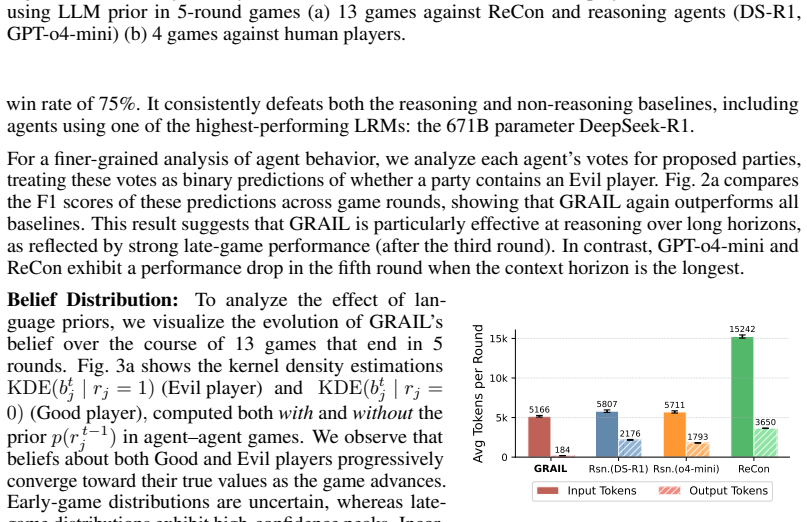
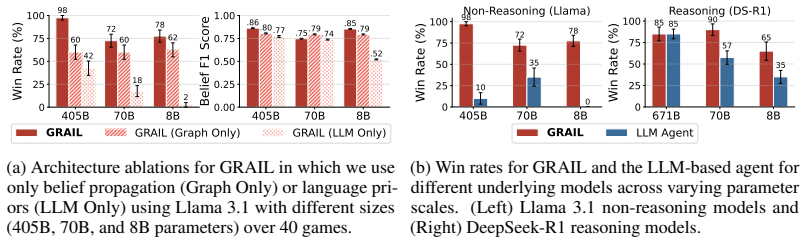
The authors demonstrate that a hybrid system, in which a graph-informed structured probabilistic model handles externalized belief inference about other players' hidden states while the language model manages only language understanding and communication, achieves competitive results against much larger pure language models in agent-versus-agent Avalon and secures a 67 percent win rate against human opponents in controlled experiments.
What carries the argument
The hybrid reasoning framework that externalizes belief inference to a graph-informed probabilistic model for tracking unobservable player intentions and beliefs.
If this is right
- Agents can operate in real time without needing extensive test-time inference.
- Performance holds across different model sizes when the belief model is kept separate.
- Qualitative ratings from humans favor the hybrid agent over both reasoning baselines and fellow humans.
Where Pith is reading between the lines
- The approach may extend to other domains requiring theory-of-mind reasoning, such as negotiation or collaborative planning.
- Success against humans points to uses in social simulation and AI training environments.
Load-bearing premise
The graph-informed probabilistic model correctly extracts and represents the crucial unobservable beliefs and intentions of other agents from partial game observations.
What would settle it
A replication study in which the hybrid agent plays against humans and fails to exceed a 50 percent win rate, or in which swapping the graph model for pure LLM-based belief inference restores the performance gap seen in distilled models.
Figures








read the original abstract
Social reasoning - inferring unobservable beliefs and intentions from partial observations of other agents - remains a challenging task for large language models (LLMs). We evaluate the limits of current reasoning language models in the social deduction game Avalon and find that while the largest models demonstrate strong performance, they require extensive test-time inference and degrade sharply when distilled to smaller, real-time-capable variants. To address this, we introduce a hybrid reasoning framework that externalizes belief inference to a structured probabilistic model, while using an LLM for language understanding and interaction. Our approach achieves competitive performance with much larger models in Agent-Agent play and, notably, is the first language agent to defeat human players in a controlled study - achieving a 67% win rate and receiving higher qualitative ratings than both reasoning baselines and human teammates. We release code, models, and a dataset to support future work on social reasoning in LLM agents, which can be found at https://camp-lab-purdue.github.io/bayesian-social-deduction/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a hybrid reasoning framework for the social deduction game Avalon that externalizes belief inference about hidden roles, intentions, and knowledge to a graph-informed structured probabilistic model while delegating language understanding and interaction to an LLM. It reports competitive performance against much larger models in agent-agent play and, in a controlled human study, a 67% win rate for the hybrid agent along with higher qualitative ratings than both reasoning baselines and human teammates. The authors release code, models, and a dataset.
Significance. If the results are robust, the work provides evidence that hybrid systems can achieve strong social reasoning with smaller, real-time LLMs by offloading complex belief tracking to an external probabilistic structure, addressing a known limitation of pure end-to-end LLM reasoning. The human-study result would constitute a notable first for language agents if the controls and statistical reporting hold. Open release of artifacts is a clear strength that supports reproducibility and follow-on research.
major comments (2)
- [§3] §3 (Model): The description of the graph-informed probabilistic belief model lacks explicit equations for the update rules and the representation of higher-order beliefs (e.g., nested beliefs about other agents' beliefs). Without these, it is impossible to verify whether the structure captures the deceptive or nested intentions that arise in human play, which is the load-bearing assumption for the 67% win-rate claim.
- [§4.3] §4.3 (Human Study): The results section reports a 67% win rate and higher qualitative ratings but provides no details on participant count, experience matching, statistical tests, or exclusion criteria. This omission prevents assessment of whether the hybrid split introduces new failure modes precisely in the human regime where superiority is claimed.
minor comments (2)
- [Abstract] The abstract and introduction use the term 'parameter-free' for the probabilistic component; clarify whether any hyperparameters in the graph construction or prior specification are tuned on the evaluation data.
- [Figure 2] Figure 2 (architecture diagram) would benefit from an explicit legend distinguishing LLM-generated text from probabilistic belief outputs to improve readability for readers unfamiliar with hybrid agent designs.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We provide point-by-point responses to the major comments below. We agree that additional mathematical detail and experimental reporting are needed to strengthen the manuscript and will revise accordingly.
read point-by-point responses
-
Referee: [§3] §3 (Model): The description of the graph-informed probabilistic belief model lacks explicit equations for the update rules and the representation of higher-order beliefs (e.g., nested beliefs about other agents' beliefs). Without these, it is impossible to verify whether the structure captures the deceptive or nested intentions that arise in human play, which is the load-bearing assumption for the 67% win-rate claim.
Authors: We acknowledge that the model section provides a high-level description of the graph-informed probabilistic belief model without explicit equations. This is a valid point, as the update rules for beliefs and the mechanism for representing higher-order beliefs are crucial for understanding how the model handles deception and nested intentions in Avalon. In the revised manuscript, we will add the formal equations for the belief update process, including how the graph structure encodes and propagates higher-order beliefs. This revision will make it possible to verify the model's capacity to support the reported performance. revision: yes
-
Referee: [§4.3] §4.3 (Human Study): The results section reports a 67% win rate and higher qualitative ratings but provides no details on participant count, experience matching, statistical tests, or exclusion criteria. This omission prevents assessment of whether the hybrid split introduces new failure modes precisely in the human regime where superiority is claimed.
Authors: We appreciate the referee drawing attention to the reporting standards for the human study. While the manuscript states the 67% win rate and qualitative ratings, we agree that more details are necessary for full evaluation. We will revise the section to include the number of participants, how they were matched for experience, the statistical tests conducted (including p-values), and the exclusion criteria used. These additions will allow for a better assessment of the results and any potential failure modes in human interactions. revision: yes
Circularity Check
No significant circularity in the hybrid model or performance claims
full rationale
The paper describes a hybrid framework that externalizes belief inference to an independent structured probabilistic model over a graph of agents/roles/observations, while delegating language tasks to the LLM. No equations, derivations, or self-citations are shown that reduce the claimed win rates or competitive performance to a fitted parameter defined by the result itself, a self-referential definition, or a load-bearing uniqueness theorem from prior author work. The results are presented as empirical outcomes from agent-agent and controlled human-play experiments, with the probabilistic component described as external and structured rather than fitted to the target metrics, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate hidden role inference as probabilistic inference over a factor graph... max-product belief propagation... neural network trained on a dataset of over 100,000 games
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GRAIL... externalizes belief inference to a structured probabilistic model
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Co-Evolving LLM Decision and Skill Bank Agents for Long-Horizon Tasks
COSPLAY co-evolves an LLM decision agent with a skill bank agent to improve long-horizon game performance, reporting over 25.1% average reward gains versus frontier LLM baselines on single-player benchmarks.
-
Evaluating Large Language Models in a Complex Hidden Role Game
LLMs achieve only 59.7% role identification accuracy in Secret Hitler versus 86.7% for rule-based agents, show negative impact as fascists, and produce 40% shorter games due to failed deception.
Reference graph
Works this paper leans on
-
[1]
Large language models for mathematical reasoning: Progresses and challenges
Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, and Wenpeng Yin. Large language models for mathematical reasoning: Progresses and challenges. In Neele Falk, Sara Papi, and Mike Zhang, editors, Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: Student Research Workshop, pages 225–237, St. Ju...
work page 2024
-
[2]
Nitay Alon, Lion Schulz, Jeffrey Rosenschein, and Peter Dayan. A (dis-)information theory of revealed and unrevealed preferences: Emerging deception and skepticism via theory of mind. Open Mind, 7:1–17, 08 2023. doi: 10.1162/opmi_a_00097
-
[3]
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sashank Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bra...
work page 2023
-
[4]
Exploring and controlling diversity in llm-agent conversation, 2025
KuanChao Chu, Yi-Pei Chen, and Hideki Nakayama. Exploring and controlling diversity in llm-agent conversation, 2025. URL https://arxiv.org/abs/2412.21102
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025. URL https://arxiv.org/abs/2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Wellman, Yu Wang, Genyue Fu, and Kang Lee
Xiao Pan Ding, Henry M. Wellman, Yu Wang, Genyue Fu, and Kang Lee. Theory-of-mind training causes honest young children to lie. Psychological Science, 26(11):1812–1821, 2015. doi: 10.1177/0956797615604628. URL https://doi.org/10.1177/0956797615604628. PMID: 26431737
-
[7]
Gtbench: Uncovering the strategic reasoning capabilities of llms via game-theoretic evaluations
Jinhao Duan, Renming Zhang, James Diffenderfer, Bhavya Kailkhura, Lichao Sun, Elias Stengel-Eskin, Mohit Bansal, Tianlong Chen, and Kaidi Xu. Gtbench: Uncovering the strategic reasoning capabilities of llms via game-theoretic evaluations. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors, Advances in Neural Info...
work page 2024
-
[8]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, 10 Arun Rao, Aston Zhang, Aurélien Rodriguez, Austen Gregerson, Ava Spataru, Baptiste Rozière, Beth...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
- [9]
-
[10]
Human-level play in the game of diplomacy by combining language models with strategic reasoning
Meta Fundamental AI Research Diplomacy Team (FAIR) †, Anton Bakhtin, Noam Brown, Emily Dinan, Gabriele Farina, Colin Flaherty, Daniel Fried, Andrew Goff, Jonathan Gray, Hengyuan Hu, Athul Paul Jacob, Mojtaba Komeili, Karthik Konath, Minae Kwon, Adam Lerer, Mike Lewis, Alexander H. Miller, Sasha Mitts, Adithya Renduchintala, Stephen Roller, Dirk Rowe, Weiy...
-
[11]
Tracking beliefs and intentions in the werewolf game
Codruta Gîrlea, Eyal Amir, and Roxana Girju. Tracking beliefs and intentions in the werewolf game. In International Conference on Principles of Knowledge Representation and Reasoning,
-
[12]
URL https://api.semanticscholar.org/CorpusID:11838
-
[13]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. A survey on llm-as-a-judge, 2025. URL https://arxiv.org/abs/ 2411.15594
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
On Calibration of Modern Neural Networks
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks, 2017. URL https://arxiv.org/abs/1706.04599
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
Jiaxian Guo, Bo Yang, Paul Yoo, Bill Yuchen Lin, Yusuke Iwasawa, and Yutaka Matsuo. Suspicion-agent: Playing imperfect information games with theory of mind aware gpt-4, 2024. URL https://arxiv.org/abs/2309.17277
-
[16]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum? id=d7KBjmI3GmQ
work page 2021
-
[17]
Ho, Rebecca Saxe, and Fiery Cushman
Mark K. Ho, Rebecca Saxe, and Fiery Cushman. Planning with theory of mind. Trends in Cognitive Sciences , 26(11):959–971, 2022. ISSN 1364-6613. doi: https://doi.org/ 10.1016/j.tics.2022.08.003. URL https://www.sciencedirect.com/science/article/ pii/S1364661322001851
-
[18]
Putting the con in context: Identifying deceptive actors in the game of mafia
Samee Ibraheem, Gaoyue Zhou, and John DeNero. Putting the con in context: Identifying deceptive actors in the game of mafia. In Marine Carpuat, Marie-Catherine de Marneffe, and Ivan Vladimir Meza Ruiz, editors, Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies, ...
-
[19]
Overcoming catastrophic forgetting in neural networks
Michal Kosinski. Evaluating large language models in theory of mind tasks. Proceedings of the National Academy of Sciences, 121(45), October 2024. ISSN 1091-6490. doi: 10.1073/pnas. 2405460121. URL http://dx.doi.org/10.1073/pnas.2405460121
-
[20]
F.R. Kschischang, B.J. Frey, and H.-A. Loeliger. Factor graphs and the sum-product algorithm. IEEE Transactions on Information Theory, 47(2):498–519, 2001. doi: 10.1109/18.910572
-
[21]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
work page 2023
-
[22]
Werewolf among us: Multimodal resources for modeling persuasion behaviors in social deduction games
Bolin Lai, Hongxin Zhang, Miao Liu, Aryan Pariani, Fiona Ryan, Wenqi Jia, Shirley Anugrah Hayati, James Rehg, and Diyi Yang. Werewolf among us: Multimodal resources for modeling persuasion behaviors in social deduction games. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Findings of the Association for Computational Linguistics: ACL 202...
-
[23]
Llm-based agent society investigation: Collaboration and confrontation in avalon gameplay, 2024
Yihuai Lan, Zhiqiang Hu, Lei Wang, Yang Wang, Deheng Ye, Peilin Zhao, Ee-Peng Lim, Hui Xiong, and Hao Wang. Llm-based agent society investigation: Collaboration and confrontation in avalon gameplay, 2024. URL https://arxiv.org/abs/2310.14985
-
[24]
Theory of mind for multi-agent collaboration via large language models
Huao Li, Yu Chong, Simon Stepputtis, Joseph Campbell, Dana Hughes, Charles Lewis, and Katia Sycara. Theory of mind for multi-agent collaboration via large language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 180–192, Singapore, December
work page 2023
-
[25]
doi: 10.18653/v1/2023.emnlp-main.13
Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.13. URL https://aclanthology.org/2023.emnlp-main.13/
-
[26]
AvalonBench: Evaluating LLMs Playing the Game of Avalon, 2023
Jonathan Light, Min Cai, Sheng Shen, and Ziniu Hu. Avalonbench: Evaluating llms playing the game of avalon, 2023. URL https://arxiv.org/abs/2310.05036
-
[27]
Enhancing language model agents using diversity of thoughts
Vijay Lingam, Behrooz Omidvar Tehrani, Sujay Sanghavi, Gaurav Gupta, Sayan Ghosh, Linbo Liu, Jun Huan, and Anoop Deoras. Enhancing language model agents using diversity of thoughts. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=ZsP3YbYeE9
work page 2025
-
[29]
Potsawee Manakul, Adian Liusie, and Mark Gales. SelfCheckGPT: Zero-resource black- box hallucination detection for generative large language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9004–9017, Singapore, December 2023. Association for Comput...
-
[30]
Henry B. Mann and Douglas R. Whitney. On a test of whether one of two random variables is stochastically larger than the other. Annals of Mathematical Statistics, 18:50–60, 1947. URL https://api.semanticscholar.org/CorpusID:14328772
work page 1947
-
[31]
Situations, actions, and causal laws
John McCarthy. Situations, actions, and causal laws. 1963. URL https://api. semanticscholar.org/CorpusID:118922379
work page 1963
-
[32]
Niloofar Mireshghallah, Hyunwoo Kim, Xuhui Zhou, Yulia Tsvetkov, Maarten Sap, Reza Shokri, and Yejin Choi. Can LLMs keep a secret? testing privacy implications of language models via contextual integrity theory. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=gmg7t8b4s0. 12
work page 2024
-
[33]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling, 2025. URL https://arxiv.org/abs/2501.19393
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Murphy, Yair Weiss, and Michael I
Kevin P. Murphy, Yair Weiss, and Michael I. Jordan. Loopy belief propagation for approximate inference: an empirical study. In Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence, UAI’99, page 467–475, San Francisco, CA, USA, 1999. Morgan Kaufmann Publishers Inc. ISBN 1558606149
work page 1999
-
[35]
Reasoning over uncertain text by generative large language models, 2024
Aliakbar Nafar, Kristen Brent Venable, and Parisa Kordjamshidi. Reasoning over uncertain text by generative large language models, 2024. URL https://arxiv.org/abs/2402.09614
-
[36]
Précis of bayesian rationality: The probabilistic approach to human reasoning
Mike Oaksford and Nick Chater. Précis of bayesian rationality: The probabilistic approach to human reasoning. Behavioral and Brain Sciences , 32(1):69–84, 2009. doi: 10.1017/ S0140525X09000284
work page 2009
-
[37]
Introducing openai o3 and o4-mini, April 2025
OpenAI. Introducing openai o3 and o4-mini, April 2025. URL https://openai.com/index/ introducing-o3-and-o4-mini/ . Accessed 2025-05-09
work page 2025
-
[38]
What are the odds? language models are capable of probabilistic reasoning
Akshay Paruchuri, Jake Garrison, Shun Liao, John Hernandez, Jacob Sunshine, Tim Althoff, Xin Liu, and Daniel McDuff. What are the odds? language models are capable of probabilistic reasoning. In Conference on Empirical Methods in Natural Language Processing, 2024. URL https://api.semanticscholar.org/CorpusID:270562235
work page 2024
-
[39]
Reasoning with language model prompting: A survey
Shuofei Qiao, Yixin Ou, Ningyu Zhang, Xiang Chen, Yunzhi Yao, Shumin Deng, Chuanqi Tan, Fei Huang, and Huajun Chen. Reasoning with language model prompting: A survey. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 5368–...
work page 2023
-
[40]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark, 2023. URL https://arxiv.org/abs/2311.12022
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Michael D. Richard and Richard P. Lippmann. Neural network classifiers estimate bayesian a posteriori probabilities. Neural Computation, 3(4):461–483, 1991. doi: 10.1162/neco.1991.3.4. 461
-
[42]
arXiv preprint arXiv:2412.19726 , year=
Matthew Riemer, Zahra Ashktorab, Djallel Bouneffouf, Payel Das, Miao Liu, Justin D. Weisz, and Murray Campbell. Position: Theory of mind benchmarks are broken for large language models, 2025. URL https://arxiv.org/abs/2412.19726
-
[43]
Bidipta Sarkar, Warren Xia, C. Karen Liu, and Dorsa Sadigh. Training language models for social deduction with multi-agent reinforcement learning, 2025. URL https://arxiv.org/ abs/2502.06060
-
[44]
Rylan Schaeffer, Brando Miranda, and Sanmi Koyejo. Are emergent abilities of large language models a mirage? In Thirty-seventh Conference on Neural Information Processing Systems,
-
[45]
URL https://openreview.net/forum?id=ITw9edRDlD
-
[46]
Pomegranate: fast and flexible probabilistic modeling in python
Jacob Schreiber. Pomegranate: fast and flexible probabilistic modeling in python. Journal of Machine Learning Research, 18(164):1–6, 2018
work page 2018
-
[47]
Knowledge-Centric Hallucination Detection
Eli Schwartz, Leshem Choshen, Joseph Shtok, Sivan Doveh, Leonid Karlinsky, and Assaf Arbelle. NumeroLogic: Number encoding for enhanced LLMs’ numerical reasoning. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages 206–212, Miami, Florida, USA, Novemb...
-
[48]
Minding language models’ (lack of) theory of mind: A plug-and-play multi-character belief tracker
Melanie Sclar, Sachin Kumar, Peter West, Alane Suhr, Yejin Choi, and Yulia Tsvetkov. Minding language models’ (lack of) theory of mind: A plug-and-play multi-character belief tracker. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pape...
-
[49]
Finding friend and foe in multi-agent games
Jack Serrino, Max Kleiman-Weiner, David C Parkes, and Josh Tenenbaum. Finding friend and foe in multi-agent games. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper_files/ paper/...
work page 2019
-
[50]
Clever hans or neural theory of mind? stress testing social reasoning in large language models
Natalie Shapira, Mosh Levy, Seyed Hossein Alavi, Xuhui Zhou, Yejin Choi, Yoav Goldberg, Maarten Sap, and Vered Shwartz. Clever hans or neural theory of mind? stress testing social reasoning in large language models. In Yvette Graham and Matthew Purver, editors,Proceedings of the 18th Conference of the European Chapter of the Association for Computational ...
work page 2024
-
[51]
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Esin DURMUS, Zac Hatfield-Dodds, Scott R Johnston, Shauna M Kravec, Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang, and Ethan Perez. Towards understanding sycophancy in language models. In The Twelfth Internati...
work page 2024
-
[52]
Loopy Belief Propagation in the Presence of Determinism
David Smith and Vibhav Gogate. Loopy Belief Propagation in the Presence of Determinism. In Samuel Kaski and Jukka Corander, editors, Proceedings of the Seventeenth International Conference on Artificial Intelligence and Statistics , volume 33 of Proceedings of Machine Learning Research, pages 895–903, Reykjavik, Iceland, 22–25 Apr 2014. PMLR. URL https: /...
work page 2014
-
[53]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters, 2024. URL https://arxiv. org/abs/2408.03314
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Simon Stepputtis, Joseph Campbell, Yaqi Xie, Zhengyang Qi, Wenxin Zhang, Ruiyi Wang, Sanketh Rangreji, Charles Lewis, and Katia Sycara. Long-horizon dialogue understanding for role identification in the game of avalon with large language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Findings of the Association for Computational Linguistic...
-
[55]
James W. A. Strachan, Dalila Albergo, Giulia Borghini, Oriana Pansardi, Eugenio Scaliti, Saurabh Gupta, Krati Saxena, Alessandro Rufo, Stefano Panzeri, Guido Manzi, Michael S. A. Graziano, and Cristina Becchio. Testing theory of mind in large language models and humans. Nature Human Behaviour , 8(7):1285–1295, May 2024. ISSN 2397-3374. doi: 10.1038/ s4156...
-
[56]
Qwq-32b: Embracing the power of reinforcement learning, March 2025
Qwen Team. Qwq-32b: Embracing the power of reinforcement learning, March 2025. URL https://qwenlm.github.io/blog/qwq-32b/
work page 2025
-
[57]
Large Language Models Fail on Trivial Alterations to Theory-of-Mind Tasks, 2023
Tomer Ullman. Large language models fail on trivial alterations to theory-of-mind tasks, 2023. URL https://arxiv.org/abs/2302.08399
-
[58]
Martin J. Wainwright and Michael I. Jordan. Graphical models, exponential families, and varia- tional inference. Foundations and Trends® in Machine Learning, 1(1–2):25–34, 2008. ISSN 1935-8237. doi: 10.1561/2200000001. URL http://dx.doi.org/10.1561/2200000001. 14
-
[59]
Avalon’s game of thoughts: Battle against deception through recursive contemplation, 2023
Shenzhi Wang, Chang Liu, Zilong Zheng, Siyuan Qi, Shuo Chen, Qisen Yang, Andrew Zhao, Chaofei Wang, Shiji Song, and Gao Huang. Avalon’s game of thoughts: Battle against deception through recursive contemplation, 2023. URL https://arxiv.org/abs/2310.01320
-
[60]
Chi, Quoc V Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed H. Chi, Quoc V Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/ forum?...
work page 2022
-
[61]
Correctness of belief propagation in gaussian graphical models of arbitrary topology
Yair Weiss and William Freeman. Correctness of belief propagation in gaussian graphical models of arbitrary topology. In S. Solla, T. Leen, and K. Müller, ed- itors, Advances in Neural Information Processing Systems , volume 12. MIT Press,
-
[62]
URL https://proceedings.neurips.cc/paper_files/paper/1999/file/ 10c272d06794d3e5785d5e7c5356e9ff-Paper.pdf
work page 1999
-
[63]
Individual comparisons by ranking methods
Frank Wilcoxon. Individual comparisons by ranking methods. Biometrics Bulletin, 1(6):80–83,
-
[64]
Individual comparisons by ranking methods,
ISSN 00994987. URL http://www.jstor.org/stable/3001968
-
[65]
Enhance reasoning for large language models in the game werewolf
Shuang Wu, Liwen Zhu, Tao Yang, Shiwei Xu, Qiang Fu, Yang Wei, and Haobo Fu. Enhance reasoning for large language models in the game werewolf, 2024. URL https://arxiv.org/ abs/2402.02330
-
[66]
Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models
Fengli Xu, Qianyue Hao, Zefang Zong, Jingwei Wang, Yunke Zhang, Jingyi Wang, Xiaochong Lan, Jiahui Gong, Tianjian Ouyang, Fanjin Meng, Chenyang Shao, Yuwei Yan, Qinglong Yang, Yiwen Song, Sijian Ren, Xinyuan Hu, Yu Li, Jie Feng, Chen Gao, and Yong Li. Towards large reasoning models: A survey of reinforced reasoning with large language models, 2025. URL ht...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Lin Xu, Zhiyuan Hu, Daquan Zhou, Hongyu Ren, Zhen Dong, Kurt Keutzer, See-Kiong Ng, and Jiashi Feng. MAgIC: Investigation of large language model powered multi-agent in cognition, adaptability, rationality and collaboration. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Proceedings of the 2024 Conference on Empirical Methods in Natural La...
-
[68]
Exploring large language models for communication games: An empirical study on werewolf,
Yuzhuang Xu, Shuo Wang, Peng Li, Fuwen Luo, Xiaolong Wang, Weidong Liu, and Yang Liu. Exploring large language models for communication games: An empirical study on werewolf,
- [69]
-
[70]
Language agents with reinforcement learning for strategic play in the werewolf game, 2024
Zelai Xu, Chao Yu, Fei Fang, Yu Wang, and Yi Wu. Language agents with reinforcement learning for strategic play in the werewolf game, 2024. URLhttps://arxiv.org/abs/2310. 18940
work page 2024
-
[71]
Number cookbook: Number understanding of language models and how to improve it
Haotong Yang, Yi Hu, Shijia Kang, Zhouchen Lin, and Muhan Zhang. Number cookbook: Number understanding of language models and how to improve it. In The Thirteenth Inter- national Conference on Learning Representations, 2025. URL https://openreview.net/ forum?id=BWS5gVjgeY
work page 2025
-
[72]
Finding the m most probable configurations us- ing loopy belief propagation
Chen Yanover and Yair Weiss. Finding the m most probable configurations us- ing loopy belief propagation. In S. Thrun, L. Saul, and B. Schölkopf, edi- tors, Advances in Neural Information Processing Systems , volume 16. MIT Press,
-
[73]
URL https://proceedings.neurips.cc/paper_files/paper/2003/file/ 70fcb77e6349f4467edd7227baa73222-Paper.pdf
work page 2003
-
[74]
Benchmarking reasoning robustness in large language models, 2025
Tong Yu, Yongcheng Jing, Xikun Zhang, Wentao Jiang, Wenjie Wu, Yingjie Wang, Wenbin Hu, Bo Du, and Dacheng Tao. Benchmarking reasoning robustness in large language models, 2025. URL https://arxiv.org/abs/2503.04550
-
[75]
Making small language models efficient reasoners: Intervention, supervision, reinforcement,
Xuechen Zhang, Zijian Huang, Chenshun Ni, Ziyang Xiong, Jiasi Chen, and Samet Oymak. Making small language models efficient reasoners: Intervention, supervision, reinforcement,
- [76]
-
[77]
Pei Zhou, Andrew Zhu, Jennifer Hu, Jay Pujara, Xiang Ren, Chris Callison-Burch, Yejin Choi, and Prithviraj Ammanabrolu. I cast detect thoughts: Learning to converse and guide with intents and theory-of-mind in dungeons and dragons. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association fo...
-
[78]
Xueyang Zhou, Guiyao Tie, Guowen Zhang, Weidong Wang, Zhigang Zuo, Di Wu, Duanfeng Chu, Pan Zhou, Lichao Sun, and Neil Zhenqiang Gong. Large reasoning models in agent scenarios: Exploring the necessity of reasoning capabilities, 2025. URL https://arxiv. org/abs/2503.11074. 16 Appendix for Bayesian Social Deduction with Graph-Informed Language Models A The...
-
[82]
Suspicious or trustworthy behaviors When looking for suspicious behavior, con- sider whether players are behaving suspi- ciously or illogically with respect to chat mes- sages or party votes, e.g. always rejecting party votes unless they or another specific player is in it, or making assertions without evidence (especially early in the game such as on Que...
-
[85]
Suspicious or trustworthy behaviors Present your team selection to the other play- ers with a detailed rationale based on past events and player behaviors. Remember that you are on the evil side - if it is possible, aim to include at least one evil player while main- taining your cover. However, you will have to justify the proposed team to the other play...
-
[90]
The team must consist of <team size> players When looking for suspicious behavior, con- sider whether players are behaving suspi- ciously or illogically with respect to chat mes- sages or party votes, e.g. always rejecting party votes unless they or another specific player is in it, or making assertions without evidence (especially early in the game such ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.