Recognition: unknown
UIPress: Bringing Optical Token Compression to UI-to-Code Generation
Pith reviewed 2026-05-10 17:16 UTC · model grok-4.3
The pith
UIPress inserts a learned compression module between ViT encoder and LLM decoder to reduce UI screenshot tokens from ~6700 to a fixed 256 while raising generation quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
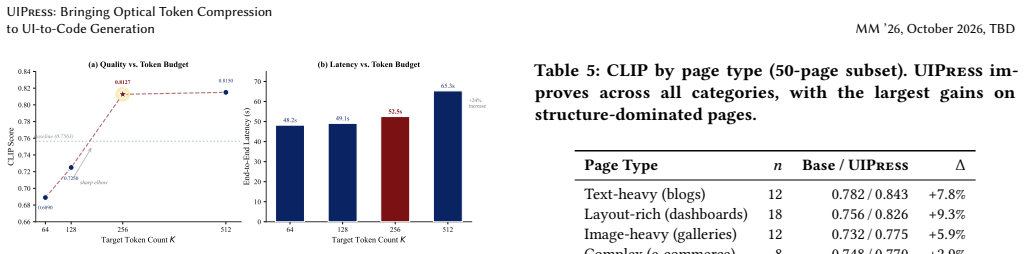
UIPress is the first encoder-side learned compression method for UI-to-Code: a lightweight module placed after the frozen ViT encoder of Qwen3-VL-8B that compresses approximately 6700 visual tokens to a fixed budget of 256 using depthwise-separable convolutions, element-guided spatial reweighting, and Transformer refinement, then fine-tunes the LLM decoder with LoRA; under identical base-model conditions it reaches a CLIP score of 0.8127 on Design2Code, surpassing the uncompressed baseline by 7.5 percent and the best inference-time baseline by 4.6 percent while delivering a 9.1 times reduction in time-to-first-token.
What carries the argument
The UIPress compression module, which learns to map full ViT visual token sequences into a fixed 256-token representation via depthwise-separable convolutions, element-guided spatial reweighting, and Transformer refinement before the LLM decoder, supplemented by LoRA adaptation on the decoder.
If this is right
- Reduces prefill latency enough to support real-time UI prototyping workflows.
- Demonstrates that task-specific optical compression can outperform both uncompressed and heuristic selection baselines on the same base model.
- Adds only 21.7 million trainable parameters (0.26 percent of the 8B model) while preserving or improving output quality.
- Establishes encoder-side learned compression as viable for UI-to-Code where prior methods either kept full token length or used task-agnostic heuristics.
- Opens the possibility of applying the same compression pattern to other long-output vision-to-code or vision-to-text tasks.
Where Pith is reading between the lines
- The same compression pattern could be tested on chart-to-code or document-to-structured-data tasks that also suffer from high visual token counts.
- Fixed-budget compression may need to be replaced by adaptive budgets that scale with UI complexity to avoid under-compression on dense screens.
- Because the encoder stays frozen, the method could be ported to other VLMs without retraining the entire vision backbone.
- Lower token counts may enable larger batch sizes during serving, improving throughput for UI generation services beyond the reported single-example speedup.
Load-bearing premise
That a fixed 256-token compression still supplies enough visual detail for the LLM to produce accurate structured HTML and CSS across varied UI designs, and that LoRA can reliably close any gap created by the compression step.
What would settle it
Measuring whether CLIP score and code-visual alignment drop sharply when the same model is tested on a held-out set of highly detailed or interactive UIs whose layout complexity exceeds the Design2Code training distribution.
Figures






read the original abstract
UI-to-Code generation requires vision-language models (VLMs) to produce thousands of tokens of structured HTML/CSS from a single screenshot, making visual token efficiency critical. Existing compression methods either select tokens at inference time using task-agnostic heuristics, or zero out low-attention features without actually shortening the sequence -- neither truly reduces prefill latency or adapts to the non-uniform information density of UI screenshots. Meanwhile, optical (encoder-side learned) compression has shown strong results for document OCR, yet no prior work has adapted this paradigm to UI-to-Code generation. We propose UIPress, a lightweight learned compression module inserted between the frozen ViT encoder and the LLM decoder of Qwen3-VL-8B. UIPress combines depthwise-separable convolutions, element-guided spatial reweighting, and Transformer refinement to compress ${\sim}$6{,}700 visual tokens to a fixed budget of 256. Together with Low-Rank Adaptation (LoRA) on the decoder to bridge the representation gap, the entire system adds only ${\sim}$21.7M trainable parameters (0.26\% of the 8B base model). Under a fair comparison on the same base model against four baselines on Design2Code, UIPress at 256 tokens achieves a CLIP score of 0.8127, outperforming the uncompressed baseline by +7.5\% and the strongest inference-time method by +4.6\%, while delivering 9.1$\times$ time-to-first-token speedup. To the best of our knowledge, UIPress is the first encoder-side learned compression method for the UI-to-Code task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces UIPress, a lightweight learned compression module placed between the frozen ViT encoder and LLM decoder of Qwen3-VL-8B for UI-to-Code generation. It reduces ~6700 visual tokens to a fixed budget of 256 tokens using depthwise-separable convolutions, element-guided spatial reweighting, and Transformer refinement, combined with LoRA on the decoder (adding ~21.7M trainable parameters, or 0.26% of the base model). On the Design2Code benchmark, UIPress reports a CLIP score of 0.8127, claiming +7.5% over the uncompressed baseline, +4.6% over the strongest inference-time baseline, and 9.1× time-to-first-token speedup, while asserting it is the first encoder-side learned compression method for this task.
Significance. If the reported gains can be isolated to the compression module under controlled conditions, the work would demonstrate a practical advance in token-efficient vision-language modeling for structured output generation from UI screenshots. The combination of encoder-side optical compression with minimal adaptation parameters offers a promising direction beyond inference-time heuristics, with clear efficiency benefits for prefill latency.
major comments (2)
- [Abstract / Experiments] Abstract and experimental comparison: The central claim of +7.5% CLIP improvement and 9.1× TTFT speedup over the uncompressed baseline on the same Qwen3-VL-8B model is load-bearing, yet the abstract does not specify whether this baseline receives the same LoRA fine-tuning applied to UIPress 'to bridge the representation gap.' If the baseline is the frozen model while UIPress is adapted, the gains cannot be attributed to the compression module (depthwise-separable convs + reweighting + Transformer) rather than adaptation.
- [Experiments] Experimental section: Concrete numbers (CLIP 0.8127, +7.5%, +4.6%, 9.1×) are presented without details on baseline implementations, exact data splits, variance across runs, or statistical tests. This omission prevents verification that the outperformance over four baselines is robust and isolates the proposed compression technique.
minor comments (2)
- [Abstract] Abstract: The 'to the best of our knowledge' claim of being the first encoder-side learned compression for UI-to-Code should be supported by a more explicit related-work comparison in the main text.
- [Abstract] Notation: Ensure consistent rendering of the approximate token count (~6,700) and parameter count throughout the manuscript.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our manuscript. We address each major comment point by point below, providing clarifications and committing to revisions where needed to improve the rigor and transparency of our experimental claims.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experimental comparison: The central claim of +7.5% CLIP improvement and 9.1× TTFT speedup over the uncompressed baseline on the same Qwen3-VL-8B model is load-bearing, yet the abstract does not specify whether this baseline receives the same LoRA fine-tuning applied to UIPress 'to bridge the representation gap.' If the baseline is the frozen model while UIPress is adapted, the gains cannot be attributed to the compression module (depthwise-separable convs + reweighting + Transformer) rather than adaptation.
Authors: We appreciate this important observation on isolating the contribution of the compression module. The LoRA adaptation is introduced specifically to bridge the representation gap between the compressed visual tokens and the LLM decoder, as stated in the manuscript. The uncompressed baseline refers to the original Qwen3-VL-8B model in its standard pre-trained configuration without additional adaptation, which is the conventional reference point for demonstrating improvements from new modules. However, we acknowledge that the abstract and experimental description do not explicitly clarify this setup, which could lead to ambiguity in attributing gains. We will revise the abstract and the experimental section (including Table 1 and surrounding text) to explicitly describe the configuration of every baseline, including the uncompressed case. We will also add results for an uncompressed baseline fine-tuned with the identical LoRA setup to more cleanly isolate the effect of the proposed encoder-side compression. revision: yes
-
Referee: [Experiments] Experimental section: Concrete numbers (CLIP 0.8127, +7.5%, +4.6%, 9.1×) are presented without details on baseline implementations, exact data splits, variance across runs, or statistical tests. This omission prevents verification that the outperformance over four baselines is robust and isolates the proposed compression technique.
Authors: We agree that additional experimental details are necessary for reproducibility and verification. The full manuscript contains descriptions of the baselines (Section 4.2) and the Design2Code benchmark, but we will expand this section to provide: explicit implementation details for each of the four baselines (including any inference-time heuristics or token selection methods), the precise train/validation/test splits used, and any available run-to-run variance. Where multiple runs were performed, we will report standard deviations; for statistical significance, we will include appropriate tests (e.g., paired t-tests) on the CLIP scores. These additions will be incorporated into the revised experimental section and supplementary material. revision: yes
Circularity Check
No circularity; empirical results are measured outcomes, not derived by construction
full rationale
The paper proposes UIPress as an encoder-side compression module (depthwise-separable convs + reweighting + Transformer) inserted into Qwen3-VL-8B, with LoRA on the decoder, and reports measured CLIP scores (0.8127) and speedups (9.1×) on the Design2Code benchmark against baselines. The token budget of 256 is an explicit fixed design choice, not a fitted parameter whose value is then 'predicted' or forced to match the gains. No equations, self-citations, uniqueness theorems, or ansatzes are invoked to derive the central claims; the improvements are presented as direct empirical measurements. The derivation chain is therefore self-contained against external benchmarks and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- token budget =
256
- added trainable parameters =
21.7M
axioms (2)
- domain assumption Freezing the ViT encoder while training only the compression module and LoRA suffices for effective adaptation.
- domain assumption CLIP score serves as a reliable proxy for the semantic and visual fidelity of generated UI code.
invented entities (1)
-
UIPress compression module
no independent evidence
Reference graph
Works this paper leans on
-
[2]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Jun- yang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-VL: A Versatile Vision- Language Model for Understanding, Localization, Text Reading, and Beyond. arXiv:2308.12966 [cs.CV] https://arxiv.org/abs/2308.12966
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al . 2025. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [5]
-
[7]
Wentong Chen, Junbo Cui, Jinyi Hu, Yujia Qin, Junjie Fang, Yue Zhao, Chongyi Wang, Jun Liu, Guirong Chen, Yupeng Huo, Yuan Yao, Yankai Lin, Zhiyuan Liu, and Maosong Sun. 2024. GUICourse: From General Vision Language Models to Versatile GUI Agents.arXiv preprint arXiv:2406.11317(2024)
- [8]
-
[9]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, Luke Marris, Sam Petulla, Colin Gaffney, et al . 2025. Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities.ArXivabs/2507.06261 (2025)...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [10]
-
[11]
Meng Fang, Shilong Deng, Yudi Zhang, Zijing Shi, Ling Chen, Mykola Pech- enizkiy, and Jun Wang. 2024. Large language models are neurosymbolic rea- soners. InProceedings of the AAAI conference on artificial intelligence, Vol. 38. 17985–17993
2024
-
[12]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models.arXiv preprint arXiv:2106.09685(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Yao Hu, and Shaohui Lin. 2025. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749(2025)
work page internal anchor Pith review arXiv 2025
-
[16]
HuggingFace-M4. 2024. WebSight: A Synthetic Dataset of Website Screenshots and HTML Code. https://huggingface.co/datasets/HuggingFaceM4/WebSight
2024
- [18]
-
[19]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. 2024. LLaVA- OneVision: Easy Visual Task Transfer. arXiv:2408.03326 [cs.CV] https://arxiv. org/abs/2408.03326 MM ’26, October 2026, TBD Dasen Dai, Shuoqi Li, Ronghao Chen, Huacan Wang, Biao Wu, and Qizhen Lan
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning. PMLR, 19730–19742
2023
-
[21]
Bishop, Alice Li, Christopher Rawles, Folawiyo Campbell- Ajala, Divya Tyamagundlu, and Oriana Riva
Wei Li, William E. Bishop, Alice Li, Christopher Rawles, Folawiyo Campbell- Ajala, Divya Tyamagundlu, and Oriana Riva. 2024. On the Effects of Data Scale on UI Control Agents. InNeurIPS
2024
- [22]
- [23]
-
[24]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual Instruc- tion Tuning. arXiv:2304.08485 [cs.CV] https://arxiv.org/abs/2304.08485
work page internal anchor Pith review arXiv 2023
-
[25]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al . 2024. Mmbench: Is your multi-modal model an all-around player?. InEuropean conference on computer vision. Springer, 216–233
2024
-
[26]
Zhihao Liu et al. 2025. DeepSeek-OCR: Optical Context Compression.arXiv preprint arXiv:2510.18234(2025)
work page internal anchor Pith review arXiv 2025
-
[27]
Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. 2023. Scissorhands: Exploit- ing the persistence of importance hypothesis for llm kv cache compression at test time.Advances in Neural Information Processing Systems36 (2023), 52342–52364
2023
-
[28]
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. 2025. Visual-rft: Visual reinforcement fine-tuning. arXiv preprint arXiv:2503.01785(2025)
work page internal anchor Pith review arXiv 2025
- [29]
- [30]
- [31]
-
[32]
Qwen Team. 2025. Qwen3-VL: A Vision-Language Model Series. https://github. com/QwenLM/Qwen3-VL
2025
-
[33]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, et al. 2021. Learning Transferable Visual Models From Natural Language Supervision. InICML
2021
- [34]
-
[35]
Haozhan Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, Ruochen Xu, and Tiancheng Zhao. 2025. VLM-R1: A stable and generalizable R1-style Large Vision- Language Model. https://github.com/om-ai-lab/VLM-R1. Accessed: 2025-02-15
2025
-
[36]
Jingwei Shi, Zeyu Zhang, Biao Wu, Yanjie Liang, Meng Fang, Ling Chen, and Yang Zhao. 2025. Presentagent: Multimodal agent for presentation video generation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 760–773
2025
- [37]
-
[38]
Zijing Shi, Meng Fang, Ling Chen, Yali Du, and Jun Wang. 2024. Human-guided moral decision making in text-based games. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 21574–21582
2024
-
[39]
Zijing Shi, Meng Fang, Yunqiu Xu, Ling Chen, and Yali Du. 2022. Stay moral and explore: Learn to behave morally in text-based games. InThe Eleventh Interna- tional Conference on Learning Representations
2022
-
[40]
Zijing Shi, Meng Fang, Shunfeng Zheng, Shilong Deng, Ling Chen, and Yali Du
- [41]
-
[42]
Zijing Shi, Yunqiu Xu, Meng Fang, and Ling Chen. 2023. Self-imitation learning for action generation in text-based games. InProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. 703–726
2023
- [43]
- [44]
- [45]
- [46]
-
[47]
Liujian Tang, Shaokang Dong, Yijia Huang, Minqi Xiang, Hongtao Ruan, Bin Wang, Shuo Li, Zhiheng Xi, Zhihui Cao, Hailiang Pang, Heng Kong, He Yang, Mingxu Chai, Zhilin Gao, Xingyu Liu, Yingnan Fu, Jiaming Liu, Xuanjing Huang, Yu-Gang Jiang, Tao Gui, Qi Zhang, Kang Wang, Yunke Zhang, and Yuran Wang
-
[48]
doi:10.48550/arXiv.2508.03700 , author =
MagicGUI: A Foundational Mobile GUI Agent with Scalable Data Pipeline and Reinforcement Fine-tuning. arXiv:2508.03700 [cs.HC] https://arxiv.org/abs/ 2508.03700
-
[49]
V-Team, Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, Shuaiqi Duan, Weihan Wang, Yan Wang, Yean Cheng, Zehai He, Zhe Su, Zhen Yang, Ziyang Pan, Aohan Zeng, Baoxu Wang, Bin Chen, Boyan Shi, Changyu Pang, Chenhui Zhang, Da Yin, Fan Yang, Guoqing Chen, Jiazheng Xu, Jiale Zhu, Jiali Chen, J...
work page internal anchor Pith review arXiv 2025
-
[50]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. InAdvances in Neural Information Processing Systems, Vol. 30
2017
- [51]
- [52]
- [53]
- [54]
-
[55]
Biao Wu, Yanda Li, Zhiwei Zhang, Yunchao Wei, Meng Fang, and Ling Chen
-
[56]
arXiv preprint arXiv:2411.02006(2024)
Foundations and recent trends in multimodal mobile agents: A survey. arXiv preprint arXiv:2411.02006(2024)
- [57]
-
[58]
Penghao Wu, Shengnan Ma, Bo Wang, Jiaheng Yu, Lewei Lu, and Ziwei Liu
- [59]
-
[60]
Yi Wu et al. 2024. WebCode2M: A Real-World, Large-Scale Frontend Code Dataset for Code Generation.arXiv preprint(2024)
2024
- [61]
- [62]
- [63]
-
[64]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al . 2024. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [65]
-
[66]
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. 2024. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800(2024)
work page internal anchor Pith review arXiv 2024
- [67]
-
[68]
Jaeyoung Yun et al. 2024. EfficientUICoder: An Efficient Visual Token Compres- sion Method for UI-to-Code Generation.arXiv preprint(2024)
2024
- [69]
-
[70]
Screenshot-to-Code
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. 2024. LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models. InACL. UIPress: Bringing Optical Token Compression to UI-to-Code Generation MM ’26, October 2026, TBD A Hyperparameters and Training Details Generation.For all Qwen3-VL-based methods,...
2024
-
[71]
All CSS must be inlined within a <style> tag in the <head>
Self-Contained: The HTML must include <!DOCTYPE html>, <html>, <head>, and <body> tags. All CSS must be inlined within a <style> tag in the <head>. No external CSS or JavaScript files
-
[72]
High Fidelity: Use Flexbox or CSS Grid to faithfully reproduce the header, navigation, main content, sidebar, footer, and any visible structures
-
[73]
Preserve colors, font sizes, spacing, alignment, borders, and backgrounds
Exact Match: Reproduce all visible text exactly (headings, paragraphs, buttons). Preserve colors, font sizes, spacing, alignment, borders, and backgrounds
-
[74]
placeholder.jpg
Assets: Use "placeholder.jpg" for image sources. Use colored <div> elements for decorative blocks
-
[75]
Figure 7: The system prompt used for the screenshot-to-code generation task
Escaping: Ensure all HTML attributes within the string use single quotes (') or are properly escaped to maintain valid JSON format. Figure 7: The system prompt used for the screenshot-to-code generation task
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.