Recognition: unknown
Skill-SD: Skill-Conditioned Self-Distillation for Multi-turn LLM Agents
Pith reviewed 2026-05-10 15:23 UTC · model grok-4.3
The pith
By turning agent trajectories into dynamic natural language skills that condition only the teacher, Skill-SD delivers large performance gains in training multi-turn LLM agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Skill-SD turns the agent's own trajectories into dynamic training-only supervision by summarizing them into compact natural language skills that describe successful behaviors, mistakes, and workflows. These skills serve as dynamic privileged information conditioning only the teacher, while the student always acts under the plain task prompt and learns to internalize the guidance through distillation. To stabilize training, an importance-weighted reverse-KL loss provides gradient-correct token-level distillation, and the teacher is dynamically synchronized with the improving student.
What carries the argument
Dynamic natural-language skill summaries extracted from completed trajectories, supplied as privileged information to condition only the teacher during self-distillation.
If this is right
- Outperforms vanilla GRPO by 14.0 percent on AppWorld and 10.9 percent on Sokoban.
- Outperforms vanilla OPSD by 42.1 percent on AppWorld and 40.6 percent on Sokoban.
- Stabilizes the combination of self-distillation and RL that otherwise collapses under naive mixing.
- Supplies dense token-level supervision drawn from diverse strategies while leaving the student's inference-time prompt unchanged.
- Allows the student to internalize trajectory-derived guidance through distillation rather than direct exposure.
Where Pith is reading between the lines
- The separation of teacher conditioning from student prompts may transfer to other RL settings where trajectory-derived information is abundant but must remain hidden at test time.
- If automated skill extraction proves reliable, the method could lower dependence on hand-crafted dense rewards or ground-truth answers for teacher models.
- Applying the same trajectory-to-skill pipeline to longer-horizon or multi-agent tasks would test whether the dynamic nature of the skills continues to scale.
Load-bearing premise
Trajectories can be summarized into compact natural-language skills that reliably capture diverse valid strategies and mistakes, and these skills supply useful dynamic privileged information without introducing harmful bias or noise when used only to condition the teacher.
What would settle it
A controlled run on AppWorld or Sokoban in which Skill-SD produces no gain over the plain RL baseline or causes training collapse even after applying the importance-weighted reverse-KL loss.
Figures




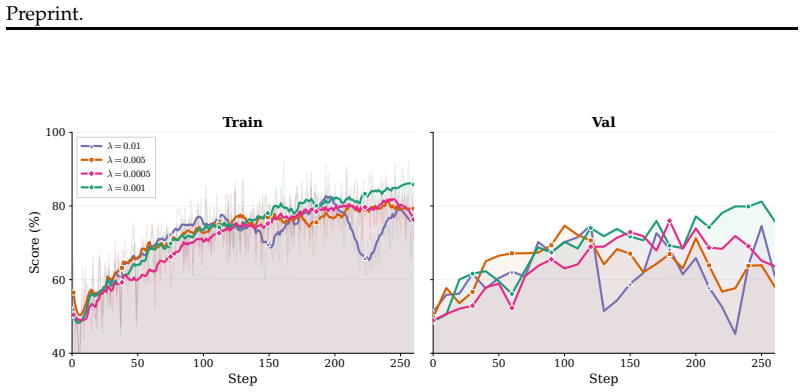
read the original abstract
Reinforcement learning (RL) has been widely used to train LLM agents for multi-turn interactive tasks, but its sample efficiency is severely limited by sparse rewards and long horizons. On-policy self-distillation (OPSD) alleviates this by providing dense token-level supervision from a privileged teacher that has access to ground-truth answers. However, such fixed privileged information cannot capture the diverse valid strategies in agent tasks, and naively combining OPSD with RL often leads to training collapse. To address these limitations, we introduce Skill-SD, a framework that turns the agent's own trajectories into dynamic training-only supervision. Completed trajectories are summarized into compact natural language skills that describe successful behaviors, mistakes, and workflows. These skills serve as dynamic privileged information conditioning only the teacher, while the student always acts under the plain task prompt and learns to internalize the guidance through distillation. To stabilize the training, we derive an importance-weighted reverse-KL loss to provide gradient-correct token-level distillation, and dynamically synchronize the teacher with the improving student. Experimental results on agentic benchmarks demonstrate that Skill-SD substantially outperforms the standard RL baseline, improving both vanilla GRPO (+14.0%/+10.9% on AppWorld/Sokoban) and vanilla OPD (+42.1%/+40.6%). Project page: https://k1xe.github.io/skill-sd/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Skill-SD, a self-distillation framework for multi-turn LLM agents that converts completed trajectories into compact natural-language skills describing behaviors, mistakes, and workflows. These skills provide dynamic privileged information that conditions only the teacher model, while the student learns under the plain prompt via an importance-weighted reverse-KL distillation loss; the teacher is periodically synchronized with the student. Experiments claim substantial gains over vanilla GRPO (+14.0% AppWorld, +10.9% Sokoban) and vanilla OPD (+42.1% AppWorld, +40.6% Sokoban).
Significance. If the skill-summarization step proves reliable and the reported margins hold under ablations and statistical controls, Skill-SD would offer a practical route to denser supervision in long-horizon, sparse-reward agent tasks without requiring fixed ground-truth answers. The dynamic, trajectory-derived nature of the privileged signal distinguishes it from static OPSD and could generalize to other interactive settings.
major comments (4)
- [Abstract, §4] Abstract and §4 (Experiments): the headline improvements (+14.0 % / +42.1 % on AppWorld) are reported without error bars, run counts, or statistical tests. Given that the central claim is empirical outperformance, the absence of variance estimates leaves open whether the margins are robust or sensitive to random seeds and summarizer stochasticity.
- [§3.1] §3.1 (Skill Extraction): the method relies on an LLM-based summarizer to produce compact natural-language skills from trajectories, yet no prompt template, validation metric, or human/automated fidelity check is described. If the summarizer hallucinates, omits key decision points, or injects systematic bias, the importance-weighted reverse-KL loss will propagate that noise; this assumption is load-bearing for all claimed gains over GRPO and OPD.
- [§3.2] §3.2 (Loss Derivation): the importance-weighted reverse-KL objective is presented as stabilizing training, but the manuscript does not show the full derivation or prove that the weighting corrects the gradient bias introduced by the dynamic teacher. Without an explicit statement of the weighting function and its dependence on the skill-conditioned teacher logits, it is unclear whether the loss is parameter-free or implicitly tuned to the reported benchmarks.
- [§4.2] §4.2 (Ablations): no ablation isolates the contribution of dynamic skill conditioning versus a fixed-skill or no-skill teacher. If a static privileged signal already recovers most of the gain, the novelty of the trajectory-to-skill pipeline would be substantially reduced.
minor comments (2)
- [§3] Notation for the reverse-KL term and the synchronization schedule should be defined once in §3 and used consistently; several symbols appear without prior definition in the loss equation.
- [Abstract] The project page is referenced but no link to code, prompts, or extracted skill examples is provided in the manuscript, hindering reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and have revised the manuscript to provide additional details, clarifications, and experiments where needed. These changes strengthen the empirical claims and methodological transparency of Skill-SD.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): the headline improvements (+14.0 % / +42.1 % on AppWorld) are reported without error bars, run counts, or statistical tests. Given that the central claim is empirical outperformance, the absence of variance estimates leaves open whether the margins are robust or sensitive to random seeds and summarizer stochasticity.
Authors: We agree that variance estimates and statistical controls are essential for robust empirical claims. Our original experiments used multiple random seeds (accounting for both RL stochasticity and summarizer variability), but error bars were omitted from the main tables for space. We have updated all tables in §4 to report means with standard errors, explicitly state the number of runs, and include paired t-test results confirming significance (p < 0.05) of the reported gains. The margins remain consistent with the original claims. revision: yes
-
Referee: [§3.1] §3.1 (Skill Extraction): the method relies on an LLM-based summarizer to produce compact natural-language skills from trajectories, yet no prompt template, validation metric, or human/automated fidelity check is described. If the summarizer hallucinates, omits key decision points, or injects systematic bias, the importance-weighted reverse-KL loss will propagate that noise; this assumption is load-bearing for all claimed gains over GRPO and OPD.
Authors: We thank the referee for noting this omission. The skill-extraction prompt template is provided in Appendix A.1. We have added a new paragraph in §3.1 describing an automated fidelity validation procedure that measures overlap between extracted skills and annotated trajectory events on a held-out set. We also discuss how the importance weighting in the distillation loss limits error propagation from imperfect summaries. These details are now included in the revised manuscript. revision: yes
-
Referee: [§3.2] §3.2 (Loss Derivation): the importance-weighted reverse-KL objective is presented as stabilizing training, but the manuscript does not show the full derivation or prove that the weighting corrects the gradient bias introduced by the dynamic teacher. Without an explicit statement of the weighting function and its dependence on the skill-conditioned teacher logits, it is unclear whether the loss is parameter-free or implicitly tuned to the reported benchmarks.
Authors: We appreciate the request for greater rigor. The full derivation appears in Appendix B, beginning from the standard reverse-KL and arriving at the importance-weighted form that corrects for the dynamic teacher distribution. The weighting function is w_t = p_teacher(y_t | skill, x) / p_student(y_t | x) and is explicitly parameter-free. We have added a concise summary of the derivation and the weighting expression directly into §3.2, with a forward reference to the appendix. revision: yes
-
Referee: [§4.2] §4.2 (Ablations): no ablation isolates the contribution of dynamic skill conditioning versus a fixed-skill or no-skill teacher. If a static privileged signal already recovers most of the gain, the novelty of the trajectory-to-skill pipeline would be substantially reduced.
Authors: This is a fair critique. We have added a new ablation in the revised §4.2 that directly compares Skill-SD against (i) a fixed-skill teacher variant (skills extracted once from early trajectories and held constant) and (ii) a no-skill teacher baseline. The results demonstrate that dynamic, trajectory-derived skills contribute an additional performance margin beyond static privileged information, supporting the core novelty of the approach. The updated section includes these comparisons. revision: yes
Circularity Check
No significant circularity; claims rest on external benchmarks and a derived loss
full rationale
The paper introduces Skill-SD by summarizing trajectories into natural-language skills that condition only the teacher for reverse-KL distillation, with an importance-weighted loss presented as derived to stabilize training. No equations or steps in the provided text reduce the reported gains (+14%/+42% over GRPO/OPD) to quantities defined by the authors' own prior parameters, fitted inputs renamed as predictions, or self-citation chains. The central results are validated on independent agentic benchmarks (AppWorld, Sokoban), and the skill-summarization step is an empirical addition rather than a self-referential definition. This satisfies the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Completed agent trajectories can be summarized into compact natural-language skills that capture successful behaviors, mistakes, and workflows.
- domain assumption The importance-weighted reverse-KL loss supplies stable, gradient-correct token-level distillation signals.
invented entities (1)
-
Dynamic skills extracted from trajectories
no independent evidence
Forward citations
Cited by 6 Pith papers
-
TimeClaw: A Time-Series AI Agent with Exploratory Execution Learning
TimeClaw is an exploratory execution learning system that turns multiple valid tool-use paths into hierarchical distilled experience for improved time-series reasoning without test-time adaptation.
-
Preference-Based Self-Distillation: Beyond KL Matching via Reward Regularization
PBSD derives a reward-reweighted teacher distribution as the analytic optimum of a reward-regularized objective, yielding better stability and performance than KL-based self-distillation on math reasoning and tool-use tasks.
-
Beyond GRPO and On-Policy Distillation: An Empirical Sparse-to-Dense Reward Principle for Language-Model Post-Training
Sparse RL on capable teachers followed by dense distillation to students beats direct GRPO on students for verifiable math reasoning.
-
SOD: Step-wise On-policy Distillation for Small Language Model Agents
SOD reweights on-policy distillation strength step-by-step using divergence to stabilize tool use in small language model agents, yielding up to 20.86% gains and 26.13% on AIME 2025 for a 0.6B model.
-
SOLAR-RL: Semi-Online Long-horizon Assignment Reinforcement Learning
SOLAR-RL assigns dense step-level rewards from static trajectory data by detecting first failure points and applying target-aligned shaping to improve long-horizon GUI task completion without full online interactions.
-
Beyond GRPO and On-Policy Distillation: An Empirical Sparse-to-Dense Reward Principle for Language-Model Post-Training
Sparse RL on a strong teacher followed by dense distillation to the student outperforms direct GRPO on the student for math tasks, with a forward-KL + OPD bridge enabling further gains.
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. In International Conference on Learning Representations, 2024
2024
-
[3]
Finite-time analysis of the multiarmed bandit problem
Peter Auer, Nicol\` o Cesa-Bianchi, and Paul Fischer. Finite-time analysis of the multiarmed bandit problem. Machine Learning, 47 0 (2--3): 0 235--256, 2002
2002
-
[4]
Yoshua Bengio, J \'e r \^o me Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. In Proceedings of the 26th International Conference on Machine Learning (ICML), pp.\ 41--48, 2009. doi:10.1145/1553374.1553380
-
[5]
Seed1.8 Model Card: Towards Generalized Real-World Agency
Bytedance Seed . Seed1.8 model card: Towards generalized real-world agency. arXiv preprint arXiv:2603.20633, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Reinforcement learning for long-horizon interactive llm agents, 2025
Kevin Chen, Marco Cusumano-Towner, Brody Huval, Aleksei Petrenko, Jackson Hamburger, Vladlen Koltun, and Philipp Kr \"a henb \"u hl. Reinforcement learning for long-horizon interactive LLM agents. arXiv preprint arXiv:2502.01600, 2025
-
[7]
arXiv preprint arXiv:2511.14460 , year=
Mingyue Cheng, Jie Ouyang, Shuo Yu, Ruiran Yan, Yucong Luo, Zirui Liu, Daoyu Wang, Qi Liu, and Enhong Chen. Agent- R1 : Training powerful LLM agents with end-to-end reinforcement learning. arXiv preprint arXiv:2511.14460, 2025
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI . DeepSeek-R1 : Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Group-in-group policy optimization for LLM agent training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for LLM agent training. In Advances in Neural Information Processing Systems, 2025
2025
-
[10]
Lipton, Michael Tschannen, Laurent Itti, and Anima Anandkumar
Tommaso Furlanello, Zachary C. Lipton, Michael Tschannen, Laurent Itti, and Anima Anandkumar. Born again neural networks. In Proceedings of the 35th International Conference on Machine Learning (ICML), pp.\ 1607--1616, 2018. URL https://proceedings.mlr.press/v80/furlanello18a.html
2018
-
[11]
doi: 10.18653/v1/2023.findings-acl.507
Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alex Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. In Findings of the Association for Computational Linguistics: ACL 2023, pp.\ 8003--8017, 2023. doi:10.18653...
-
[12]
Hu, Benjamin Van Durme, Jacob Andreas, and Harsh Jhamtani
Michael Y. Hu, Benjamin Van Durme, Jacob Andreas, and Harsh Jhamtani. Sample-efficient online learning in LM agents via hindsight trajectory rewriting. arXiv preprint arXiv:2510.10304, 2025
-
[13]
Reinforcement Learning via Self-Distillation
Jonas H \"u botter, Frederike L \"u beck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause. Reinforcement learning via self-distillation. arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review arXiv 2026
-
[14]
Llm-powered gui agents in phone automation: Surveying progress and prospects
Guangyi Liu, Pengxiang Zhao, Yaozhen Liang, Liang Liu, Yaxuan Guo, Han Xiao, Weifeng Lin, Yuxiang Chai, Yue Han, Shuai Ren, et al. Llm-powered gui agents in phone automation: Surveying progress and prospects. arXiv preprint arXiv:2504.19838, 2025 a
-
[15]
Learnact: Few-shot mobile gui agent with a unified demonstration benchmark,
Guangyi Liu, Pengxiang Zhao, Liang Liu, Zhiming Chen, Yuxiang Chai, Shuai Ren, Hao Wang, Shibo He, and Wenchao Meng. Learnact: Few-shot mobile gui agent with a unified demonstration benchmark. arXiv preprint arXiv:2504.13805, 2025 b
-
[16]
Memgui-bench: Benchmarking memory of mobile gui agents in dynamic environments,
Guangyi Liu, Pengxiang Zhao, Yaozhen Liang, Qinyi Luo, Shunye Tang, Yuxiang Chai, Weifeng Lin, Han Xiao, WenHao Wang, Siheng Chen, et al. Memgui-bench: Benchmarking memory of mobile gui agents in dynamic environments. arXiv preprint arXiv:2602.06075, 2026
-
[17]
Kezhao Liu, Jason Klein Liu, Mingtao Chen, and Yiming Liu. Rethinking KL regularization in RLHF : From value estimation to gradient optimization. arXiv preprint arXiv:2510.01555, 2025 c
-
[18]
arXiv preprint arXiv:2602.04942 , year =
Emiliano Penaloza, Dheeraj Vattikonda, Nicolas Gontier, Alexandre Lacoste, Laurent Charlin, and Massimo Caccia. Privileged information distillation for language models. arXiv preprint arXiv:2602.04942, 2026
-
[19]
Qwen Team . Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
gym-sokoban: Reinforcement learning environment for the game of sokoban
Max-Philipp Schrader. gym-sokoban: Reinforcement learning environment for the game of sokoban. https://github.com/mpSchrader/gym-sokoban, 2018
2018
-
[21]
Approximating KL divergence
John Schulman. Approximating KL divergence. http://joschu.net/blog/kl-approx.html, 2020. Blog post
2020
-
[22]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. DeepSeekMath : Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. In Advances in Neural Information Processing Systems, 2023
2023
-
[26]
arXiv preprint arXiv:2506.09477 , year=
Yunhao Tang and R \'e mi Munos. On a few pitfalls in KL divergence gradient estimation for RL . arXiv preprint arXiv:2506.09477, 2025
-
[27]
AppWorld : A controllable world of apps and people for benchmarking interactive coding agents
Harsh Trivedi, Tushar Khot, Mareike Hartmann, Ruskin Manku, Vinty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, and Niranjan Balasubramanian. AppWorld : A controllable world of apps and people for benchmarking interactive coding agents. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pp.\ 16022--16076, 2024
2024
-
[28]
A new learning paradigm: Learning using privileged information , journal =
Vladimir Vapnik and Akshay Vashist. A new learning paradigm: Learning using privileged information. Neural Networks, 22 0 (5--6): 0 544--557, 2009. doi:10.1016/j.neunet.2009.06.042
-
[29]
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi
Ruiyi Wang and Prithviraj Ammanabrolu. A practitioner's guide to multi-turn agentic reinforcement learning. arXiv preprint arXiv:2510.01132, 2025
-
[30]
OpenClaw-RL: Train Any Agent Simply by Talking
Yinjie Wang, Xuyang Chen, Xiaolong Jin, Mengdi Wang, and Ling Yang. OpenClaw-RL : Train any agent simply by talking. arXiv preprint arXiv:2603.10165, 2026
work page Pith review arXiv 2026
-
[31]
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
Zihan Wang, Kangrui Wang, Qineng Wang, Pingyue Zhang, Linjie Li, Zhengyuan Yang, Xing Jin, Kefan Yu, Minh Nhat Nguyen, Licheng Liu, Eli Gottlieb, Yiping Lu, Kyunghyun Cho, Jiajun Wu, Fei-Fei Li, Lijuan Wang, Yejin Choi, and Manling Li. RAGEN : Understanding self-evolution in LLM agents via multi-turn reinforcement learning. arXiv preprint arXiv:2504.20073, 2025
work page internal anchor Pith review arXiv 2025
-
[32]
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
Rong Wu, Xiaoman Wang, Jianbiao Mei, Pinlong Cai, Daocheng Fu, Cheng Yang, Licheng Wen, Xuemeng Yang, Yufan Shen, Yuxin Wang, and Botian Shi. EvolveR : Self-evolving LLM agents through an experience-driven lifecycle. arXiv preprint arXiv:2510.16079, 2025
work page internal anchor Pith review arXiv 2025
-
[33]
AgentGym-RL : Training LLM agents for long-horizon decision making through multi-turn reinforcement learning
Zhiheng Xi, Jixuan Huang, Chenyang Liao, Baodai Huang, Honglin Guo, Jiaqi Liu, Rui Zheng, Junjie Ye, Jiazheng Zhang, Wenxiang Chen, Wei He, Yiwen Ding, Guanyu Li, Zehui Chen, Zhengyin Du, Xuesong Yao, Yufei Xu, Jiecao Chen, Tao Gui, Zuxuan Wu, Qi Zhang, Xuanjing Huang, and Yu-Gang Jiang. AgentGym-RL : Training LLM agents for long-horizon decision making t...
2026
-
[34]
arXiv preprint arXiv:2505.21496 , year=
Han Xiao, Guozhi Wang, Yuxiang Chai, Zimu Lu, Weifeng Lin, Hao He, Lue Fan, Liuyang Bian, Rui Hu, Liang Liu, et al. Ui-genie: A self-improving approach for iteratively boosting mllm-based mobile gui agents. arXiv preprint arXiv:2505.21496, 2025
-
[35]
Ui-mem: Self-evolving experience memory for online reinforcement learning in mobile gui agents
Han Xiao, Guozhi Wang, Hao Wang, Shilong Liu, Yuxiang Chai, Yue Pan, Yufeng Zhou, Xiaoxin Chen, Yafei Wen, and Hongsheng Li. Ui-mem: Self-evolving experience memory for online reinforcement learning in mobile gui agents. arXiv preprint arXiv:2602.05832, 2026
-
[36]
arXiv preprint arXiv:2506.02208 , year =
Hongling Xu, Qi Zhu, Heyuan Deng, Jinpeng Li, Lu Hou, Yasheng Wang, Lifeng Shang, Ruifeng Xu, and Fei Mi. KDRL : Post-training reasoning LLM s via unified knowledge distillation and reinforcement learning. arXiv preprint arXiv:2506.02208, 2025
-
[37]
Learning to reason under off-policy guidance
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. Learning to reason under off-policy guidance. In Advances in Neural Information Processing Systems, 2025
2025
-
[38]
WebShop : Towards scalable real-world web interaction with grounded language agents
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. WebShop : Towards scalable real-world web interaction with grounded language agents. In Advances in Neural Information Processing Systems, pp.\ 20744--20757, 2022
2022
-
[39]
ReAct : Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct : Synergizing reasoning and acting in language models. In International Conference on Learning Representations, 2023
2023
-
[40]
arXiv preprint arXiv:2603.16856 , year=
Tianzhu Ye, Li Dong, Qingxiu Dong, Xun Wu, Shaohan Huang, and Furu Wei. Online experiential learning for language models. arXiv preprint arXiv:2603.16856, 2026 a
-
[41]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models. arXiv preprint arXiv:2602.12275, 2026 b
work page internal anchor Pith review arXiv 2026
-
[42]
Distilling system 2 into system 1
Ping Yu, Jing Xu, Jason Weston, and Ilia Kulikov. Distilling system 2 into system 1. arXiv preprint arXiv:2407.06023, 2024
-
[43]
DAPO : An open-source LLM reinforcement learning system at scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
2025
-
[44]
Siyu Yuan, Zehui Chen, Zhiheng Xi, Junjie Ye, Zhengyin Du, and Jiecao Chen. Agent- R : Training language model agents to reflect via iterative self-training. arXiv preprint arXiv:2501.11425, 2025
-
[45]
Agentevolver: Towards efficient self-evolving agent system.arXiv, 2025
Yunpeng Zhai et al. AgentEvolver : Towards efficient self-evolving agent system. arXiv preprint arXiv:2511.10395, 2025
-
[46]
AgentRL : Scaling agentic reinforcement learning with a multi-turn, multi-task framework
Hanchen Zhang et al. AgentRL : Scaling agentic reinforcement learning with a multi-turn, multi-task framework. In International Conference on Learning Representations, 2026 a
2026
-
[47]
On the design of KL -regularized policy gradient algorithms for LLM reasoning
Yifan Zhang, Yifeng Liu, Huizhuo Yuan, Yang Yuan, Quanquan Gu, and Andrew Chi-Chih Yao. On the design of KL -regularized policy gradient algorithms for LLM reasoning. In International Conference on Learning Representations, 2026 b
2026
-
[48]
Reinforcement-aware Knowledge Distillation for LLM Reasoning
Zhaoyang Zhang, Shuli Jiang, Yantao Shen, Yuting Zhang, Dhananjay Ram, Shuo Yang, Zhuowen Tu, Wei Xia, and Stefano Soatto. Reinforcement-aware knowledge distillation for LLM reasoning. arXiv preprint arXiv:2602.22495, 2026 c
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
ExpeL : LLM agents are experiential learners
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. ExpeL : LLM agents are experiential learners. In Proceedings of the AAAI Conference on Artificial Intelligence, pp.\ 19632--19642, 2024
2024
-
[50]
MAS-Bench: A Unified Benchmark for Shortcut-Augmented Hybrid Mobile GUI Agents
Pengxiang Zhao, Guangyi Liu, Yaozhen Liang, Weiqing He, Zhengxi Lu, Yuehao Huang, Yaxuan Guo, Kexin Zhang, Hao Wang, Liang Liu, et al. Mas-bench: A unified benchmark for shortcut-augmented hybrid mobile gui agents. arXiv preprint arXiv:2509.06477, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models. arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review arXiv 2026
-
[52]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[53]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[54]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2209.15189 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.