Recognition: 2 theorem links
· Lean TheoremNaiAD: Initiate Data-Driven Research for LLM Advertising
Pith reviewed 2026-05-12 04:23 UTC · model grok-4.3
The pith
NaiAD dataset shows successful LLM ad integration follows four semantic strategies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
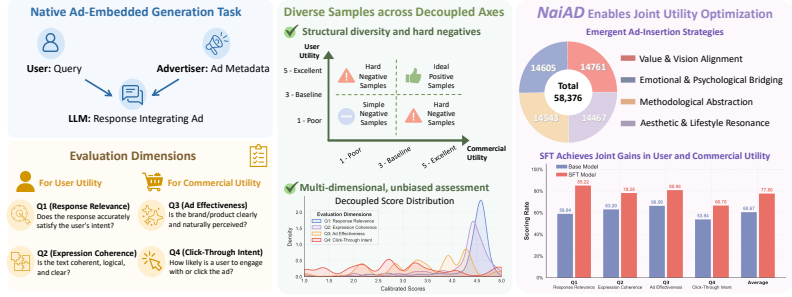
Successful ad integration relies on reasoning paths that cluster into four distinct semantic strategies. Models leveraging NaiAD internalize these strategies to simultaneously improve user and commercial utility, while enabling independent control over these distinct objectives via in-context learning. The dataset, generated through a decoupled pipeline and labeled with Variance-Calibrated Prediction-Powered Inference, positions itself as foundational infrastructure for future LLM-native ad systems.
What carries the argument
Four distinct semantic strategies that cluster the reasoning paths for successful ad integration, which models internalize from the NaiAD dataset.
If this is right
- Models using NaiAD achieve simultaneous gains in user and commercial utility.
- In-context learning on the dataset allows separate control over user and commercial objectives.
- The resource serves as foundational infrastructure for developing LLM-native ad systems.
- Decoupled generation produces responses that range from explicitly disentangled utilities to uniformly strong or weak across dimensions.
Where Pith is reading between the lines
- Similar mechanistic clustering of reasoning paths could be applied to other LLM tasks that balance conflicting objectives such as helpfulness and safety.
- The dataset's construction methods may transfer to creating training resources for commercial chat systems outside pure advertising.
- Real-user interaction logs could be checked to see whether the four strategies appear naturally in deployed LLM responses.
Load-bearing premise
The theoretically grounded evaluation metrics accurately and separately capture real user and commercial utility, and the four semantic strategies generalize beyond the constructed samples to actual deployed LLM advertising scenarios.
What would settle it
A deployment test in which models fine-tuned or prompted on NaiAD show no gains in measured user satisfaction or ad performance relative to baselines, or where the automated utility scores diverge from human judgments on separation of objectives.
Figures










read the original abstract
Reconciling platform revenue with user experience in LLM advertising motivates a data-centric foundation. We introduce NaiAD, the first comprehensive dataset for LLM-native advertising comprising 58,999 carefully constructed ad-embedded responses paired with user queries. NaiAD is organized around theoretically grounded evaluation metrics that separately and comprehensively capture user and commercial utility. To mitigate the dimensional collinearity of aligned LLMs, we propose a decoupled generation pipeline that produces structurally diverse samples, ranging from responses that explicitly disentangle stakeholder utilities to responses that are uniformly strong or weak across dimensions. We further provide score labels calibrated by a Variance-Calibrated Prediction-Powered Inference (VC-PPI) framework, aligning automated scoring with human annotations. Mechanistic analyses reveal that successful ad integration relies on reasoning paths that cluster into four distinct semantic strategies. Models leveraging NaiAD internalize these strategies to simultaneously improve user and commercial utility, while enabling independent control over these distinct objectives via in-context learning. Together, these results position NaiAD as a foundational infrastructure for developing future LLM-native ad systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NaiAD, a dataset of 58,999 ad-embedded LLM responses paired with queries, organized around metrics that separately capture user and commercial utility. It describes a decoupled generation pipeline to produce diverse samples (from disentangled to uniformly strong/weak responses), a VC-PPI framework to calibrate automated scores against human annotations, and mechanistic analyses that identify four semantic strategy clusters. The central claim is that models leveraging NaiAD internalize these strategies, yielding simultaneous gains in both utilities and independent control over them via in-context learning.
Significance. If the claims hold after external validation, NaiAD would provide valuable infrastructure for LLM-native advertising research by addressing the tension between platform revenue and user experience through data-driven methods. The decoupled pipeline and VC-PPI calibration offer practical tools for handling collinearity in aligned models, and the strategy clusters could inform prompting or fine-tuning techniques. The work's impact is currently limited by its exclusive reliance on synthetic data.
major comments (3)
- [Abstract] Abstract: The claim that 'Models leveraging NaiAD internalize these strategies to simultaneously improve user and commercial utility, while enabling independent control over these distinct objectives via in-context learning' lacks any quantitative validation, error analysis, baseline comparisons, or details on how internalization was measured or tested; the abstract supplies only the existence of the dataset, pipeline, calibration, and clusters.
- [Mechanistic analyses] Mechanistic analyses (as described in abstract): The four semantic strategy clusters are identified exclusively on the 58,999 constructed NaiAD samples; no external test set from deployed LLM advertising systems is used to verify whether the same clusters appear, whether they predict real engagement or revenue, or whether utility gains survive outside the synthetic distribution.
- [VC-PPI framework] VC-PPI calibration (abstract): The framework aligns automated scores only to human annotations collected on the same constructed samples, so it remains unclear whether the theoretically grounded metrics accurately and separately capture real user and commercial utility or whether reported improvements are artifacts of the decoupled generation process.
minor comments (2)
- [Abstract] Abstract: The four strategies are referenced but neither named nor exemplified, making it difficult to assess their distinctness or how they enable independent ICL control.
- [General] General: The manuscript would benefit from an explicit limitations section addressing the synthetic nature of the data and plans for real-world deployment testing.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. We address each major comment below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'Models leveraging NaiAD internalize these strategies to simultaneously improve user and commercial utility, while enabling independent control over these distinct objectives via in-context learning' lacks any quantitative validation, error analysis, baseline comparisons, or details on how internalization was measured or tested; the abstract supplies only the existence of the dataset, pipeline, calibration, and clusters.
Authors: We agree that the abstract, being concise by nature, does not include the quantitative details supporting the claim. The full manuscript contains dedicated experimental sections that measure internalization via in-context learning setups, reporting simultaneous utility gains relative to baselines along with controls for independent objective adjustment using the calibrated scores. We will revise the abstract to incorporate key quantitative highlights and a brief description of the evaluation methodology. revision: yes
-
Referee: [Mechanistic analyses] Mechanistic analyses (as described in abstract): The four semantic strategy clusters are identified exclusively on the 58,999 constructed NaiAD samples; no external test set from deployed LLM advertising systems is used to verify whether the same clusters appear, whether they predict real engagement or revenue, or whether utility gains survive outside the synthetic distribution.
Authors: The clusters are derived from the NaiAD dataset, which was explicitly constructed via the decoupled pipeline to produce diverse utility combinations and enable identification of semantic strategies. This internal analysis reveals consistent patterns correlating with balanced utilities. We acknowledge that external validation on real deployed systems would strengthen generalizability; however, such data is proprietary and unavailable for this foundational dataset paper. We will add an expanded limitations discussion outlining this point and how the public release of NaiAD supports future external studies. revision: partial
-
Referee: [VC-PPI framework] VC-PPI calibration (abstract): The framework aligns automated scores only to human annotations collected on the same constructed samples, so it remains unclear whether the theoretically grounded metrics accurately and separately capture real user and commercial utility or whether reported improvements are artifacts of the decoupled generation process.
Authors: The VC-PPI framework calibrates automated scores to human annotations collected on the NaiAD samples to align them with perceived utilities while accounting for variance, addressing collinearity in aligned models. The human annotations provide a direct grounding for the metrics' ability to separately capture the two utilities. We will expand the manuscript with additional details on the annotation process, agreement statistics, and theoretical justification of the metrics. Full validation against live production utilities would require access to deployed systems and is outside the scope of introducing this dataset. revision: partial
- External verification of the four semantic strategy clusters and utility gains on test sets from deployed LLM advertising systems or live user engagement data.
Circularity Check
No circularity; empirical dataset and observation paper
full rationale
The paper's core contribution is the construction of the NaiAD dataset via a decoupled generation pipeline, followed by VC-PPI calibration to human annotations on those samples and mechanistic clustering of reasoning paths within the same data. No mathematical derivation, parameter fitting presented as prediction, or self-citation chain is used to establish the central claims. The four semantic strategies are discovered from the constructed samples, and reported utility improvements and ICL control are observed on models trained or prompted on NaiAD; these are standard empirical findings on a new resource rather than a closed loop that reduces the result to its own inputs by definition or construction. External generalization is a separate validity concern, not circularity.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Mechanistic analyses reveal that successful ad integration relies on reasoning paths that cluster into four distinct semantic strategies... Value & Vision Alignment, Aesthetic & Lifestyle Resonance, Emotional & Psychological Bridging, Methodological Abstraction
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
NaiAD is organized around theoretically grounded evaluation metrics that separately and comprehensively capture user and commercial utility... decoupled generation pipeline... Variance-Calibrated Prediction-Powered Inference (VC-PPI)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Angelopoulos, Stephen Bates, Clara Fannjiang, Michael I
Anastasios N. Angelopoulos, Stephen Bates, Clara Fannjiang, Michael I. Jordan, and Tijana Zrnic. Prediction-powered inference.CoRR, abs/2301.09633, 2023
-
[2]
Anthropic. Introducing claude opus 4.5. https://www.anthropic.com/news/ claude-opus-4-5, November 24 2025. Accessed: 2026-05-06
work page 2025
-
[3]
Competition in two-sided markets.The RAND journal of economics, 37(3):668–691, 2006
Mark Armstrong. Competition in two-sided markets.The RAND journal of economics, 37(3):668–691, 2006
work page 2006
-
[4]
J.L. Austin.How To Do Things With Words: The William James Lectures delivered at Harvard University in 1955. Oxford University Press, September 1975
work page 1955
-
[5]
Mae-am: Query-driven multi-advertisement embeddings and auction mechanism in llm
Anonymous authors. Mae-am: Query-driven multi-advertisement embeddings and auction mechanism in llm. InComming Soon, 2026
work page 2026
-
[6]
Position auctions in ai-generated content
Santiago Balseiro, Kshipra Bhawalkar, Yuan Deng, Zhe Feng, Jieming Mao, Aranyak Mehta, Vahab Mirrokni, Renato Paes Leme, Di Wang, and Song Zuo. Position auctions in ai-generated content. InProceedings of the ACM Web Conference 2026, pages 261–272, 2026
work page 2026
-
[7]
Generating Campaign Ads & Keywords for Pro- grammatic Advertising.IEEE Access, 11:43557–43565, 2023
Ahmet Bulut and Abdelrahman Mahmoud. Generating Campaign Ads & Keywords for Pro- grammatic Advertising.IEEE Access, 11:43557–43565, 2023
work page 2023
-
[8]
Budget-Constrained Auctions with Unassured Priors: Strategic Equivalence and Structural Properties
Zhaohua Chen, Mingwei Yang, Chang Wang, Jicheng Li, Zheng Cai, Yukun Ren, Zhihua Zhu, and Xiaotie Deng. Budget-Constrained Auctions with Unassured Priors: Strategic Equivalence and Structural Properties. InProceedings of the ACM Web Conference 2024, pages 14–24, Singapore Singapore, May 2024. ACM
work page 2024
-
[9]
Query-Variant Adver- tisement Text Generation with Association Knowledge, September 2021
Siyu Duan, Wei Li, Cai Jing, Yancheng He, Yunfang Wu, and Xu Sun. Query-Variant Adver- tisement Text Generation with Association Knowledge, September 2021. arXiv:2004.06438 [cs]
-
[10]
Auctions with LLM Summaries, April 2024
Kumar Avinava Dubey, Zhe Feng, Rahul Kidambi, Aranyak Mehta, and Di Wang. Auctions with LLM Summaries, April 2024. arXiv:2404.08126 [cs]
-
[11]
Mechanism design for large language models
Paul Duetting, Vahab Mirrokni, Renato Paes Leme, Haifeng Xu, and Song Zuo. Mechanism design for large language models. InProceedings of the ACM Web Conference 2024, pages 144–155, 2024
work page 2024
-
[12]
Soheil Feizi, MohammadTaghi Hajiaghayi, Keivan Rezaei, and Suho Shin. Online advertise- ments with llms: Opportunities and challenges.arXiv preprint arXiv:2311.07601, 2023
-
[13]
arXiv preprint arXiv:2406.04291 , year=
Adam Fisch, Joshua Maynez, R. Alex Hofer, Bhuwan Dhingra, Amir Globerson, and William W. Cohen. Stratified prediction-powered inference for hybrid language model evaluation.CoRR, abs/2406.04291, 2024. 10
-
[14]
Ad Auctions for LLMs via Retrieval Augmented Generation
MohammadTaghi Hajiaghayi, Sébastien Lahaie, Keivan Rezaei, and Suho Shin. Ad Auctions for LLMs via Retrieval Augmented Generation. InAdvances in Neural Information Processing Systems 37, pages 18445–18480, Vancouver, BC, Canada, 2024. Neural Information Processing Systems Foundation, Inc. (NeurIPS)
work page 2024
-
[15]
Hendry Hendry, Tukino Tukino, Eko Sediyono, Ahmad Fauzi, and Baenil Huda. Hyewcos: A comparative study of hybrid embedding and weighting techniques for text similarity in short subjective educational text.Information, 16(11):995, 2025
work page 2025
-
[16]
Lingxiang Hu, Yiding Sun, Tianle Xia, Wenwei Li, Ming Xu, Liqun Liu, Peng Shu, Huan Yu, and Jie Jiang. AD-Bench: A Real-World, Trajectory-Aware Advertising Analytics Benchmark for LLM Agents, February 2026. arXiv:2602.14257 [cs]
-
[17]
Silan Hu, Shiqi Zhang, Yimin Shi, and Xiaokui Xiao. Gem-bench: A benchmark for ad-injected response generation within generative engine marketing.arXiv preprint arXiv:2509.14221, 2025
-
[18]
Mm-opera: Benchmarking open-ended association reasoning for large vision-language models, 2025
Zimeng Huang, Jinxin Ke, Xiaoxuan Fan, Yufeng Yang, Yang Liu, Liu Zhonghan, Zedi Wang, Junteng Dai, Haoyi Jiang, Yuyu Zhou, Keze Wang, and Ziliang Chen. Mm-opera: Benchmarking open-ended association reasoning for large vision-language models, 2025
work page 2025
-
[19]
Closing statement: Linguistics and poetics.Style in Language, 1960
Roman Jakobson. Closing statement: Linguistics and poetics.Style in Language, 1960
work page 1960
-
[20]
Artificial hivemind: The open-ended homogeneity of language models (and beyond)
Liwei Jiang, Yuanjun Chai, Margaret Li, Mickel Liu, Raymond Fok, Nouha Dziri, Yulia Tsvetkov, Maarten Sap, and Yejin Choi. Artificial hivemind: The open-ended homogeneity of language models (and beyond). InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2026
work page 2026
-
[21]
An Empiri- cal Study of Generating Texts for Search Engine Advertising
Hidetaka Kamigaito, Peinan Zhang, Hiroya Takamura, and Manabu Okumura. An Empiri- cal Study of Generating Texts for Search Engine Advertising. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Industry Papers, pages 255–262, Online, 2021. Association for Comput...
work page 2021
-
[22]
Striking Gold in Adver- tising: Standardization and Exploration of Ad Text Generation
Masato Mita, Soichiro Murakami, Akihiko Kato, and Peinan Zhang. Striking Gold in Adver- tising: Standardization and Exploration of Ad Text Generation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 955–972, Bangkok, Thailand, 2024. Association for Computational Linguistics
work page 2024
-
[23]
Tommy Mordo, Moshe Tennenholtz, and Oren Kurland. Sponsored Question Answering. InProceedings of the 2024 ACM SIGIR International Conference on Theory of Information Retrieval, pages 167–173, August 2024. arXiv:2407.04471 [cs]
-
[24]
NDTV News Desk. OpenAI faces backlash over ads appearing in ChatGPT, users advise "don’t do it". NDTV , December 5 2025. Accessed: May 4, 2026
work page 2025
- [25]
-
[26]
BannerBench: Benchmarking vision language models for multi-ad selection with human preferences
Hiroto Otake, Peinan Zhang, Yusuke Sakai, Masato Mita, Hiroki Ouchi, and Taro Watanabe. BannerBench: Benchmarking vision language models for multi-ad selection with human preferences. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Computational Linguistics: EMNLP 2025, pages 24145...
work page 2025
-
[27]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026
work page 2026
-
[28]
Qwen3.6-Plus: Towards real world agents, April 2026
Qwen Team. Qwen3.6-Plus: Towards real world agents, April 2026
work page 2026
-
[29]
Sentence-BERT: Sentence embeddings using Siamese BERT- networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT- networks. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors,Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992,...
work page 2019
-
[30]
Jean-Charles Rochet and Jean Tirole. Platform competition in two-sided markets.Journal of the european economic association, 1(4):990–1029, 2003
work page 2003
-
[31]
Detecting Generated Native Ads in Conversational Search
Sebastian Schmidt, Ines Zelch, Janek Bevendorff, Benno Stein, Matthias Hagen, and Martin Potthast. Detecting Generated Native Ads in Conversational Search. InCompanion Proceedings of the ACM Web Conference 2024, pages 722–725, Singapore Singapore, May 2024. ACM
work page 2024
-
[32]
John R. Searle. Speech acts: An essay in the philosophy of language. 1969
work page 1969
-
[33]
Xiang Shi, Jiawei Liu, Yinpeng Liu, Qikai Cheng, and Wei Lu. Know where to go: Make llm a relevant, responsible, and trustworthy searchers.Decision Support Systems, 188:114354, 2025
work page 2025
-
[34]
Ermis Soumalias, Michael J. Curry, and Sven Seuken. Truthful Aggregation of LLMs with an Application to Online Advertising, February 2025. arXiv:2405.05905 [cs]
-
[35]
The problem with OpenAI putting ads in ChatGPT
Jameson Spivack. The problem with OpenAI putting ads in ChatGPT. Observer, January 23
-
[36]
Accessed: May 4, 2026
work page 2026
-
[37]
When will chatgpt replace search? maybe sooner than you think, 2023
Peter Tsai. When will chatgpt replace search? maybe sooner than you think, 2023. Last accessed 11 November 2025
work page 2023
-
[38]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 24824–24837. Curran Assoc...
work page 2022
- [39]
-
[40]
Ad insertion in llm-generated responses.arXiv preprint arXiv:2601.19435, 2026
Shengwei Xu, Zhaohua Chen, Xiaotie Deng, Zhiyi Huang, and Grant Schoenebeck. Ad insertion in llm-generated responses.arXiv preprint arXiv:2601.19435, 2026
-
[41]
A User Study on the Acceptance of Native Advertising in Generative IR
Ines Zelch, Matthias Hagen, and Martin Potthast. A User Study on the Acceptance of Native Advertising in Generative IR. InProceedings of the 2024 ACM SIGIR Conference on Human Information Interaction and Retrieval, pages 142–152, Sheffield United Kingdom, March 2024. ACM
work page 2024
-
[42]
AdTEC: A unified benchmark for evaluating text quality in search engine advertising
Peinan Zhang, Yusuke Sakai, Masato Mita, Hiroki Ouchi, and Taro Watanabe. AdTEC: A unified benchmark for evaluating text quality in search engine advertising. InProceedings of the 2025 Annual Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL). Association for Computational Linguistics, 2025
work page 2025
-
[43]
LLM-Auction: Generative Auction towards LLM-Native Advertising
Chujie Zhao, Qun Hu, Shiping Song, Dagui Chen, Han Zhu, Jian Xu, and Bo Zheng. Llm- auction: Generative auction towards llm-native advertising.arXiv preprint arXiv:2512.10551, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
A Survey of Large Language Models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. A survey of large language models.arXiv preprint arXiv:2303.18223, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Judging llm-as-a-judge with mt-bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Syste...
work page 2023
-
[46]
Decoupled control allows platforms to dynamically slide along the Pareto frontier
Dynamic Pareto Optimization and Persona-Adaptive Integration.Traditional advertising imposes a trade-off: aggressive ads harm user experience, while subtle commercial content may sacrifice Click-Through Rates (CTR). Decoupled control allows platforms to dynamically slide along the Pareto frontier. For instance, systems can prioritize user utility (e.g., h...
-
[47]
Tiered Monetization and Attribute-Based Bidding.By offering programmatic control over com- mercial intensity, platforms can transition from traditional position-based bidding to utility-weighted exposure models. Advertisers seeking direct conversion can bid on specific commercial utility pa- rameters, whereas brand-awareness campaigns can optimize for hig...
-
[48]
Algorithmic Transparency and Modular System Iteration.As regulatory scrutiny over undis- closed promotional content and algorithmic bias intensifies, decoupled generation provides a verifiable mechanism for compliance. Platforms can mathematically constrain the commercial influence factor beneath predefined thresholds to ensure objective responses. From a...
-
[49]
Source Data and Domain Specificity.The NaiAD dataset is built upon queries from INFINITY- CHAT and advertisements from the A VTI dataset, which, while diverse, do not cover all possible user intents or commercial sectors. Consequently, models trained or evaluated on NaiAD may exhibit domain-specific biases and their performance may not generalize to under...
-
[50]
Scale of Human Calibration.Our VC-PPI framework relies on a human-annotated anchor set (n= 684 ) to calibrate the scores of the entire dataset. While statistically grounded, the robustness of 13 this calibration is constrained by the size and diversity of this anchor set. A larger and more varied set of human annotations could potentially refine the calib...
-
[51]
Hallucination and Factual Veracity.A significant, unresolved limitation is the potential for model-generated factual inaccuracies or hallucinations. • Ambiguity in Advertising Context:The boundary between persuasive marketing language, acceptable exaggeration, and harmful hallucination is inherently ambiguous. For instance, a model generating a claim not ...
-
[52]
Static, Single-Turn Interaction.The current version of NaiAD focuses on single-turn, query- response interactions. It does not capture the dynamics of multi-turn conversations where native advertising might need to adapt, persist, or be retracted based on user feedback over a prolonged dialogue. A.4 Broader Impact and Future Work Positive Societal Impact....
-
[53]
to generate the high-quality explicit reasoning paths (Logical Bridges) that intuitively mapped user queries to advertisements. • Strategy-Guided Dataset Generation (Section 3):The generation of the synthetic corpus in NaiAD, including the Chain-of-Thought (CoT) bridge construction and subsequent ad-embedded response generation, was also powered byClaude-...
-
[54]
is regularized based on the mean of preceding dimensions µ1:3: Q∗ 4 ∈ n max 1,min 5,⌊µ 1:3⌉+ϵ ϵ∈ {−1,0,1} o (5) where⌊·⌉denotes the nearest-integer rounding function. Rejection Sampling Boundaries.During generation, an instance self-evaluating as ˆQ∈R 4 is accepted against its target Q∗ if and only if it satisfies both the Chebyshev distance (L∞-norm) and...
-
[55]
**Keyword Extraction**: Extract 3-5 core semantic keywords from the ad copy
-
[56]
**Strategy Application**: Apply the above strategy to find a deep connection bridge between the user’s query and the ad
-
[57]
The ad content MUST be wrapped in <ad>...</ad> tags
**ad_injected_response**: Answer the query and integrate the ad using the specified strategy. The ad content MUST be wrapped in <ad>...</ad> tags. Include at least one concrete USP
-
[58]
Be honest about the quality level
**Strict Self-Evaluation**: Evaluate your response strictly against the Q1-Q4 criteria. Be honest about the quality level. ### Contextual Matching: Current query-ad semantic match tier: [{match_tier}]. {Q1_Q4_criteria} ### Mandatory Output Format (JSON ONLY): {JSON_SCHEMA} {few_shot_sample} CRITICAL: 1. Ensure your JSON is perfectly well-formed and COMPLE...
-
[59]
The "response" field MUST include the exact ad_name volume. Scoring Few-Shot Sample "query": "Please provide an example to explain what high-quality customer service is.", "ad_name": "Kelly Services", "llm_response": "Speaking of high-quality customer service, you might think of staff being very polite or someone providing help that makes you feel good—ma...
-
[60]
**Evidence Extraction**: Give bullet points on specific part or extracted key words of the text that influences this dimension
-
[61]
**Logic Reasoning**: Concisely state if this performance is better than, equal to, or worse than which provided shot for THIS dimension and EVERY comparison, strictly explain how your logic lead to the 1.0-5.0 scale in each comparison according to every criteria and shots
-
[62]
**Final Score**: Assign a float score based on the deduction. {few_shot_sample} [Target Turn] query: {query} response: {response} [Dimension to score] {targeting_dimension_criterion} Hint: The following methodology gives the base of scoring: The baseline for all scoring dimensions is set at 3. From there, imagine 24 adjusting a spring: treat 1 and 5 as op...
-
[63]
Independent Assessment:Each sample was independently reviewed to capture diverse perspec- tives
-
[64]
25 Figure 7: Screenshot of human annotation interface for scoring samples
Discrepancy Resolution:Samples showing significant variance in scoring (exceeding a threshold variance) were flagged for secondary review, where annotators discussed the discrepancy to reach a consensus score. 25 Figure 7: Screenshot of human annotation interface for scoring samples
-
[65]
Consistency Monitoring:The platform included “gold standard” check-samples (hidden to the annotator) to detect drifting scoring patterns, ensuring that the anchor set maintained high fidelity throughout the process. This rigorous approach ensures that DH functions as a high-fidelity reference, providing the statistical leverage necessary to calibrate the ...
-
[66]
Discrete Bias Shifts:By applying different correction terms ˆ∆k to different strata, the transforma- tion introduces discrete shifts across the score range. When these shifted clusters are aggregated into a single density plot, the boundaries between strata manifest as sharp transitions or localized spikes
-
[67]
Amplification of Integer-Preference Bias:Since both LLM judges and human annotators tend to favor certain descrete scores (e.g., integer-based scores), the raw data already contains clustering. Our stratified approach, by effectively centering each stratum on its respective human-aligned bias correction term, reinforces these existing score preferences an...
-
[68]
Effortless elegance starts with golden morning light and fresh espresso
-
[69]
Velvet nights and champagne dreams await the bold
-
[70]
Where marble floors meet ocean views—this is home
-
[71]
Cashmere mornings and silk evenings define the opulent life
-
[72]
Private jets and panoramic sunsets—live without limits
-
[73]
Crystal chandeliers reflecting a life well curated
-
[74]
From penthouse balconies, the world looks beautifully small
-
[75]
Designer details that whisper success in every stitch
-
[76]
Yacht decks, blue horizons, and endless possibility
-
[77]
The art of living well begins with exquisite taste
-
[78]
Gold accents and quiet confidence—luxury redefined
-
[79]
Where every sunrise greets you through floor-to-ceiling glass
-
[80]
Fine wine, good company, and memories that sparkle
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.