SSL4RL: Revisiting Self-supervised Learning as Intrinsic Reward for Visual-Language Reasoning
Pith reviewed 2026-05-21 20:20 UTC · model grok-4.3
The pith
Self-supervised learning objectives can be reformulated as automatic reward signals for reinforcing vision-language model reasoning without external evaluators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SSL4RL reformulates common self-supervised learning objectives into dense automatic reward signals that can be used for RL-based fine-tuning of vision-language models, eliminating the need for human preference data or AI evaluators and leading to improved results on reasoning benchmarks.
What carries the argument
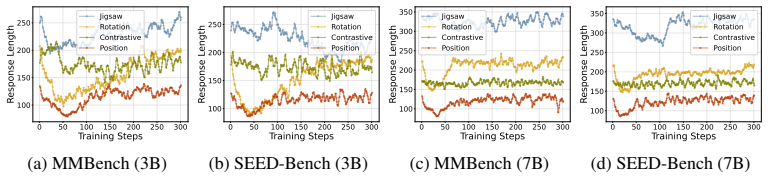
Reformulation of SSL objectives such as image rotation prediction and masked patch reconstruction into dense, automatic reward signals for RL fine-tuning of VLMs.
If this is right
- VLMs show improved performance on vision-centric and vision-language reasoning tasks after RL fine-tuning with SSL rewards.
- No human preference data or external evaluators are required to generate the rewards.
- The effectiveness of the approach depends on selecting SSL tasks with appropriate difficulty and alignment to the target domain.
- The framework can be applied to other domains such as graph learning with similar benefits.
Where Pith is reading between the lines
- This approach could lower the barrier to applying RL in multimodal settings by removing dependency on costly data collection.
- Researchers might investigate optimal combinations of different SSL tasks for reward design.
- Scaling the method to even larger models could test whether the benefits persist or amplify.
Load-bearing premise
Self-supervised learning objectives can be reformulated into dense, automatic reward signals that align with and improve desired vision-language reasoning behaviors in VLMs.
What would settle it
A controlled experiment showing that fine-tuning a VLM using these SSL-derived rewards produces no significant improvement or even worse performance on standard vision-language reasoning benchmarks compared to a baseline without such RL.
Figures












read the original abstract
Vision-language models (VLMs) have shown remarkable abilities by integrating large language models with visual inputs. However, they often fail to utilize visual evidence adequately, either depending on linguistic priors in vision-centric tasks or resorting to textual shortcuts during reasoning. Although reinforcement learning (RL) can align models with desired behaviors, its application to VLMs has been hindered by the lack of scalable and reliable reward mechanisms. To overcome this challenge, we propose SSL4RL, a novel framework that leverages self-supervised learning (SSL) tasks as a source of verifiable rewards for RL-based fine-tuning. Our approach reformulates SSL objectives-such as predicting image rotation or reconstructing masked patches-into dense, automatic reward signals, eliminating the need for human preference data or unreliable AI evaluators. Experiments show that SSL4RL substantially improves performance on both vision-centric and vision-language reasoning benchmarks. Furthermore, through systematic ablations, we identify key factors-such as task difficulty, model scale, and semantic alignment with the target domain-that influence the effectiveness of SSL4RL tasks, offering new design principles for future work. We also demonstrate the framework's generality by applying it to graph learning, where it yields significant gains. SSL4RL establishes a versatile and effective paradigm for aligning multimodal models using verifiable, self-supervised objectives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SSL4RL, a framework that reformulates self-supervised learning objectives such as image rotation prediction and masked patch reconstruction into dense, automatic reward signals for RL-based fine-tuning of vision-language models. The central claim is that this approach improves VLMs' utilization of visual evidence on vision-centric and vision-language reasoning benchmarks without human preferences or AI evaluators. Systematic ablations identify influencing factors including task difficulty, model scale, and semantic alignment, and the method is demonstrated on graph learning tasks.
Significance. If the results hold, SSL4RL provides a scalable, verifiable alternative to human or LLM-based rewards for multimodal alignment, with the ablations offering concrete design principles for selecting SSL tasks. The extension to graph learning demonstrates generality beyond VLMs. These elements strengthen the contribution if experimental attribution is clarified.
major comments (2)
- [Experiments] Experiments section: The reported benchmark improvements lack details on statistical significance testing, exact baseline implementations, data splits, and control conditions that isolate the SSL reward signal from generic RL training effects or additional optimization steps. This is load-bearing for the central claim that gains arise specifically from the reformulated intrinsic rewards.
- [Ablations] Ablations on semantic alignment and task difficulty: No control experiment decouples the SSL objective (e.g., rotation prediction succeeding on texture statistics) from the target VL reasoning distribution (e.g., object relations). Without this, it remains possible that observed gains reflect low-level visual regularization rather than improved high-level reasoning alignment.
minor comments (2)
- [Method] The method section would benefit from an explicit equation or pseudocode showing the precise mapping from SSL loss to per-step reward value.
- Figure captions for benchmark results should include error bars or run counts to aid interpretation of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and indicate the changes we will make to strengthen the experimental rigor and clarity of the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The reported benchmark improvements lack details on statistical significance testing, exact baseline implementations, data splits, and control conditions that isolate the SSL reward signal from generic RL training effects or additional optimization steps. This is load-bearing for the central claim that gains arise specifically from the reformulated intrinsic rewards.
Authors: We agree that these details are essential for supporting the central claim. In the revised manuscript we will expand the Experiments section to report results over multiple random seeds with means and standard deviations for statistical significance. We will also provide precise descriptions of baseline implementations (including hyperparameter settings and training protocols), explicitly state the data splits used, and add control experiments that apply standard RL fine-tuning without the SSL-derived rewards. These controls will help isolate the contribution of the reformulated intrinsic rewards from generic optimization effects. revision: yes
-
Referee: [Ablations] Ablations on semantic alignment and task difficulty: No control experiment decouples the SSL objective (e.g., rotation prediction succeeding on texture statistics) from the target VL reasoning distribution (e.g., object relations). Without this, it remains possible that observed gains reflect low-level visual regularization rather than improved high-level reasoning alignment.
Authors: We acknowledge the value of a more targeted control to separate low-level visual statistics from semantic alignment with reasoning tasks. In the revision we will introduce an additional ablation that applies SSL objectives to inputs with disrupted high-level structure (e.g., texture-preserving but relation-disrupting transformations) and compare performance against the original semantically aligned tasks on the VL reasoning benchmarks. The results and discussion will be added to the Ablations section to clarify whether gains arise primarily from high-level alignment or from general visual regularization. revision: yes
Circularity Check
No circularity: SSL rewards derived from independent standard objectives with empirical validation
full rationale
The paper introduces SSL4RL by reformulating established self-supervised tasks (rotation prediction, masked reconstruction) into RL reward signals for VLMs. These objectives pre-exist the target reasoning benchmarks and are not fitted or redefined in terms of the claimed performance gains. Experiments and ablations on benchmarks, task difficulty, and semantic alignment provide external validation rather than reducing the result to a self-referential fit or self-citation chain. No equations or derivations collapse the output to the input by construction, and the framework is presented as a practical paradigm with generality shown on graph learning.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SSL tasks such as rotation prediction and masked patch reconstruction can be reformulated into dense automatic reward signals that align with target VLM reasoning behaviors
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our approach reformulates SSL objectives—such as predicting image rotation or reconstructing masked patches—into dense, automatic reward signals... r=1[ŷ=y]
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We adopt Grouped Reinforcement Policy Optimization (GRPO)... J(θ)=E[R(τ)−βKL...]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
SSL-R1: Self-Supervised Visual Reinforcement Post-Training for Multimodal Large Language Models
SSL-R1 reformulates visual SSL tasks into verifiable puzzles to supply rewards for RL post-training of MLLMs, yielding gains on multimodal benchmarks without external supervision.
-
Boosting Visual Instruction Tuning with Self-Supervised Guidance
Mixing 3-10% of visually grounded self-supervised instructions into visual instruction tuning consistently boosts MLLM performance on vision-centric benchmarks.
-
Visually-Guided Policy Optimization for Multimodal Reasoning
VGPO introduces visual attention compensation and dual-grained advantage re-weighting to reinforce visual focus in VLMs, yielding better activation and performance on multimodal reasoning tasks.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jason Kernion, Jackson Jones, Andy Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Con- stitutional ai: Harmlessness from ai feedback.arXiv:2212.08073, 2022. URLhttps: //arxiv.org/abs/2212.08073
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InICCV,
-
[4]
URLhttps://arxiv.org/abs/2104.14294
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Changyu Chen, Xiting Wang, Ting-En Lin, Ang Lv, Yuchuan Wu, Xin Gao, Ji-Rong Wen, Rui Yan, and Yongbin Li. Masked thought: Simply masking partial reasoning steps can im- prove mathematical reasoning learning of language models. InACL, 2024. URLhttps: //arxiv.org/abs/2403.02178
-
[6]
Humans or llms as the judge? a study on judgement bias
Guanting Chen et al. Humans or llms as the judge? a study on judgement bias. InEMNLP,
-
[7]
URLhttps://aclanthology.org/2024.emnlp-main.474.pdf
work page 2024
-
[8]
Mixed au- toencoder for self-supervised visual representation learning
Kai Chen, Zhili Liu, Lanqing Hong, Hang Xu, Zhenguo Li, and Dit-Yan Yeung. Mixed au- toencoder for self-supervised visual representation learning. InCVPR, 2023
work page 2023
-
[9]
A Simple Framework for Contrastive Learning of Visual Representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InICML, 2020. URLhttps://arxiv. org/abs/2002.05709
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[10]
Xiaokang Chen, Mingyu Ding, Xiaodi Wang, Ying Xin, Shentong Mo, Yunhao Wang, Shumin Han, Ping Luo, Gang Zeng, and Jingdong Wang. Context autoencoder for self-supervised representation learning.International Journal of Computer Vision, 132(1):208–223, 2024
work page 2024
-
[11]
Caparena: Benchmarking and analyzing detailed image captioning in the llm era
Kanzhi Cheng, Wenpo Song, Jiaxin Fan, Zheng Ma, Qiushi Sun, Fangzhi Xu, Chenyang Yan, Nuo Chen, Jianbing Zhang, and Jiajun Chen. Caparena: Benchmarking and analyzing detailed image captioning in the llm era. InACL Findings, 2025
work page 2025
-
[12]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai D...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InCVPR, 2009
work page 2009
-
[14]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InNAACL, 2019. URLhttps: //arxiv.org/abs/1810.04805
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[15]
Carl Doersch, Abhinav Gupta, and Alexei A. Efros. Unsupervised visual representation learn- ing by context prediction. InICCV, 2015. URLhttps://arxiv.org/abs/1505. 05192
work page 2015
-
[16]
Vlmevalkit: An open-source toolkit for evaluating large multi-modality models
Haodong Duan, Junming Yang, Yuxuan Qiao, Xinyu Fang, Lin Chen, Yuan Liu, Xiaoyi Dong, Yuhang Zang, Pan Zhang, Jiaqi Wang, et al. Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. InACM MM, 2024
work page 2024
-
[17]
Jiarui Feng, Hao Liu, Lecheng Kong, Mingfang Zhu, Yixin Chen, and Muhan Zhang. Taglas: An atlas of text-attributed graph datasets in the era of large graph and language models.arXiv preprint arXiv:2406.14683, 2024
-
[18]
Stephanie Fu, Tyler Bonnen, Devin Guillory, and Trevor Darrell. Hidden in plain sight: Vlms overlook their visual representations.arXiv preprint arXiv:2506.08008, 2025
-
[19]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InECCV, 2024
work page 2024
-
[20]
Robust con- trastive learning using negative samples with diminished semantics
Songwei Ge, Shlok Mishra, Chun-Liang Li, Haohan Wang, and David Jacobs. Robust con- trastive learning using negative samples with diminished semantics. InNeurIPS, 2021
work page 2021
-
[21]
Unsupervised representation learning by predicting image rotations
Spyros Gidaris, Praveer Singh, and Nikos Komodakis. Unsupervised representation learning by predicting image rotations. InICLR, 2018. URLhttps://arxiv.org/abs/1803. 07728
work page 2018
-
[22]
Bootstrap your own latent: A new approach to self-supervised learn- ing
Jean-Bastien Grill et al. Bootstrap your own latent: A new approach to self-supervised learn- ing. InNeurIPS, 2020. URLhttps://arxiv.org/abs/2006.07733
-
[23]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InCVPR, 2020. URLhttps://arxiv.org/ abs/1911.05722
-
[24]
Masked Autoencoders Are Scalable Vision Learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll ´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InCVPR, 2022. URLhttps://arxiv.org/ abs/2111.06377
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
Graphmae: Self-supervised masked graph autoencoders
Zhenyu Hou, Xiao Liu, Yukuo Cen, Yuxiao Dong, Hongxia Yang, Chunjie Wang, and Jie Tang. Graphmae: Self-supervised masked graph autoencoders. InKDD, 2022. URLhttps: //arxiv.org/abs/2205.10803
-
[27]
arXiv preprint arXiv:1905.12265 , year=
Weihua Hu, Bowen Liu, Joseph Gomes, Marinka Zitnik, Percy Liang, Vijay Pande, and Jure Leskovec. Strategies for pre-training graph neural networks. InICLR, 2020. URLhttps: //arxiv.org/abs/1905.12265
-
[28]
Visual robustness benchmark for visual ques- tion answering (vqa)
Md Farhan Ishmam, Ishmam Tashdeed, Talukder Asir Saadat, Md Hamjajul Ashmafee, Abu Raihan Mostofa Kamal, and Md Azam Hossain. Visual robustness benchmark for visual ques- tion answering (vqa). InWACV, 2025
work page 2025
-
[29]
Look again, think slowly: Enhancing visual reflection in vision-language models
Pu Jian, Junhong Wu, Wei Sun, Chen Wang, Shuo Ren, and Jiajun Zhang. Look again, think slowly: Enhancing visual reflection in vision-language models. InEMNLP, 2025. 13
work page 2025
-
[30]
Wei Jin, Tyler Derr, Haochen Liu, Yiqi Wang, Suhang Wang, Zitao Liu, and Jiliang Tang. Self-supervised learning on graphs: Deep insights and new direction.arXiv preprint arXiv:2006.10141, 2020
-
[31]
Hard negative mixing for contrastive learning
Yannis Kalantidis, Mert Bulent Sariyildiz, Noe Pion, Philippe Weinzaepfel, and Diane Larlus. Hard negative mixing for contrastive learning. InNeurIPS, 2020
work page 2020
-
[32]
Variational Graph Auto-Encoders
Thomas N Kipf and Max Welling. Variational graph auto-encoders.arXiv preprint arXiv:1611.07308, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[33]
Gotmare, Silvio Savarese, and Steven C.H
Hung Le, Yue Wang, Akhilesh D. Gotmare, Silvio Savarese, and Steven C.H. Hoi. Coderl: Mastering code generation through pretrained models and deep reinforcement learning. In NeurIPS, 2022. URLhttps://arxiv.org/abs/2207.01780
-
[34]
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. InACL, 2020. URLhttps://arxiv.org/abs/1910.13461
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[35]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. Seed- bench: Benchmarking multimodal llms with generative comprehension.arXiv preprint arXiv:2307.16125, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Junnan Li, Ramprasaath R. Selvaraju, Akhilesh D. Gotmare, Shafiq Joty, Caiming Xiong, and Steven Hoi. Align before fuse: Vision and language representation learning with momentum distillation. InNeurIPS, 2021. URLhttps://arxiv.org/abs/2107.07651
- [38]
-
[39]
Mmbench: Is your multi-modal model an all-around player? InECCV, 2024
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InECCV, 2024
work page 2024
-
[40]
Yuhong Liu, Beichen Zhang, Yuhang Zang, Yuhang Cao, Long Xing, Xiaoyi Dong, Haodong Duan, Dahua Lin, and Jiaqi Wang. Spatial-ssrl: Enhancing spatial understanding via self- supervised reinforcement learning.arXiv preprint arXiv:2510.27606, 2025
-
[41]
Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles
Mehdi Noroozi and Paolo Favaro. Unsupervised learning of visual representations by solving jigsaw puzzles. InECCV, 2016. URLhttps://arxiv.org/abs/1603.09246
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[42]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khali- dov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback....
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[44]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InICML,
-
[45]
URLhttps://arxiv.org/abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InNeurIPS, 2023. URLhttps://arxiv.org/abs/2305.18290
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.JMLR, 2020. URLhttps://arxiv.org/abs/1910.10683. 14
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[48]
Is llm-as-a-judge robust? investigating universal adversarial attacks on zero- shot llm assessment
Vasu Raina et al. Is llm-as-a-judge robust? investigating universal adversarial attacks on zero- shot llm assessment. InEMNLP, 2024. URLhttps://aclanthology.org/2024. emnlp-main.427.pdf
work page 2024
-
[49]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[50]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhoujun Shao et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models via grpo.arXiv:2402.03300, 2024. URLhttps://arxiv.org/abs/ 2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, et al. Vlm-r1: A stable and generalizable r1- style large vision-language model.arXiv preprint arXiv:2504.07615, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InNeurIPS,
-
[53]
URLhttps://arxiv.org/abs/2303.11366
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Mer- hej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ram ´e, Morgane Rivi `ere, Louis Rouil- lard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Ga¨el Liu, Francesco Visin, Kathleen Kenealy, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Cambrian-1: A fully open, vision-centric exploration of multimodal llms
Peter Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Adithya Jairam Vedagiri IYER, Sai Charitha Akula, Shusheng Yang, Jihan Yang, Manoj Middepogu, Ziteng Wang, et al. Cambrian-1: A fully open, vision-centric exploration of multimodal llms. InNeurIPS, 2024. 15
work page 2024
-
[56]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang et al. Self-consistency improves chain of thought reasoning in language models. InICLR, 2023. URLhttps://arxiv.org/abs/2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
Self-Instruct: Aligning Language Models with Self-Generated Instructions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instruc- tions. InACL, 2023. URLhttps://arxiv.org/abs/2212.10560
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [58]
-
[59]
V?: Guided visual search as a core mechanism in multimodal llms
Penghao Wu and Saining Xie. V?: Guided visual search as a core mechanism in multimodal llms. InCVPR, 2024
work page 2024
-
[60]
Grok-1.5 vision preview.https://x.ai/news/grok-1.5v, April 2024
xAI. Grok-1.5 vision preview.https://x.ai/news/grok-1.5v, April 2024. URL https://x.ai/news/grok-1.5v. Accessed: [Today’s Date]
work page 2024
-
[61]
Hard negative examples are hard, but useful
Hong Xuan, Abby Stylianou, Xiaotong Liu, and Robert Pless. Hard negative examples are hard, but useful. InECCV, 2020
work page 2020
-
[62]
Graph contrastive learning with augmentations
Yonglong You, Tianlong Chen, Zhangyang Sui, and Yang Wang. Graph contrastive learning with augmentations. InNeurIPS, 2020. URLhttps://proceedings.neurips.cc/ paper/2020/file/3fe230348e9a12c13120749e3f9fa4cd-Paper.pdf
work page 2020
- [63]
-
[64]
Yi-Fan Zhang, Huanyu Zhang, Haochen Tian, Chaoyou Fu, Shuangqing Zhang, Junfei Wu, Feng Li, Kun Wang, Qingsong Wen, Zhang Zhang, et al. Mme-realworld: Could your multi- modal llm challenge high-resolution real-world scenarios that are difficult for humans?arXiv preprint arXiv:2408.13257, 2024. 16 The Use of Large Language Models (LLMs) In this work, LLMs ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
Brown fur covering most of its body: … the overall appearance suggests it had brown fur. 3. Long legs: The fossil shows long legs... Given these observations, the trait that can be clearly observed on the fossil is the rounded ears. Response: To determine which trait Ursus spelaeus had based on the fossil, let's analyze the given options: A. Rounded ears ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.