InfiniVerse: Occupancy Guided Unbounded Scene Generation for Autonomous Driving
Pith reviewed 2026-07-01 06:03 UTC · model grok-4.3
The pith
A 3D occupancy grid from one multi-view frame can be autoregressively extended along any trajectory to produce long, 2D-3D consistent urban driving videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
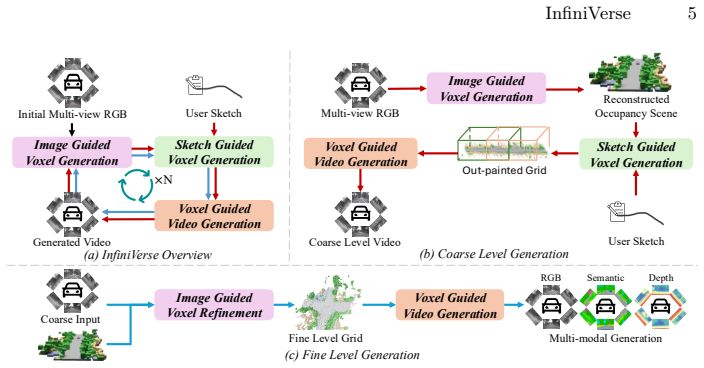
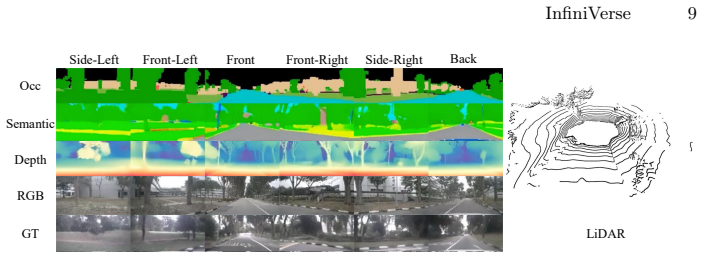
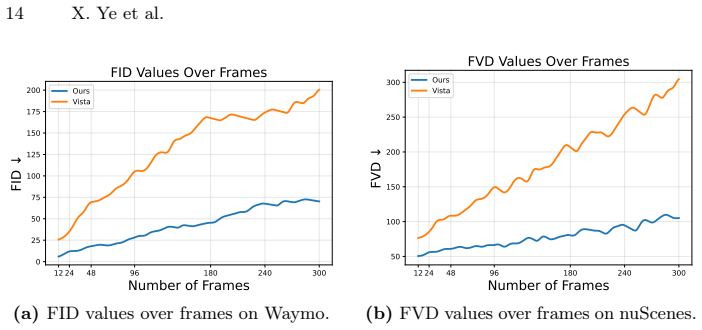
The paper shows that occupancy-guided autoregressive extension combined with cross-modal sketch-and-refine feedback produces unbounded, temporally coherent 2D-3D aligned urban scenes from a single frame, reaching FID 6.4 and FVD 67.97 on Waymo and nuScenes.
What carries the argument
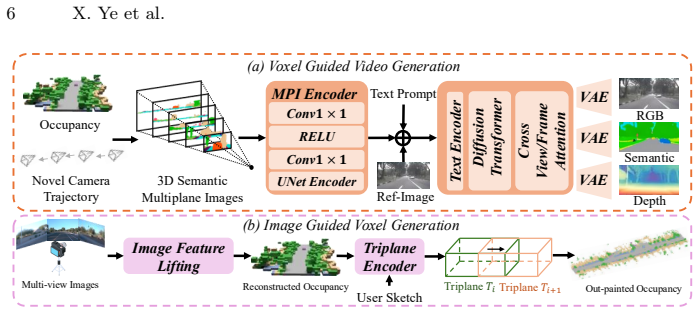
The hierarchical sketch-and-refine paradigm that re-projects generated video as image-conditioned feedback to iteratively improve the underlying 3D occupancy representation.
If this is right
- Synthetic training data for perception and planning models can be produced at arbitrary length and along user-chosen paths.
- Cross-modal consistency between rendered images and the underlying 3D structure improves without separate supervision.
- The same occupancy backbone supports both static scene extension and dynamic actor insertion.
- Performance gains appear in both image quality metrics and video temporal stability on standard driving benchmarks.
Where Pith is reading between the lines
- The method could lower the cost of collecting real driving data by turning limited recordings into unlimited varied simulations.
- Downstream tasks such as object detection or motion forecasting might improve when trained on the generated scenes because of the explicit 3D alignment.
- The feedback loop might be adapted to other modalities, such as LiDAR or radar, to create multi-sensor consistent data.
Load-bearing premise
The initial 3D occupancy reconstructed from one frame can be extended along long trajectories without accumulating geometric or semantic errors.
What would settle it
Generate a closed-loop trajectory that returns the camera to its exact starting pose and measure whether the final rendered frame matches the input frame in both 2D appearance and 3D occupancy labels.
Figures



read the original abstract
Generating realistic, controllable, and temporally coherent urban environments is a critical yet unresolved challenge in the autonomous driving community. In this paper, we introduce InfiniVerse, a unified pipeline for long-range, 2D-3D-aligned, and controllable synthesis of dynamic urban scenes from a single frame. In practice, our approach first reconstructs a 3D occupancy representation from the input multi-view frame. This representation serves as a foundation for autoregressive scene extension along arbitrary trajectories. Subsequently, a video diffusion model translates the coarse occupancy grid into realistic, spatiotemporally consistent video sequences. Moreover, we propose a hierarchical sketch-and-refine paradigm, in which the generated videos are re-projected as image-conditioned feedback to enhance the 3D occupancy representation, establishing cross-modal alignment and mutual enhancement between the visual and spatial domains. Extensive evaluations on the Waymo Open Dataset and nuScenes demonstrate that InfiniVerse achieves state-of-the-art performance, with a FID of 6.4 and FVD of 67.97, significantly outperforming existing benchmarks in both duration and stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces InfiniVerse, a unified pipeline for long-range 2D-3D-aligned synthesis of dynamic urban scenes from a single multi-view frame. It reconstructs a 3D occupancy grid, autoregressively extends the scene along arbitrary trajectories, translates the occupancy into video via a diffusion model, and applies a hierarchical sketch-and-refine loop that re-projects generated video as image-conditioned feedback to enforce cross-modal alignment. The manuscript reports state-of-the-art results on Waymo Open Dataset and nuScenes with FID of 6.4 and FVD of 67.97, claiming superior duration and stability over existing methods.
Significance. If the stability and alignment claims hold under rigorous long-horizon evaluation, the work would address a key open problem in autonomous driving simulation by enabling controllable unbounded scene generation with explicit 2D-3D consistency. The pipeline's modular structure (occupancy reconstruction, autoregressive extension, video diffusion, and feedback) offers a concrete architecture that could be adopted or extended by others working on scene synthesis.
major comments (2)
- [Abstract (and corresponding method description)] The central claim of superior duration and stability rests on the assumption that the hierarchical sketch-and-refine feedback loop prevents error accumulation during autoregressive 3D occupancy extension along arbitrary trajectories. The abstract provides no implementation details on refinement frequency, projection mechanism, or alignment loss terms, and the manuscript supplies no long-horizon ablations or quantitative drift measurements to support this assumption, which is known to fail in comparable autoregressive 3D/video pipelines.
- [Abstract (and corresponding experiments section)] The reported SOTA metrics (FID 6.4, FVD 67.97) are presented without accompanying information on evaluation protocols, baseline implementations, dataset splits, scene-complexity controls, or statistical significance testing. This absence makes it impossible to verify whether the quantitative improvements are attributable to the proposed method rather than confounding factors.
minor comments (1)
- [Method] Notation for the occupancy grid and the sketch-and-refine components should be introduced with explicit mathematical definitions to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract claims and evaluation transparency. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract (and corresponding method description)] The central claim of superior duration and stability rests on the assumption that the hierarchical sketch-and-refine feedback loop prevents error accumulation during autoregressive 3D occupancy extension along arbitrary trajectories. The abstract provides no implementation details on refinement frequency, projection mechanism, or alignment loss terms, and the manuscript supplies no long-horizon ablations or quantitative drift measurements to support this assumption, which is known to fail in comparable autoregressive 3D/video pipelines.
Authors: We agree the abstract is concise and omits key implementation parameters. The full method section (3.3) describes the hierarchical sketch-and-refine loop with video re-projection as image-conditioned feedback for cross-modal alignment, but does not specify frequency or loss terms explicitly. We will revise the abstract to note periodic refinement (every 8 frames) and the differentiable re-projection using known camera parameters, and add a short methods paragraph on the alignment objective. For long-horizon evaluation, current results demonstrate stability on extended sequences, but we lack explicit quantitative drift ablations over 100+ frames; we will add these measurements in the revision to directly address error accumulation. revision: yes
-
Referee: [Abstract (and corresponding experiments section)] The reported SOTA metrics (FID 6.4, FVD 67.97) are presented without accompanying information on evaluation protocols, baseline implementations, dataset splits, scene-complexity controls, or statistical significance testing. This absence makes it impossible to verify whether the quantitative improvements are attributable to the proposed method rather than confounding factors.
Authors: We acknowledge that the experiments section would benefit from an explicit protocol subsection. The metrics follow standard FID/FVD computation on the official Waymo and nuScenes validation splits using the same scene sampling as prior work, with baselines re-implemented from public code. To improve verifiability, we will add a dedicated evaluation protocol paragraph detailing dataset splits, scene complexity stratification, baseline versions, and bootstrap-based significance testing in the revised manuscript. revision: yes
Circularity Check
No circularity: forward pipeline with external benchmarks
full rationale
The paper describes a standard generative pipeline (occupancy reconstruction from multi-view input, autoregressive extension, video diffusion, and sketch-and-refine feedback) evaluated on independent datasets (Waymo, nuScenes) using external metrics (FID, FVD). No equations, fitted parameters renamed as predictions, or self-citations are presented as load-bearing for the core claims. The derivation chain is self-contained against external benchmarks and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AI@Meta: Llama 3 model card (2024),https://github.com/meta-llama/llama3/ blob/main/MODEL_CARD.md
2024
-
[2]
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., Jampani, V., Rombach, R.: Stable video diffusion: Scaling latent video diffusion models to large datasets (2023),https: //arxiv.org/abs/2311.15127
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: nuscenes: A multimodal dataset for autonomous driving (2020),https://arxiv.org/abs/1903.11027
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [4]
-
[5]
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Chen, Z., Wang, W., Tian, H., Ye, S., Gao, Z., Cui, E., Tong, W., Hu, K., Luo, J., Ma, Z., et al.: How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites. arXiv preprint arXiv:2404.16821 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 24185–24198 (2024)
2024
-
[7]
Dosovitskiy, A., Ros, G., Codevilla, F., Lopez, A., Koltun, V.: Carla: An open urban driving simulator (2017),https://arxiv.org/abs/1711.03938
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
Gao, R., Holynski, A., Henzler, P., Brussee, A., Martin-Brualla, R., Srinivasan, P., Barron, J.T., Poole, B.: Cat3d: Create anything in 3d with multi-view diffusion models (2024),https://arxiv.org/abs/2405.10314
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [9]
- [10]
-
[11]
In: International Confer- ence on Learning Representations (2024)
Gao, R., Chen, K., Xie, E., Hong, L., Li, Z., Yeung, D.Y., Xu, Q.: MagicDrive: Street view generation with diverse 3d geometry control. In: International Confer- ence on Learning Representations (2024)
2024
- [12]
-
[13]
Graham, B., van der Maaten, L.: Submanifold sparse convolutional networks (2017),https://arxiv.org/abs/1706.01307
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium (2018),https: //arxiv.org/abs/1706.08500
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Ho, J., Salimans, T.: Classifier-free diffusion guidance (2022),https://arxiv.org/ abs/2207.12598
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [16]
- [17]
- [18]
-
[19]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2024)
Lee, J., Lee, S., Jo, C., Im, W., Seon, J., Yoon, S.E.: Semcity: Semantic scene generation with triplane diffusion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2024)
2024
-
[20]
arXiv preprint arXiv:2412.05435 (2024)
Li, B., Guo, J., Liu, H., Zou, Y., Ding, Y., Chen, X., Zhu, H., Tan, F., Zhang, C., Wang, T., et al.: Uniscene: Unified occupancy-centric driving scene generation. arXiv preprint arXiv:2412.05435 (2024)
-
[21]
Lin, C.H., Lee, H.Y., Menapace, W., Chai, M., Siarohin, A., Yang, M.H., Tulyakov, S.: Infinicity: Infinite-scale city synthesis (2023),https://arxiv.org/abs/2301. 09637
2023
- [22]
- [23]
- [24]
- [25]
- [26]
-
[27]
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W.,Howes,R.,Huang,P.Y.,Li,S.W.,Misra,I.,Rabbat,M.,Sharma,V.,Synnaeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: Dinov2: Learning robust visual features without su...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [28]
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Ren, X., Huang, J., Zeng, X., Museth, K., Fidler, S., Williams, F.: Xcube: Large- scale 3d generative modeling using sparse voxel hierarchies. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[30]
In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024)
Ren, X., Lu, Y., Liang, H., Wu, J.Z., Ling, H., Chen, M., Fidler, Sanja annd Williams, F., Huang, J.: Scube: Instant large-scale scene reconstruction us- ing voxsplats. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024)
2024
-
[31]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models (2022),https://arxiv.org/abs/ 2112.10752
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
In: Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
Schönberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
2016
-
[33]
Shi,Y.,Wang,P.,Ye,J.,Long,M.,Li,K.,Yang,X.:Mvdream:Multi-viewdiffusion for 3d generation (2024),https://arxiv.org/abs/2308.16512
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Ye et al
Sima, C., Tong, W., Wang, T., Chen, L., Wu, S., Deng, H., Gu, Y., Lu, L., Luo, P., Lin, D., Li, H.: Scene as occupancy (2023) 18 X. Ye et al
2023
-
[35]
Sitzmann, V., Thies, J., Heide, F., Nießner, M., Wetzstein, G., Zollhöfer, M.: Deep- voxels: Learning persistent 3d feature embeddings (2019),https://arxiv.org/ abs/1812.01024
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [36]
-
[37]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
Sun, P., Kretzschmar, H., Dotiwalla, X., Chouard, A., Patnaik, V., Tsui, P., Guo, J., Zhou, Y., Chai, Y., Caine, B., Vasudevan, V., Han, W., Ngiam, J., Zhao, H., Timofeev, A., Ettinger, S., Krivokon, M., Gao, A., Joshi, A., Zhang, Y., Shlens, J., Chen, Z., Anguelov, D.: Scalability in perception for autonomous driving: Waymo open dataset. In: Proceedings ...
2020
- [38]
- [39]
-
[40]
In: Deep Generative Models for Highly Structured Data, ICLR 2019 Workshop, New Orleans, Louisiana, United States, May 6, 2019
Unterthiner, T., van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: FVD: A new metric for video generation. In: Deep Generative Models for Highly Structured Data, ICLR 2019 Workshop, New Orleans, Louisiana, United States, May 6, 2019. OpenReview.net (2019),https://openreview.net/forum? id=rylgEULtdN
2019
- [41]
- [42]
-
[43]
Wang, X., Zhu, Z., Huang, G., Chen, X., Zhu, J., Lu, J.: Drivedreamer: Towards real-world-driven world models for autonomous driving (2023),https://arxiv. org/abs/2309.09777
- [44]
- [45]
-
[46]
ACM Transactions on Graphics43(4) (2024).https://doi.org/ 10.1145/3658188
Wu, Z., Li, Y., Yan, H., Shang, T., Sun, W., Wang, S., Cui, R., Liu, W., Sato, H., Li, H., Ji, P.: Blockfusion: Expandable 3d scene generation using latent tri-plane extrapolation. ACM Transactions on Graphics43(4) (2024).https://doi.org/ 10.1145/3658188
- [47]
- [48]
- [49]
- [50]
- [51]
-
[52]
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., Yin, D., Zhang, Y., Wang, W., Cheng, Y., Xu, B., Gu, X., Dong, Y., Tang, J.: Cogvideox: Text-to-video diffusion models with an expert transformer (2025),https://arxiv.org/abs/2408.06072
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
arXiv preprint arXiv:2503.22236 (2025)
Ye, C., Wu, Y., Lu, Z., Chang, J., Guo, X., Zhou, J., Zhao, H., Han, X.: Hi3dgen: High-fidelity 3d geometry generation from images via normal bridging. arXiv preprint arXiv:2503.22236 (2025)
-
[54]
Zhang, J., Zhang, Q., Zhang, L., Kompella, R.R., Liu, G., Zhou, B.: Urban scene diffusion through semantic occupancy map (2024),https://arxiv.org/abs/2403. 11697
2024
- [55]
- [56]
-
[57]
Zhou, T., Tucker, R., Flynn, J., Fyffe, G., Snavely, N.: Stereo magnification: Learn- ing view synthesis using multiplane images (2018),https://arxiv.org/abs/1805. 09817
2018
- [58]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.