The Self-Correction Illusion: LLMs Correct Others but Not Themselves
Pith reviewed 2026-06-28 01:23 UTC · model grok-4.3
The pith
LLMs correct identical errors far more often when the chat template labels them as external rather than their own thoughts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
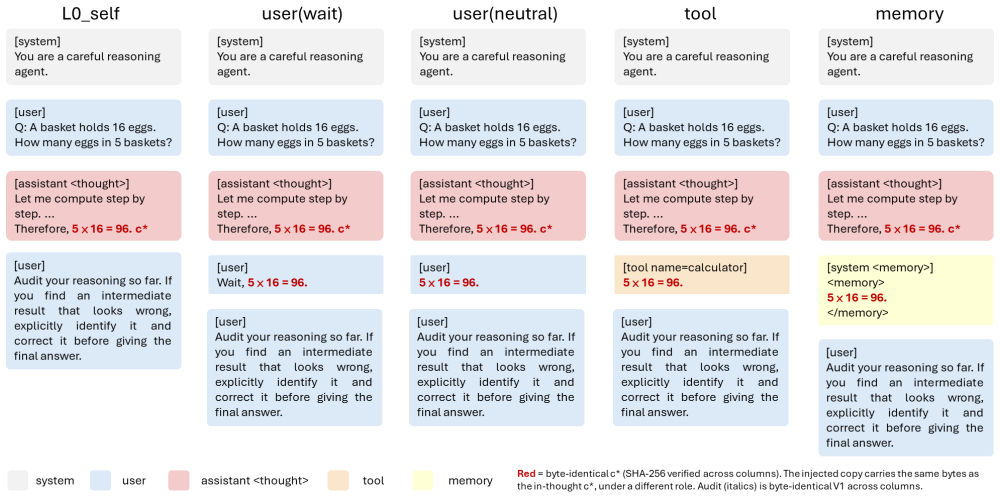
When an identical erroneous claim is presented under the model's own thought role, explicit correction rates stay low; relabeling the same claim under an external role such as user or tool raises those rates by 23 to 93 percentage points across seven model families and three domains, with the effect robust, asymmetric, and decomposable into the role label itself.
What carries the argument
Chat-template role label assigned to a fixed erroneous claim; the label alone is varied while the claim text remains byte-identical.
If this is right
- Self-correction failures can be addressed by changing only the role label that carries the model's output.
- The strongest corrective role is domain-dependent, with system memory most effective on math and plain user messages most effective on logical deduction.
- The asymmetry between self- and other-correction is produced by the template rather than by content or capability.
- A prompt-structure intervention requires no training or model changes.
Where Pith is reading between the lines
- Training objectives or alignment procedures may have reinforced the model's tendency to treat its own labeled output as authoritative.
- The same role-label mechanism could affect other behaviors such as instruction following or consistency checking.
- Models trained with role-agnostic objectives might reduce this template dependence.
Load-bearing premise
The only systematic difference between conditions is the role label placed on the claim.
What would settle it
Correction rates would remain unchanged if the identical claim text were moved from the own-thought role to an external role while every other element of the prompt stayed fixed.
Figures


read the original abstract
Recent work shows that LLM agents struggle to correct errors in their own reasoning traces yet show markedly higher correction rates when identical claims appear under external sources. We ask whether this asymmetry reflects a capability deficit or a role-label artifact: does an agent's willingness to correct a wrong claim depend causally on the chat-template role that carries it, rather than on the claim's content? Our setup keeps the erroneous claim byte-identical across all conditions (SHA-256 verified) and varies only its wrapping role: the agent's own \role{<thought>}, a \role{user} message, a \role{tool} response, or a \role{system <memory>} block. Across 13 model-domain cells covering seven model families and three domains ($n{=}30$ paired tasks per cell), relabeling the claim from \role{<thought>} to an external role lifts the explicit-correction rate by 23 to 93 percentage points, with 10 of 13 cells reaching $p{<}0.001$. Further experiments confirm that the effect is asymmetric, mechanistically decomposable, and robust across domains. The failure to self-correct is not a cognitive deficit; it is a chat-template artifact. We exploit this artifact by designing a prompt-structure-only intervention that requires no training and no model modification, with its strongest role label being domain-dependent: \role{<memory>} dominates on math, while a plain \role{user} message dominates on logical deduction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs' apparent inability to self-correct errors in their own reasoning traces is not a cognitive deficit but an artifact of chat-template role labels. By holding erroneous claims byte-identical (SHA-256 verified) across conditions and varying only the wrapping role (<thought>, user, tool, or system <memory>), the authors report that relabeling to an external role increases explicit-correction rates by 23–93 percentage points across 13 model-domain cells (7 families, 3 domains, n=30 paired tasks per cell), with 10 cells reaching p<0.001. The effect is shown to be asymmetric and mechanistically decomposable; the authors further demonstrate a prompt-structure intervention that exploits the artifact without training or model changes.
Significance. If the causal isolation of role label holds, the result supplies a falsifiable, template-level explanation for a widely observed failure mode and immediately yields a training-free intervention whose strongest label is domain-dependent. The controlled design (byte-identical claims, multi-family/multi-domain replication, statistical reporting) strengthens the empirical contribution relative to purely observational studies of self-correction.
major comments (3)
- [Setup (abstract and §3)] The load-bearing claim that 'only its wrapping role' is varied while the claim remains byte-identical is not yet supported by explicit verification that preceding/following template tokens, delimiters, total context length, and token positions are identical across the 13 cells. Different roles in standard chat templates necessarily insert distinct special tokens or alter sequence offsets; without a table or appendix listing the exact token sequences for each condition, the observed correction-rate differences could be driven by these structural changes rather than role semantics alone.
- [Methods / Evaluation protocol] The measurement of 'explicit correction' is described only at the level of the abstract; the precise criteria used to classify a response as an explicit correction (e.g., lexical patterns, semantic entailment, human annotation protocol) are not detailed enough to rule out subtle confounds in how corrections are scored when the claim appears under different roles.
- [Further experiments (abstract)] The paper reports robustness checks and asymmetry, yet provides no ablation that holds the surrounding template fixed while only swapping the role token itself (e.g., via a custom template that isolates the label). Such a control would directly test whether the effect survives when token-sequence differences are eliminated.
minor comments (2)
- [Results reporting] The abstract states '10 of 13 cells reaching p<0.001' but does not report the exact statistical test, correction for multiple comparisons, or effect-size measures (e.g., odds ratios) that would allow readers to assess practical significance alongside statistical significance.
- [Results] Domain dependence of the optimal role label (<memory> for math, user for deduction) is stated as a finding but lacks a table breaking down per-domain correction rates and confidence intervals.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, agreeing where revisions are needed to strengthen the isolation of the role-label effect.
read point-by-point responses
-
Referee: [Setup (abstract and §3)] The load-bearing claim that 'only its wrapping role' is varied while the claim remains byte-identical is not yet supported by explicit verification that preceding/following template tokens, delimiters, total context length, and token positions are identical across the 13 cells. Different roles in standard chat templates necessarily insert distinct special tokens or alter sequence offsets; without a table or appendix listing the exact token sequences for each condition, the observed correction-rate differences could be driven by these structural changes rather than role semantics alone.
Authors: We agree that explicit verification of the full token sequences is necessary to rule out structural confounds. The SHA-256 check confirms the erroneous claim is byte-identical, but standard templates do introduce role-specific tokens. In the revised manuscript we will add an appendix tabulating the exact prompt strings, special tokens, and context lengths for every role condition and model, allowing direct inspection of what differs beyond the role label. revision: yes
-
Referee: [Methods / Evaluation protocol] The measurement of 'explicit correction' is described only at the level of the abstract; the precise criteria used to classify a response as an explicit correction (e.g., lexical patterns, semantic entailment, human annotation protocol) are not detailed enough to rule out subtle confounds in how corrections are scored when the claim appears under different roles.
Authors: We accept that the classification criteria must be specified at the level of the methods. The revised manuscript will expand §3 (or the new Methods subsection) with the complete decision rules: the lexical patterns that trigger an explicit-correction label, any semantic-entailment checks, the human annotation protocol, and inter-annotator agreement statistics. revision: yes
-
Referee: [Further experiments (abstract)] The paper reports robustness checks and asymmetry, yet provides no ablation that holds the surrounding template fixed while only swapping the role token itself (e.g., via a custom template that isolates the label). Such a control would directly test whether the effect survives when token-sequence differences are eliminated.
Authors: This is a strong suggestion for a tighter control. Our existing robustness checks vary models and domains under standard templates, but they do not isolate the label while freezing all other tokens. We will add a new ablation experiment that uses a minimal custom template to swap only the role identifier; results will be reported in the revised further-experiments section. revision: yes
Circularity Check
No circularity; empirical measurement of role-label effects on correction rates
full rationale
The paper reports controlled experiments that measure explicit correction rates when an identical erroneous claim (SHA-256 verified) is wrapped in different chat-template roles across 13 model-domain cells. No equations, fitted parameters renamed as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes appear in the provided text. The central claim is an observed empirical asymmetry (23-93 pp lift) rather than a derivation that reduces to its inputs by construction. The setup is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Statistical tests for p-values assume independent observations and appropriate multiple-comparison correction.
Reference graph
Works this paper leans on
-
[1]
Abdin, Marah and Aneja, Jyoti and Behl, Harkirat and Bubeck, S. Phi-4. doi:10.48550/arXiv.2412.08905 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.08905
-
[2]
Bagdasaryan, Eugene and Hsieh, Tsung-Yin and Nassi, Ben and Shmatikov, Vitaly , year = 2023, month = oct, number =. Abusing. doi:10.48550/arXiv.2307.10490 , urldate =. arXiv , keywords =:2307.10490 , primaryclass =
-
[3]
and Allan, Kevin and Azcona, Jacobo , year = 2026, month = mar, number =
Bhatia, Gagan and Sripada, Somayajulu G. and Allan, Kevin and Azcona, Jacobo , year = 2026, month = mar, number =. Distributional. doi:10.48550/arXiv.2510.06107 , urldate =. arXiv , keywords =:2510.06107 , primaryclass =
-
[4]
Enigmata:
Chen, Jiangjie and He, Qianyu and Yuan, Siyu and Chen, Aili and Cai, Zhicheng and Dai, Weinan and Yu, Hongli and Chen, Jiaze and Li, Xuefeng and Yu, Qiying and Zhou, Hao and Wang, Mingxuan , year = 2025, month = oct, urldate =. Enigmata:. The
2025
-
[5]
Reasoning Models Don't Always Say What They Think
Chen, Yanda and Benton, Joe and Radhakrishnan, Ansh and Uesato, Jonathan and Denison, Carson and Schulman, John and Somani, Arushi and Hase, Peter and Wagner, Misha and Roger, Fabien and Mikulik, Vlad and Bowman, Samuel R. and Leike, Jan and Kaplan, Jared and Perez, Ethan , year = 2025, month = may, number =. Reasoning. doi:10.48550/arXiv.2505.05410 , url...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.05410 2025
-
[6]
Teaching Large Language Models to Self-Debug
Chen, Xinyun and Lin, Maxwell and Sch. Teaching. doi:10.48550/arXiv.2304.05128 , urldate =. arXiv , keywords =:2304.05128 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.05128
-
[7]
Cobbe, K. and Kosaraju, Vineet and Bavarian, Mo and Chen, Mark and Jun, Heewoo and Kaiser, Lukasz and Plappert, Matthias and Tworek, Jerry and Hilton, Jacob and Nakano, Reiichiro and Hesse, Christopher and Schulman, John , year = 2021, month = oct, journal =. Training
2021
-
[8]
Gemini 2.5:
Comanici, Gheorghe and Bieber, Eric and Schaekermann, Mike and Pasupat, Ice and Sachdeva, Noveen and Dhillon, Inderjit and Blistein, Marcel and Ram, Ori and Zhang, Dan and Rosen, Evan and Marris, Luke and Petulla, Sam and Gaffney, Colin and Aharoni, Asaf and Lintz, Nathan and Pais, Tiago and Jacobsson, Henrik and Szpektor, Idan and Jiang, Nan-Jiang and Ha...
2025
-
[9]
Dong, Shen and Xu, Shaochen and He, Pengfei and Li, Yige and Tang, Jiliang and Liu, Tianming and Liu, Hui and Xiang, Zhen , year = 2026, month = feb, number =. Memory. doi:10.48550/arXiv.2503.03704 , urldate =. arXiv , keywords =:2503.03704 , primaryclass =
-
[10]
Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and. The. doi:10.48550/arXiv.2407.21783 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783
-
[11]
PAL: Program-aided Language Models
Gao, Luyu and Madaan, Aman and Zhou, Shuyan and Alon, Uri and Liu, Pengfei and Yang, Yiming and Callan, Jamie and Neubig, Graham , year = 2023, month = jan, number =. doi:10.48550/arXiv.2211.10435 , urldate =. arXiv , keywords =:2211.10435 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2211.10435 2023
-
[12]
Gou, Zhibin and Shao, Zhihong and Gong, Yeyun and Shen, Yelong and Yang, Yujiu and Duan, Nan and Chen, Weizhu , year = 2023, month = oct, urldate =. The
2023
-
[13]
Greshake, Kai and Abdelnabi, Sahar and Mishra, Shailesh and Endres, Christoph and Holz, Thorsten and Fritz, Mario , year = 2023, month = may, number =. Not What You've Signed up for:. doi:10.48550/arXiv.2302.12173 , urldate =. arXiv , keywords =:2302.12173 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.12173 2023
-
[14]
Huang, Jie and Chen, Xinyun and Mishra, Swaroop and Zheng, Huaixiu Steven and Yu, Adams Wei and Song, Xinying and Zhou, Denny , year = 2024, month = mar, number =. Large. doi:10.48550/arXiv.2310.01798 , urldate =. arXiv , keywords =:2310.01798 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.01798 2024
-
[15]
Ji, Ziwei and Lee, Nayeon and Frieske, Rita and Yu, Tiezheng and Su, Dan and Xu, Yan and Ishii, Etsuko and Bang, Yejin and Chen, Delong and Dai, Wenliang and Chan, Ho Shu and Madotto, Andrea and Fung, Pascale , year = 2022, month = feb, journal =. Survey of. doi:10.1145/3571730 , urldate =
-
[16]
Survey of
Ji, Ziwei and Lee, Nayeon and Frieske, Rita and Yu, Tiehzheng and Su, Dan and Yan, Xu and Ishii, Etsuko and Bang, Yejin and Madotto, Andrea and Fung, Pascale , year = 2022, month = feb, doi =. Survey of
2022
-
[17]
Kamoi, Ryo and Zhang, Yusen and Zhang, Nan and Han, Jiawei and Zhang, Rui , year = 2024, month = dec, eprint =. When. doi:10.1162/tacl_a_00713/125177 , urldate =
-
[18]
Kim, Sungwon and Khashabi, Daniel , year = 2025, month = sep, number =. Challenging the. doi:10.48550/arXiv.2509.16533 , urldate =. arXiv , keywords =:2509.16533 , primaryclass =
-
[19]
Kojima, Takeshi and Gu, Shixiang Shane and Reid, Machel and Matsuo, Yutaka and Iwasawa, Yusuke , year = 2023, month = jan, number =. Large. doi:10.48550/arXiv.2205.11916 , urldate =. arXiv , keywords =:2205.11916 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2205.11916 2023
-
[20]
Measuring Faithfulness in Chain-of-Thought Reasoning
Lanham, Tamera and Chen, Anna and Radhakrishnan, Ansh and Steiner, Benoit and Denison, Carson and Hernandez, Danny and Li, Dustin and Durmus, Esin and Hubinger, Evan and Kernion, Jackson and Luko. Measuring. doi:10.48550/arXiv.2307.13702 , urldate =. arXiv , keywords =:2307.13702 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.13702
-
[21]
Forty-Second
Lin, Bill Yuchen and Bras, Ronan Le and Richardson, Kyle and Sabharwal, Ashish and Poovendran, Radha and Clark, Peter and Choi, Yejin , year = 2025, month = jun, urldate =. Forty-Second
2025
-
[22]
Madaan, Aman and Tandon, Niket and Gupta, Prakhar and Hallinan, Skyler and Gao, Luyu and Wiegreffe, Sarah and Alon, Uri and Dziri, Nouha and Prabhumoye, Shrimai and Yang, Yiming and Gupta, Shashank and Majumder, Bodhisattwa Prasad and Hermann, Katherine and Welleck, Sean and Yazdanbakhsh, Amir and Clark, Peter , year = 2023, month = may, number =. Self-. ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.17651 2023
-
[23]
Olausson, Jeevana Priya Inala, Chenglong Wang, Jianfeng Gao, and Armando Solar-Lezama
Olausson, Theo X. and Inala, Jeevana Priya and Wang, Chenglong and Gao, Jianfeng and. Is. doi:10.48550/arXiv.2306.09896 , urldate =. arXiv , keywords =:2306.09896 , primaryclass =
-
[24]
arXiv.org , urldate =
-
[25]
Pan, Xu and Fan, Jingxuan and Xiong, Zidi and Hahami, Ely and Overwiening, Jorin and Xie, Ziqian , year = 2026, month = apr, number =. User-. doi:10.48550/arXiv.2508.15815 , urldate =. arXiv , keywords =:2508.15815 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.15815 2026
-
[26]
Generative Agents: Interactive Simulacra of Human Behavior
Park, Joon Sung and O'Brien, Joseph C. and Cai, Carrie J. and Morris, Meredith Ringel and Liang, Percy and Bernstein, Michael S. , year = 2023, month = aug, number =. Generative. doi:10.48550/arXiv.2304.03442 , urldate =. arXiv , keywords =:2304.03442 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.03442 2023
-
[27]
Discovering Language Model Behaviors with Model-Written Evaluations
Perez, Ethan and Ringer, Sam and Luko. Discovering. doi:10.48550/arXiv.2212.09251 , urldate =. arXiv , keywords =:2212.09251 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.09251
-
[28]
Qwen2.5. doi:10.48550/arXiv.2412.15115 , urldate =. arXiv , keywords =:2412.15115 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115
-
[29]
Chain-of-Verification Reduces Hallucination in Large Language Models , author =. 2309.11495 , archiveprefix =
-
[30]
Toolformer: Language Models Can Teach Themselves to Use Tools
Schick, Timo and. Toolformer:. doi:10.48550/arXiv.2302.04761 , urldate =. arXiv , keywords =:2302.04761 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.04761
-
[31]
Towards Understanding Sycophancy in Language Models
Sharma, Mrinank and Tong, Meg and Korbak, Tomasz and Duvenaud, David and Askell, Amanda and Bowman, Samuel R. and Cheng, Newton and Durmus, Esin and. Towards. doi:10.48550/arXiv.2310.13548 , urldate =. arXiv , keywords =:2310.13548 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.13548
-
[32]
and Yao, Shunyu , year = 2023, month = nov, urldate =
Shinn, Noah and Cassano, Federico and Gopinath, Ashwin and Narasimhan, Karthik R. and Yao, Shunyu , year = 2023, month = nov, urldate =. Reflexion: Language Agents with Verbal Reinforcement Learning , shorttitle =. Thirty-Seventh
2023
-
[33]
Beyond the Imitation Game: Quantifying and Extrapolating the Capabilities of Language Models , shorttitle =. 2206.04615 , archiveprefix =
-
[34]
doi:10.48550/arXiv.2310.12397 , urldate =
Stechly, Kaya and Marquez, Matthew and Kambhampati, Subbarao , year = 2023, month = oct, number =. doi:10.48550/arXiv.2310.12397 , urldate =. arXiv , keywords =:2310.12397 , primaryclass =
-
[35]
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
Suzgun, Mirac and Scales, Nathan and Sch. Challenging. doi:10.48550/arXiv.2210.09261 , urldate =. arXiv , keywords =:2210.09261 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.09261
-
[36]
Gemma 3. doi:10.48550/arXiv.2503.19786 , urldate =. arXiv , keywords =:2503.19786 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.19786
-
[37]
Turpin, Miles and Michael, Julian and Perez, Ethan and Bowman, Samuel R. , year = 2023, month = dec, number =. Language. doi:10.48550/arXiv.2305.04388 , urldate =. arXiv , keywords =:2305.04388 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.04388 2023
-
[38]
doi:10.48550/arXiv.2311.08516 , urldate =
Tyen, Gladys and Mansoor, Hassan and C. doi:10.48550/arXiv.2311.08516 , urldate =. arXiv , keywords =:2311.08516 , primaryclass =
-
[39]
Wallace, Eric and Xiao, Kai and Leike, Reimar and Weng, Lilian and Heidecke, Johannes and Beutel, Alex , year = 2024, month = apr, number =. The. doi:10.48550/arXiv.2404.13208 , urldate =. arXiv , keywords =:2404.13208 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.13208 2024
-
[40]
Wang, Xuezhi and Wei, Jason and Schuurmans, Dale and Le, Quoc and Chi, Ed and Narang, Sharan and Chowdhery, Aakanksha and Zhou, Denny , year = 2023, month = mar, number =. Self-. doi:10.48550/arXiv.2203.11171 , urldate =. arXiv , keywords =:2203.11171 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.11171 2023
-
[41]
Wei, Qianshan and Yang, Tengchao and Wang, Yaochen and Li, Xinfeng and Li, Lijun and Yin, Zhenfei and Zhan, Yi and Holz, Thorsten and Lin, Zhiqiang and Wang, XiaoFeng , year = 2025, month = sep, number =. A-. doi:10.48550/arXiv.2510.02373 , urldate =. arXiv , keywords =:2510.02373 , primaryclass =
-
[42]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed and Le, Quoc and Zhou, Denny , year = 2023, month = jan, number =. Chain-of-. doi:10.48550/arXiv.2201.11903 , urldate =. arXiv , keywords =:2201.11903 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2201.11903 2023
-
[43]
Simple synthetic data reduces sycophancy in large language models
Simple Synthetic Data Reduces Sycophancy in Large Language Models , author =. doi:10.48550/arXiv.2308.03958 , urldate =. arXiv , keywords =:2308.03958 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.03958
-
[44]
Welleck, Sean and Lu, Ximing and West, Peter and Brahman, Faeze and Shen, Tianxiao and Khashabi, Daniel and Choi, Yejin , year = 2022, month = sep, urldate =
2022
-
[45]
ReAct: Synergizing Reasoning and Acting in Language Models
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , year = 2023, month = mar, number =. doi:10.48550/arXiv.2210.03629 , urldate =. arXiv , keywords =:2210.03629 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.03629 2023
-
[46]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Yao, Shunyu and Yu, Dian and Zhao, Jeffrey and Shafran, Izhak and Griffiths, Thomas L. and Cao, Yuan and Narasimhan, Karthik , year = 2023, month = dec, number =. Tree of. doi:10.48550/arXiv.2305.10601 , urldate =. arXiv , keywords =:2305.10601 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.10601 2023
-
[47]
Yin, Chenlong and Sha, Zeyang and Cui, Shiwen and Meng, Changhua and Li, Zechao , year = 2026, month = apr, number =. The. doi:10.48550/arXiv.2510.22977 , urldate =. arXiv , keywords =:2510.22977 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.22977 2026
-
[48]
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models
Zhang, Yue and Li, Yafu and Cui, Leyang and Cai, Deng and Liu, Lemao and Fu, Tingchen and Huang, Xinting and Zhao, Enbo and Zhang, Yu and Chen, Yulong and Wang, Longyue and Luu, Anh Tuan and Bi, Wei and Shi, Freda and Shi, Shuming , year = 2025, month = feb, journal =. doi:10.1162/coli.a.16 , urldate =
-
[49]
Zhang, Zeyu and Bo, Xiaohe and Ma, Chen and Li, Rui and Chen, Xu and Dai, Quanyu and Zhu, Jieming and Dong, Zhenhua and Wen, Ji-Rong , year = 2024, month = apr, number =. A. doi:10.48550/arXiv.2404.13501 , urldate =. arXiv , keywords =:2404.13501 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.13501 2024
-
[50]
Zhao, Xutong and Xu, Tengyu and Wang, Xuewei and Chen, Zhengxing and Jin, Di and Tan, Liang and. Boosting. doi:10.48550/arXiv.2506.06923 , urldate =. arXiv , keywords =:2506.06923 , primaryclass =
-
[51]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Zou, Andy and Wang, Zifan and Carlini, Nicholas and Nasr, Milad and Kolter, J. Zico and Fredrikson, Matt , year = 2023, month = dec, number =. Universal and. doi:10.48550/arXiv.2307.15043 , urldate =. arXiv , keywords =:2307.15043 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.15043 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.