C3G: Learning Compact 3D Representations with 2K Gaussians
Pith reviewed 2026-05-17 02:03 UTC · model grok-4.3
The pith
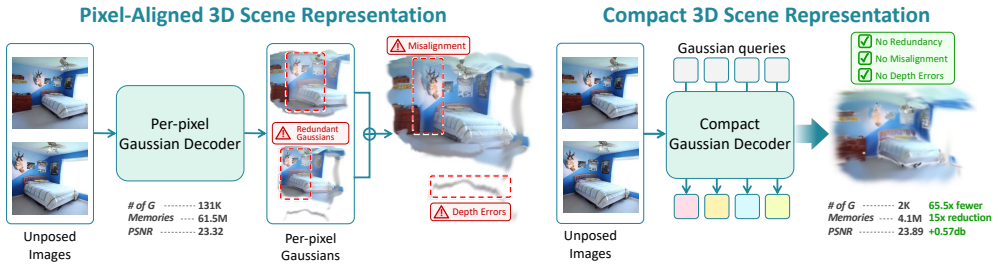
C3G shows that only about 2,000 strategically placed 3D Gaussians suffice for high-quality scene reconstruction and understanding from sparse unposed views.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
C3G estimates compact 3D Gaussians only at essential spatial locations by introducing learnable tokens that aggregate multi-view features through self-attention to guide Gaussian generation, then exploits the learned attention patterns for efficient Gaussian decoding and feature lifting, yielding superior memory efficiency and feature fidelity on pose-free novel view synthesis, 3D open-vocabulary segmentation, and view-invariant feature aggregation.
What carries the argument
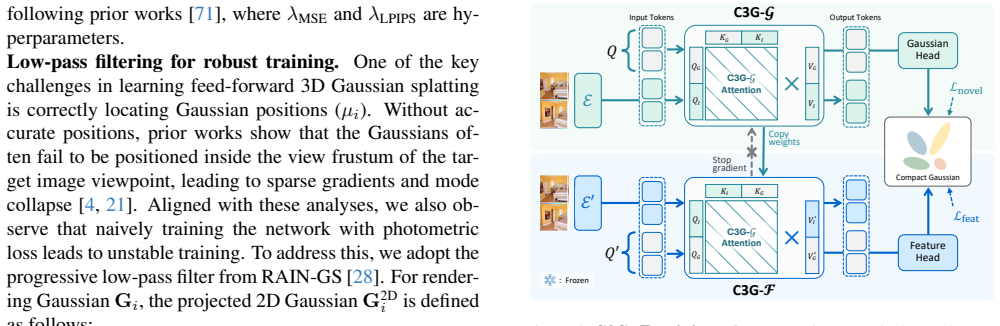
Learnable tokens that aggregate multi-view features via self-attention to guide the generation and decoding of a limited set of 3D Gaussians at essential locations.
If this is right
- High-quality novel view synthesis becomes feasible with orders-of-magnitude lower memory than per-pixel Gaussian methods.
- 3D open-vocabulary segmentation improves through more effective multi-view feature aggregation.
- Feed-forward processing of unposed sparse views requires far less storage while retaining geometric fidelity.
- Redundancy in 3D representations can be eliminated without sacrificing reconstruction or understanding performance.
Where Pith is reading between the lines
- The same token-guided placement strategy could be tested on larger indoor or outdoor scenes to check whether compactness scales beyond the evaluated datasets.
- Attention-driven selection of essential locations may transfer to other sparse-view 3D tasks such as object tracking or surface reconstruction.
- Real-time applications on resource-constrained devices become more plausible once the Gaussian count is fixed near 2K.
Load-bearing premise
That learnable tokens aggregating multi-view features via self-attention can reliably guide Gaussian generation and decoding at essential locations without losing critical geometric details or introducing artifacts from sparse unposed views.
What would settle it
A benchmark comparison on standard datasets where the 2K-Gaussian model produces measurably worse novel-view PSNR or segmentation accuracy than dense per-pixel Gaussian baselines would falsify the sufficiency claim.
Figures












read the original abstract
Reconstructing and understanding 3D scenes from unposed sparse views in a feed-forward manner remains as a challenging task in 3D computer vision. Recent approaches use per-pixel 3D Gaussian Splatting for reconstruction, followed by a 2D-to-3D feature lifting stage for scene understanding. However, they generate excessive redundant Gaussians, causing high memory overhead and sub-optimal multi-view feature aggregation, leading to degraded novel view synthesis and scene understanding performance. We propose C3G, a novel feed-forward framework that estimates compact 3D Gaussians only at essential spatial locations, minimizing redundancy while enabling effective feature lifting. We introduce learnable tokens that aggregate multi-view features through self-attention to guide Gaussian generation, ensuring each Gaussian integrates relevant visual features across views. We then exploit the learned attention patterns for Gaussian decoding to efficiently lift features. Extensive experiments on pose-free novel view synthesis, 3D open-vocabulary segmentation, and view-invariant feature aggregation demonstrate our approach's effectiveness. Results show that a compact yet geometrically meaningful representation is sufficient for high-quality scene reconstruction and understanding, achieving superior memory efficiency and feature fidelity compared to existing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes C3G, a feed-forward framework for 3D scene reconstruction and understanding from unposed sparse views. It generates only 2K compact 3D Gaussians at essential locations by using learnable tokens that aggregate multi-view features via self-attention; these tokens also guide efficient feature lifting for downstream tasks including pose-free novel view synthesis, 3D open-vocabulary segmentation, and view-invariant feature aggregation. The central claim is that this compact yet geometrically meaningful representation suffices for high-quality results while improving memory efficiency and feature fidelity over dense Gaussian methods.
Significance. If the quantitative claims hold, the work establishes that a fixed small number of Gaussians (2K) can replace redundant per-pixel splatting for both reconstruction and semantic tasks in the challenging feed-forward, pose-free regime. This would represent a meaningful advance in memory-efficient 3D vision pipelines and could influence subsequent work on compact scene representations.
major comments (3)
- [§3.2] §3.2 (Learnable Token Aggregation): the self-attention mechanism for multi-view feature aggregation is presented as the key enabler for selecting essential Gaussian locations, yet no analysis or ablation is provided on its behavior under limited view overlap or weak correspondences typical of sparse unposed inputs; this directly bears on whether critical geometric details are preserved or artifacts are introduced in the decoder.
- [§4.1, Table 2] §4.1 and Table 2 (Novel View Synthesis Results): the superiority claim over baselines is stated without reporting absolute metrics (e.g., PSNR, SSIM, LPIPS) or statistical significance across multiple scenes; without these numbers the memory-efficiency advantage cannot be weighed against any potential quality trade-off.
- [§4.3] §4.3 (3D Open-Vocabulary Segmentation): the feature-lifting stage is said to exploit learned attention patterns, but the paper does not quantify how much of the reported mIoU gain is attributable to the compact 2K representation versus the attention guidance itself; an ablation removing the token-guided component would be required to support the central compactness claim.
minor comments (3)
- The abstract asserts 'superior memory efficiency' but does not define the exact memory metric (e.g., peak GPU memory or parameter count) used for comparison.
- Notation for the learnable tokens (e.g., T in Eq. (3)) is introduced without an explicit dimensionality or initialization description, which would aid reproducibility.
- Figure 3 caption refers to 'attention maps' but the figure itself lacks a color scale or legend explaining what the visualized values represent.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We have carefully considered each point and provide detailed responses below. Where appropriate, we will revise the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Learnable Token Aggregation): the self-attention mechanism for multi-view feature aggregation is presented as the key enabler for selecting essential Gaussian locations, yet no analysis or ablation is provided on its behavior under limited view overlap or weak correspondences typical of sparse unposed inputs; this directly bears on whether critical geometric details are preserved or artifacts are introduced in the decoder.
Authors: We agree that further analysis of the self-attention mechanism under conditions of limited view overlap would be valuable. Our current experiments are conducted on datasets featuring sparse, unposed views with naturally occurring limited overlap and weak correspondences. To address this, we will add a new subsection or paragraph in §3.2 discussing the robustness of the attention-based aggregation, supported by qualitative attention visualizations on challenging sparse-view examples. If feasible within page limits, we will also include a targeted ablation on synthetic data with controlled overlap levels. revision: partial
-
Referee: [§4.1, Table 2] §4.1 and Table 2 (Novel View Synthesis Results): the superiority claim over baselines is stated without reporting absolute metrics (e.g., PSNR, SSIM, LPIPS) or statistical significance across multiple scenes; without these numbers the memory-efficiency advantage cannot be weighed against any potential quality trade-off.
Authors: The referee is correct that absolute performance metrics are important for a balanced evaluation. While Table 2 highlights relative gains in memory efficiency and performance, we will update the table and accompanying text in §4.1 to include the absolute values of PSNR, SSIM, and LPIPS for C3G and all baselines. Additionally, we will report mean and standard deviation across multiple scenes to demonstrate statistical significance. revision: yes
-
Referee: [§4.3] §4.3 (3D Open-Vocabulary Segmentation): the feature-lifting stage is said to exploit learned attention patterns, but the paper does not quantify how much of the reported mIoU gain is attributable to the compact 2K representation versus the attention guidance itself; an ablation removing the token-guided component would be required to support the central compactness claim.
Authors: We appreciate this suggestion for clarifying the source of improvements. The central claim of our work is that the compact 2K Gaussian representation, enabled by the learnable tokens and attention, suffices for high-quality results. To better isolate the compactness aspect, we will conduct and report an ablation in the revised manuscript where we replace the compact representation with a dense per-pixel Gaussian baseline while keeping the attention-guided feature lifting. This will help attribute the mIoU gains more precisely. revision: yes
Circularity Check
No significant circularity in derivation; method uses standard attention without self-referential reduction
full rationale
The paper introduces a feed-forward framework for compact 3D Gaussians guided by learnable tokens and self-attention, validated empirically on novel view synthesis and segmentation tasks. No equations, derivations, or load-bearing steps in the abstract or described method reduce predictions to fitted inputs by construction or via self-citation chains. The approach relies on established attention mechanisms and experimental comparisons rather than internal redefinitions or ansatzes smuggled through citations. This yields a self-contained proposal with independent empirical content, consistent with a low circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-attention on multi-view features can produce reliable guidance for Gaussian placement and decoding
invented entities (1)
-
Learnable tokens for multi-view aggregation
no independent evidence
Forward citations
Cited by 6 Pith papers
-
No Pose, No Problem in 4D: Feed-Forward Dynamic Gaussians from Unposed Multi-View Videos
NoPo4D is the first feed-forward system for dynamic 4D Gaussian splatting from unposed multi-view videos, using velocity decomposition supervised by optical flow and a bidirectional motion encoder.
-
PointForward: Feedforward Driving Reconstruction through Point-Aligned Representations
PointForward uses sparse world-space 3D queries and scene graphs to deliver consistent single-pass reconstruction of dynamic driving scenes via point-aligned representations.
-
SplatWeaver: Learning to Allocate Gaussian Primitives for Generalizable Novel View Synthesis
SplatWeaver dynamically allocates Gaussian primitives via cardinality experts and pixel-level routing guided by high-frequency cues for improved generalizable novel view synthesis.
-
SplatWeaver: Learning to Allocate Gaussian Primitives for Generalizable Novel View Synthesis
SplatWeaver uses cardinality Gaussian experts and pixel-level routing to dynamically allocate varying numbers of Gaussian primitives for generalizable novel view synthesis.
-
GlobalSplat: Efficient Feed-Forward 3D Gaussian Splatting via Global Scene Tokens
GlobalSplat achieves competitive novel-view synthesis on RealEstate10K and ACID using only 16K Gaussians via global scene tokens and coarse-to-fine training, with a 4MB footprint and under 78ms inference.
-
Entropy-Gradient Grounding: Training-Free Evidence Retrieval in Vision-Language Models
Entropy-gradient grounding uses model uncertainty to retrieve evidence regions in VLMs, improving performance on detail-critical and compositional tasks across multiple architectures.
Reference graph
Works this paper leans on
-
[1]
Cross-view completion models are zero-shot correspondence estimators
Honggyu An, Jin Hyeon Kim, Seonghoon Park, Jaewoo Jung, Jisang Han, Sunghwan Hong, and Seungryong Kim. Cross-view completion models are zero-shot correspondence estimators. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 1103–1115, 2025. 5
work page 2025
-
[2]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hin- ton. Layer normalization.arXiv preprint arXiv:1607.06450,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Neil Burgess. Spatial memory: how egocentric and allocen- tric combine.Trends in cognitive sciences, 10(12):551–557,
-
[4]
pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction
David Charatan, Sizhe Lester Li, Andrea Tagliasacchi, and Vincent Sitzmann. pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19457–19467, 2024. 3, 4, 5, 11, 14, 15
work page 2024
-
[5]
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images
Yuedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, Tat-Jen Cham, and Jianfei Cai. Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. InEuropean Conference on Computer Vision, pages 370–386. Springer, 2024. 3, 11, 14, 15
work page 2024
-
[6]
Jiahuan Cheng, Jan-Nico Zaech, Luc Van Gool, and Danda Pani Paudel. Occam’s lgs: An efficient ap- proach for language gaussian splatting.arXiv preprint arXiv:2412.01807, 2024. 2, 5
-
[7]
Seokju Cho, Sunghwan Hong, Sangryul Jeon, Yunsung Lee, Kwanghoon Sohn, and Seungryong Kim. Cats: Cost ag- gregation transformers for visual correspondence.Advances in Neural Information Processing Systems, 34:9011–9023,
-
[8]
Seokju Cho, Sunghwan Hong, and Seungryong Kim. Cats++: Boosting cost aggregation with convolutions and transformers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(6):7174–7194, 2022. 12
work page 2022
-
[9]
Cat- seg: Cost aggregation for open-vocabulary semantic seg- mentation
Seokju Cho, Heeseong Shin, Sunghwan Hong, Anurag Arnab, Paul Hongsuck Seo, and Seungryong Kim. Cat- seg: Cost aggregation for open-vocabulary semantic seg- mentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4113– 4123, 2024. 7
work page 2024
-
[10]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017. 7, 8, 9, 11, 12, 17, 18, 19
work page 2017
-
[11]
Learning to render novel views from wide-baseline stereo pairs
Yilun Du, Cameron Smith, Ayush Tewari, and Vincent Sitz- mann. Learning to render novel views from wide-baseline stereo pairs. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4970– 4980, 2023. 3, 7
work page 2023
-
[12]
Roma: Robust dense fea- ture matching
Johan Edstedt, Qiyu Sun, Georg B ¨okman, M ˚arten Wadenb¨ack, and Michael Felsberg. Roma: Robust dense fea- ture matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19790– 19800, 2024. 9
work page 2024
-
[13]
Prob- ing the 3d awareness of visual foundation models
Mohamed El Banani, Amit Raj, Kevis-Kokitsi Maninis, Ab- hishek Kar, Yuanzhen Li, Michael Rubinstein, Deqing Sun, Leonidas Guibas, Justin Johnson, and Varun Jampani. Prob- ing the 3d awareness of visual foundation models. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21795–21806, 2024. 6, 7, 12
work page 2024
-
[14]
Zhiwen Fan, Jian Zhang, Wenyan Cong, Peihao Wang, Renjie Li, Kairun Wen, Shijie Zhou, Achuta Kadambi, Zhangyang Wang, Danfei Xu, et al. Large spatial model: End-to-end unposed images to semantic 3d.Advances in neural information processing systems, 37:40212–40229,
-
[15]
1, 2, 3, 5, 7, 8, 9, 11, 12, 13, 14
-
[16]
arXiv preprint arXiv:2504.00992 , year=
Elisabetta Fedele, Boyang Sun, Leonidas Guibas, Marc Pollefeys, and Francis Engelmann. Superdec: 3d scene de- composition with superquadric primitives.arXiv preprint arXiv:2504.00992, 2025. 2, 4
-
[17]
D^2USt3R: Enhancing 3D Reconstruction with 4D Pointmaps for Dynamic Scenes, April 2025
Jisang Han, Honggyu An, Jaewoo Jung, Takuya Narihira, Junyoung Seo, Kazumi Fukuda, Chaehyun Kim, Sunghwan Hong, Yuki Mitsufuji, and Seungryong Kim. Dˆ 2ust3r: En- hancing 3d reconstruction with 4d pointmaps for dynamic scenes.arXiv preprint arXiv:2504.06264, 2025. 2
-
[18]
Deep matching prior: Test-time optimization for dense correspondence
Sunghwan Hong and Seungryong Kim. Deep matching prior: Test-time optimization for dense correspondence. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9907–9917, 2021. 12
work page 2021
-
[19]
Cost aggregation with 4d convolutional swin transformer for few-shot segmentation
Sunghwan Hong, Seokju Cho, Jisu Nam, Stephen Lin, and Seungryong Kim. Cost aggregation with 4d convolutional swin transformer for few-shot segmentation. InEuropean Conference on Computer Vision, pages 108–126. Springer, 2022
work page 2022
-
[20]
Sunghwan Hong, Jisu Nam, Seokju Cho, Susung Hong, San- gryul Jeon, Dongbo Min, and Seungryong Kim. Neural matching fields: Implicit representation of matching fields for visual correspondence.Advances in Neural Information Processing Systems, 35:13512–13526, 2022
work page 2022
-
[21]
Sunghwan Hong, Seokju Cho, Seungryong Kim, and Stephen Lin. Unifying feature and cost aggregation with transformers for semantic and visual correspondence.arXiv preprint arXiv:2403.11120, 2024. 12
-
[22]
Pf3plat: Pose-free feed-forward 3d gaussian splatting, 2025
Sunghwan Hong, Jaewoo Jung, Heeseong Shin, Jisang Han, Jiaolong Yang, Chong Luo, and Seungryong Kim. Pf3plat: Pose-free feed-forward 3d gaussian splatting.arXiv preprint arXiv:2410.22128, 2024. 2, 3, 5, 11, 14, 15
-
[23]
Unifying cor- respondence pose and nerf for generalized pose-free novel view synthesis
Sunghwan Hong, Jaewoo Jung, Heeseong Shin, Jiaolong Yang, Seungryong Kim, and Chong Luo. Unifying cor- respondence pose and nerf for generalized pose-free novel view synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20196– 20206, 2024. 3, 11, 14, 15
work page 2024
-
[24]
Guichen Huang, Ruoyu Wang, Xiangjun Gao, Che Sun, Yuwei Wu, Shenghua Gao, and Yunde Jia. Longsplat: On- line generalizable 3d gaussian splatting from long sequence images.arXiv preprint arXiv:2507.16144, 2025. 3
-
[25]
No pose at all: Self-supervised pose-free 3d gaussian splatting from sparse 21 views
Ranran Huang and Krystian Mikolajczyk. No pose at all: Self-supervised pose-free 3d gaussian splatting from sparse 21 views. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 27947–27957, 2025. 2, 3, 11, 14, 15
work page 2025
-
[26]
Anysplat: Feed-forward 3d gaussian splatting from unconstrained views, 2025
Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, et al. Anysplat: Feed-forward 3d gaussian splatting from unconstrained views.arXiv preprint arXiv:2505.23716,
-
[27]
Geonerf: Generalizing nerf with geometry priors
Mohammad Mahdi Johari, Yann Lepoittevin, and Franc ¸ois Fleuret. Geonerf: Generalizing nerf with geometry priors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18365–18375, 2022. 3
work page 2022
-
[28]
Kim Jun-Seong, GeonU Kim, Kim Yu-Ji, Yu-Chiang Frank Wang, Jaesung Choe, and Tae-Hyun Oh. Dr. splat: Directly referring 3d gaussian splatting via direct language embed- ding registration. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14137–14146, 2025. 5
work page 2025
-
[29]
Relaxing accurate initialization constraint for 3d gaussian splatting
Jaewoo Jung, Jisang Han, Honggyu An, Jiwon Kang, Seonghoon Park, and Seungryong Kim. Relaxing accurate initialization constraint for 3d gaussian splatting. 2024. 5, 6, 9
work page 2024
-
[30]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1,
-
[31]
Chaehyun Kim, Heeseong Shin, Eunbeen Hong, Heeji Yoon, Anurag Arnab, Paul Hongsuck Seo, Sunghwan Hong, and Seungryong Kim. Seg4diff: Unveiling open-vocabulary seg- mentation in text-to-image diffusion transformers.arXiv preprint arXiv:2509.18096, 2025. 2
-
[32]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF international confer- ence on computer vision, pages 4015–4026, 2023. 14
work page 2023
-
[34]
Cf3: Compact and fast 3d feature fields.arXiv preprint arXiv:2508.05254,
Hyunjoon Lee, Joonkyu Min, and Jaesik Park. Cf3: Compact and fast 3d feature fields.arXiv preprint arXiv:2508.05254,
-
[35]
1, 2, 3, 5, 7, 8, 11, 12, 13
-
[36]
Ground- ing image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and J´erˆome Revaud. Ground- ing image matching in 3d with mast3r. InEuropean Confer- ence on Computer Vision, pages 71–91. Springer, 2024. 3, 6, 9, 11, 14
work page 2024
-
[37]
Language-driven Semantic Segmentation
Boyi Li, Kilian Q Weinberger, Serge Belongie, Vladlen Koltun, and Ren ´e Ranftl. Language-driven semantic seg- mentation.arXiv preprint arXiv:2201.03546, 2022. 6, 7, 8, 11, 12, 13
work page internal anchor Pith review arXiv 2022
-
[38]
Langsplatv2: High- dimensional 3d language gaussian splatting with 450+ fps
Wanhua Li, Yujie Zhao, Minghan Qin, Yang Liu, Yuanhao Cai, Chuang Gan, and Hanspeter Pfister. Langsplatv2: High- dimensional 3d language gaussian splatting with 450+ fps. arXiv preprint arXiv:2507.07136, 2025. 3, 12
-
[39]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 14
work page 2023
-
[40]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024. 14
work page 2024
-
[41]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
David G Lowe. Distinctive image features from scale- invariant keypoints.International journal of computer vi- sion, 60(2):91–110, 2004. 12
work page 2004
-
[43]
Ludvig: Learning-free uplift- ing of 2d visual features to gaussian splatting scenes
Juliette Marrie, Romain M ´en´egaux, Michael Arbel, Diane Larlus, and Julien Mairal. Ludvig: Learning-free uplift- ing of 2d visual features to gaussian splatting scenes. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7440–7450, 2025. 2, 5
work page 2025
-
[44]
Evolsplat: Efficient volume-based gaussian splatting for urban view synthesis
Sheng Miao, Jiaxin Huang, Dongfeng Bai, Xu Yan, Hongyu Zhou, Yue Wang, Bingbing Liu, Andreas Geiger, and Yiyi Liao. Evolsplat: Efficient volume-based gaussian splatting for urban view synthesis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 11286– 11296, 2025. 3
work page 2025
-
[45]
Tom Monnier, Jake Austin, Angjoo Kanazawa, Alexei Efros, and Mathieu Aubry. Differentiable blocks world: Qualitative 3d decomposition by rendering primitives.Advances in Neu- ral Information Processing Systems, 36:5791–5807, 2023. 2
work page 2023
-
[46]
Polyfit: Polygonal surface reconstruction from point clouds
Liangliang Nan and Peter Wonka. Polyfit: Polygonal surface reconstruction from point clouds. InProceedings of the IEEE international conference on computer vision, pages 2353– 2361, 2017. 3
work page 2017
-
[47]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 2, 6, 7, 9, 12, 14
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Superquadrics revisited: Learning 3d shape pars- ing beyond cuboids
Despoina Paschalidou, Ali Osman Ulusoy, and Andreas Geiger. Superquadrics revisited: Learning 3d shape pars- ing beyond cuboids. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 10344–10353, 2019. 2, 4
work page 2019
-
[49]
Learning unsupervised hierarchical part decomposition of 3d objects from a single rgb image
Despoina Paschalidou, Luc Van Gool, and Andreas Geiger. Learning unsupervised hierarchical part decomposition of 3d objects from a single rgb image. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1060–1070, 2020. 2
work page 2020
-
[50]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4195–4205,
-
[51]
Unidepth: Universal monocular metric depth estimation
Luigi Piccinelli, Yung-Hsu Yang, Christos Sakaridis, Mattia Segu, Siyuan Li, Luc Van Gool, and Fisher Yu. Unidepth: Universal monocular metric depth estimation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10106–10116, 2024. 12
work page 2024
-
[52]
Langsplat: 3d language gaussian splatting
Minghan Qin, Wanhua Li, Jiawei Zhou, Haoqian Wang, and Hanspeter Pfister. Langsplat: 3d language gaussian splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20051–20060, 2024. 3, 12 22
work page 2024
-
[53]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 12
work page 2021
-
[54]
Superglue: Learning feature matching with graph neural networks
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superglue: Learning feature matching with graph neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4938–4947, 2020. 12
work page 2020
-
[55]
Structure- from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure- from-motion revisited. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 4104–4113, 2016. 11
work page 2016
-
[56]
William Shen, Ge Yang, Alan Yu, Jansen Wong, Leslie Pack Kaelbling, and Phillip Isola. Distilled feature fields en- able few-shot language-guided manipulation.arXiv preprint arXiv:2308.07931, 2023. 2
-
[57]
Spatialsplat: Efficient semantic 3d from sparse unposed images,
Yu Sheng, Jiajun Deng, Xinran Zhang, Yu Zhang, Bei Hua, Yanyong Zhang, and Jianmin Ji. Spatialsplat: Efficient semantic 3d from sparse unposed images.arXiv preprint arXiv:2505.23044, 2025. 2
-
[58]
Mental rotation of three-dimensional objects.Science, 171(3972):701–703,
Roger N Shepard and Jacqueline Metzler. Mental rotation of three-dimensional objects.Science, 171(3972):701–703,
-
[59]
Heeseong Shin, Chaehyun Kim, Sunghwan Hong, Seokju Cho, Anurag Arnab, Paul Hongsuck Seo, and Seungryong Kim. Towards open-vocabulary semantic segmentation with- out semantic labels.Advances in Neural Information Pro- cessing Systems, 37:9153–9177, 2024. 7
work page 2024
-
[60]
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025. 2, 6, 7, 8, 9, 10, 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs
Brandon Smart, Chuanxia Zheng, Iro Laina, and Vic- tor Adrian Prisacariu. Splatt3r: Zero-shot gaussian splatting from uncalibrated image pairs.arXiv preprint arXiv:2408.13912, 2024. 3, 11, 14, 15
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
The Replica Dataset: A Digital Replica of Indoor Spaces
Julian Straub, Thomas Whelan, Lingni Ma, Yufan Chen, Erik Wijmans, Simon Green, Jakob J Engel, Raul Mur-Artal, Carl Ren, Shobhit Verma, et al. The replica dataset: A digital replica of indoor spaces.arXiv preprint arXiv:1906.05797,
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[63]
Learning shape abstractions by as- sembling volumetric primitives
Shubham Tulsiani, Hao Su, Leonidas J Guibas, Alexei A Efros, and Jitendra Malik. Learning shape abstractions by as- sembling volumetric primitives. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2635–2643, 2017. 2
work page 2017
-
[64]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 2, 3
work page 2017
-
[65]
Vggt: Vi- sual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Vi- sual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025. 2, 3, 4, 6, 7, 8, 9, 10, 11, 12, 14, 15
work page 2025
-
[66]
Ibr- net: Learning multi-view image-based rendering
Qianqian Wang, Zhicheng Wang, Kyle Genova, Pratul P Srinivasan, Howard Zhou, Jonathan T Barron, Ricardo Martin-Brualla, Noah Snavely, and Thomas Funkhouser. Ibr- net: Learning multi-view image-based rendering. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4690–4699, 2021. 3
work page 2021
-
[67]
Dust3r: Geometric 3d vi- sion made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vi- sion made easy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20697– 20709, 2024. 3
work page 2024
-
[68]
Zpressor: Bottleneck-aware compression for scalable feed-forward 3dgs,
Weijie Wang, Donny Y Chen, Zeyu Zhang, Duochao Shi, Akide Liu, and Bohan Zhuang. Zpressor: Bottleneck-aware compression for scalable feed-forward 3dgs.arXiv preprint arXiv:2505.23734, 2025. 3
-
[69]
V olsplat: Rethinking feed-forward 3d gaussian splatting with voxel-aligned prediction,
Weijie Wang, Yeqing Chen, Zeyu Zhang, Hengyu Liu, Haoxiao Wang, Zhiyuan Feng, Wenkang Qin, Zheng Zhu, Donny Y Chen, and Bohan Zhuang. V olsplat: Rethinking feed-forward 3d gaussian splatting with voxel-aligned pre- diction.arXiv preprint arXiv:2509.19297, 2025. 3
-
[70]
Yunsong Wang, Tianxin Huang, Hanlin Chen, and Gim Hee Lee. Freesplat: Generalizable 3d gaussian splatting towards free view synthesis of indoor scenes.Advances in Neural Information Processing Systems, 37:107326–107349, 2024. 3
work page 2024
-
[71]
Anyup: Universal feature upsampling
Thomas Wimmer, Prune Truong, Marie-Julie Rakotosaona, Michael Oechsle, Federico Tombari, Bernt Schiele, and Jan Eric Lenssen. Anyup: Universal feature upsampling. arXiv preprint arXiv:2510.12764, 2025. 8, 9, 12
-
[72]
Murf: multi-baseline radiance fields
Haofei Xu, Anpei Chen, Yuedong Chen, Christos Sakaridis, Yulun Zhang, Marc Pollefeys, Andreas Geiger, and Fisher Yu. Murf: multi-baseline radiance fields. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20041–20050, 2024. 3
work page 2024
-
[73]
No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images
Botao Ye, Sifei Liu, Haofei Xu, Xueting Li, Marc Pollefeys, Ming-Hsuan Yang, and Songyou Peng. No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images.arXiv preprint arXiv:2410.24207, 2024. 2, 3, 4, 5, 7, 9, 11, 14, 15
-
[74]
pixelnerf: Neural radiance fields from one or few images
Alex Yu, Vickie Ye, Matthew Tancik, and Angjoo Kanazawa. pixelnerf: Neural radiance fields from one or few images. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 4578–4587, 2021. 3
work page 2021
-
[75]
Improving 2d feature representations by 3d-aware fine-tuning
Yuanwen Yue, Anurag Das, Francis Engelmann, Siyu Tang, and Jan Eric Lenssen. Improving 2d feature representations by 3d-aware fine-tuning. InEuropean Conference on Com- puter Vision, pages 57–74. Springer, 2024. 7, 9
work page 2024
-
[76]
Karim Abou Zeid, Kadir Yilmaz, Daan de Geus, Alexander Hermans, David Adrian, Timm Linder, and Bastian Leibe. Dino in the room: Leveraging 2d foundation models for 3d segmentation.arXiv preprint arXiv:2503.18944, 2025. 2, 5
-
[77]
Transplat: Generalizable 3d gaussian splatting from sparse multi-view images with transformers
Chuanrui Zhang, Yingshuang Zou, Zhuoling Li, Minmin Yi, and Haoqian Wang. Transplat: Generalizable 3d gaussian splatting from sparse multi-view images with transformers. InProceedings of the AAAI Conference on Artificial Intelli- gence, pages 9869–9877, 2025. 3 23
work page 2025
-
[78]
Shengjun Zhang, Xin Fei, Fangfu Liu, Haixu Song, and Yueqi Duan. Gaussian graph network: Learning efficient and generalizable gaussian representations from multi-view im- ages.Advances in Neural Information Processing Systems, 37:50361–50380, 2024. 3
work page 2024
-
[79]
Diffusion Transformers with Representation Autoencoders
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion transformers with representation autoen- coders.arXiv preprint arXiv:2510.11690, 2025. 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[80]
Extract free dense labels from clip
Chong Zhou, Chen Change Loy, and Bo Dai. Extract free dense labels from clip. InEuropean conference on computer vision, pages 696–712. Springer, 2022. 6, 7, 8, 12
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.