DoubleAgents: Human-Agent Alignment in a Socially Embedded Workflow
Pith reviewed 2026-05-18 17:05 UTC · model grok-4.3
The pith
DoubleAgents uses three distributed cognition components to increase user comfort and reliance when delegating evolving coordination tasks to AI agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
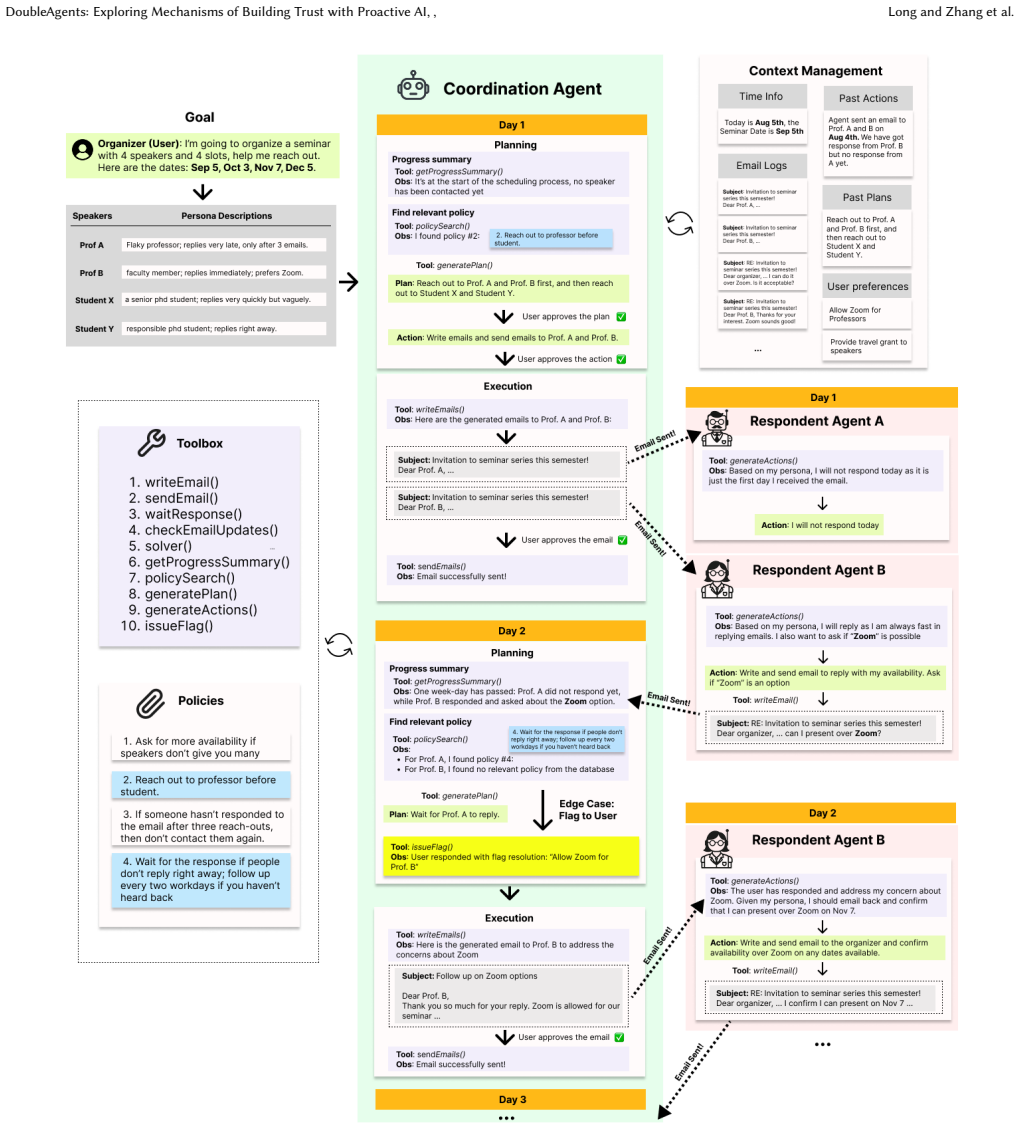
DoubleAgents demonstrates that a distributed cognition approach to human-agent alignment enables effective support for coordination tasks by combining a coordination agent that maintains state and proposes actions, a dashboard visualization that renders the agent's reasoning legible for evaluation, and a policy module that transforms user edits into reusable alignment artifacts including coordination policies, email templates, and stop hooks, resulting in measurable increases in user comfort with task offloading and system reliance across a two-day lab study and three real-world deployments.
What carries the argument
The three distributed cognition components consisting of a coordination agent for state maintenance and action proposals, a dashboard visualization for making reasoning legible, and a policy module that converts user edits into reusable artifacts.
Load-bearing premise
The observed increases in comfort and reliance over time are caused by the three distributed cognition components rather than study novelty, small sample size, or other unmeasured factors in the lab and deployment settings.
What would settle it
Running a controlled comparison study in which participants use DoubleAgents without the dashboard or without the policy module and finding no corresponding rise in comfort or reliance after two days of use.
Figures






read the original abstract
Aligning agentic AI with user intent is critical for delegating complex, socially embedded tasks, yet user preferences are often implicit, evolving, and difficult to specify upfront. We present DoubleAgents, a system for human-agent alignment in coordination tasks, grounded in distributed cognition. DoubleAgents integrates three components: (1) a coordination agent that maintains state and proposes plans and actions, (2) a dashboard visualization that makes the agent's reasoning legible for user evaluation, and (3) a policy module that transforms user edits into reusable alignment artifacts, including coordination policies, email templates, and stop hooks, which improve system behavior over time. We evaluate DoubleAgents through a two-day lab study (n=10), three real-world deployments, and a technical evaluation. Participants' comfort in offloading tasks and reliance on DoubleAgents both increased over time, correlating with the three distributed cognition components. Participants still required control at points of uncertainty - edge-case flagging and context-dependent actions. We contribute a distributed cognition approach to human-agent alignment in socially embedded tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DoubleAgents, a system for human-agent alignment in socially embedded coordination tasks, grounded in distributed cognition. It integrates three components: a coordination agent that maintains state and proposes plans, a dashboard that visualizes the agent's reasoning for user evaluation, and a policy module that converts user edits into reusable artifacts such as coordination policies, email templates, and stop hooks. The authors evaluate the system via a two-day lab study (n=10), three real-world deployments, and a technical evaluation, reporting that participants' comfort in offloading tasks and reliance on DoubleAgents increased over time and correlated with the three components. The work highlights the continued need for user control at points of uncertainty such as edge cases.
Significance. If the attribution of improvements to the specific components holds under more rigorous controls, the work provides a promising structured approach to handling implicit and evolving user preferences in agentic workflows. The policy module's mechanism for turning edits into reusable artifacts and the dashboard's emphasis on legibility address practical challenges in human-AI coordination. The combination of lab, deployment, and technical evaluations adds breadth, though the current evidence remains preliminary due to limited methodological detail.
major comments (2)
- [Evaluation section and abstract] The central empirical claim—that increases in offloading comfort and reliance correlate with the three distributed-cognition components—rests on observations from the lab study (n=10 over two days) and deployments, yet the manuscript provides no details on the specific measures employed, statistical analyses, controls for confounds, baseline comparisons, or exclusion criteria. This omission leaves the attribution vulnerable to alternative explanations such as novelty effects or small-sample variability.
- [Evaluation section] No component ablation, control conditions, or comparative baselines are described that would isolate the individual contributions of the coordination agent, dashboard, and policy module. Without such isolation, the reported correlation cannot be confidently distinguished from generic exposure to a new system or unmeasured variables in the deployment settings.
minor comments (1)
- The abstract and evaluation descriptions would benefit from clearer specification of the exact quantitative or qualitative instruments used to track comfort and reliance over time.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for acknowledging the potential of the distributed-cognition approach in DoubleAgents. We address the major comments point by point below and will revise the Evaluation section to increase methodological transparency.
read point-by-point responses
-
Referee: [Evaluation section and abstract] The central empirical claim—that increases in offloading comfort and reliance correlate with the three distributed-cognition components—rests on observations from the lab study (n=10 over two days) and deployments, yet the manuscript provides no details on the specific measures employed, statistical analyses, controls for confounds, baseline comparisons, or exclusion criteria. This omission leaves the attribution vulnerable to alternative explanations such as novelty effects or small-sample variability.
Authors: We agree that the current manuscript lacks sufficient detail on the evaluation measures and analyses. The lab study used pre- and post-session 7-point Likert scales for comfort in offloading and reliance, daily usage logs, and semi-structured interviews analyzed via thematic coding. Observed increases were tracked through within-subjects changes across the two days. In the revision we will add explicit descriptions of all measures, the analysis procedures (including any descriptive statistics or non-parametric tests applied to the small sample), discussion of confounds such as novelty effects, and clarification that no participants were excluded. We will also note the absence of external baselines given the focus on longitudinal within-system changes. revision: yes
-
Referee: [Evaluation section] No component ablation, control conditions, or comparative baselines are described that would isolate the individual contributions of the coordination agent, dashboard, and policy module. Without such isolation, the reported correlation cannot be confidently distinguished from generic exposure to a new system or unmeasured variables in the deployment settings.
Authors: We acknowledge that the lack of ablations prevents strong causal isolation of each component. The study evaluated the integrated system to preserve the distributed-cognition workflow in realistic settings. In the revised manuscript we will add a limitations subsection explaining this design decision, provide more granular qualitative observations linking specific components to usage patterns and self-reported changes, and outline future controlled experiments that could isolate contributions. This will clarify the interpretive nature of the current correlations without overstating the evidence. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an HCI system (DoubleAgents) with three components grounded in distributed cognition and reports empirical observations from a lab study (n=10) and deployments. Participants' comfort and reliance increased over time and correlated with the components. No equations, parameter fittings, mathematical derivations, or predictions derived from inputs are present. Claims rest on direct study observations rather than any self-definitional reduction, fitted-input-as-prediction, or self-citation load-bearing steps. The provided text contains no uniqueness theorems, ansatzes smuggled via citation, or renaming of known results. The central attribution may face validity questions around confounds or controls, but this is unrelated to circularity; the evaluation chain is self-contained through system implementation and user data collection.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Distributed cognition provides a suitable framework for designing human-agent alignment in socially embedded coordination tasks.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Participants' comfort in offloading tasks and reliance on DoubleAgents both increased over time, correlating with the three distributed cognition components.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Saleh Afroogh, Ali Akbari, Emmie Malone, Mohammadali Kargar, and Hananeh Alambeigi. 2024. Trust in AI: Progress, Challenges, and Future Directions.Human- ities and Social Sciences Communications11, 1 (2024), 1–13. doi:10.1057/s41599- 024-04044-8
-
[2]
Arriaga, and Adam Tauman Kalai
Gati Aher, Rosa I. Arriaga, and Adam Tauman Kalai. 2023. Using Large Language Models to Simulate Multiple Humans and Replicate Human Subject Studies. arXiv:2208.10264 [cs.CL] https://arxiv.org/abs/2208.10264
-
[3]
Anthropic. 2025. Introducing Computer Use, a New Claude 3.5 Sonnet, and Claude 3.5 Haiku.Anthropic News(March 2025). https://www.anthropic.com/news/3-5- models-and-computer-use
work page 2025
-
[4]
Sai Anirudh Athaluri, Sandeep Varma Manthena, VSR Krishna Manoj Kesapra- gada, Vineel Yarlagadda, Tirth Dave, and Rama Tulasi Siri Duddumpudi. 2023. Exploring the boundaries of reality: investigating the phenomenon of artificial in- telligence hallucination in scientific writing through ChatGPT references.Cureus 15, 4 (2023)
work page 2023
-
[5]
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, et al. 2022. Constitutional AI: Harmlessness from AI feedback.arXiv preprint arXiv:2212.08073(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
K. Beratan. 2007. A Cognition-based View of Decision Processes in Com- plex Social–Ecological Systems.Ecology and Society12 (2007), 27. https: //api.semanticscholar.org/CorpusId:27199163
work page 2007
-
[7]
Elsa Fouragnan, Gabriele Chierchia, Susanne Greiner, Rémi Neveu, Paolo Avesani, and Giorgio Coricelli. 2013. Reputational Priors Magnify Striatal Responses to Violations of Trust.The Journal of Neuroscience33 (2013), 3602 – 3611. https: //api.semanticscholar.org/CorpusID:14023190
work page 2013
-
[8]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [9]
-
[10]
Sandra G Hart. 2006. NASA-task load index (NASA-TLX); 20 years later. In Proceedings of the human factors and ergonomics society annual meeting, Vol. 50. Sage publications Sage CA: Los Angeles, CA, 904–908
work page 2006
-
[11]
Gaole He, Gianluca Demartini, and Ujwal Gadiraju. 2025. Plan-Then-Execute: An Empirical Study of User Trust and Team Performance When Using LLM Agents As A Daily Assistant. InProceedings of the CHI Conference on Human Factors in Computing Systems. ACM. doi:10.1145/3706598.3713218
-
[12]
Luke Hewitt, Ashwini Ashokkumar, Isaias Ghezae, and Robb Willer. 2024. Pre- dicting Results of Social Science Experiments Using Large Language Models. (2024). Working Paper
work page 2024
- [13]
-
[14]
Saffron Huang, Divya Siddarth, Liane Lovitt, Thomas I. Liao, Esin Durmus, Alex Tamkin, and Deep Ganguli. 2024. Collective Constitutional AI: Aligning a Lan- guage Model with Public Input. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’24). Association for Computing Machinery. doi:10.1145/3630106.3658979
-
[15]
Peter Kollock. 1998. SOCIAL DILEMMAS: The Anatomy of Cooperation.Re- view of Sociology24 (1998), 183–214. https://api.semanticscholar.org/CorpusID: 21021101
work page 1998
-
[16]
Roderick M. Kramer. 1999. TRUST AND DISTRUST IN ORGANIZATIONS: Emerg- ing Perspectives, Enduring Questions.Annual Review of Psychology50, Volume 50, 1999 (Feb. 1999), 569–598. doi:10.1146/annurev.psych.50.1.569 Publisher: Annual Reviews
-
[17]
Michel Krieger, Emily Margarete Stark, and Scott R Klemmer. 2009. Coordinating tasks on the commons: designing for personal goals, expertise and serendipity. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems. 1485–1494
work page 2009
-
[18]
Amazon AGI Labs. 2025. Introducing Amazon Nova Act.Amazon Science Blog (March 2025). https://labs.amazon.science/blog/nova-act
work page 2025
- [19]
-
[20]
A. Lansing, Natalie J. Romero, Elizabeth Siantz, Vivianne Silva, Kimberly Center, Danielle L. Casteel, and T. Gilmer. 2023. Building trust: Leadership reflections on community empowerment and engagement in a large urban initiative.BMC Public Health23 (2023). https://api.semanticscholar.org/CorpusId:259265327
work page 2023
-
[21]
Tao Long, Katy Ilonka Gero, and Lydia B Chilton. 2024. Not Just Novelty: A Lon- gitudinal Study on Utility and Customization of an AI Workflow. InProceedings of the 2024 ACM Designing Interactive Systems Conference(Copenhagen, Denmark) (DIS ’24). Association for Computing Machinery, New York, NY, USA, 782–803. doi:10.1145/3643834.3661587
-
[22]
Manus AI. 2025. Manus: The General AI Agent. https://manus.im/ Accessed: 2025-04-08
work page 2025
-
[23]
Tula Masterman, Sandi Besen, Mason Sawtell, and Alex Chao. 2024. The landscape of emerging ai agent architectures for reasoning, planning, and tool calling: A survey.arXiv preprint arXiv:2404.11584(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Roger C. Mayer, James H. Davis, and F. David Schoorman. 1995. An Integrative Model of Organizational Trust.The Academy of Management Review20, 3 (1995), 709–734. doi:10.2307/258792 Publisher: Academy of Management
-
[25]
Jakob Nielsen. 1992. Finding usability problems through heuristic evaluation. In Proceedings of the SIGCHI conference on Human factors in computing systems
work page 1992
-
[26]
OpenAI. 2025. Introducing Operator.OpenAI Blog(January 2025). https: //openai.com/index/introducing-operator/
work page 2025
-
[27]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, et al
-
[28]
InAdvances in Neural Information Processing Systems (NeurIPS), Vol
Training language models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 35. 27730– 27744
- [29]
-
[30]
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative Agents: Interactive Simulacra DoubleAgents: Exploring Mechanisms of Building Trust with Proactive AI, , Long and Zhang et al. of Human Behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Tech...
work page 2023
-
[31]
Joon Sung Park, Lindsay Popowski, Carrie Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2022. Social simulacra: Creating populated prototypes for social computing systems. InProceedings of the 35th Annual ACM Symposium on User Interface Software and Technology. 1–18
work page 2022
-
[32]
Wedin, James Wexler, Mahima Pushkarna, Aaron Donsbach, Nitesh Goyal, Carrie J
Savvas Petridis, Benjamin D. Wedin, James Wexler, Mahima Pushkarna, Aaron Donsbach, Nitesh Goyal, Carrie J. Cai, and Michael Terry. 2024. Constitution- Maker: Interactively Critiquing Large Language Models by Converting Feedback into Principles. InProceedings of the 29th International Conference on Intelligent User Interfaces (IUI ’24). ACM, 853–868
work page 2024
-
[33]
Alberto Purpura, Sahil Wadhwa, Jesse Zymet, Akshay Gupta, Andy Luo, Melissa Kazemi Rad, Swapnil Shinde, and Mohammad Shahed Sorower. 2025. Building Safe GenAI Applications: An End-to-End Overview of Red Teaming for Large Language Models. arXiv:2503.01742 [cs.CL] https://arxiv.org/abs/2503. 01742
-
[34]
Yosef S Razin and Karen M Feigh. 2024. Converging Measures and an Emer- gent Model: A Meta-Analysis of Human-Machine Trust Questionnaires.ACM Transactions on Human-Robot Interaction13, 4 (2024), 1–41
work page 2024
-
[35]
John K. Rempel, John G. Holmes, and Mark P. Zanna. 1985. Trust in close re- lationships.Journal of Personality and Social Psychology49, 1 (1985), 95–112. doi:10.1037/0022-3514.49.1.95 Place: US Publisher: American Psychological Asso- ciation
-
[36]
Ross, Fernando Martinez, Stephanie Houde, Michael Muller, and Justin D
Steven I. Ross, Fernando Martinez, Stephanie Houde, Michael Muller, and Justin D. Weisz. 2023. The Programmer’s Assistant: Conversational Interaction with a Large Language Model for Software Development. InProceedings of the 28th International Conference on Intelligent User Interfaces(Sydney, NSW, Australia) (IUI ’23). Association for Computing Machinery,...
-
[37]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessí, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: language models can teach themselves to use tools. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Curran Associates ...
work page 2023
-
[38]
Significant Gravitas. [n. d.].AutoGPT. https://github.com/Significant-Gravitas/ AutoGPT
-
[39]
Karthik Sreedhar, Alice Cai, Jenny Ma, Jeffrey V Nickerson, and Lydia B Chilton
-
[40]
InPro- ceedings of the 30th International Conference on Intelligent User Interfaces (IUI ’25)
Simulating Cooperative Prosocial Behavior with Multi-Agent LLMs: Evidence and Mechanisms for AI Agents to Inform Policy Decisions. InPro- ceedings of the 30th International Conference on Intelligent User Interfaces (IUI ’25). Association for Computing Machinery, New York, NY, USA, 1272–1286. doi:10.1145/3708359.3712149
-
[41]
Karthik Sreedhar and Lydia B. Chilton. 2025. Simulating Human Strategic Behav- ior: Comparing Single and Multi-agent LLMs. InProceedings of the 58th Hawaii International Conference on System Sciences (HICSS)
work page 2025
-
[42]
Kaya Stechly, Karthik Valmeekam, and Subbarao Kambhampati. 2025. ON THE SELF-VERIFICATION LIMITATIONS OF LARGE LANGUAGE MODELS ON REA- SONING AND PLANNING TASKS. (2025)
work page 2025
-
[43]
Meta Fundamental AI Research Diplomacy Team, Anton Bakhtin, Noam Brown, Emily Dinan, Gabriele Farina, et al . 2022. Human-level play in the game of Diplomacy by combining language models with strategic reasoning.Science378, 6622 (2022), 1067–1074. doi:10.1126/science.ade9097
-
[44]
Jaime Teevan, Shamsi T Iqbal, Carrie J Cai, Jeffrey P Bigham, Michael S Bernstein, and Elizabeth M Gerber. 2016. Productivity decomposed: Getting big things done with little microtasks. InProceedings of the 2016 CHI Conference Extended Abstracts on Human Factors in Computing Systems. 3500–3507
work page 2016
-
[45]
Harsh Trivedi, Tushar Khot, Mareike Hartmann, Ruskin Manku, Vinty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, and Niranjan Balasubramanian
- [46]
- [47]
- [48]
-
[49]
Qian Yang, Aaron Steinfeld, Carolyn Rosé, and John Zimmerman. 2020. Re- examining Whether, Why, and How Human-AI Interaction Is Uniquely Difficult to Design. InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’20). Association for Computing Machinery, New York, NY, USA, 1–13. doi:10.1145/3313831.3376301
-
[50]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2024. 𝜏- bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains. (2024). arXiv:2406.12045 [cs.AI] https://arxiv.org/abs/2406.12045
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. doi:10.48550/arXiv.2305.10601 arXiv:2305.10601 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.10601 2023
-
[52]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR)
work page 2023
- [53]
-
[54]
Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, et al. 2025. Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models.Computational Linguistics(2025), 1–46
work page 2025
- [55]
-
[56]
Xuhui Zhou, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Yu, Zhengyang Qi, Louis-Philippe Morency, Yonatan Bisk, Daniel Fried, Graham Neubig, et al
-
[57]
Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667(2023). A DoubleAgents Prompts A.1 Coordination Agent A.1.1 Progress Summary. You are an expert seminar organizer assistant. Your task is to analyze the current progress and return a JSON object. Input information may include: - Speaker details (pers...
-
[58]
Send email to X to request availability for slots XXX
"Send email to X to request availability for slots XXX" (initial outreach). 2. "Follow up with X" (if email sent but no reply). 3. "Wait for response from X" (if email sent and still within expected waiting window). 4. "Confirm and assign slot for X" (only if X has shared availability; avoid finalizing too early unless time is urgent). 5. "Send clarificat...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.