Recognition: 2 theorem links
· Lean TheoremSOD: Step-wise On-policy Distillation for Small Language Model Agents
Pith reviewed 2026-05-11 02:22 UTC · model grok-4.3
The pith
SOD enables reliable tool-integrated reasoning in small language models by reweighting teacher distillation according to per-step divergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
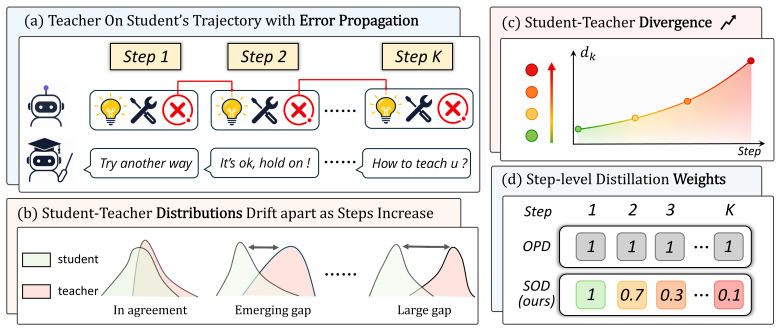
SOD is a step-wise on-policy distillation method that computes divergence between student and teacher at each reasoning step and adaptively lowers the weight of teacher supervision in high-divergence steps, thereby attenuating the influence of cascading tool-call errors while retaining dense guidance where trajectories remain aligned.
What carries the argument
Step-level divergence measurement used to adaptively reweight the distillation loss at each point in the student-generated trajectory.
If this is right
- Small models acquire stable performance on long-horizon tool tasks that previously required much larger teachers.
- Agentic reasoning capabilities transfer to models as small as 0.6 billion parameters on math and science benchmarks.
- Training avoids the progressive unreliability that arises when early tool mistakes distort later supervision.
- Benchmarks involving code, math, and science show consistent gains without increasing model size or inference cost.
Where Pith is reading between the lines
- The same per-step reweighting principle could be tested on sequential tasks outside tool use, such as multi-turn dialogue or planning.
- Combining the divergence signal with outcome-level rewards might produce hybrid training that is both dense and goal-directed.
- Measuring divergence against multiple teachers could reveal whether the method scales when the reference policy itself contains errors.
Load-bearing premise
Step-level divergence can be measured reliably enough to identify and reduce misleading teacher signals without discarding useful guidance or adding new biases to the training trajectories.
What would settle it
Applying SOD to the same set of trajectories used by standard on-policy distillation and observing no reduction in error propagation or no accuracy gain on the target benchmarks.
Figures





read the original abstract
Tool-integrated reasoning (TIR) is difficult to scale to small language models due to instability in long-horizon tool interactions and limited model capacity. While reinforcement learning methods like group relative policy optimization provide only sparse outcome-level rewards. Recently, on-policy distillation (OPD) has gained popularity by supplying dense token-level supervision from a teacher on student-generated trajectories. However, our experiments indicate that applying OPD to TIR leads to a critical failure mode: erroneous tool calls tend to cascade across subsequent reasoning steps, progressively amplifying student-teacher divergence and rendering the teacher's token-level supervision increasingly unreliable. To address this, we propose SOD, a step-wise on-policy distillation framework for small language model agents, which adaptively reweights distillation strength at each step based on step-level divergence. Therefore, SOD can attenuate potentially misleading teacher signals in high-divergence regions while preserving dense guidance in well-aligned states. Experiments on challenging math, science, and code benchmarks show that SOD achieves up to 20.86% improvement over the second-best baseline. Notably, our 0.6B student achieves 26.13% on AIME 2025, demonstrating effective transfer of agentic reasoning to lightweight models. Our code is available at https://github.com/YoungZ365/SOD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SOD, a step-wise variant of on-policy distillation tailored to tool-integrated reasoning (TIR) agents. It diagnoses a cascading-error failure mode in standard on-policy distillation wherein erroneous tool calls increase student-teacher divergence, rendering subsequent token-level supervision unreliable. SOD mitigates this by computing a per-step divergence metric and adaptively down-weighting the distillation loss in high-divergence regions while retaining dense supervision elsewhere. Experiments across math, science, and code benchmarks report gains of up to 20.86 % over the second-best baseline, including a 0.6 B-parameter student reaching 26.13 % on AIME 2025; code is released at https://github.com/YoungZ365/SOD.
Significance. If the divergence-based reweighting reliably isolates misleading supervision without introducing new selection biases, SOD would constitute a practical advance for transferring agentic TIR capabilities to small models, where capacity limits and long-horizon instability are acute. The open-source code is a clear reproducibility asset.
major comments (2)
- [Abstract] Abstract: the headline claims (20.86 % improvement, 26.13 % on AIME 2025 for the 0.6 B model) are presented without any description of experimental controls, statistical significance tests, exact baseline configurations, number of runs, or the precise definition and computation of step-level divergence. These omissions prevent assessment of whether the reported gains are attributable to the proposed mechanism or to uncontrolled factors such as hyper-parameter tuning or trajectory filtering.
- [Method / Experiments] Method / Experiments sections: the central assumption that step-level divergence (presumably a per-step KL or output distance) reliably flags regions of cascading TIR errors is not supported by any reported correlation analysis, ablation, or visualization. In TIR, tool-call steps are discrete and high-variance; divergence could be dominated by format noise or sampling stochasticity rather than substantive error propagation. Without such evidence the adaptive reweighting reduces to a generic heuristic whose gains may not generalize.
minor comments (2)
- The abstract states that code is available; this is a positive for reproducibility and should be retained.
- [Method] Clarify whether divergence is computed only on tool-call tokens, on the full reasoning step, or on the entire trajectory prefix; the current description leaves the exact scope ambiguous.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claims (20.86 % improvement, 26.13 % on AIME 2025 for the 0.6 B model) are presented without any description of experimental controls, statistical significance tests, exact baseline configurations, number of runs, or the precise definition and computation of step-level divergence. These omissions prevent assessment of whether the reported gains are attributable to the proposed mechanism or to uncontrolled factors such as hyper-parameter tuning or trajectory filtering.
Authors: We agree that the abstract would benefit from greater specificity on experimental controls. In the revised manuscript we will expand the abstract to briefly state the main baselines compared, the number of independent evaluation runs (with results averaged across seeds), and the exact formulation of the step-level divergence metric (KL divergence between teacher and student token distributions at each step). We will also note that hyper-parameters were tuned on a held-out validation set and that no trajectory filtering beyond standard length limits was applied. These additions will make the source of the reported gains more transparent. revision: yes
-
Referee: [Method / Experiments] Method / Experiments sections: the central assumption that step-level divergence (presumably a per-step KL or output distance) reliably flags regions of cascading TIR errors is not supported by any reported correlation analysis, ablation, or visualization. In TIR, tool-call steps are discrete and high-variance; divergence could be dominated by format noise or sampling stochasticity rather than substantive error propagation. Without such evidence the adaptive reweighting reduces to a generic heuristic whose gains may not generalize.
Authors: The referee correctly observes that the original submission lacks direct correlation analysis or visualizations tying step-level divergence to cascading TIR errors. While the consistent outperformance of SOD over standard on-policy distillation and other baselines across math, science, and code tasks provides indirect empirical support, we did not include the requested ablations or trajectory-level plots. In the revision we will add (i) visualizations of per-step divergence on successful versus failing trajectories and (ii) an ablation that replaces the divergence-based reweighting with a random or fixed-threshold baseline. These additions will test whether the metric primarily captures substantive error propagation rather than format noise or sampling variance. revision: yes
Circularity Check
No circularity: empirical algorithmic proposal with independent experimental validation
full rationale
The paper introduces SOD as an algorithmic modification to on-policy distillation that reweights steps by measured divergence. All reported gains (20.86% relative improvement, 26.13% absolute on AIME 2025) are presented as outcomes of benchmark experiments rather than quantities derived from equations or fitted parameters inside the paper. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the derivation chain; the central mapping from divergence to supervision quality is treated as an empirical hypothesis tested by ablation and comparison, not presupposed by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel / J_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SOD adaptively reweights distillation strength at each step based on step-level divergence... wk = min(∏(du+ε)/(du+1+ε), 1+δ)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 1 (Discontinuous divergence amplification) and Proposition 2 (Gradient SNR degradation) under tool-induced state drift
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The Rise and Potential of Large Language Model Based Agents: A Survey
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. The rise and potential of large language model based agents: A survey.arXiv preprint arXiv:2309.07864, 2023
work page internal anchor Pith review arXiv 2023
-
[2]
Minki Kang, Jongwon Jeong, Seanie Lee, Jaewoong Cho, and Sung Ju Hwang. Distilling llm agent into small models with retrieval and code tools.arXiv preprint arXiv:2505.17612, 2025
-
[3]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InICLR, 2023
work page 2023
-
[4]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InNeurIPS, 2023
work page 2023
-
[5]
Joykirat Singh, Raghav Magazine, Yash Pandya, and Akshay Nambi. Agentic reasoning and tool integration for llms via reinforcement learning.arXiv preprint arXiv:2505.01441, 2025
-
[6]
Mixed distillation helps smaller language models reason better
Li Chenglin, Qianglong Chen, Liangyue Li, Caiyu Wang, Feng Tao, Yicheng Li, Zulong Chen, and Yin Zhang. Mixed distillation helps smaller language models reason better. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 1673–1690, 2024
work page 2024
-
[7]
Shengda Fan, Xuyan Ye, Yupeng Huo, Zhi-Yuan Chen, Yiju Guo, Shenzhi Yang, Wenkai Yang, Shuqi Ye, Jingwen Chen, Haotian Chen, et al. Agentprocessbench: Diagnosing step-level process quality in tool-using agents.arXiv preprint arXiv:2603.14465, 2026
-
[8]
On-device language models: A comprehensive review.arXiv preprint arXiv:2409.00088, 2024
Jiajun Xu, Zhiyuan Li, Wei Chen, Qun Wang, Xin Gao, Qi Cai, and Ziyuan Ling. On-device language models: A comprehensive review.arXiv preprint arXiv:2409.00088, 2024
-
[9]
Caixia Yan, Xiaojun Chang, Minnan Luo, Huan Liu, Xiaoqin Zhang, and Qinghua Zheng
Xiaohan Xu, Ming Li, Chongyang Tao, Tao Shen, Reynold Cheng, Jinyang Li, Can Xu, Dacheng Tao, and Tianyi Zhou. A survey on knowledge distillation of large language models.arXiv preprint arXiv:2402.13116, 2024
-
[10]
arXiv preprint arXiv:2506.14728 , year=
Jiahao Qiu, Xinzhe Juan, Yimin Wang, Ling Yang, Xuan Qi, Tongcheng Zhang, Jiacheng Guo, Yifu Lu, Zixin Yao, Hongru Wang, et al. Agentdistill: Training-free agent distillation with generalizable mcp boxes.arXiv preprint arXiv:2506.14728, 2025
-
[11]
Yi Yao, He Zhu, Piaohong Wang, Jincheng Ren, Xinlong Yang, Qianben Chen, Xiaowan Li, Dingfeng Shi, Jiaxian Li, Qiexiang Wang, et al. O-researcher: An open ended deep research model via multi-agent distillation and agentic rl.arXiv preprint arXiv:2601.03743, 2026
-
[12]
arXiv preprint arXiv:2508.13167 , year=
Weizhen Li, Jianbo Lin, Zhuosong Jiang, Jingyi Cao, Xinpeng Liu, Jiayu Zhang, Zhenqiang Huang, Qianben Chen, Weichen Sun, Qiexiang Wang, et al. Chain-of-agents: End-to-end agent foundation models via multi-agent distillation and agentic rl.arXiv preprint arXiv:2508.13167, 2025
-
[13]
ToolRL: Reward is All Tool Learning Needs
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xiusi Chen, Dilek Hakkani-Tür, Gokhan Tur, and Heng Ji. Toolrl: Reward is all tool learning needs.arXiv preprint arXiv:2504.13958, 2025
work page internal anchor Pith review arXiv 2025
-
[14]
Corrado Rainone, Tim Bakker, and Roland Memisevic. Replacing thinking with tool usage enables reasoning in small language models.arXiv preprint arXiv:2507.05065, 2025
-
[15]
Zhenghai Xue, Longtao Zheng, Qian Liu, Yingru Li, Xiaosen Zheng, Zejun Ma, and Bo An. Simpletir: End-to-end reinforcement learning for multi-turn tool-integrated reasoning.arXiv preprint arXiv:2509.02479, 2025
-
[16]
Structured agent distillation for large language model
Jun Liu, Zhenglun Kong, Peiyan Dong, Changdi Yang, Tianqi Li, Hao Tang, Geng Yuan, Wei Niu, Wenbin Zhang, Pu Zhao, et al. Structured agent distillation for large language model. arXiv preprint arXiv:2505.13820, 2025
-
[17]
Torl: Scaling tool-integrated rl, 2025 b
Xuefeng Li, Haoyang Zou, and Pengfei Liu. Torl: Scaling tool-integrated rl.arXiv preprint arXiv:2503.23383, 2025. 11
-
[18]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516, 2025
work page Pith review arXiv 2025
-
[19]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. R1-searcher: Incentivizing the search capability in llms via reinforcement learning.arXiv preprint arXiv:2503.05592, 2025
work page internal anchor Pith review arXiv 2025
-
[20]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Fan Yang, Rui Meng, Trudi Di Qi, Ali Ezzati, and Yuxin Wen. Kepo: Knowledge-enhanced pref- erence optimization for reinforcement learning with reasoning.arXiv preprint arXiv:2602.00400, 2026
work page internal anchor Pith review arXiv 2026
-
[23]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InThe twelfth international conference on learning representations, 2024
work page 2024
-
[24]
Minillm: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. Minillm: Knowledge distillation of large language models. InThe twelfth international conference on learning representations, 2024
work page 2024
-
[25]
Entropy-aware on-policy distillation of language models
Woogyeol Jin, Taywon Min, Yongjin Yang, Swanand Ravindra Kadhe, Yi Zhou, Dennis Wei, Nathalie Baracaldo, and Kimin Lee. Entropy-aware on-policy distillation of language models. arXiv preprint arXiv:2603.07079, 2026
-
[26]
arXiv preprint arXiv:2603.11137 , year =
Jongwoo Ko, Sara Abdali, Young Jin Kim, Tianyi Chen, and Pashmina Cameron. Scaling reasoning efficiently via relaxed on-policy distillation.arXiv preprint arXiv:2603.11137, 2026
-
[27]
Yecheng Wu, Song Han, and Hai Cai. Lightning opd: Efficient post-training for large reasoning models with offline on-policy distillation.arXiv preprint arXiv:2604.13010, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai Yang, Zhiyuan Liu, et al. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Rlkd: Distilling llms’ reasoning via reinforcement learning
Shicheng Xu, Liang Pang, Yunchang Zhu, Jia Gu, Zihao Wei, Jingcheng Deng, Feiyang Pan, Huawei Shen, and Xueqi Cheng. Rlkd: Distilling llms’ reasoning via reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 34151–34159, 2026
work page 2026
-
[31]
Gengsheng Li, Tianyu Yang, Junfeng Fang, Mingyang Song, Mao Zheng, Haiyun Guo, Dan Zhang, Jinqiao Wang, and Tat-Seng Chua. Unifying group-relative and self-distillation policy optimization via sample routing.arXiv preprint arXiv:2604.02288, 2026
-
[32]
Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. Self-distilled rlvr.arXiv preprint arXiv:2604.03128, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Walid Bousselham, Hilde Kuehne, and Cordelia Schmid. V old: Reasoning transfer from llms to vision-language models via on-policy distillation.arXiv preprint arXiv:2510.23497, 2025
-
[34]
OpenClaw-RL: Train Any Agent Simply by Talking
Yinjie Wang, Xuyang Chen, Xiaolong Jin, Mengdi Wang, and Ling Yang. Openclaw-rl: Train any agent simply by talking.arXiv preprint arXiv:2603.10165, 2026. 12
work page Pith review arXiv 2026
-
[35]
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
Yuqian Fu, Haohuan Huang, Kaiwen Jiang, Yuanheng Zhu, and Dongbin Zhao. Revisiting on- policy distillation: Empirical failure modes and simple fixes.arXiv preprint arXiv:2603.25562, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
A Survey of On-Policy Distillation for Large Language Models
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models. arXiv preprint arXiv:2604.00626, 2026
work page internal anchor Pith review arXiv 2026
-
[37]
Stéphane Ross, Geoffrey J. Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InAISTATS, 2011
work page 2011
-
[38]
arXiv preprint arXiv:2305.15717 , year =
Arnav Gudibande, Eric Wallace, Charlie Snell, Xinyang Geng, Hao Liu, Pieter Abbeel, Sergey Levine, and Dawn Song. The false promise of imitating proprietary llms.arXiv preprint arXiv:2305.15717, 2023
-
[39]
TCOD: Exploring Temporal Curriculum in On-Policy Distillation for Multi-turn Autonomous Agents
Jiaqi Wang, Wenhao Zhang, Weijie Shi, Yaliang Li, and James Cheng. Tcod: Exploring temporal curriculum in on-policy distillation for multi-turn autonomous agents.arXiv preprint arXiv:2604.24005, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Stable On-Policy Distillation through Adaptive Target Reformulation
Ijun Jang, Jewon Yeom, Juan Yeo, Hyunggu Lim, and Taesup Kim. Stable on-policy distillation through adaptive target reformulation.arXiv preprint arXiv:2601.07155, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
TIP: Token Importance in On-Policy Distillation
Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, Zhipeng Wang, and Alborz Geramifard. Tip: Token importance in on-policy distillation.arXiv preprint arXiv:2604.14084, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences.Advances in neural information processing systems, 30, 2017
work page 2017
-
[43]
Fine-Tuning Language Models from Human Preferences
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[44]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[45]
arXiv preprint arXiv:2310.05915 , year=
Baian Chen, Chang Shu, Ehsan Shareghi, Nigel Collier, Karthik Narasimhan, and Shunyu Yao. Fireact: Toward language agent fine-tuning.arXiv preprint arXiv:2310.05915, 2023
-
[46]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
work page 2024
-
[47]
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, and Wanjun Zhong. Retool: Reinforcement learning for strategic tool use in llms.arXiv preprint arXiv:2504.11536, 2025
work page internal anchor Pith review arXiv 2025
-
[48]
Digirl: Training in-the-wild device-control agents with autonomous reinforcement learning
Hao Bai, Yifei Zhou, Mert Cemri, Jiayi Pan, Alane Suhr, Sergey Levine, and Aviral Kumar. Digirl: Training in-the-wild device-control agents with autonomous reinforcement learning. Advances in Neural Information Processing Systems, 37:12461–12495, 2024
work page 2024
-
[49]
Zehan Qi, Xiao Liu, Iat Long Iong, Hanyu Lai, Xueqiao Sun, Wenyi Zhao, Yu Yang, Xinyue Yang, Jiadai Sun, Shuntian Yao, et al. Webrl: Training llm web agents via self-evolving online curriculum reinforcement learning.arXiv preprint arXiv:2411.02337, 2024
-
[50]
arXiv preprint arXiv:2402.19446 , year=
Yifei Zhou, Andrea Zanette, Jiayi Pan, Sergey Levine, and Aviral Kumar. Archer: Training lan- guage model agents via hierarchical multi-turn rl, 2024.URL https://arxiv. org/abs/2402.19446, 2024
-
[51]
Reinforcement learning for long-horizon interactive llm agents, 2025
Kevin Chen, Marco Cusumano-Towner, Brody Huval, Aleksei Petrenko, Jackson Hamburger, Vladlen Koltun, and Philipp Krähenbühl. Reinforcement learning for long-horizon interactive llm agents.arXiv preprint arXiv:2502.01600, 2025
-
[52]
Demystifying reinforcement learning in agentic reasoning.arXiv preprint arXiv:2510.11701, 2025
Zhaochen Yu, Ling Yang, Jiaru Zou, Shuicheng Yan, and Mengdi Wang. Demystifying reinforcement learning in agentic reasoning.arXiv preprint arXiv:2510.11701, 2025. 13
-
[53]
Yinjie Wang, Tianbao Xie, Ke Shen, Mengdi Wang, and Ling Yang. Rlanything: Forge environment, policy, and reward model in completely dynamic rl system.arXiv preprint arXiv:2602.02488, 2026
-
[54]
Yinjie Wang, Ling Yang, Ye Tian, Ke Shen, and Mengdi Wang. Co-evolving llm coder and unit tester via reinforcement learning.arXiv preprint arXiv:2506.03136, 2025
-
[55]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models.arXiv preprint arXiv:2602.12275, 2026
work page internal anchor Pith review arXiv 2026
-
[56]
Black-box on-policy distillation of large language models.arXiv preprint arXiv:2511.10643,
Tianzhu Ye, Li Dong, Zewen Chi, Xun Wu, Shaohan Huang, and Furu Wei. Black-box on-policy distillation of large language models.arXiv preprint arXiv:2511.10643, 2025
-
[57]
Hybrid Policy Distillation for LLMs
Wenhong Zhu, Ruobing Xie, Rui Wang, and Pengfei Liu. Hybrid policy distillation for llms. arXiv preprint arXiv:2604.20244, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[58]
SCOPE: Signal-Calibrated On-Policy Distillation Enhancement with Dual-Path Adaptive Weighting
Binbin Zheng, Xing Ma, Yiheng Liang, Jingqing Ruan, Xiaoliang Fu, Kepeng Lin, Benchang Zhu, Ke Zeng, and Xunliang Cai. Scope: Signal-calibrated on-policy distillation enhancement with dual-path adaptive weighting.arXiv preprint arXiv:2604.10688, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[59]
SODA: Semi On-Policy Black-Box Distillation for Large Language Models
Xiwen Chen, Jingjing Wang, Wenhui Zhu, Peijie Qiu, Xuanzhao Dong, Hejian Sang, Zhipeng Wang, Alborz Geramifard, and Feng Luo. Soda: Semi on-policy black-box distillation for large language models.arXiv preprint arXiv:2604.03873, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[60]
Wenkai Yang, Weijie Liu, Ruobing Xie, Kai Yang, Saiyong Yang, and Yankai Lin. Learning beyond teacher: Generalized on-policy distillation with reward extrapolation.arXiv preprint arXiv:2602.12125, 2026
-
[61]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review arXiv 2026
-
[62]
arXiv preprint arXiv:2602.04942 , year =
Emiliano Penaloza, Dheeraj Vattikonda, Nicolas Gontier, Alexandre Lacoste, Laurent Charlin, and Massimo Caccia. Privileged information distillation for language models.arXiv preprint arXiv:2602.04942, 2026
-
[63]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review arXiv 2026
-
[64]
Self-Distillation Enables Continual Learning
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning.arXiv preprint arXiv:2601.19897, 2026
work page internal anchor Pith review arXiv 2026
-
[65]
Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
Yinghui He, Simran Kaur, Adithya Bhaskar, Yongjin Yang, Jiarui Liu, Narutatsu Ri, Liam Fowl, Abhishek Panigrahi, Danqi Chen, and Sanjeev Arora. Self-distillation zero: Self-revision turns binary rewards into dense supervision.arXiv preprint arXiv:2604.12002, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[66]
Skill-SD: Skill-Conditioned Self-Distillation for Multi-turn LLM Agents
Hao Wang, Guozhi Wang, Han Xiao, Yufeng Zhou, Yue Pan, Jichao Wang, Ke Xu, Yafei Wen, Xiaohu Ruan, Xiaoxin Chen, et al. Skill-sd: Skill-conditioned self-distillation for multi-turn llm agents.arXiv preprint arXiv:2604.10674, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[67]
https://thinkingmachines.ai/blog/ on-policy-distillation/
Kevin Lu and Thinking Machines Lab. On-policy distillation.Thinking Machines Lab: Con- nectionism, 2025. doi: 10.64434/tml.20251026. https://thinkingmachines.ai/blog/on-policy- distillation
-
[68]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori B Hashimoto. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20286–20332, 2025
work page 2025
-
[69]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025. 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
Skywork open reasoner 1 technical report.arXiv preprint arXiv:2505.22312,
Jujie He, Jiacai Liu, Chris Yuhao Liu, Rui Yan, Chaojie Wang, Peng Cheng, Xiaoyu Zhang, Fuxiang Zhang, Jiacheng Xu, Wei Shen, Siyuan Li, Liang Zeng, Tianwen Wei, Cheng Cheng, Bo An, Yang Liu, and Yahui Zhou. Skywork open reasoner 1 technical report.arXiv preprint arXiv:2505.22312, 2025
-
[71]
Megascience: Pushing the frontiers of post-training datasets for science reasoning, 2025
Run-Ze Fan, Zengzhi Wang, and Pengfei Liu. Megascience: Pushing the frontiers of post- training datasets for science reasoning.arXiv preprint arXiv:2507.16812, 2025
-
[72]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling, 2024
work page 2024
-
[73]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. InThe Thirteenth International Conference on Learning Representations
-
[74]
Jiaru Zou, Ling Yang, Jingwen Gu, Jiahao Qiu, Ke Shen, Jingrui He, and Mengdi Wang. Reasonflux-prm: Trajectory-aware prms for long chain-of-thought reasoning in llms.The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[75]
Yunhui Xia, Wei Shen, Yan Wang, Jason Klein Liu, Huifeng Sun, Siyue Wu, Jian Hu, and Xiaolong Xu. Leetcodedataset: A temporal dataset for robust evaluation and efficient training of code llms.arXiv preprint arXiv:2504.14655, 2025
-
[76]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025. 15 Appendix A Algorithmic Details of SOD We present the complete training procedure of SOD in...
work page 2025
-
[77]
The maximum prompt length is set to 2,560 tokens and the maximum response length to 20,480 tokens
All RL & Distillation baselines including SOD are trained based on the SFT checkpoint. The maximum prompt length is set to 2,560 tokens and the maximum response length to 20,480 tokens. We sample 16 responses per prompt during training and 32 during validation. All methods are trained for at most 1 epoch (For the teacher models, we train for at most 2 epo...
work page 2024
-
[78]
This already introduces a divergence jump substantially larger than text-only drift ( Ω(m·η tool) vs
Initial perturbation: An erroneous tool call returns a corrupted observation (e.g.,a runtime error, incorrect output, or timeout message). This already introduces a divergence jump substantially larger than text-only drift ( Ω(m·η tool) vs. O(η)), though the teacher, hav- ing encountered some error patterns during pretraining, can still provide partially ...
-
[79]
Cascading accumulation: Weaker student models, precisely the targets of OPD, are prone to making consecutive errors. Each subsequent erroneous tool call further corrupts the prefix, and thejointpattern of multiple consecutive failures becomes exponentially unlikely under the teacher’s training distribution (∼p j err for j consecutive errors). It is this a...
-
[80]
Supervision breakdown: In the resulting low-overlap states (ρt ≈0 ) caused by accumu- lated consecutive errors, the OPD gradient estimator suffers variance explosion and SNR degradation (Proposition 2). Updates become dominated by uninformative, high-magnitude contributions from tokens where the teacher provides no meaningful guidance. Figure 1(b) confirm...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.