Recognition: 2 theorem links
· Lean TheoremXQCfD: Accelerating Fast Actor-Critic Algorithms with Prior Data and Prior Policies
Pith reviewed 2026-05-12 04:52 UTC · model grok-4.3
The pith
XQCfD uses stationary networks and augmented buffers to retain and improve upon pretrained policies in actor-critic learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
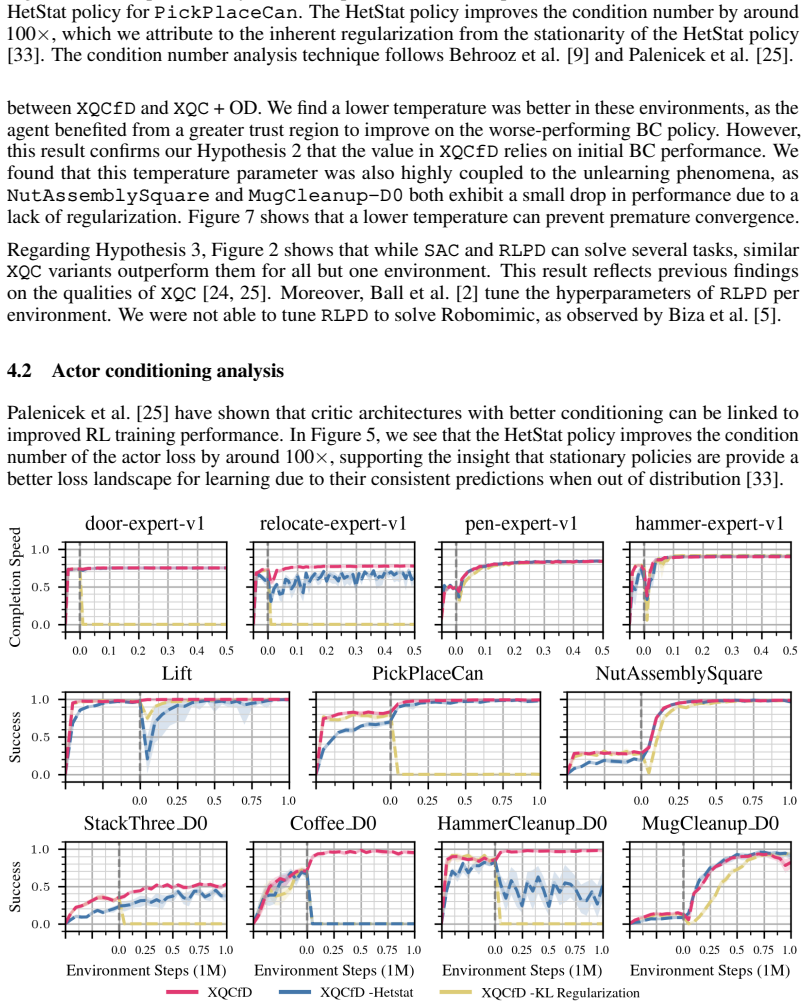
The central discovery is that a stationary policy architecture combined with augmented replay buffers allows the XQC actor-critic to avoid rapidly unlearning strong initial policies from demonstrations. Instead, the higher entropy predictions enable effective policy improvement on out-of-distribution states, producing state-of-the-art results across complex manipulation tasks on the Adroit, Robomimic, and MimicGen benchmarks with a low update-to-data ratio and no ensemble networks.
What carries the argument
Stationary policy network architecture that generates higher-entropy predictions out of distribution to support ongoing improvement from pretrained policies.
If this is right
- Pretrained policies can be retained and refined using demonstration data without special stabilization techniques beyond the stationary design.
- Robotic agents achieve higher sample efficiency in sparse-reward settings by mixing prior data with new interactions.
- Performance gains occur without increasing the update-to-data ratio or adding network ensembles.
- The method applies directly to popular benchmarks for dexterous manipulation.
Where Pith is reading between the lines
- Other fast actor-critic variants might benefit from similar stationary designs to preserve prior knowledge.
- This approach could lower the barrier to using demonstration data in online reinforcement learning by reducing the risk of catastrophic forgetting.
- Future work might test whether the higher entropy property holds across different task distributions beyond manipulation.
Load-bearing premise
The assumption that standard network architectures inherently lose high entropy predictions out of distribution, and that making them stationary will fix this without new instabilities.
What would settle it
Running the method on the Adroit benchmark and finding that the learned policy entropy matches that of non-stationary networks on out-of-distribution states, or that final performance does not exceed prior actor-critic baselines.
Figures







read the original abstract
For reinforcement learning in the real world online exploration is expensive A common practice in robotic reinforcement learning is to incorporate additional data to improve sample efficiency Expert demonstration data is often crucial for solving hard exploration tasks with sparse rewards While prior data is used to augment experience and pretrain models we show that the design of existing algorithms fails to achieve the sample efficiency that is possible in this setting due to a failure to use pretrained policies effectively We propose XQCfD which extends the sample-efficient XQC actor-critic to learn from demonstrations using augmented replay buffers pretrained policies and stationary policy architectures designed to avoid rapidly unlearning the strong initial policy like prior works We show our stationary network architecture enables policy improvement out-of-distribution better than standard network architectures due to its higher entropy predictions XQCfD achieves state of the art performance across a range of complex manipulation tasks with sparse rewards from the popular Adroit Robomimic and MimicGen benchmarks -- notably with a low update-to-data ratio and no ensemble networks
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes XQCfD, an extension of the XQC actor-critic algorithm that incorporates expert demonstration data via augmented replay buffers, pretrained policies, and stationary policy network architectures. The central claim is that this design prevents rapid unlearning of strong initial policies (unlike prior actor-critic methods), enables better out-of-distribution policy improvement through higher-entropy predictions, and achieves state-of-the-art sample-efficient performance on sparse-reward robotic manipulation tasks from the Adroit, Robomimic, and MimicGen benchmarks, notably without ensembles and at low update-to-data ratios.
Significance. If the empirical results hold under rigorous verification, the work could meaningfully advance sample-efficient robotic RL by showing how to better leverage prior data and policies. The emphasis on stationary architectures for preserving entropy in OOD regions offers a practical design insight that may reduce reliance on ensembles or high update frequencies in demonstration-augmented settings.
major comments (2)
- [Abstract] Abstract: The central attribution of SOTA gains to the stationary architecture's higher-entropy OOD predictions is load-bearing for the contribution, yet the provided description contains no reference to specific ablation studies, entropy measurements, or controlled comparisons against non-stationary baselines that would isolate this mechanism from the effects of augmented buffers and pretrained policies.
- [Abstract] The claim that existing actor-critic designs inherently fail to retain and improve upon strong pretrained policies (Abstract) requires explicit evidence from head-to-head experiments; without reported metrics on policy retention (e.g., performance degradation curves or KL divergence to the initial policy) on the same Adroit/MimicGen tasks, it is difficult to assess whether the stationary design is necessary or merely sufficient.
minor comments (2)
- [Abstract] The abstract is written as a single unbroken paragraph with multiple run-on clauses, reducing readability; breaking it into 2-3 sentences would improve clarity.
- [Abstract] The acronym XQCfD is introduced without an explicit expansion on first use, which is standard for algorithmic papers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the abstract and supporting claims with clearer evidence. We address each major comment below and will incorporate revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central attribution of SOTA gains to the stationary architecture's higher-entropy OOD predictions is load-bearing for the contribution, yet the provided description contains no reference to specific ablation studies, entropy measurements, or controlled comparisons against non-stationary baselines that would isolate this mechanism from the effects of augmented buffers and pretrained policies.
Authors: We agree the abstract is too concise on this point. The full manuscript includes ablation studies in Section 5.2 that isolate the stationary architecture by comparing variants with and without it (while holding buffers and pretraining fixed), plus entropy measurements in Figure 6 and OOD policy improvement analysis in Section 4.3. We will revise the abstract to explicitly reference these controlled comparisons and measurements. revision: yes
-
Referee: [Abstract] The claim that existing actor-critic designs inherently fail to retain and improve upon strong pretrained policies (Abstract) requires explicit evidence from head-to-head experiments; without reported metrics on policy retention (e.g., performance degradation curves or KL divergence to the initial policy) on the same Adroit/MimicGen tasks, it is difficult to assess whether the stationary design is necessary or merely sufficient.
Authors: Section 4.1 already reports head-to-head results on Adroit and MimicGen showing performance degradation for non-stationary baselines (SAC, TD3) initialized from the same pretrained policies, contrasted with XQCfD's retention and improvement. However, we did not include explicit KL divergence to the initial policy or full degradation curves. We will add these metrics in the revision to directly support the necessity claim. revision: yes
Circularity Check
No significant circularity; algorithmic extension with empirical validation
full rationale
The paper presents XQCfD as an extension of the prior XQC actor-critic algorithm, incorporating augmented replay buffers, pretrained policies, and a stationary network architecture. Claims of improved out-of-distribution policy improvement and SOTA performance on Adroit/Robomimic/MimicGen benchmarks are supported by experimental results rather than any closed-form derivations or predictions. No equations, fitted parameters renamed as predictions, or self-citation chains that reduce the central result to its own inputs appear in the provided abstract or high-level description. The derivation chain is self-contained against external benchmarks and does not exhibit self-definitional, fitted-input, or uniqueness-imported circularity.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose XQCfD which extends the sample-efficient XQC actor-critic to learn from demonstrations using augmented replay buffers, pre-trained policies and stationary policy architectures... HetStat policies... random Fourier features
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
stationary last layer features... p(z|s) = N(0, σ²) ... random Fourier features φθ,V(s) = fk(V s)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Maximum a posteriori policy optimisation
Abbas Abdolmaleki, Jost Tobias Springenberg, Yuval Tassa, Remi Munos, Nicolas Heess, and Martin Riedmiller. Maximum a posteriori policy optimisation. InInternational Conference on Learning Representations (ICLR), 2018
work page 2018
-
[2]
Efficient online reinforcement learning with offline data
Philip J Ball, Laura Smith, Ilya Kostrikov, and Sergey Levine. Efficient online reinforcement learning with offline data. InInternational Conference on Machine Learning (ICML), 2023
work page 2023
-
[3]
Bellemare, Will Dabney, and Rémi Munos
Marc G. Bellemare, Will Dabney, and Rémi Munos. A distributional perspective on reinforce- ment learning. InInternational Conference on Machine Learning (ICML), 2017
work page 2017
-
[4]
Aditya Bhatt, Daniel Palenicek, Boris Belousov, Max Argus, Artemij Amiranashvili, Thomas Brox, and Jan Peters. CrossQ: Batch normalization in deep reinforcement learning for greater sample efficiency and simplicity.International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[5]
On-robot reinforcement learning with goal-contrastive rewards
Ondrej Biza, Thomas Weng, Lingfeng Sun, Karl Schmeckpeper, Tarik Kelestemur, Yecheng Ja- son Ma, Robert Platt, Jan-Willem van de Meent, and Lawson LS Wong. On-robot reinforcement learning with goal-contrastive rewards. InIEEE International Conference on Robotics and Automation (ICRA), 2025
work page 2025
-
[6]
Randomized Ensembled Dou- ble Q-Learning: Learning fast without a model
Xinyue Chen, Che Wang, Zijian Zhou, and Keith W Ross. Randomized Ensembled Dou- ble Q-Learning: Learning fast without a model. InInternational Conference on Learning Representations (ICLR), 2021
work page 2021
-
[7]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research (IJRR), 2025
work page 2025
-
[8]
Monroe D Donsker and SR Srinivasa Varadhan. Asymptotic evaluation of certain Markov process expectations for large time.Communications on Pure and Applied Mathematics, 1983
work page 1983
-
[9]
An investigation into neural net opti- mization via Hessian eigenvalue density
Behrooz Ghorbani, Shankar Krishnan, and Ying Xiao. An investigation into neural net opti- mization via Hessian eigenvalue density. InInternational Conference on Machine Learning (ICML), 2019
work page 2019
-
[10]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational Conference on Machine Learning (ICML), 2018. 10
work page 2018
-
[11]
TD-MPC2: Scalable, robust world models for continuous control
Nicklas Hansen, Hao Su, and Xiaolong Wang. TD-MPC2: Scalable, robust world models for continuous control. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[12]
Imitation bootstrapped reinforcement learning
Hengyuan Hu, Suvir Mirchandani, and Dorsa Sadigh. Imitation bootstrapped reinforcement learning. InRobotics: Science and Systems (RSS), 2024
work page 2024
-
[13]
Batch normalization: Accelerating deep network training by reducing internal covariate shift
Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. InInternational Conference on Machine Learning (ICML), 2015
work page 2015
-
[14]
Jens Kober and Jan Peters. Policy search for motor primitives in robotics.Advances in Neural Information Processing Systems (NeurIPS), 2008
work page 2008
-
[15]
Offline-to-online reinforcement learning via balanced replay and pessimistic Q-ensemble
Seunghyun Lee, Younggyo Seo, Kimin Lee, Pieter Abbeel, and Jinwoo Shin. Offline-to-online reinforcement learning via balanced replay and pessimistic Q-ensemble. InConference on Robot Learning (CoRL), 2022
work page 2022
-
[16]
End-to-end training of deep visuomotor policies.Journal of Machine Learning Research (JMLR), 2016
Sergey Levine, Chelsea Finn, Trevor Darrell, and Pieter Abbeel. End-to-end training of deep visuomotor policies.Journal of Machine Learning Research (JMLR), 2016
work page 2016
-
[17]
Normalization and effective learning rates in reinforcement learning
Clare Lyle, Zeyu Zheng, Khimya Khetarpal, James Martens, Hado van Hasselt, Razvan Pascanu, and Will Dabney. Normalization and effective learning rates in reinforcement learning. In Advances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[18]
What matters in learning from offline human demonstrations for robot manipulation
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Martín-Martín. What matters in learning from offline human demonstrations for robot manipulation. InConference on Robot Learning (CoRL), 2021
work page 2021
-
[19]
Mimicgen: A data generation system for scalable robot learning using human demonstrations
Ajay Mandlekar, Soroush Nasiriany, Bowen Wen, Iretiayo Akinola, Yashraj Narang, Linxi Fan, Yuke Zhu, and Dieter Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations. InConference on Robot Learning (CoRL), 2023
work page 2023
-
[20]
Periodic activation functions induce stationarity
Lassi Meronen, Martin Trapp, and Arno Solin. Periodic activation functions induce stationarity. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
work page 2021
-
[21]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
Ashvin Nair, Abhishek Gupta, Murtaza Dalal, and Sergey Levine. AW AC: Accelerating online reinforcement learning with offline datasets.arXiv preprint arXiv:2006.09359, 2020
work page internal anchor Pith review arXiv 2006
-
[22]
Mitsuhiko Nakamoto, Simon Zhai, Anikait Singh, Max Sobol Mark, Yi Ma, Chelsea Finn, Aviral Kumar, and Sergey Levine. Cal-QL: Calibrated offline RL pre-training for efficient online fine-tuning.Advances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[23]
Manu Orsini, Anton Raichuk, Léonard Hussenot, Damien Vincent, Robert Dadashi, Sertan Girgin, Matthieu Geist, Olivier Bachem, Olivier Pietquin, and Marcin Andrychowicz. What matters for adversarial imitation learning? InAdvances in Neural Information Processing Systems (NeurIPS), 2021
work page 2021
-
[24]
Daniel Palenicek, Florian V ogt, Joe Watson, and Jan Peters. Scaling off-policy reinforcement learning with batch and weight normalization.Advances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[25]
Daniel Palenicek, Florian V ogt, Joe Watson, Ingmar Posner, and Jan Peters. XQC: Well- conditioned optimization accelerates deep reinforcement learning.International Conference on Learning Representations (ICLR), 2026
work page 2026
-
[26]
Policy gradient methods for robotics
Jan Peters and Stefan Schaal. Policy gradient methods for robotics. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2006
work page 2006
-
[27]
Information theoretic methods in statistics and computer science: Lecture 1 — f-divergences, 2020
Yury Polyanskiy. Information theoretic methods in statistics and computer science: Lecture 1 — f-divergences, 2020
work page 2020
-
[28]
D. A. Pomerleau. Efficient training of artificial neural networks for autonomous navigation. Neural Computation, 1991. 11
work page 1991
-
[29]
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines.Advances in Neural Information Processing Systems (NeurIPS), 2007
work page 2007
-
[30]
Aravind Rajeswaran, Vikash Kumar, Abhishek Gupta, Giulia Vezzani, John Schulman, Emanuel Todorov, and Sergey Levine. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations.Robotics: Science and Systems (RSS), 2018
work page 2018
-
[31]
Rasmussen and Chris Williams.Gaussian Processes for Machine Learning
Carl E. Rasmussen and Chris Williams.Gaussian Processes for Machine Learning. MIT Press, 2006
work page 2006
-
[32]
On stochastic optimal control and reinforcement learning by approximate inference
Konrad Rawlik, Marc Toussaint, and Sethu Vijayakumar. On stochastic optimal control and reinforcement learning by approximate inference. InRobotics: Science and Systems (RSS), 2013
work page 2013
-
[33]
Tim GJ Rudner, Cong Lu, Michael A Osborne, Yarin Gal, and Yee Teh. On pathologies in KL-regularized reinforcement learning from expert demonstrations.Advances in Neural Information Processing Systems (NeurIPS), 2021
work page 2021
-
[34]
Shibani Santurkar, Dimitris Tsipras, Andrew Ilyas, and Aleksander Madry. How does batch nor- malization help optimization?Advances in Neural Information Processing Systems (NeurIPS), 2018
work page 2018
-
[35]
Nicol Schraudolph, Peter Dayan, and Terrence J Sejnowski. Temporal difference learning of position evaluation in the game of Go.Advances in Neural Information Processing Systems (NeurIPS), 1993
work page 1993
-
[36]
Keep doing what worked: Behavior modelling priors for offline reinforcement learning
Noah Siegel, Jost Tobias Springenberg, Felix Berkenkamp, Abbas Abdolmaleki, Michael Neunert, Thomas Lampe, Roland Hafner, Nicolas Heess, and Martin Riedmiller. Keep doing what worked: Behavior modelling priors for offline reinforcement learning. InInternational Conference on Learning Representations (ICLR), 2020
work page 2020
-
[37]
Mastering the game of Go with deep neural networks and tree search.Nature, 2016
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driess- che, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mastering the game of Go with deep neural networks and tree search.Nature, 2016
work page 2016
-
[38]
Andrew Stirn, Hans-Hermann Wessels, Megan Schertzer, Laura Pereira, Neville E. Sanjana, and David A. Knowles. Faithful heteroscedastic regression with neural networks. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2023
work page 2023
-
[39]
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. The MIT Press, Cambridge, MA, 1998
work page 1998
-
[40]
L2 regularization versus batch and weight normalization
Twan Van Laarhoven. L2 regularization versus batch and weight normalization.arXiv preprint arXiv:1706.05350, 2017
-
[41]
Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards
Mel Vecerik, Todd Hester, Jonathan Scholz, Fumin Wang, Olivier Pietquin, Bilal Piot, Nicolas Heess, Thomas Rothörl, Thomas Lampe, and Martin Riedmiller. Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards.arXiv preprint arXiv:1707.08817, 2017
work page Pith review arXiv 2017
-
[42]
Neural linear models with functional Gaussian process priors
Joe Watson, Jihao Andreas Lin, Pascal Klink, and Jan Peters. Neural linear models with functional Gaussian process priors. InThird Symposium on Advances in Approximate Bayesian Inference
-
[43]
Joe Watson, Sandy H. Huang, and Nicolas Heess. Coherent soft imitation learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[44]
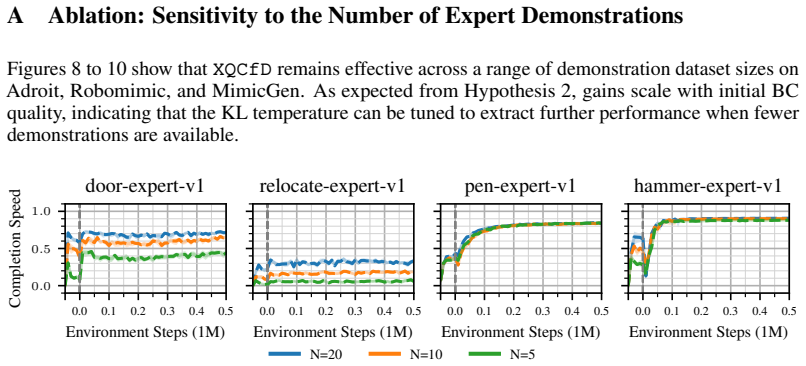
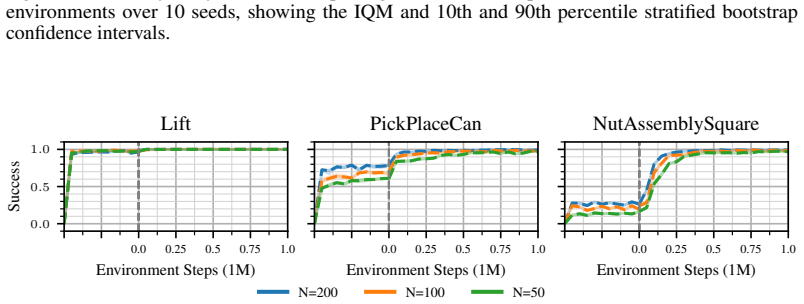
Yi Zhao, Rinu Boney, Alexander Ilin, Juho Kannala, and Joni Pajarinen. Adaptive behavior cloning regularization for stable offline-to-online reinforcement learning.Offline Reinforcement Learning Workshop at Neural Information Processing Systems, 2021. 12 A Ablation: Sensitivity to the Number of Expert Demonstrations Figures 8 to 10 show that XQCfD remains...
work page 2021
-
[45]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.