InternBootcamp Technical Report: Boosting LLM Reasoning with Verifiable Task Scaling
Pith reviewed 2026-05-21 22:29 UTC · model grok-4.3
The pith
Scaling the number of verifiable reasoning tasks by two orders of magnitude yields consistent LLM performance gains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that consistent performance gains in LLM reasoning arise from including more training tasks over two orders of magnitude in scale. The authors build InternBootcamp to provide 1000+ verifiable task environments and show through training that this task scaling leads to better models, with their 32B model reaching state-of-the-art on Bootcamp-EVAL while excelling elsewhere.
What carries the argument
InternBootcamp, the open-source framework that generates unlimited verifiable reasoning tasks across diverse domains for RL-based training and evaluation.
Load-bearing premise
The observed performance improvements result from the greater number and variety of verifiable tasks and not from differences in total training compute or other variables.
What would settle it
A controlled experiment training models on repeated instances of fewer tasks versus new instances of more tasks while holding total compute and data volume fixed; lack of advantage for the larger task set would falsify the scaling claim.
Figures





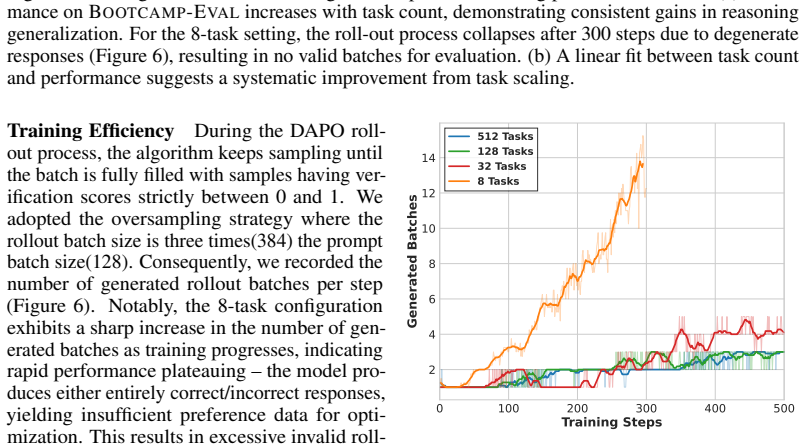





read the original abstract
Large language models (LLMs) have revolutionized artificial intelligence by enabling complex reasoning capabilities. While recent advancements in reinforcement learning (RL) have primarily focused on domain-specific reasoning tasks (e.g., mathematics or code generation), real-world reasoning scenarios often require models to handle diverse and complex environments that narrow-domain benchmarks cannot fully capture. To address this gap, we present InternBootcamp, an open-source framework comprising 1000+ domain-diverse task environments specifically designed for LLM reasoning research. Our codebase offers two key functionalities: (1) automated generation of unlimited training/testing cases with configurable difficulty levels, and (2) integrated verification modules for objective response evaluation. These features make InternBootcamp fundamental infrastructure for RL-based model optimization, synthetic data generation, and model evaluation. Although manually developing such a framework with enormous task coverage is extremely cumbersome, we accelerate the development procedure through an automated agent workflow supplemented by manual validation protocols, which enables the task scope to expand rapidly. % With these bootcamps, we further establish Bootcamp-EVAL, an automatically generated benchmark for comprehensive performance assessment. Evaluation reveals that frontier models still underperform in many reasoning tasks, while training with InternBootcamp provides an effective way to significantly improve performance, leading to our 32B model that achieves state-of-the-art results on Bootcamp-EVAL and excels on other established benchmarks. In particular, we validate that consistent performance gains come from including more training tasks, namely \textbf{task scaling}, over two orders of magnitude, offering a promising route towards capable reasoning generalist.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces InternBootcamp, an open-source framework containing 1000+ domain-diverse verifiable task environments for LLM reasoning research. It provides automated generation of unlimited training and test cases with configurable difficulty and integrated verification modules. The central empirical claim is that scaling the number of distinct training tasks by over two orders of magnitude produces consistent performance gains, enabling a 32B model to reach state-of-the-art results on the authors' Bootcamp-EVAL benchmark and other established reasoning benchmarks.
Significance. If the task-scaling result survives controls for total compute and data volume, the finding would offer a concrete, falsifiable route toward reasoning generalists that complements model-size and token scaling. The open framework with automated case generation and objective verification constitutes reusable infrastructure for RL post-training and synthetic-data research.
major comments (2)
- The task-scaling experiments (described in the results section following the framework presentation) do not report whether total training tokens, number of gradient steps, or per-task example counts were held fixed while the number of tasks was varied from ~10 to 1000+. Without these controls the observed gains remain consistent with ordinary data-volume scaling rather than the claimed effect of task diversity and verifiability.
- The training details for the 32B model (Methods section) omit hyperparameter schedules, learning-rate matching across task-count ablations, and any statistical significance tests or confidence intervals on the reported performance deltas.
minor comments (2)
- The abstract states that the 32B model 'excels on other established benchmarks' but does not name the specific benchmarks or report the absolute scores; adding these numbers would strengthen the claim.
- Notation for difficulty levels and verification success rates should be defined once in a table or appendix rather than re-introduced in multiple sections.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of experimental rigor that we will address through revisions. We respond to each major comment below.
read point-by-point responses
-
Referee: The task-scaling experiments (described in the results section following the framework presentation) do not report whether total training tokens, number of gradient steps, or per-task example counts were held fixed while the number of tasks was varied from ~10 to 1000+. Without these controls the observed gains remain consistent with ordinary data-volume scaling rather than the claimed effect of task diversity and verifiability.
Authors: We acknowledge that the manuscript does not explicitly document the controls for total training tokens, gradient steps, or per-task example counts in the task-scaling ablations. The experiments were designed to vary the number of distinct tasks while attempting to keep per-task training volume consistent, but we agree that without clear reporting it is difficult to fully separate task diversity from data-volume effects. We will revise the results section to include a detailed table of training configurations, reporting total tokens, gradient steps, and per-task example counts for each ablation point, along with a discussion of how these relate to the observed gains. revision: yes
-
Referee: The training details for the 32B model (Methods section) omit hyperparameter schedules, learning-rate matching across task-count ablations, and any statistical significance tests or confidence intervals on the reported performance deltas.
Authors: We agree that additional training details are needed for reproducibility and to support the claims. The 32B model training used a cosine learning-rate schedule with matched base rates across ablations, but these specifics and any statistical analysis were not included in the current Methods section. We will expand the Methods section to provide the full hyperparameter schedules, confirm learning-rate matching, and add statistical significance tests with confidence intervals for the key performance deltas. revision: yes
Circularity Check
No circularity: empirical task scaling validation is self-contained
full rationale
The paper is a technical report presenting an open-source framework (InternBootcamp) with 1000+ verifiable tasks and reporting experimental results on performance gains from increasing the number of training tasks over two orders of magnitude. No equations, fitted parameters, or mathematical derivations are described in the abstract or provided text. The central claim of task scaling benefits is presented as an empirical observation from training runs rather than a reduction to self-defined inputs, self-citations, or renamed known results. No load-bearing steps reduce by construction to prior author work or fitted quantities; the work is an independent empirical contribution without the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Automated agent workflow plus manual validation produces task environments whose difficulty and correctness can be trusted for RL training.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we validate that consistent performance gains come from including more training tasks, namely task scaling, over two orders of magnitude
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
scaling the number of training tasks enhances both training efficiency and LLM reasoning capabilities
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
A Survey of Reinforcement Learning for Large Reasoning Models
A survey compiling RL methods, challenges, data resources, and applications for enhancing reasoning in large language models and large reasoning models since DeepSeek-R1.
Reference graph
Works this paper leans on
-
[1]
AI-MO. Aime problems and solutions. https://artofproblemsolving.com/wiki/index. php/AIME_Problems_and_Solutions, 2023
work page 2023
-
[2]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention.arXiv preprint arXiv:2506.13585, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Enigmata: Scaling logical reasoning in large language models with synthetic verifiable puzzles
Jiangjie Chen, Qianyu He, Siyu Yuan, Aili Chen, Zhicheng Cai, Weinan Dai, Hongli Yu, Qiying Yu, Xuefeng Li, Jiaze Chen, Hao Zhou, and Mingxuan Wang. Enigmata: Scaling logical reasoning in large language models with synthetic verifiable puzzles. 2025. URL https://api.semanticscholar.org/CorpusID:278911832
work page 2025
-
[5]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page 2021
-
[6]
Yew Ken Chia, Vernon Toh Yan Han, Deepanway Ghosal, Lidong Bing, and Soujanya Poria. Puzzlevqa: Diagnosing multimodal reasoning challenges of language models with abstract visual patterns, 2024
work page 2024
-
[7]
Xtuner: A toolkit for efficiently fine-tuning llm
XTuner Contributors. Xtuner: A toolkit for efficiently fine-tuning llm. https://github.com/ InternLM/xtuner, 2023
work page 2023
-
[8]
Alphae- volve: A learning framework to discover novel alphas in quantitative investment
Can Cui, Wei Wang, Meihui Zhang, Gang Chen, Zhaojing Luo, and Beng Chin Ooi. Alphae- volve: A learning framework to discover novel alphas in quantitative investment. In Guoliang Li, Zhanhuai Li, Stratos Idreos, and Divesh Srivastava, editors,SIGMOD ’21: International Conference on Management of Data, Virtual Event, China, June 20-25, 2021, pages 2208–2216...
-
[10]
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Xinrun Du, Yifan Yao, Kaijing Ma, Bingli Wang, Tianyu Zheng, King Zhu, Minghao Liu, Yiming Liang, Xiaolong Jin, Zhenlin Wei, et al. Supergpqa: Scaling llm evaluation across 285 graduate disciplines.arXiv preprint arXiv:2502.14739, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Stream of search (sos): Learning to search in language
Kanishk Gandhi, Denise HJ Lee, Gabriel Grand, Muxin Liu, Winson Cheng, Archit Sharma, and Noah Goodman. Stream of search (sos): Learning to search in language. InFirst Conference on Language Modeling
-
[12]
Deepanway Ghosal, Vernon Toh Yan Han, Yew Ken Chia, , and Soujanya Poria. Are language models puzzle prodigies? algorithmic puzzles unveil serious challenges in multimodal reasoning. arXiv preprint arXiv:2403.03864, 2024
-
[13]
Panagiotis Giadikiaroglou, Maria Lymperaiou, Giorgos Filandrianos, and Giorgos Stamou. Puzzle solving using reasoning of large language models: A survey.arXiv preprint arXiv:2402.11291, 2024
-
[14]
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, et al. Towards an ai co-scientist. arXiv preprint arXiv:2502.18864, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[17]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021. 12
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Highly accurate protein structure prediction with alphafold.nature, 596(7873):583–589, 2021
John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ron- neberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin Žídek, Anna Potapenko, et al. Highly accurate protein structure prediction with alphafold.nature, 596(7873):583–589, 2021
work page 2021
-
[21]
Big-bench extra hard.arXiv preprint arXiv:2502.19187, 2025
Mehran Kazemi, Bahare Fatemi, Hritik Bansal, John Palowitch, Chrysovalantis Anastasiou, Sanket Vaibhav Mehta, Lalit K Jain, Virginia Aglietti, Disha Jindal, Peter Chen, et al. Big-bench extra hard.arXiv preprint arXiv:2502.19187, 2025
-
[22]
Fastmcts: A simple sampling strategy for data synthesis.arXiv preprint arXiv:2502.11476, 2025
Peiji Li, Kai Lv, Yunfan Shao, Yichuan Ma, Linyang Li, Xiaoqing Zheng, Xipeng Qiu, and Qipeng Guo. Fastmcts: A simple sampling strategy for data synthesis.arXiv preprint arXiv:2502.11476, 2025
-
[23]
Quantum internet: A vision for the road ahead,
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson, Pushm...
-
[24]
Bill Yuchen Lin, Ronan Le Bras, Kyle Richardson, Ashish Sabharwal, Radha Poovendran, Peter Clark, and Yejin Choi. Zebralogic: On the scaling limits of llms for logical reasoning.arXiv preprint arXiv:2502.01100, 2025
-
[25]
Beyond outcomes: Transparent assessment of LLM reasoning in games.CoRR, abs/2412.13602,
Wenye Lin, Jonathan Roberts, Yunhan Yang, Samuel Albanie, Zongqing Lu, and Kai Han. Beyond outcomes: Transparent assessment of LLM reasoning in games.CoRR, abs/2412.13602,
-
[27]
Are your llms capable of stable reasoning?arXiv preprint arXiv:2412.13147, 2024
Junnan Liu, Hongwei Liu, Linchen Xiao, Ziyi Wang, Kuikun Liu, Songyang Gao, Wenwei Zhang, Songyang Zhang, and Kai Chen. Are your llms capable of stable reasoning?arXiv preprint arXiv:2412.13147, 2024
-
[29]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scien- tist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Kaijing Ma, Xinrun Du, Yunran Wang, Haoran Zhang, Zhoufutu Wen, Xingwei Qu, Jian Yang, Jiaheng Liu, Minghao Liu, Xiang Yue, et al. Kor-bench: Benchmarking language models on knowledge-orthogonal reasoning tasks.arXiv preprint arXiv:2410.06526, 2024
-
[31]
Chinmay Mittal, Krishna Kartik, Parag Singla, et al. Puzzlebench: Can llms solve challenging first-order combinatorial reasoning problems.arXiv preprint arXiv:2402.02611, 2024
-
[32]
Slice sampling.The annals of statistics, 31(3):705–767, 2003
Radford M Neal. Slice sampling.The annals of statistics, 31(3):705–767, 2003
work page 2003
-
[33]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling, 2024. 13
work page 2024
- [34]
-
[35]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Korgym: A dynamic game platform for llm reasoning evaluation
Jiajun Shi, Jian Yang, Jiaheng Liu, Xingyuan Bu, Jiangjie Chen, Junting Zhou, Kaijing Ma, Zhoufutu Wen, Bingli Wang, Yancheng He, Liang Song, Hualei Zhu, Shilong Li, Xing-Rui Wang, Wei Zhang, Ru Yuan, Yifan Yao, Wen lei Yang, Yunli Wang, Siyuan Fang, Siyu Yuan, Qianyu He, Xian Tang, Yingshui Tan, Wangchunshu Zhou, Zhaoxiang Zhang, Zhoujun Li, Wenhao Huang...
-
[37]
URLhttps://api.semanticscholar.org/CorpusID:278769502
-
[38]
Welcome to the era of experience.Google AI, 1, 2025
David Silver and Richard S Sutton. Welcome to the era of experience.Google AI, 1, 2025
work page 2025
-
[39]
Mas- tering the game of go with deep neural networks and tree search.nature, 529(7587):484–489, 2016
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driess- che, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mas- tering the game of go with deep neural networks and tree search.nature, 529(7587):484–489, 2016
work page 2016
-
[41]
Mastering the game of go without human knowledge.nature, 550(7676):354–359, 2017
David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. Mastering the game of go without human knowledge.nature, 550(7676):354–359, 2017
work page 2017
-
[42]
Jingqi Tong, Jixin Tang, Hangcheng Li, Yurong Mou, Ming Zhang, Jun Zhao, Yanbo Wen, Fan Song, Jiahao Zhan, Yuyang Lu, et al. Code2logic: Game-code-driven data synthesis for enhancing vlms general reasoning.arXiv preprint arXiv:2505.13886, 2025
-
[43]
Solving olympiad geometry without human demonstrations.Nature, 625(7995):476–482, 2024
Trieu H Trinh, Yuhuai Wu, Quoc V Le, He He, and Thang Luong. Solving olympiad geometry without human demonstrations.Nature, 625(7995):476–482, 2024
work page 2024
-
[44]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Scientific discovery in the age of artificial intelligence.Nature, 620(7972):47–60, 2023
Hanchen Wang, Tianfan Fu, Yuanqi Du, Wenhao Gao, Kexin Huang, Ziming Liu, Payal Chandak, Shengchao Liu, Peter Van Katwyk, Andreea Deac, et al. Scientific discovery in the age of artificial intelligence.Nature, 620(7972):47–60, 2023
work page 2023
-
[46]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V . Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/ forum?...
work page 2023
-
[47]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[48]
Liang Wen, Yunke Cai, Fenrui Xiao, Xin He, Qi An, Zhenyu Duan, Yimin Du, Junchen Liu, Lifu Tang, Xiaowei Lv, Haosheng Zou, Yongchao Deng, Shousheng Jia, and Xiangzheng Zhang. Light-r1: Curriculum sft, dpo and rl for long cot from scratch and beyond, 2025. URL https://arxiv.org/abs/2503.10460
-
[49]
WizardLM: Empowering large pre-trained language models to follow complex instructions
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244, 2023. 14
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Learning to Reason under Off-Policy Guidance
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. Learning to reason under off-policy guidance.arXiv preprint arXiv:2504.14945, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jian Yang, Jiaxi Yang, Jingren Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2025
-
[53]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
work page 2023
-
[54]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[55]
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models.arXiv preprint arXiv:2309.12284, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Yu Yue, Yufeng Yuan, Qiying Yu, Xiaochen Zuo, Ruofei Zhu, Wenyuan Xu, Jiaze Chen, Chengyi Wang, TianTian Fan, Zhengyin Du, et al. Vapo: Efficient and reliable reinforcement learning for advanced reasoning tasks.arXiv preprint arXiv:2504.05118, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Italian crossword generator: Enhancing education through interactive word puzzles
Kamyar Zeinalipour, Tommaso Iaquinta, Asya Zanollo, Giovanni Angelini, Leonardo Rigutini, Marco Maggini, and Marco Gori. Italian crossword generator: Enhancing education through interactive word puzzles. 2023
work page 2023
-
[59]
TTRL: Test-Time Reinforcement Learning
Yuxin Zuo, Kaiyan Zhang, Li Sheng, Shang Qu, Ganqu Cui, Xuekai Zhu, Haozhan Li, Yuchen Zhang, Xinwei Long, Ermo Hua, et al. Ttrl: Test-time reinforcement learning.arXiv preprint arXiv:2504.16084, 2025. 15 A Task Sources and Curation We notice that there exists a wide range of reasoning tasks in the real world that are verifiable. We believe that these tas...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.