EXPO: Stable Reinforcement Learning with Expressive Policies
Pith reviewed 2026-05-19 05:06 UTC · model grok-4.3
The pith
EXPO stabilizes value maximization for expressive policies in online RL by pairing a base imitation policy with a lightweight Gaussian edit policy that selects higher-value actions on the fly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
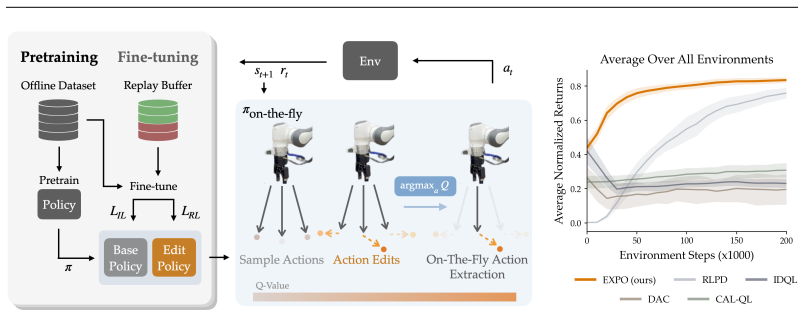
EXPO constructs an on-the-fly policy that maximizes Q-value by sampling actions from a large expressive base policy trained with a stable imitation objective, editing those actions with a lightweight Gaussian policy toward higher value, and then selecting the higher-Q action from the pair for both sampling and TD backup; this yields up to 2-3x better sample efficiency than prior methods when fine-tuning a pretrained policy or training online from offline data.
What carries the argument
The on-the-fly policy that selects between base-policy actions and actions edited by the lightweight Gaussian edit policy to maximize Q-value for both sampling and backups.
Load-bearing premise
The lightweight Gaussian edit policy can reliably produce higher-value actions from the base policy samples without introducing instability or bias into the TD backups or the on-the-fly selection process.
What would settle it
Train the same base and edit policies but replace the value-based selection step with random choice between base and edited actions; if sample efficiency then falls back to the level of prior direct-optimization methods, the selection mechanism is necessary for the reported gains.
Figures







read the original abstract
We study the problem of training and fine-tuning expressive policies with online reinforcement learning (RL) given an offline dataset. Training expressive policy classes with online RL present a unique challenge of stable value maximization. Unlike simpler Gaussian policies commonly used in online RL, expressive policies like diffusion and flow-matching policies are parameterized by a long denoising chain, which hinders stable gradient propagation from actions to policy parameters when optimizing against some value function. Our key insight is that we can address stable value maximization by avoiding direct optimization over value with the expressive policy and instead construct an on-the-fly RL policy to maximize Q-value. We propose Expressive Policy Optimization (EXPO), a sample-efficient online RL algorithm that utilizes an on-the-fly policy to maximize value with two parameterized policies -- a larger expressive base policy trained with a stable imitation learning objective and a light-weight Gaussian edit policy that edits the actions sampled from the base policy toward a higher value distribution. The on-the-fly policy optimizes the actions from the base policy with the learned edit policy and chooses the value maximizing action from the base and edited actions for both sampling and temporal-difference (TD) backup. Our approach yields up to 2-3x improvement in sample efficiency on average over prior methods both in the setting of fine-tuning a pretrained policy given offline data and in leveraging offline data to train online.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Expressive Policy Optimization (EXPO), an online RL algorithm for training and fine-tuning expressive policies (diffusion/flow-matching) given offline data. It trains a large base policy via stable imitation learning and a lightweight Gaussian edit policy; an on-the-fly policy then selects the higher-Q action between base and edited samples for both environment steps and TD backups, claiming up to 2-3x average sample-efficiency gains over prior methods in both fine-tuning and online-from-offline settings.
Significance. If the empirical claims hold under rigorous controls, the work would be significant for enabling stable online RL with complex policy classes that are otherwise difficult to optimize directly against value functions. The hybrid use of imitation-trained expressive policies plus lightweight edits offers a practical route to leverage offline data without full offline RL overhead.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): the on-the-fly max-Q selection for both sampling and TD targets uses the same Q-network without double-Q or target-network decoupling. This risks uncorrected optimistic bias when the edit policy is imperfect, directly threatening the stability claim and the reported 2-3x sample-efficiency gains. A concrete test (e.g., ablation with double-Q or target-network selection) is needed to show the bias does not inflate returns.
- [§4] §4 (experiments): the reported gains lack error bars, full ablation tables on edit-policy scale/training frequency, and controls for the selection bias identified above. Without these, it is impossible to verify whether the central sample-efficiency claim is robust or driven by the optimistic selection mechanism.
minor comments (2)
- [§3] Notation for the edit policy variance and the exact form of the on-the-fly policy (Eq. numbers in §3) should be clarified to avoid ambiguity with standard Gaussian policies.
- [§4] Figure captions and axis labels in the experimental plots should explicitly state the number of seeds and whether shaded regions are standard error or min/max.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The concerns regarding potential optimistic bias in the on-the-fly selection mechanism and the need for more rigorous experimental reporting are well-taken. We address each major comment below and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): the on-the-fly max-Q selection for both sampling and TD targets uses the same Q-network without double-Q or target-network decoupling. This risks uncorrected optimistic bias when the edit policy is imperfect, directly threatening the stability claim and the reported 2-3x sample-efficiency gains. A concrete test (e.g., ablation with double-Q or target-network selection) is needed to show the bias does not inflate returns.
Authors: We appreciate the referee's identification of this potential source of bias. Our design intentionally avoids direct value optimization of the expressive base policy to promote stability, relying instead on imitation learning for the base and small Gaussian edits. The on-the-fly max-Q choice is applied only between the base action and the lightly edited action, which limits the scope for over-optimism compared to unconstrained maximization. Nevertheless, to directly test the concern, we have run an additional ablation that decouples the selection Q-network via a target network (updated with polyak averaging) and will include these results in the revised §4. The performance gains remain consistent, supporting that the reported improvements are not primarily driven by uncorrected bias. revision: yes
-
Referee: [§4] §4 (experiments): the reported gains lack error bars, full ablation tables on edit-policy scale/training frequency, and controls for the selection bias identified above. Without these, it is impossible to verify whether the central sample-efficiency claim is robust or driven by the optimistic selection mechanism.
Authors: We agree that error bars and expanded ablations are necessary to substantiate the empirical claims. In the revision we will add standard error bars computed over at least five random seeds for all main results. We will also include a fuller set of ablation tables varying edit-policy network size, update frequency, and perturbation scale. To control for selection bias we will add a comparison against a variant that uses random selection between base and edited actions (instead of max-Q) and report the resulting sample-efficiency curves; these controls will be presented alongside the original results in the updated §4. revision: yes
Circularity Check
No significant circularity: algorithmic construction remains independent of its inputs.
full rationale
The paper presents EXPO as a new algorithmic procedure that combines a base expressive policy trained by imitation learning, a lightweight Gaussian edit policy, and on-the-fly selection of the higher-Q action for both sampling and TD targets. This construction does not reduce any claimed performance gain or stability property to a fitted parameter or self-citation by definition; the 2-3x sample-efficiency result is framed as an empirical outcome measured against external baselines rather than a quantity forced by the method's own equations. No load-bearing uniqueness theorems, ansatzes smuggled via prior self-work, or renaming of known patterns appear in the derivation chain. The approach is therefore self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
free parameters (1)
- edit policy scale and training frequency
axioms (1)
- domain assumption The value function provides a reliable signal for selecting between base and edited actions during both data collection and TD updates.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The on-the-fly policy optimizes the actions from the base policy with the learned edit policy and chooses the value maximizing action from the base and edited actions for both sampling and temporal-difference (TD) backup.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 5 Pith papers
-
Coordinated Diffusion: Generating Multi-Agent Behavior Without Multi-Agent Demonstrations
CoDi decomposes the multi-agent diffusion score into pre-trained single-agent policies plus a gradient-free cost guidance term to generate coordinated behavior from single-agent data alone.
-
TMRL: Diffusion Timestep-Modulated Pretraining Enables Exploration for Efficient Policy Finetuning
TMRL bridges behavioral cloning pretraining and RL finetuning via diffusion noise and timestep modulation to enable controlled exploration, improving sample efficiency and enabling real-world robot training in under one hour.
-
Adaptive Action Chunking via Multi-Chunk Q Value Estimation
ACH lets RL policies dynamically pick action chunk lengths by jointly estimating Q-values for all candidate lengths via a single Transformer pass.
-
OGPO: Sample Efficient Full-Finetuning of Generative Control Policies
OGPO is a sample-efficient off-policy method for full finetuning of generative control policies that reaches SOTA on robotic manipulation tasks and can recover from poor behavior-cloning initializations without expert data.
-
FASTER: Value-Guided Sampling for Fast RL
FASTER models multi-candidate denoising as an MDP and trains a value function to filter actions early, delivering the performance of full sampling at lower cost in diffusion RL policies.
Reference graph
Works this paper leans on
-
[1]
Ankile, L., Simeonov, A., Shenfeld, I., and Agrawal, P
Lars Ankile, Anthony Simeonov, Idan Shenfeld, Marcel Torne, and Pulkit Agrawal. From imitation to refinement–residual rl for precise assembly. arXiv preprint arXiv:2407.16677,
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Offline reinforcement learning via high-fidelity generative behavior modeling
Huayu Chen, Cheng Lu, Chengyang Ying, Hang Su, and Jun Zhu. Offline reinforcement learning via high-fidelity generative behavior modeling. arXiv preprint arXiv:2209.14548,
-
[4]
arXiv preprint arXiv:2101.05982 , year=
Xinyue Chen, Che Wang, Zijian Zhou, and Keith Ross. Randomized ensembled double q-learning: Learning fast without a model. arXiv preprint arXiv:2101.05982,
-
[5]
Diffusion-based reinforcement learning via q-weighted variational policy optimization
Shutong Ding, Ke Hu, Zhenhao Zhang, Kan Ren, Weinan Zhang, Jingyi Yu, Jingya Wang, and Ye Shi. Diffusion-based reinforcement learning via q-weighted variational policy optimization. arXiv preprint arXiv:2405.16173,
-
[6]
Perry Dong, Alec M Lessing, Annie S Chen, and Chelsea Finn
URL https://openreview.net/forum?id=v8jdwkUNXb. Perry Dong, Alec M Lessing, Annie S Chen, and Chelsea Finn. Reinforcement learning via implicit imitation guidance. arXiv preprint arXiv:2506.07505,
-
[7]
Linjiajie Fang, Ruoxue Liu, Jing Zhang, Wenjia Wang, and Bing-Yi Jing
URL https://proceedings.mlr.press/v80/espeholt18a.html. Linjiajie Fang, Ruoxue Liu, Jing Zhang, Wenjia Wang, and Bing-Yi Jing. Diffusion actor-critic: Formulating constrained policy iteration as diffusion noise regression for offline reinforcement learning. arXiv preprint arXiv:2405.20555,
-
[8]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
URL https://arxiv.org/abs/2004.07219. Yuwei Fu, Di Wu, and Benoit Boulet. A closer look at offline rl agents. Advances in Neural Information Processing Systems, 35:8591–8604,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[9]
MADE: Masked Autoencoder for Distribution Estimation
URL https://arxiv.org/abs/1502.03509. Seyed Kamyar Seyed Ghasemipour, Dale Schuurmans, and Shixiang Shane Gu. Emaq: Expected-max q-learning operator for simple yet effective offline and online rl. In International Conference on Machine Learning, pp. 3682–3691. PMLR,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Soft Actor-Critic Algorithms and Applications
Tuomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George Tucker, Sehoon Ha, Jie Tan, Vikash Kumar, Henry Zhu, Abhishek Gupta, Pieter Abbeel, et al. Soft actor-critic algorithms and applications. arXiv preprint arXiv:1812.05905,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Philippe Hansen-Estruch, Ilya Kostrikov, Michael Janner, Jakub Grudzien Kuba, and Sergey Levine
URL https://arxiv.org/abs/2212.05698. Philippe Hansen-Estruch, Ilya Kostrikov, Michael Janner, Jakub Grudzien Kuba, and Sergey Levine. Idql: Implicit q-learning as an actor-critic method with diffusion policies. arXiv preprint arXiv:2304.10573,
-
[12]
Aligniql: Policy alignment in implicit q-learning through constrained optimization
Longxiang He, Li Shen, Junbo Tan, and Xueqian Wang. Aligniql: Policy alignment in implicit q-learning through constrained optimization. arXiv preprint arXiv:2405.18187,
-
[13]
Deep Q-learning from Demonstrations
URL https://arxiv. org/abs/1704.03732. Hengyuan Hu, Suvir Mirchandani, and Dorsa Sadigh. Imitation bootstrapped reinforcement learning. arXiv preprint arXiv:2311.02198,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Offline Reinforcement Learning with Implicit Q-Learning
URL https://arxiv.org/abs/2110.06169. 12 Seunghyun Lee, Younggyo Seo, Kimin Lee, Pieter Abbeel, and Jinwoo Shin. Offline-to-online reinforcement learning via balanced replay and pessimistic q-ensemble,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Qiyang Li, Jason Zhang, Dibya Ghosh, Amy Zhang, and Sergey Levine
URL https: //arxiv.org/abs/2107.00591. Qiyang Li, Jason Zhang, Dibya Ghosh, Amy Zhang, and Sergey Levine. Accelerating exploration with unlabeled prior data. Advances in Neural Information Processing Systems, 36:67434–67458,
-
[16]
MimicGen: A Data Generation System for Scalable Robot Learning using Human Demonstrations
URL https://arxiv.org/abs/2310.17596. Max Sobol Mark, Archit Sharma, Fahim Tajwar, Rafael Rafailov, Sergey Levine, and Chelsea Finn. Offline retraining for online rl: Decoupled policy learning to mitigate exploration bias,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
URL https://arxiv.org/abs/2310.08558. Max Sobol Mark, Tian Gao, Georgia Gabriela Sampaio, Mohan Kumar Srirama, Archit Sharma, Chelsea Finn, and Aviral Kumar. Policy agnostic rl: Offline rl and online rl fine-tuning of any class and backbone. arXiv preprint arXiv:2412.06685,
-
[18]
Overcoming Exploration in Reinforcement Learning with Demonstrations
URL https://arxiv. org/abs/1709.10089. Ashvin Nair, Abhishek Gupta, Murtaza Dalal, and Sergey Levine. Awac: Accelerating online reinforcement learning with offline datasets,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
URL https://arxiv.org/abs/2006. 09359. Mitsuhiko Nakamoto, Simon Zhai, Anikait Singh, Max Sobol Mark, Yi Ma, Chelsea Finn, Aviral Kumar, and Sergey Levine. Cal-ql: Calibrated offline rl pre-training for efficient online fine-tuning. Advances in Neural Information Processing Systems, 36:62244–62269,
work page 2006
-
[20]
Seohong Park, Kevin Frans, Sergey Levine, and Aviral Kumar
URL https://arxiv.org/abs/2303.05479. Seohong Park, Kevin Frans, Sergey Levine, and Aviral Kumar. Is value learning really the main bottleneck in offline rl? arXiv preprint arXiv:2406.09329,
-
[21]
Seohong Park, Qiyang Li, and Sergey Levine. Flow q-learning. arXiv preprint arXiv:2502.02538,
-
[22]
Michael Psenka, Alejandro Escontrela, Pieter Abbeel, and Yi Ma. Learning a diffusion model policy from rewards via q-score matching. arXiv preprint arXiv:2312.11752,
-
[23]
Diffusion Policy Policy Optimization
Allen Z Ren, Justin Lidard, Lars L Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, and Max Simchowitz. Diffusion policy policy optimization. arXiv preprint arXiv:2409.00588,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Hybrid rl: Using both offline and online data can make rl efficient.arXiv preprint arXiv:2210.06718,
URL https: //arxiv.org/abs/2210.06718. Mel Vecerik, Todd Hester, Jonathan Scholz, Fumin Wang, Olivier Pietquin, Bilal Piot, Nicolas Heess, Thomas Rothörl, Thomas Lampe, and Martin Riedmiller. Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards,
-
[26]
Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards
URL https: //arxiv.org/abs/1707.08817. Zhendong Wang, Jonathan J Hunt, and Mingyuan Zhou. Diffusion policies as an expressive policy class for offline reinforcement learning. arXiv preprint arXiv:2208.06193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Xiu Yuan, Tongzhou Mu, Stone Tao, Yunhao Fang, Mengke Zhang, and Hao Su. Policy decorator: Model-agnostic online refinement for large policy model. arXiv preprint arXiv:2412.13630,
-
[28]
Policy expansion for bridging offline-to- online reinforcement learning,
URL https://arxiv.org/abs/2302.00935. Shiyuan Zhang, Weitong Zhang, and Quanquan Gu. Energy-weighted flow matching for offline reinforcement learning. arXiv preprint arXiv:2503.04975,
-
[29]
For offline-to-online training, we present the number of pretraining steps for each suite
Each training run presented is with three seeds and error bars indicating max and min. For offline-to-online training, we present the number of pretraining steps for each suite. We do not pretrain in the online setting. We use the same residual block structure for the base policy as IDQL (Hansen-Estruch et al., 2023). Hyperparameter Robomimic Adroit Antma...
work page 2023
-
[30]
The Adroit and Antmaze environments use the default D4RL provided datasets
We subsample 10 trajectories for Lift and use the MH dataset for Can to make the tasks harder. The Adroit and Antmaze environments use the default D4RL provided datasets. Hyperparameter Num Data Composition MimicGen Stack 200 10 human and 190 generated by MimicGen MimicGen Threading 50 10 human and 40 generated by MimicGen Robomimic Lift 10 PH Robomimic S...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.