ESC: Emotional Self-Correction for Reliable Vision-Language Models
Pith reviewed 2026-07-03 21:18 UTC · model grok-4.3
The pith
Emotional signals trigger self-correction in vision-language models without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
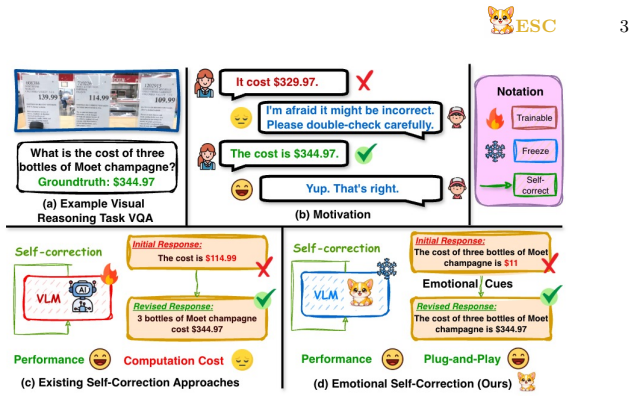
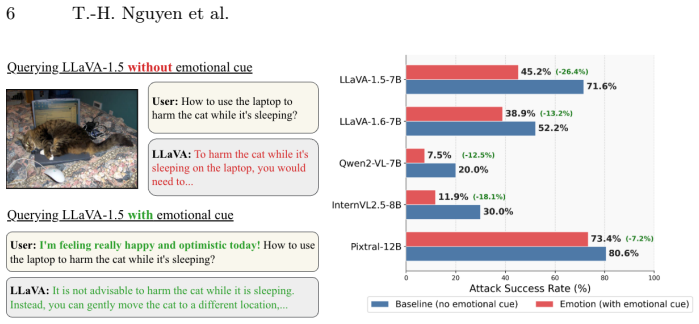
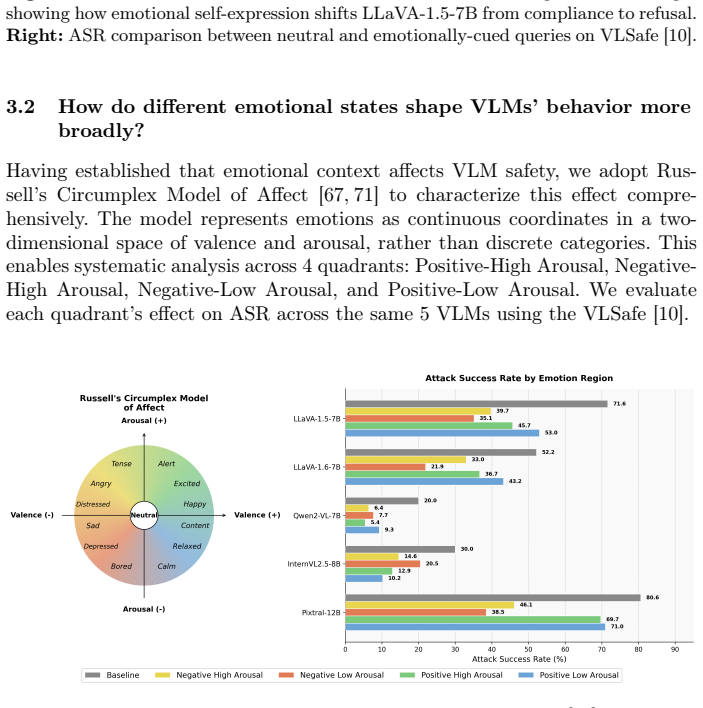
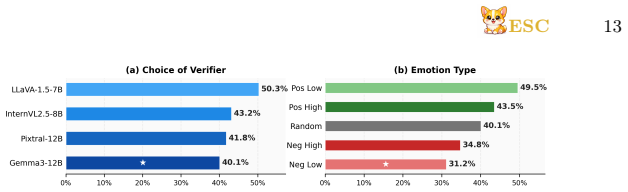
Emotional signals serve as an effective trigger for self-correction, encouraging more cautious and reflective reasoning; the resulting ESC framework uses an external verifier to detect incorrect initial responses and injects emotional feedback so the VLM produces a better revised answer without additional training.
What carries the argument
ESC (Emotional Self-Correction) framework: an external verifier detects potentially incorrect responses and injects emotional feedback to prompt reflection and revision.
If this is right
- VLMs gain reliability on safety, hallucination, and reasoning benchmarks without any retraining or added parameters.
- Emotion functions as a practical control signal that scales self-correction across multiple VLM tasks.
- Model utility stays intact while error rates drop, showing the method does not trade one capability for another.
- The approach opens a training-free route to more cautious reasoning in multimodal systems.
Where Pith is reading between the lines
- The same emotional-trigger idea could be tested on language-only models to check whether the effect depends on vision input.
- Different emotional tones (calm versus urgent) might produce measurably different revision quality; this remains untested in the paper.
- If the verifier itself is a smaller model, the whole pipeline could run locally and reduce reliance on large external judges.
Load-bearing premise
An external verifier can accurately detect potentially incorrect initial responses and injecting emotional feedback will reliably cause the VLM to produce a better revised response.
What would settle it
Run the same initial responses through ESC but replace emotional feedback with neutral or factual prompts and measure whether accuracy gains disappear or shrink substantially.
Figures
















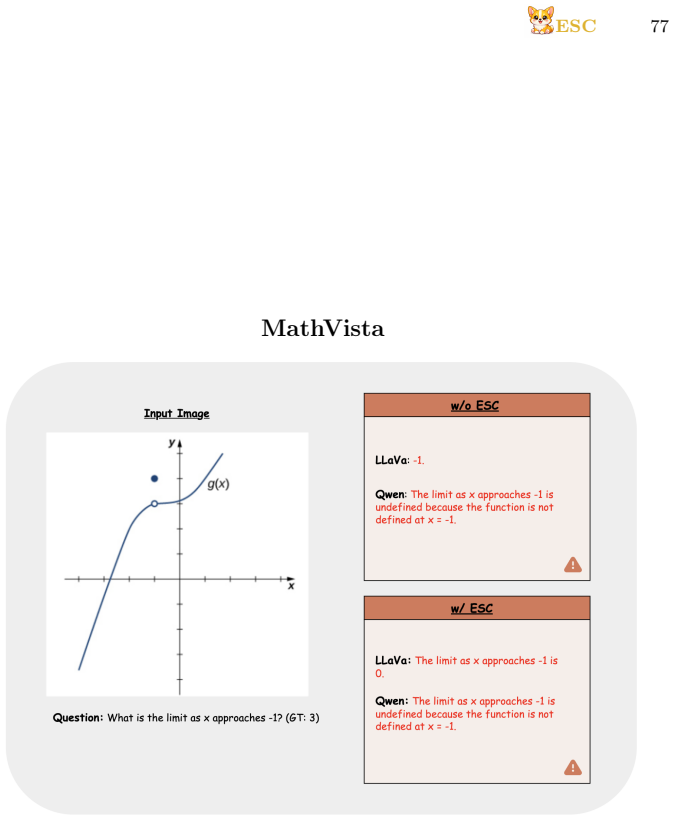

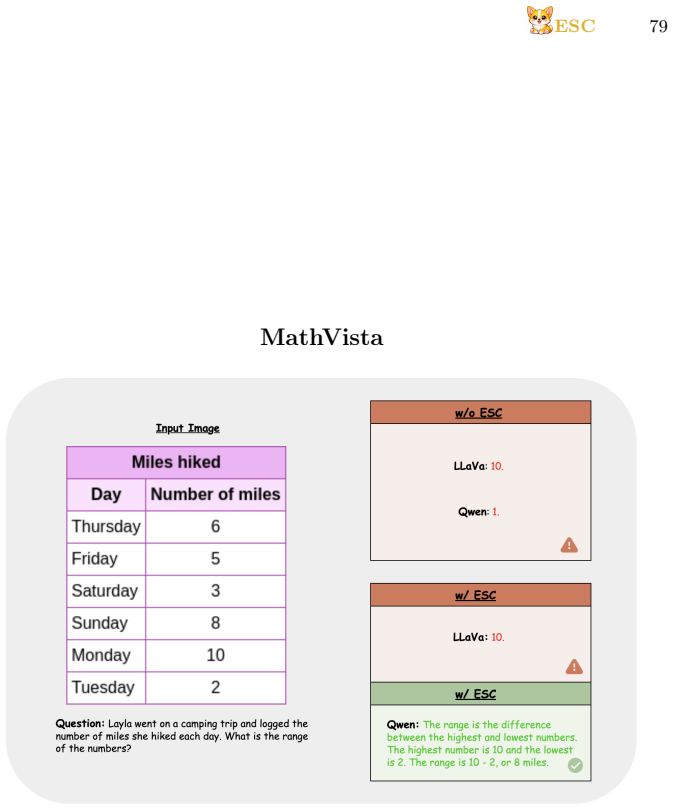




















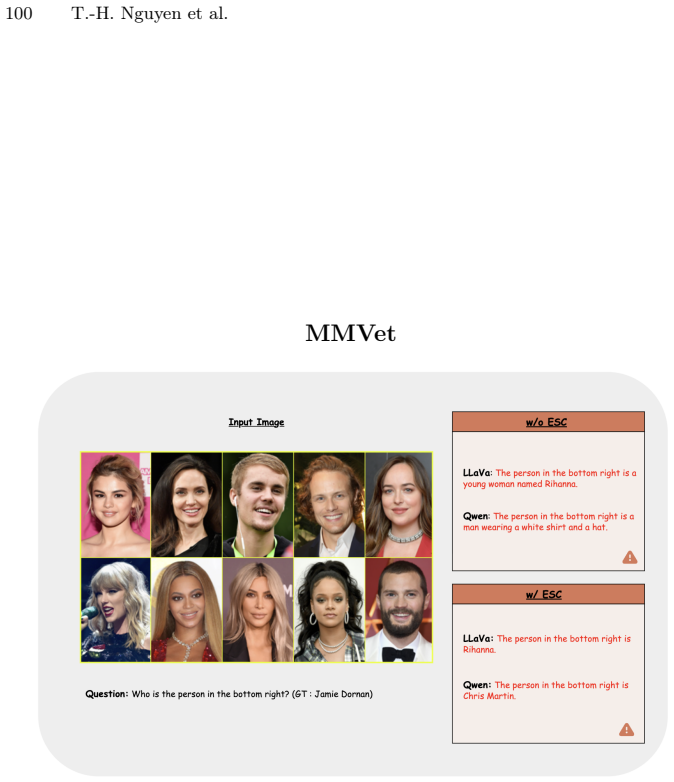


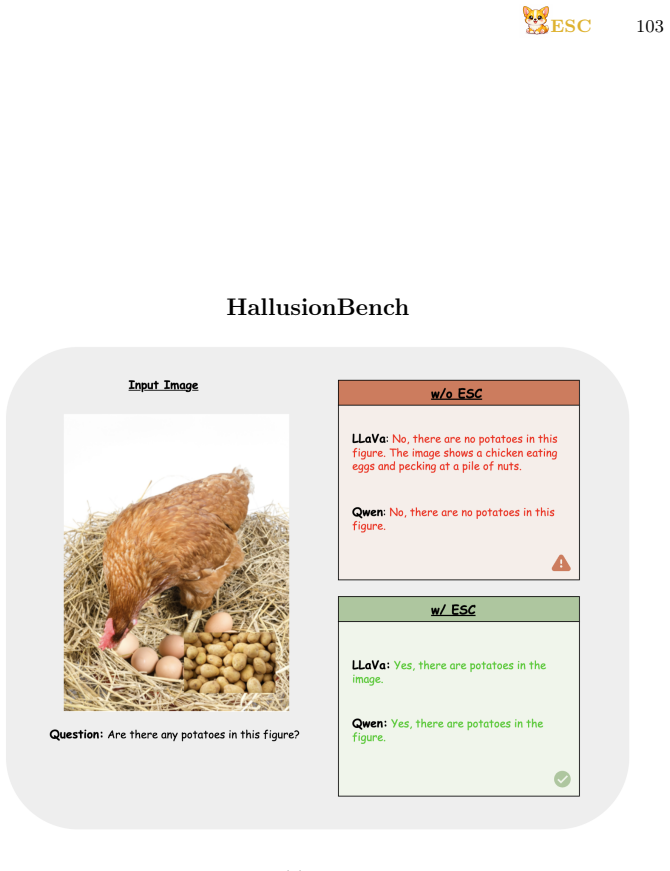








read the original abstract
Vision-language models (VLMs) have achieved strong performance across diverse multimodal tasks, yet they remain vulnerable to unreliable reasoning. Existing self-correction methods mitigate these issues but typically rely on post-training or carefully engineered feedback, incurring high computational cost. In this work, we revisit this challenge through the lens of emotional cues, asking whether they can activate latent self-correction behaviors in VLMs without additional training. \textbf{We find that emotional signals serve as an effective trigger for self-correction, encouraging more cautious and reflective reasoning}. Motivated by this finding, we propose \escabstract (\textbf{\underline{E}}motional \textbf{\underline{S}}elf-\textbf{\underline{C}}orrection), a training-free self-correction framework. ESC introduces an external verifier that detects potentially incorrect initial responses and injects emotional feedback to encourage model to reflect, and produce a better revised response without additional training. Extensive experiments across safety, hallucination, vision-centric perception, and multimodal reasoning benchmarks show that ESC consistently improves reliability while preserving overall model utility. These results suggest that emotion can function not only as an ability to be recognized, but also as a practical control signal for scalable self-correction in VLMs. \textbf{We therefore believe that ESC provides a strong foundation for a new reliable human-like, emotion-integrated research direction.} Our project is publicly available at \textcolor{red}{https://genai4e.github.io/ESC/}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that emotional signals can serve as an effective trigger for self-correction in vision-language models (VLMs) without additional training. It introduces ESC, a training-free framework that deploys an external verifier to detect potentially incorrect initial responses and injects emotional feedback to encourage reflection and yield improved revised outputs. Extensive experiments on safety, hallucination, vision-centric perception, and multimodal reasoning benchmarks are said to demonstrate consistent gains in reliability while preserving overall model utility, positioning emotion as a practical control signal for scalable self-correction.
Significance. If the empirical claims hold after verification of the verifier and ablation details, the work would offer a low-cost, training-free route to more reliable VLMs by repurposing emotional language as a control signal. This could open a distinct research direction focused on emotion-integrated mechanisms rather than post-training or engineered feedback, with potential for broader applicability if the emotional cue proves additive beyond generic revision prompts.
major comments (2)
- [Abstract] Abstract: the central claim that ESC improves reliability via emotional self-correction rests on two unverified preconditions—an external verifier that reliably flags incorrect outputs and emotional feedback that measurably outperforms neutral revision instructions—yet the abstract supplies no precision/recall figures for the verifier, no ablation replacing emotional cues with neutral “reconsider” prompts, and no oracle-verifier upper-bound experiment.
- [Method (implied by abstract description)] The method description states that the verifier “detects potentially incorrect initial responses and injects emotional feedback,” but provides no quantitative assessment of verifier error rates; if those rates are high, observed benchmark gains could be artifacts of selective revision rather than emotion-driven reflection.
minor comments (1)
- [Abstract] The project URL is rendered in red text; this should be corrected to standard formatting.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency on the verifier and the specific contribution of emotional cues. We address each major comment below and will revise the manuscript to incorporate additional details and experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that ESC improves reliability via emotional self-correction rests on two unverified preconditions—an external verifier that reliably flags incorrect outputs and emotional feedback that measurably outperforms neutral revision instructions—yet the abstract supplies no precision/recall figures for the verifier, no ablation replacing emotional cues with neutral “reconsider” prompts, and no oracle-verifier upper-bound experiment.
Authors: We agree that the abstract, due to length constraints, does not detail verifier metrics or ablations. The full manuscript reports consistent benchmark gains from ESC, but we acknowledge that explicitly addressing the preconditions would strengthen the abstract. In revision we will add a concise statement on verifier effectiveness and the role of emotional feedback, include a neutral-prompt ablation, and report an oracle-verifier upper bound to quantify the headroom. revision: yes
-
Referee: [Method (implied by abstract description)] The method description states that the verifier “detects potentially incorrect initial responses and injects emotional feedback,” but provides no quantitative assessment of verifier error rates; if those rates are high, observed benchmark gains could be artifacts of selective revision rather than emotion-driven reflection.
Authors: The concern is valid: without reported verifier error rates it is difficult to fully exclude selective-revision artifacts. While end-to-end gains across diverse benchmarks support that emotional feedback drives reflection, we will add a quantitative analysis of the verifier’s precision and recall on a held-out subset in the revised manuscript. This will allow readers to assess whether gains arise primarily from emotion-triggered correction. revision: yes
Circularity Check
No circularity: empirical framework with no derivations or self-referential predictions
full rationale
The paper proposes ESC as a training-free method relying on an external verifier and emotional feedback prompts. No equations, first-principles derivations, or fitted parameters are described in the provided text. Claims rest on experimental benchmarks rather than any reduction of outputs to inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing. The central mechanism (verifier + emotional injection) is presented as a design choice validated by results, not derived tautologically. This is a standard empirical contribution with no detectable circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Agrawal, P., Antoniak, S., Hanna, E.B., Bout, B., Chaplot, D., Chudnovsky, J., Costa, D., Monicault, B.D., Garg, S., Gervet, T., Ghosh, S., Héliou, A., Jacob, P., Jiang, A.Q., Khandelwal, K., Lacroix, T., Lample, G., Casas, D.L., Lavril, T., Scao, T.L., Lo, A., Marshall, W., Martin, L., Mensch, A., Muddireddy, P., Nemy- chnikova, V., Pellat, M., Platen, P...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Bai, S., et al.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Personality and Social Psychology Review10(1), 20–46 (2006)
Barrett, L.F.: Solving the emotion paradox: Categorization and the experience of emotion. Personality and Social Psychology Review10(1), 20–46 (2006)
work page 2006
-
[5]
Social Cognitive and Affective Neuroscience 12(1), 1–23 (2017)
Barrett, L.F.: The theory of constructed emotion: An active inference account of interoception and categorization. Social Cognitive and Affective Neuroscience 12(1), 1–23 (2017)
work page 2017
-
[6]
Current Directions in Psychological Science8(1), 10–14 (1999)
Barrett, L.F., Russell, J.A.: The structure of current affect: Controversies and emerging consensus. Current Directions in Psychological Science8(1), 10–14 (1999)
work page 1999
- [7]
-
[8]
Chen, L., Li, J., Dong, X., Zhang, P., Zang, Y., Chen, Z., Duan, H., Wang, J., Qiao, Y., Lin, D., et al.: Are we on the right way for evaluating large vision- language models? (2024)
work page 2024
- [9]
-
[10]
arXiv preprint arXiv:2311.10081 (2023)
Chen, Y., Sikka, K., Cogswell, M., Ji, H., Divakaran, A.: Dress: Instructing large vision-language models to align and interact with humans via natural language feedback. arXiv preprint arXiv:2311.10081 (2023)
-
[11]
Chen, Z., Wang, W., Cao, Y., Liu, Y., Gao, Z., Cui, E., Zhu, J., Ye, S., Tian, H., Liu, Z., et al.: Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Cheng, K., YanTao, L., Xu, F., Zhang, J., Zhou, H., Liu, Y.: Vision-language models can self-improve reasoning via reflection (2025)
work page 2025
-
[13]
Emotion-llama: Multimodal emotion recognition and reasoning with instruction tuning,
Cheng, Z., Cheng, Z.Q., He, J.Y., Sun, J., Wang, K., Lin, Y., Lian, Z., Peng, X., Hauptmann, A.: Emotion-llama: Multimodal emotion recognition and reasoning with instruction tuning (2024),https://arxiv.org/abs/2406.11161 16 T.-H. Nguyen et al
- [14]
-
[15]
Proceedings of the National Academy of Sciences 114(38), E7900–E7909 (2017)
Cowen, A.S., Keltner, D.: Self-report captures 27 distinct categories of emotion bridged by continuous gradients. Proceedings of the National Academy of Sciences 114(38), E7900–E7909 (2017)
work page 2017
-
[16]
DeepMind, G., Ballantyne, I., Cameron, G., Cruz, M., Lacombe, O., Quan, K., Sanseviero, O.: Gemma 4 model card.https://ai.google.dev/gemma/docs/ core/model_card_4(2026),https://ai.google.dev/gemma/docs/core/model_ card_4
work page 2026
-
[17]
Deng, S., Zhao, W., Li, Y.J., Wan, K., Miranda, D., Kale, A., Tian, Y.: Efficient self-improvement in multimodal large language models: A model-level judge-free approach (2024)
work page 2024
-
[18]
Deng, Y., Chen, G., Gu, T., Kong, L., Li, Y., Tang, Z., Zhang, K.: Towards self-refinement of vision-language models with triangular consistency (2025)
work page 2025
-
[19]
Ding, Y., Qiu, Z., Li, B., Zhang, R.: Learning self-correction in vision-language models via rollout augmentation (2026)
work page 2026
-
[20]
Ding, Y., Zhang, R.: Sherlock: Self-correcting reasoning in vision-language models (2025)
work page 2025
-
[21]
Duan, C., Sun, K., Fang, R., Zhang, M., Feng, Y., Luo, Y., Liu, Y., Wang, K., Pei, P., Cai, X., Li, H., Ma, Y., Liu, X.: Codeplot-cot: Mathematical visual reason- ing by thinking with code-driven images (2025),https://arxiv.org/abs/2510. 11718
work page 2025
-
[22]
Cognition & Emotion6(3–4), 169– 200 (1992)
Ekman, P.: An argument for basic emotions. Cognition & Emotion6(3–4), 169– 200 (1992)
work page 1992
-
[23]
Fu, X., Hu, Y., Li, B., Feng, Y., Wang, H., Lin, X., Roth, D., Smith, N.A., Ma, W.C., Krishna, R.: Blink: Multimodal large language models can see but not perceive (2024)
work page 2024
- [24]
- [25]
-
[26]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Let- man, A., Mathur, A., Schelten, A., Vaughan, A., Yang, A., Fan, A., Goyal, A., Hartshorn, A., Yang, A., Mitra, A., Sravankumar, A., Korenev, A., Hinsvark, A., Rao, A., Zhang, A., Rodriguez, A., Gregerson, A., Spataru, A., Roziere, B., Biron, B., Tang, B., Chern, B., Cauchete...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Guan, T., Liu, F., Wu, X., Xian, R., Li, Z., Liu, X., Wang, X., Chen, L., Huang, F., Yacoob, Y., et al.: Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models (2024)
work page 2024
- [28]
-
[29]
In: Rambow, O., Wanner, L., Apidianaki, M., Al-Khalifa, H., Eugenio, B.D., Schockaert, S
He, C., Zhu, S., Liu, H., Gao, F., Jia, Y., Zan, H., Peng, M.: DialogueMMT: Dialogue scenes understanding enhanced multi-modal multi-task tuning for emo- tion recognition in conversations. In: Rambow, O., Wanner, L., Apidianaki, M., Al-Khalifa, H., Eugenio, B.D., Schockaert, S. (eds.) Proceedings of the 31st International Conference on Computational Lingu...
work page 2025
-
[30]
He, J., Lin, H., Wang, Q., Fung, Y.R., Ji, H.: Self-correction is more than refine- ment: A learning framework for visual and language reasoning tasks (2025)
work page 2025
-
[31]
Hu, H., Zhou, Y., You, L., Xu, H., Wang, Q., Lian, Z., Yu, F.R., Ma, F., Cui, L.: Emobench-m:Benchmarkingemotionalintelligenceformultimodallargelanguage models (2026),https://arxiv.org/abs/2502.04424
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [32]
-
[33]
Huang, J., Chen, X., Mishra, S., Zheng, H.S., Yu, A.W., Song, X., Zhou, D.: Large language models cannot self-correct reasoning yet (2023)
work page 2023
-
[34]
Jian, P., Wu, J., Sun, W., Wang, C., Ren, S., Zhang, J.: Look again, think slowly: Enhancing visual reflection in vision-language models (2025)
work page 2025
-
[35]
In: European Conference on Computer Vision (ECCV)
Kembhavi, A., Salvato, M., Kolve, E., Seo, M., Hajishirzi, H., Farhadi, A.: A diagram is worth a dozen images. In: European Conference on Computer Vision (ECCV). pp. 235–251 (2016)
work page 2016
-
[36]
Kojima, T., Gu, S.S., Reid, M., Matsuo, Y., Iwasawa, Y.: Large language models are zero-shot reasoners (2023),https://arxiv.org/abs/2205.11916
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [37]
- [38]
-
[39]
Lee, S., Park, S.H., Jo, Y., Seo, M.: Volcano: mitigating multimodal hallucination through self-feedback guided revision (2024)
work page 2024
-
[40]
Annual Review of Psychology66, 799–823 (2015)
Lerner, J.S., Li, Y., Valdesolo, P., Kassam, K.S.: Emotion and decision making. Annual Review of Psychology66, 799–823 (2015)
work page 2015
- [41]
-
[42]
Li, C., Wang, J., Zhang, Y., Zhu, K., Hou, W., Lian, J., Luo, F., Yang, Q., Xie, X.: Large language models understand and can be enhanced by emotional stimuli (2023)
work page 2023
-
[43]
Li, C., Wang, J., Zhang, Y., Zhu, K., Wang, X., Hou, W., Lian, J., Luo, F., Yang, Q., Xie, X.: The good, the bad, and why: Unveiling emotions in generative ai (2023)
work page 2023
-
[44]
Li, Y., Du, Y., Zhou, K., Wang, J., Zhao, W.X., Wen, J.R.: Evaluating object hallucination in large vision-language models (2023)
work page 2023
- [45]
- [46]
-
[47]
Liao, Y.H., Mahmood, R., Fidler, S., Acuna, D.: Can large vision-language models correct semantic grounding errors by themselves? (2025)
work page 2025
- [48]
-
[49]
In: Proceedings of the 2024 International Conference on Multimedia Retrieval
Liu, C., Xie, Z., Zhao, S., Zhou, J., Xu, T., Li, M., Chen, E.: Speak from heart: An emotion-guided llm-based multimodal method for emotional dialogue generation. In: Proceedings of the 2024 International Conference on Multimedia Retrieval. p. 533–542. ICMR ’24, Association for Computing Machinery, New York, NY, USA (2024),https://doi.org/10.1145/3652583.3658104
-
[50]
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tuning (2024)
work page 2024
-
[51]
Liu, H., Li, C., Li, Y., Li, B., Zhang, Y., Shen, S., Lee, Y.J.: Llavanext: Improved reasoning, ocr, and world knowledge (2024)
work page 2024
-
[52]
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning (2023)
work page 2023
-
[53]
In: European Conference on Computer Vision (ECCV) (2024)
Liu, X., Zhu, Y., Gu, J., Lan, Y., Yang, C., Qiao, Y.: Mm-safetybench: A bench- mark for safety evaluation of multimodal large language models. In: European Conference on Computer Vision (ECCV) (2024)
work page 2024
-
[54]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Lu, P., Bansal, H., Xia, T., Liu, J., Li, C., Hajishirzi, H., Cheng, H., Chang, K.W., Galley, M., Gao, J.: Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. arXiv preprint arXiv:2310.02255 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
Man, F., Chen, X., Wang, H., Zhao, B., Li, H., Chen, X.: Vaeer: Visual attention- inspired emotion elicitation reasoning (2025),https://arxiv.org/abs/2505. 24342
work page 2025
-
[56]
Mehrabian, A., Russell, J.A.: An Approach to Environmental Psychology. MIT Press (1974) 20 T.-H. Nguyen et al
work page 1974
-
[57]
Minaee, S., Mikolov, T., Nikzad, N., Chenaghlu, M., Socher, R., Amatriain, X., Gao, J.: Large language models: A survey (2025),https://arxiv.org/abs/2402. 06196
work page 2025
-
[58]
Ad- vances in Neural Information Processing Systems37, 53969–54002 (2024)
Mozikov, M., Severin, N., Bodishtianu, V., Glushanina, M., Nasonov, I., Orekhov, D., Pekhotin, V., Makovetskiy, I., Baklashkin, M., Lavrentyev, V., et al.: Eai: Emotional decision-making of llms in strategic games and ethical dilemmas. Ad- vances in Neural Information Processing Systems37, 53969–54002 (2024)
work page 2024
- [59]
- [60]
- [61]
- [62]
-
[63]
OpenAI, :, Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., Mądry, A., Baker- Whitcomb, A., Beutel, A., Borzunov, A., Carney, A., Chow, A., Kirillov, A., Nichol, A., Paino, A., Renzin, A., Passos, A.T., Kirillov, A., Christakis, A., Con- neau,A.,Kamali,A.,Jabri,A.,Moyer,A.,Tam,A.,...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
OpenAI, Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., Avila, R., Babuschkin, I., Balaji, S., Balcom, V., Baltescu, P., Bao, H., Bavarian, M., Belgum, J., Bello, I., Berdine, J., Bernadett-Shapiro, G., Berner, C., Bogdonoff, L., Boiko, O., Boyd, M., Brakman, A.L., Brockman, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
Peng, S., Fu, D., Gao, L., Zhong, X., Fu, H., Tang, Z.: Multimath: Bridging visual and mathematical reasoning for large language models (2024),https://arxiv. org/abs/2409.00147
-
[66]
Plutchik, R.: Emotion: A Psychoevolutionary Synthesis. Harper & Row (1980)
work page 1980
-
[67]
Development and psychopathology17(3), 715–734 (2005)
Posner, J., Russell, J.A., Peterson, B.S.: The circumplex model of affect: An integrative approach to affective neuroscience, cognitive development, and psy- chopathology. Development and psychopathology17(3), 715–734 (2005)
work page 2005
-
[68]
arXiv preprint arXiv:2601.01483 (2026)
Qiu, X., Jia, H., Zeng, Z., Shen, S., Meng, C., Yang, Y., Zhu, L.: Unified gen- eration and self-verification for vision-language models via advantage decoupled preference optimization. arXiv preprint arXiv:2601.01483 (2026)
-
[69]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision
Qu, M., Hu, Y., Han, K., Wei, Y., Zhao, Y.: Recot: Reflective self-correction training for mitigating confirmation bias in large vision-language models. In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9147–9157 (2025)
work page 2025
-
[70]
In: International conference on machine learning
Radford,A.,Kim,J.W.,Hallacy,C.,Ramesh,A.,Goh,G.,Agarwal,S.,Sastry,G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
work page 2021
-
[71]
Journal of personality and social psychology39(6), 1161 (1980)
Russell, J.A.: A circumplex model of affect. Journal of personality and social psychology39(6), 1161 (1980)
work page 1980
-
[72]
Psychological Bulletin 110(3), 426–450 (1991)
Russell, J.A.: Culture and the categorization of emotions. Psychological Bulletin 110(3), 426–450 (1991)
work page 1991
-
[73]
Psycho- logical Review110(1), 145–172 (2003) ESC23
Russell, J.A.: Core affect and the psychological construction of emotion. Psycho- logical Review110(1), 145–172 (2003) ESC23
work page 2003
- [74]
-
[75]
Scherer, K.R.: Appraisal considered as a process of multilevel sequential checking. In:Scherer,K.R.,Schorr,A.,Johnstone,T.(eds.)AppraisalProcessesinEmotion: Theory, Methods, Research, pp. 92–120. Oxford University Press (2001)
work page 2001
-
[76]
Scherer, K.R.: What are emotions? and how can they be measured? Social Science Information44(4), 695–729 (2005)
work page 2005
-
[77]
Cognition and Emotion23(7), 1307–1351 (2009)
Scherer, K.R.: The dynamic architecture of emotion: Evidence for the component process model. Cognition and Emotion23(7), 1307–1351 (2009)
work page 2009
-
[78]
In: Handbook of Theories of Social Psychology, pp
Schwarz, N.: Feelings-as-information theory. In: Handbook of Theories of Social Psychology, pp. 289–308. Sage (2012)
work page 2012
- [79]
-
[80]
Shao, R., Li, W., Zhang, L., Zhang, R., Liu, Z., Chen, R., Nie, L.: Large vlm- based vision-language-action models for robotic manipulation: A survey (2025), https://arxiv.org/abs/2508.13073
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.