OptiWorld: Optimal Control for Video World Generation under Physical Constraints
Pith reviewed 2026-06-28 19:00 UTC · model grok-4.3
The pith
OptiWorld adds an optimal-control layer at inference time that extracts a world state, plans a physically constrained trajectory on a continuous manifold, and conditions video rendering on the plan.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
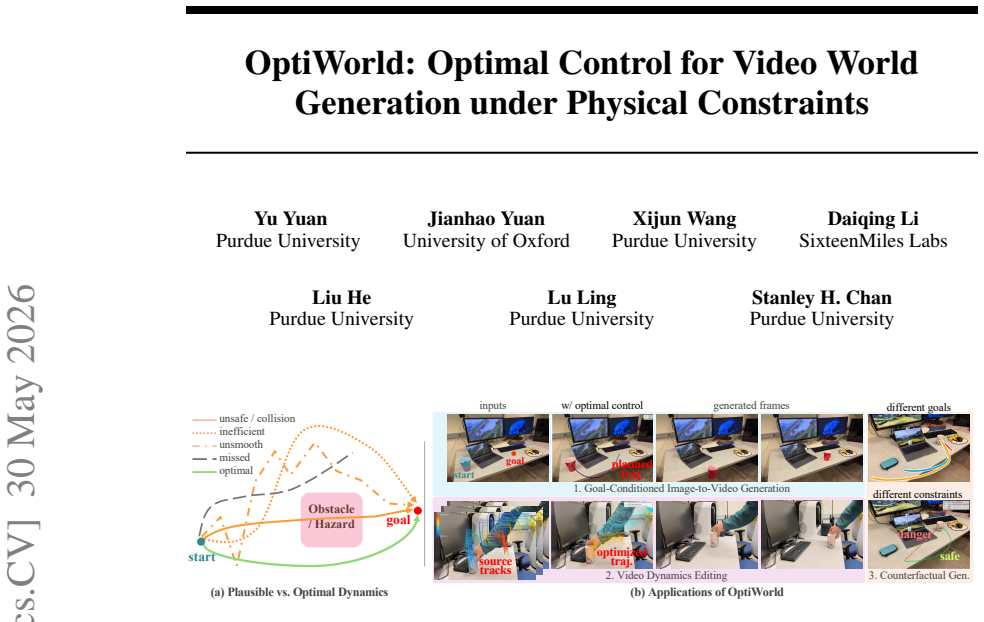
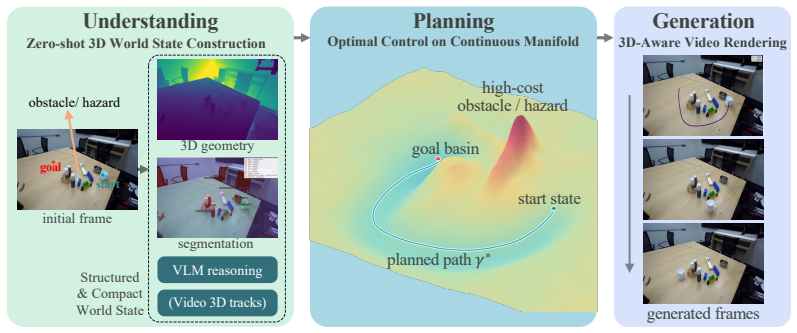
OptiWorld brings classical optimal control into video generation at inference time: it extracts a compact task-relevant world state, formulates planning as a geometric problem on a continuous manifold that encodes both 3D structure and physical constraints, and renders the video conditioned on the resulting optimal trajectory, thereby producing outputs with preferable dynamics across goal-conditioned generation, dynamics editing, and counterfactual tasks.
What carries the argument
The optimal-control layer that converts 3D geometry and task-dependent physical constraints into a unified planning geometry on a continuous manifold.
If this is right
- Goal-conditioned image-to-video generation can produce trajectories that reach specified end states while obeying smoothness and safety constraints.
- Video dynamics editing can adjust an existing clip to follow a new, physically valid path without regenerating the entire sequence from scratch.
- Counterfactual generation can explore alternative physically consistent outcomes from the same initial frames by varying the planned trajectory.
- The same base video model can be reused across multiple control objectives without retraining or fine-tuning.
Where Pith is reading between the lines
- The manifold formulation might allow the same control layer to be ported to other generative domains such as 3D scene synthesis or audio generation.
- If the world-state extraction step proves robust, the method could reduce reliance on physics simulation during training of the underlying video model.
- Real-time interactive applications could become feasible if the geometric planning step can be made fast enough for online trajectory updates.
Load-bearing premise
A compact task-relevant world state can be reliably extracted from the video model and that formulating planning as a geometric problem on a continuous manifold is sufficient to enforce all relevant physical constraints without introducing new inconsistencies.
What would settle it
Generate videos with the control layer active and observe whether the rendered motion still exhibits clear physical violations (such as interpenetration, abrupt velocity changes, or failure to reach stated goals) at a rate comparable to the uncontrolled base model.
Figures







read the original abstract
Video generation models are becoming a scalable form of world models, but they mainly generate plausible motion rather than proactively control or optimize the underlying dynamics. As a result, an object in the generated video may follow trajectories that are unsafe, not smooth, inefficient, or physically inconsistent. In this work, we propose \textbf{OptiWorld}, a framework that brings classical optimal control into video generation at inference time. OptiWorld first extracts a compact, task-relevant world state, then plans an optimal trajectory under physical constraints, and finally renders the video conditioned on this trajectory. We formulate planning as a geometric problem on a continuous manifold, which converts 3D geometry and task-dependent physical constraints into a unified planning geometry. By adding this optimal-control layer, OptiWorld generates videos with preferable dynamics, demonstrating strong potential in multiple tasks including goal-conditioned image-to-video generation, video dynamics editing, and counterfactual generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents OptiWorld, a framework that integrates classical optimal control into video generation at inference time. It extracts a compact, task-relevant world state from the video model, plans an optimal trajectory under physical constraints by formulating the problem as a geometric optimization on a continuous manifold, and then renders the video conditioned on this trajectory. The approach is claimed to produce videos with preferable dynamics and shows potential for goal-conditioned image-to-video generation, video dynamics editing, and counterfactual generation.
Significance. If the proposed method can be shown to reliably extract states and enforce constraints without inconsistencies, it would represent a significant advancement in video world models by enabling optimization of underlying dynamics rather than just plausible motion. This could have broad implications for applications requiring physical consistency in generated videos.
major comments (1)
- [Abstract] Abstract: The central claim that OptiWorld generates videos with preferable dynamics lacks any supporting equations, algorithms, implementation details, or experimental results. Without these, it is impossible to evaluate whether the state extraction is reliable or if the geometric planning on the manifold sufficiently enforces physical constraints, which is load-bearing for the contribution.
Simulated Author's Rebuttal
We thank the referee for their review and comments on our manuscript. Below we provide a point-by-point response to the major comment.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that OptiWorld generates videos with preferable dynamics lacks any supporting equations, algorithms, implementation details, or experimental results. Without these, it is impossible to evaluate whether the state extraction is reliable or if the geometric planning on the manifold sufficiently enforces physical constraints, which is load-bearing for the contribution.
Authors: The abstract is written as a concise summary of the contribution. The full manuscript details the state extraction procedure, formulates the planning problem as geometric optimization on a continuous manifold that unifies 3D geometry with task-dependent physical constraints, describes the inference-time optimal-control layer, and reports experimental results across goal-conditioned image-to-video generation, dynamics editing, and counterfactual tasks that demonstrate videos with preferable dynamics. These elements are presented in the methods and experiments sections and directly support evaluation of state-extraction reliability and constraint enforcement. revision: no
Circularity Check
No significant circularity
full rationale
The provided abstract and description outline a high-level framework that extracts a world state, applies classical optimal control for trajectory planning on a manifold, and conditions video rendering on the result. No equations, algorithms, fitted parameters, or self-citations are present in the visible text that would allow any derivation step to reduce to its own inputs by construction. The central claims invoke external concepts from optimal control and geometry without redefining them in terms of the paper's outputs or renaming known results. This is the expected self-contained case when no load-bearing internal chain is exhibited.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
David Ha and Jürgen Schmidhuber, “World models,”arXiv preprint arXiv:1803.10122, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Towards video world models,
Xun Huang, “Towards video world models,” 2025
2025
-
[3]
Video generation models as world simulators,
OpanAI, “Video generation models as world simulators,” https://openai.com/index/ video-generation-models-as-world-simulators/
-
[4]
Veo 3.1: Our state-of-the-art video generation model,
Google, “Veo 3.1: Our state-of-the-art video generation model,” https://aistudio.google.com/ models/veo-3/, 2025
2025
-
[5]
Seedance 2.0: Advancing Video Generation for World Complexity
Team Seedance, “Seedance 2.0: Advancing video generation for world complexity,”arXiv preprint arXiv:2604.14148, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Team HunyuanWorld, “Hunyuanworld 1.0: Generating immersive, explorable, and interactive 3d worlds from words or pixels,”arXiv preprint arXiv:2507.21809, 2025
-
[7]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, “Wan: Open and advanced large-scale video generative models,”arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Genie 3: A new frontier for world models,
Philip J. Ball, Jakob Bauer, Frank Belletti, Bethanie Brownfield, Ariel Ephrat, Shlomi Fruchter, Agrim Gupta, Kristian Holsheimer, Aleksander Holynski, Jiri Hron, Christos Kaplanis, Marjorie Limont, Matt McGill, Yanko Oliveira, Jack Parker-Holder, Frank Perbet, Guy Scully, Jeremy Shar, Stephen Spencer, Omer Tov, Ruben Villegas, Emma Wang, Jessica Yung, Ci...
2025
-
[9]
Matrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
Zile Wang, Zexiang Liu, Jiaxing Li, Kaichen Huang, Baixin Xu, Fei Kang, Mengyin An, Peiyu Wang, Biao Jiang, Yichen Wei, et al., “Matrix-game 3.0: Real-time and streaming interactive world model with long-horizon memory,”arXiv preprint arXiv:2604.08995, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Lyra 2.0: Explorable Generative 3D Worlds
Tianchang Shen, Sherwin Bahmani, Kai He, Sangeetha Grama Srinivasan, Tianshi Cao, Jiawei Ren, Ruilong Li, Zian Wang, Nicholas Sharp, Zan Gojcic, Sanja Fidler, Jiahui Huang, Huan Ling, Jun Gao, and Xuanchi Ren, “Lyra 2.0: Explorable generative 3d worlds,”arXiv preprint arXiv:2604.13036, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, Ayaan Malik, Kyungmin Lee, William Liang, Nadun Ranawaka, Jiasheng Gu, Yinzhen Xu, Guanzhi Wang, Fengyuan Hu, Avnish Narayan, Johan Bjorck, Jing Wang, Gwanghyun Kim, Dantong Niu, Ruijie Zheng, Yuqi Xie, Jimmy Wu, Qi ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Cosmos World Foundation Model Platform for Physical AI
NVIDIA, “World simulation with video foundation models for physical ai,”arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Cosmos policy: Fine-tuning video models for visuomotor control and planning,
Moo Jin Kim, Yihuai Gao, Tsung-Yi Lin, Yen-Chen Lin, Yunhao Ge, Grace Lam, Percy Liang, Shuran Song, Ming-Yu Liu, Chelsea Finn, and Jinwei Gu, “Cosmos policy: Fine-tuning video models for visuomotor control and planning,” inInternational Conference on Learning Representations (ICLR), 2026
2026
-
[14]
Evaluating gemini robotics policies in a veo world simulator.arXiv preprint arXiv:2512.10675, 2025
Gemini Robotics Team, “Evaluating gemini robotics policies in a veo world simulator,”arXiv preprint arXiv:2512.10675, 2025. 10
-
[15]
Diffusion models are real-time game engines,
Dani Valevski, Yaniv Leviathan, Moab Arar, and Shlomi Fruchter, “Diffusion models are real-time game engines,” inInternational Conference on Learning Representations, 2025
2025
-
[16]
Hunyuan-gamecraft-2: Instruction-following interactive game world model
Junshu Tang, Jiacheng Liu, Jiaqi Li, Longhuang Wu, Haoyu Yang, Penghao Zhao, Siruis Gong, Xiang Yuan, Shuai Shao, and Qinglin Lu, “Hunyuan-gamecraft-2: Instruction-following interactive game world model,”arXiv preprint arXiv:2511.23429, 2025
- [17]
-
[18]
Diffusion for world modeling: Visual details matter in atari,
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, and François Fleuret, “Diffusion for world modeling: Visual details matter in atari,” inThirty-eighth Conference on Neural Information Processing Systems, 2024
2024
-
[19]
Video models are zero-shot learners and reasoners
Thaddäus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos, “Video models are zero-shot learners and reasoners,”arXiv preprint arXiv:2509.20328, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
How far is video generation from world model: A physical law perspective,
Bingyi Kang, Yang Yue, Rui Lu, Zhijie Lin, Yang Zhao, Kaixin Wang, Gao Huang, and Jiashi Feng, “How far is video generation from world model: A physical law perspective,” inInternational Conference on Machine Learning, 2025
2025
-
[21]
Generative physical ai in vision: A survey,
Daochang Liu, Junyu Zhang, Anh-Dung Dinh, Eunbyung Park, Shichao Zhang, and Chang Xu, “Generative physical ai in vision: A survey,” 2025
2025
-
[22]
Do generative video models understand physical principles?,
Saman Motamed, Laura Culp, Kevin Swersky, Priyank Jaini Jaini, and Robert Geirhos, “Do generative video models understand physical principles?,” 2025
2025
-
[23]
Hritik Bansal, Clark Peng, Yonatan Bitton, Roman Goldenberg, Aditya Grover, and Kai-Wei Chang, “VideoPhy-2: A challenging action-centric physical commonsense evaluation in video generation,”arXiv preprint arXiv:2503.06800, 2025
-
[24]
Towards world simulator: Crafting physical commonsense-based benchmark for video generation,
Fanqing Meng, Jiaqi Liao, Xinyu Tan, Wenqi Shao, Quanfeng Lu, Kaipeng Zhang, Cheng Yu, Dianqi Li, Yu Qiao, and Ping Luo, “Towards world simulator: Crafting physical commonsense-based benchmark for video generation,” inInternational Conference on Machine Learning, 2025
2025
-
[25]
Chenyu Zhang, Daniil Cherniavskii, Andrii Zadaianchuk, Antonios Tragoudaras, Antonios V ozikis, Thij- men Nijdam, Derck W. E. Prinzhorn, Mark Bodracska, Nicu Sebe, and Efstratios Gavves, “Morpheus: Benchmarking physical reasoning of video generative models with real physical experiments,”arXiv preprint arXiv:2504.02918, 2025
-
[26]
Pisa experiments: Exploring physics post-training for video diffusion models by watching stuff drop,
Chenyu Li, Oscar Michel, Xichen Pan, Sainan Liu, Mike Roberts, and Saining Xie, “Pisa experiments: Exploring physics post-training for video diffusion models by watching stuff drop,” inInternational Conference on Machine Learning, 2025
2025
-
[27]
World-in-world: World models in a closed-loop world,
Jiahan Zhang, Muqing Jiang, Nanru Dai, Taiming Lu, Arda Uzunoglu, Shunchi Zhang, Yana Wei, Jiahao Wang, Vishal M. Patel, Paul Pu Liang, Daniel Khashabi, Cheng Peng, Rama Chellappa, Tianmin Shu, Alan Yuille, Yilun Du, and Jieneng Chen, “World-in-world: World models in a closed-loop world,”arXiv preprint arXiv:2510.18135, 2025
-
[28]
Gpt4motion: Scripting physical motions in text-to-video generation via blender-oriented gpt planning,
Jiaxi Lv, Yi Huang Huang, Mingfu Yan, Jiancheng Huang, Jianzhuang Liu, Yifan Liu Liu, Yafei Wen, Xiaoxin Chen, and Shifeng Chen, “Gpt4motion: Scripting physical motions in text-to-video generation via blender-oriented gpt planning,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[29]
Xindi Yang, Baolu Li, Yiming Zhang, Zhenfei Yin, Lei Bai, Liqian Ma, Zhiyong Wang, Jianfei Cai, Tien-Tsin Wong, Huchuan Lu, and Xu Jia, “Vlipp: Towards physically plausible video generation with vision and language informed physical prior,”arXiv preprint arXiv:2503.23368, 2025
-
[30]
Motion modes: What could happen next?,
Karran Pandey, Matheus Gadelha, Yannick Hold-Geoffroy, Karan Singh, Niloy J. Mitra, and Paul Guerrero, “Motion modes: What could happen next?,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[31]
PhyT2V: Llm-guided iterative self-refinement for physics-grounded text-to-video generation,
Qiyao Xue, Xiangyu Yin, Boyuan Yang, and Wei Gao, “PhyT2V: Llm-guided iterative self-refinement for physics-grounded text-to-video generation,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. 11
2025
-
[32]
WISA: World simulator assistant for physics- aware text-to-video generation,
Jing Wang, Ao Ma, Ke Cao, Jun Zheng, Zhanjie Zhang, Jiasong Feng, Shanyuan Liu, Yuhang Ma, Bo Cheng, Dawei Leng, Yuhui Yin, and Xiaodan Liang, “WISA: World simulator assistant for physics- aware text-to-video generation,”arXiv preprint arXiv:2502.08153, 2025
-
[33]
Videojam: Joint appearance-motion representations for enhanced motion generation in video models,
Hila Chefer, Uriel Singer, Amit Zohar, Yuval Kirstain, Adam Polyak, Yaniv Taigman, Lior Wolf, and Shelly Sheynin, “Videojam: Joint appearance-motion representations for enhanced motion generation in video models,”arXiv preprint arXiv:2502.02492, 2025
-
[34]
arXiv preprint arXiv:2509.21309 (2025) 4
Yu Yuan, Xijun Wang, Tharindu Wickremasinghe, Zeeshan Nadir, Bole Ma, and Stanley H. Chan, “NewtonGen: Physics-consistent and controllable text-to-video generation via neural newtonian dynamics,” arXiv preprint arXiv: 2509.21309, 2025
-
[35]
SeeU: Seeing the unseen world via 4d dynamics-aware generation,
Yu Yuan, Tharindu Wickremasinghe, Zeeshan Nadir, Xijun Wang, Yiheng Chi, and Stanley H. Chan, “SeeU: Seeing the unseen world via 4d dynamics-aware generation,”arXiv preprint arXiv: 2512.03350, 2025
-
[36]
Stengel,Optimal Control and Estimation, Dover Publications, New York, USA, 1994
Robert F. Stengel,Optimal Control and Estimation, Dover Publications, New York, USA, 1994
1994
-
[37]
Levitor: 3d trajectory oriented image-to-video synthesis,
Hanlin Wang, Hao Ouyang, Qiuyu Wang, Wen Wang, Ka Leong Cheng, Qifeng Chen, Yujun Shen, and Limin Wang, “Levitor: 3d trajectory oriented image-to-video synthesis,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[38]
Go-with-the-flow: Motion-controllable video diffusion models using real-time warped noise,
Ryan Burgert, Yuancheng Xu, Wenqi Xian, Oliver Pilarski, Pascal Clausen, Mingming He, Li Ma, Yitong Deng, Lingxiao Li, Mohsen Mousavi, Michael Ryoo, Paul Debevec, and Ning Yu, “Go-with-the-flow: Motion-controllable video diffusion models using real-time warped noise,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[39]
Diffusion as shader: 3d-aware video diffusion for versatile video generation control,
Zekai Gu, Rui Yan, Jiahao Lu, Peng Li, Zhiyang Dou, Chenyang Si, Zhen Dong, Qifeng Liu, Cheng Lin, Ziwei Liu, Wenping Wang, and Yuan Liu, “Diffusion as shader: 3d-aware video diffusion for versatile video generation control,”arXiv preprint arXiv:2501.03847, 2025
-
[40]
arXiv preprint arXiv:2505.22944 (2025) 12
Angtian Wang, Haibin Huang, Zhiyuan Fang, Yiding Yang, and Chongyang Ma, “ATI: Any trajectory instruction for controllable video generation,”arXiv preprint arXiv:2505.22944, 2025
-
[41]
Yingjie Chen, Yifang Men, Yuan Yao, Miaomiao Cui, and Liefeng Bo, “Perception-as-control: Fine-grained controllable image animation with 3d-aware motion representation,”arXiv preprint arXiv:2501.05020, 2025
-
[42]
Motioncanvas: Cinematic shot design with controllable image-to-video generation,
Jinbo Xing, Long Mai, Cusuh Ham, Jiahui Huang, Aniruddha Mahapatra, Chi-Wing Fu, Tien-Tsin Wong, and Feng Liu, “Motioncanvas: Cinematic shot design with controllable image-to-video generation,”arXiv preprint arXiv:2502.04299, 2025
-
[43]
Generative video motion editing with 3d point tracks,
Yao-Chih Lee, Zhoutong Zhang, Jiahui Huang, Jui-Hsien Wang, Joon-Young Lee, Jia-Bin Huang, Eli Shechtman, and Zhengqi Li, “Generative video motion editing with 3d point tracks,”arXiv preprint arXiv:2512.02015, 2025
-
[44]
Motionv2v: Editing motion in a video,
Ryan Burgert, Charles Herrmann, Forrester Cole, Michael S Ryoo, Neal Wadhwa, Andrey V oynov, and Nataniel Ruiz, “Motionv2v: Editing motion in a video,”arXiv preprint arXiv:2511.20640, 2025
-
[45]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, and Jiaolong Yang, “Moge-2: Accurate monocular geometry with metric scale and sharp details,” arXiv preprint arXiv:2507.02546, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shubham Debnath, Ronghang Hu, Dídac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Anqi Huang, Jiawen Lei, Tengyu Ma, Bowen Guo, Aditya Kalla, Matthew Marks, John Greer, Muxin Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Eleni Mavroudi, Kuan Xu, Tsung-Han Wu, Yitian Zhou, Lily Momeni, R...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Qwen2.5-vl,
Qwen Team, “Qwen2.5-vl,” 2025
2025
-
[48]
Yuze Wu, Mo Zhu, Xingxing Li, Yuheng Du, Yuxin Fan, Wenjun Li, Zhichao Han, Xin Zhou, and Fei Gao, “VLA-AN: An efficient and onboard vision-language-action framework for aerial navigation in complex environments,”arXiv preprint arXiv:2512.15258, 2025
-
[49]
Diffog: Differentiable policy trajectory optimization with generalizability,
Zhengtong Xu, Zichen Miao, Qiang Qiu, Zhe Zhang, and Yu She, “Diffog: Differentiable policy trajectory optimization with generalizability,”IEEE Transactions on Robotics, 2026. 12
2026
-
[50]
Sampling-based algorithms for optimal motion planning,
Sertac Karaman and Emilio Frazzoli, “Sampling-based algorithms for optimal motion planning,”The International Journal of Robotics Research (IJRR), 2011
2011
-
[51]
A formal basis for the heuristic determination of minimum cost paths,
Peter E. Hart, Nils J. Nilsson, and Bertram Raphael, “A formal basis for the heuristic determination of minimum cost paths,”IEEE Transactions on Systems Science and Cybernetics, 1968
1968
-
[52]
Rawlings, D.Q
J. Rawlings, D.Q. Mayne, and Moritz Diehl,Model Predictive Control: Theory, Computation, and Design, 2017
2017
-
[53]
Francesco Bullo and Andrew D Lewis,Geometric control of mechanical systems: modeling, analysis, and design for simple mechanical control systems, 2005
2005
-
[54]
Denoising diffusion probabilistic models,
Jonathan Ho, Ajay Jain, and Pieter Abbeel, “Denoising diffusion probabilistic models,” inAdvances in Neural Information Processing Systems, 2020, p. 6840–6851
2020
-
[55]
Score-based generative modeling through stochastic differential equations,
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole, “Score-based generative modeling through stochastic differential equations,” inInternational Conference on Learning Representations, 2021
2021
-
[56]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei, “Scaling laws for neural language models,”arXiv preprint arXiv: 2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[57]
Scalable diffusion models with transformers,
William Peebles and Saining Xie, “Scalable diffusion models with transformers,” inInternational Conference on Computer Vision, 2023
2023
-
[58]
Cogvideox: Text-to-video diffusion models with an expert transformer,
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al., “Cogvideox: Text-to-video diffusion models with an expert transformer,” inInternational Conference on Learning Representations, 2025
2025
-
[59]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al., “Hunyuanvideo: A systematic framework for large video generative models,”arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
Haoyi Duan, Hong-Xing Yu, Sirui Chen, Li Fei-Fei, and Jiajun Wu, “WorldScore: A unified evaluation benchmark for world generation,”arXiv preprint arXiv:2504.00983, 2025
-
[61]
Likephys: Evaluating intuitive physics understanding in video diffusion models via likelihood preference,
Jianhao Yuan, Fabio Pizzati, Francesco Pinto, Lars Kunze, Ivan Laptev, Paul Newman, Philip Torr, and Daniele De Martini, “Likephys: Evaluating intuitive physics understanding in video diffusion models via likelihood preference,” inInternational Conference on Learning Representations, 2026
2026
-
[62]
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang, “Camer- aCtrl: Enabling camera control for text-to-video generation,”arXiv preprint arXiv:2404.02101, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
CamCo: Camera-Controllable 3D-Consistent Image-to-Video Generation
Dejia Xu, Weili Nie, Chao Liu, Sifei Liu, Jan Kautz, Zhangyang Wang, and Arash Vahdat, “CamCo: Camera-controllable 3d-consistent image-to-video generation,”arXiv preprint arXiv:2406.02509, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
Training-free camera control for video generation,
Chen Hou, Guoqiang Wei, Yan Zeng, and Zhibo Chen, “Training-free camera control for video generation,” arXiv preprint arXiv:2406.10126, 2024
-
[65]
Cavia: Camera-controllable multi-view video diffusion with view-integrated attention,
Dejia Xu, Yifan Jiang, Chen Huang, Liangchen Song, Thorsten Gernoth, Liangliang Cao, Zhangyang Wang, and Hao Tang, “Cavia: Camera-controllable multi-view video diffusion with view-integrated attention,”arXiv preprint arXiv:2410.10774, 2024
-
[66]
Motionctrl: A unified and flexible motion controller for video generation,
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan, “Motionctrl: A unified and flexible motion controller for video generation,” inACM SIGGRAPH 2024 Conference Papers, 2024, pp. 1–11
2024
-
[67]
E.T. the exceptional trajec- tories: Text-to-camera-trajectory generation with character awareness,
Robin Courant, Nicolas Dufour, Xi Wang, Marc Christie, and Vicky Kalogeiton, “E.T. the exceptional trajec- tories: Text-to-camera-trajectory generation with character awareness,”arXiv preprint arXiv:2407.01516, 2024
-
[68]
Tora: Trajectory-oriented diffusion transformer for video generation,
Zhenghao Zhang, Junchao Liao, Menghao Li, Zuozhuo Dai, Bingxue Qiu, Siyu Zhu, Long Qin, and Weizhi Wang, “Tora: Trajectory-oriented diffusion transformer for video generation,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[69]
Tora2: Motion and appearance customized diffusion transformer for multi-entity video generation,
Zhenghao Zhang, Junchao Liao, Xiangyu Meng, Long Qin, and Weizhi Wang, “Tora2: Motion and appearance customized diffusion transformer for multi-entity video generation,” inACM International Conference on Multimedia, 2025. 13
2025
-
[70]
Motion prompting: Controlling video generation with motion trajectories,
Daniel Geng, Charles Herrmann, Junhwa Hur, Forrester Cole, Serena Zhang, Tobias Pfaff, Tatiana Lopez- Guevara, Carl Doersch, Yusuf Aytar, Michael Rubinstein, Chen Sun, Oliver Wang, Andrew Owens, and Deqing Sun, “Motion prompting: Controlling video generation with motion trajectories,”arXiv preprint arXiv:2412.02700, 2024
-
[71]
Phys4dgen: Physics-compliant 4d generation with multi-material composition perception
Jiajing Lin, Zhenzhong Wang, Shu Jiang, Yongjie Hou, and Min Jiang, “Phys4dgen: A physics-driven framework for controllable and efficient 4d content generation from a single image,”arXiv preprint arXiv:2411.16800, 2024
-
[72]
Physgaus- sian: Physics-integrated 3d gaussians for generative dynamics,
Tianyi Xie, Zeshun Zong, Yuxing Qiu, Xuan Li, Yutao Feng, Yin Yang, and Chenfanfu Jiang, “Physgaus- sian: Physics-integrated 3d gaussians for generative dynamics,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[73]
Physmotion: Physics-grounded dynamics from a single image,
Xiyang Tan, Ying Jiang, Xuan Li, Zeshun Zong, Tianyi Xie, Yin Yang, and Chenfanfu Jiang, “Physmotion: Physics-grounded dynamics from a single image,”arXiv preprint arXiv:2411.17189, 2024
-
[74]
PhysDreamer: Physics-based interaction with 3d objects via video generation,
Tianyuan Zhang, Hong-Xing Yu, Rundi Wu, Brandon Y . Feng, Changxi Zheng, Noah Snavely, Jiajun Wu, and William T. Freeman, “PhysDreamer: Physics-based interaction with 3d objects via video generation,” inEuropean Conference on Computer Vision, 2024
2024
-
[75]
Autovfx: Physically realistic video editing from natural language instructions,
Hao-Yu Hsu, Zhi-Hao Lin, Albert Zhai, Hongchi Xia, and Shenlong Wang, “Autovfx: Physically realistic video editing from natural language instructions,”arXiv preprint arXiv:2411.02394, 2024
-
[76]
Physdiff: Physics-guided human motion diffusion model,
Ye Yuan, Jiaming Song, Umar Iqbal, Arash Vahdat, and Jan Kautz, “Physdiff: Physics-guided human motion diffusion model,” inInternational Conference on Computer Vision, 2023
2023
-
[77]
Physgen: Rigid-body physics- grounded image-to-video generation,
Shaowei Liu, Zhongzheng Ren, Saurabh Gupta, and Shenlong Wang, “Physgen: Rigid-body physics- grounded image-to-video generation,” inEuropean Conference on Computer Vision, 2024
2024
-
[78]
Motioncraft: Physics-based zero-shot video generation,
Luca Savant Aira, Antonio Montanaro, Emanuele Aiello, Diego Valsesia, and Enrico Magli, “Motioncraft: Physics-based zero-shot video generation,” inAdvances in Neural Information Processing Systems, 2024
2024
-
[79]
Physgen3d: Crafting a miniature interactive world from a single image,
Boyuan Chen, Hanxiao Jiang, Shaowei Liu, Saurabh Gupta, Yunzhu Li, Hao Zhao, and Shenlong Wang, “Physgen3d: Crafting a miniature interactive world from a single image,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[80]
Physanimator: Physics-guided generative cartoon animation,
Tianyi Xie, Yiwei Zhao, Ying Jiang, and Chenfanfu Jiang, “Physanimator: Physics-guided generative cartoon animation,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.