DriveCtrl: Conditioned Sim-to-Real Driving Video Generation
Pith reviewed 2026-06-30 21:03 UTC · model grok-4.3
The pith
DriveCtrl generates realistic driving videos from simulations while preserving scene layout and annotations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
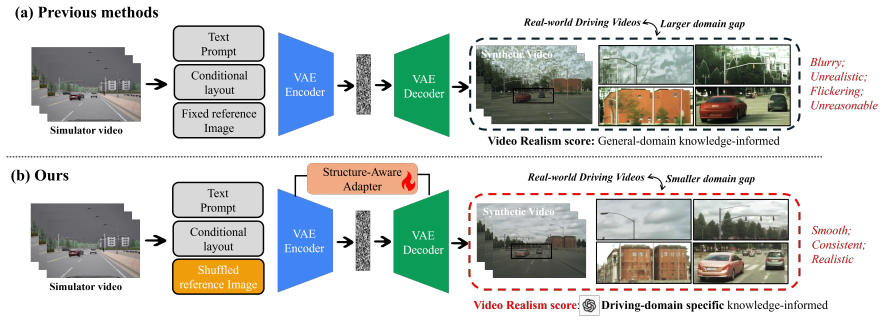
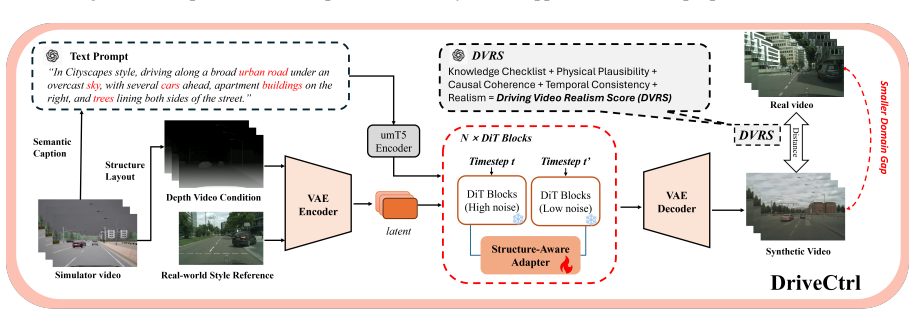
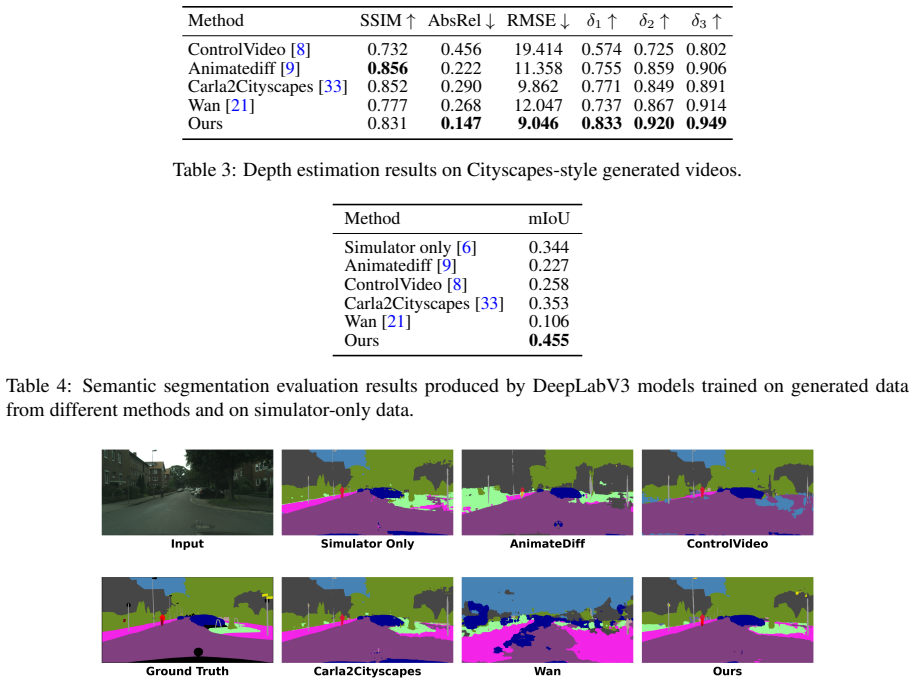
DriveCtrl is a depth-conditioned controllable sim-to-real video generation framework built on a pretrained video foundation model; its structure-aware adapter enables depth-guided generation while preserving the scene layout and motion patterns of the source simulation, yielding temporally coherent videos aligned with the original sequences; the accompanying pipeline supports structural depth, reference style, and text conditioning and retains frame-level annotations; experiments show consistent gains over the base model and alternatives in realism, temporal quality, and perception-task performance.
What carries the argument
The structure-aware adapter, which conditions generation on depth to preserve scene layout and motion patterns from the simulation.
If this is right
- Generated videos remain aligned with the original simulated sequences, keeping annotations valid for downstream tasks.
- The method outperforms the base model and alternatives in visual realism and temporal consistency.
- The pipeline supports depth, style, and text conditioning while retaining frame-level labels.
- Use of the new DVRS metric provides a domain-specific way to quantify driving video realism.
Where Pith is reading between the lines
- If the adapter generalizes, the same conditioning approach could apply to other simulation environments that supply depth.
- Mixing these generated videos with real data could increase effective training set size without additional manual labeling.
- The preservation of motion patterns suggests the method could support tasks that require consistent object tracking across frames.
Load-bearing premise
The structure-aware adapter can use depth to guide visual realism without altering the original scene layout or motion patterns.
What would settle it
A test showing that videos generated by DriveCtrl produce lower perception-task accuracy than the base model or that object positions and trajectories deviate from the source simulation annotations.
Figures



read the original abstract
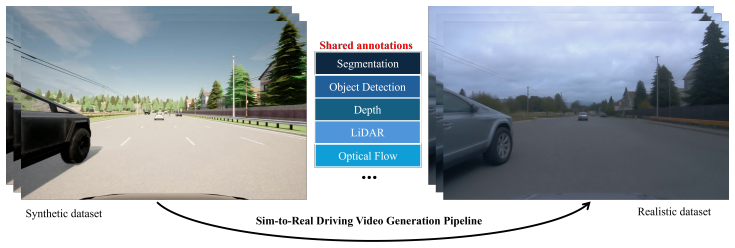
Large-scale labelled driving video data is essential for training autonomous driving systems. Although simulation offers scalable and fully annotated data, the domain gap between synthetic and real-world driving videos significantly limits its utility for downstream deployment. Existing video generation methods are not well-suited for this task, as they fail to simultaneously preserve scene structure, object dynamics, temporal consistency, and visual realism, all of which are critical for maintaining annotation validity in generated data. In this paper, we present DriveCtrl, a depth-conditioned controllable sim-to-real video generation framework for realistic driving video synthesis. Built upon a pretrained video foundation model, DriveCtrl introduces a structure-aware adapter that enables depth-guided generation while preserving the scene layout and motion patterns of the source simulation, producing temporally coherent driving videos that remain aligned with the original simulated sequences. We further introduce a scalable data generation pipeline that transforms simulator videos into realistic driving footage matching the visual style of a target real-world dataset. The pipeline supports three conditioning signals: structural depth, reference-dataset style, and text prompts, while preserving frame-level annotations for downstream perception tasks. To better assess this task, we propose a driving-domain-specific knowledge-informed evaluation metric called Driving Video Realism Score (DVRS) that assesses the realism of generated videos. Experiments demonstrate that DriveCtrl consistently outperforms the base model and competing alternatives in realism, temporal quality, and perception task performance, substantially narrowing the sim-to-real gap for driving video generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DriveCtrl, a depth-conditioned controllable sim-to-real video generation framework built on a pretrained video foundation model. It proposes a structure-aware adapter to enable depth-guided generation while preserving scene layout and motion from simulation, a scalable pipeline supporting structural depth, reference style, and text prompts, and a new Driving Video Realism Score (DVRS) metric. The abstract claims consistent outperformance over the base model and alternatives in realism, temporal quality, and perception task performance, substantially narrowing the sim-to-real gap while preserving frame-level annotations.
Significance. If the experimental claims hold with proper validation, the work could meaningfully advance scalable labeled data generation for autonomous driving perception by bridging simulation and real domains without losing annotation utility. The domain-specific DVRS metric is a constructive addition for evaluation in this area.
major comments (2)
- [Abstract] Abstract: The central claim that DriveCtrl 'consistently outperforms the base model and competing alternatives in realism, temporal quality, and perception task performance' and 'substantially narrowing the sim-to-real gap' is asserted without any reference to baselines, quantitative results, tables, or error analysis. This is load-bearing for the utility argument and prevents assessment of evidence strength.
- [Abstract] Abstract: The structure-aware adapter is presented as the mechanism that 'enables depth-guided generation while preserving the scene layout and motion patterns of the source simulation' and that the pipeline 'preserves frame-level annotations for downstream perception tasks,' yet no architecture details, auxiliary losses for label consistency, or ablations measuring annotation drift (e.g., object position or depth shifts) are described. This directly undermines the claim that generated videos remain usable as labeled training data.
minor comments (1)
- [Abstract] Abstract: The description of DVRS as 'driving-domain-specific knowledge-informed' would benefit from a one-sentence expansion on the knowledge components or how it differs from standard metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the claims require stronger grounding and will revise the abstract to better reference the experimental evidence and mechanisms presented in the full manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that DriveCtrl 'consistently outperforms the base model and competing alternatives in realism, temporal quality, and perception task performance' and 'substantially narrowing the sim-to-real gap' is asserted without any reference to baselines, quantitative results, tables, or error analysis. This is load-bearing for the utility argument and prevents assessment of evidence strength.
Authors: The abstract serves as a high-level summary. The full manuscript contains the supporting evidence in Section 4, with Tables 1–3 reporting quantitative comparisons against the base model and alternatives on realism (DVRS, FID), temporal quality (FVD, warping error), and perception task performance (e.g., mAP gains on detection and segmentation). Error bars and statistical analysis appear in the main text and supplementary material. We will revise the abstract to include key numerical results and explicit pointers to these tables and sections. revision: yes
-
Referee: [Abstract] Abstract: The structure-aware adapter is presented as the mechanism that 'enables depth-guided generation while preserving the scene layout and motion patterns of the source simulation' and that the pipeline 'preserves frame-level annotations for downstream perception tasks,' yet no architecture details, auxiliary losses for label consistency, or ablations measuring annotation drift (e.g., object position or depth shifts) are described. This directly undermines the claim that generated videos remain usable as labeled training data.
Authors: Architecture details of the structure-aware adapter, including its depth-injection design and motion-preservation properties, are provided in Section 3.2. The pipeline maintains annotation alignment via direct structural conditioning from simulation depth maps rather than auxiliary losses. The manuscript includes qualitative alignment checks and some quantitative scene-consistency metrics, but does not contain dedicated ablations quantifying object-position or depth drift. We will add a brief reference to the adapter details in the abstract and include the requested annotation-drift ablations in the revised experiments section. revision: partial
Circularity Check
No circularity: claims rest on proposed architecture and external experiments with no derivations or self-referential reductions.
full rationale
The paper presents an empirical architecture (DriveCtrl with structure-aware adapter) and a data pipeline for sim-to-real video generation. No equations, first-principles derivations, or mathematical predictions are present. All claims of performance and annotation preservation are supported by external experiments, comparisons to base models, and a proposed metric (DVRS), rather than any self-definition, fitted-input renaming, or load-bearing self-citation chains. The central utility argument (preservation of simulator labels) is asserted via the adapter design but evaluated externally; it does not reduce to the inputs by construction. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained video foundation model supports effective depth conditioning via adapter while preserving motion patterns
Reference graph
Works this paper leans on
-
[1]
The cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3213–3223, 2016
2016
-
[2]
Bdd100k: A diverse driving dataset for heterogeneous multitask learning
Fisher Yu, Haofeng Chen, Xin Wang, Wenqi Xian, Yingying Chen, Fangchen Liu, Vashisht Madhavan, and Trevor Darrell. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[3]
Scalability in perception for au- tonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aur ´elien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, Vijay Vasudevan, Wei Han, Jiquan Ngiam, Hang Zhao, Alek- sei Timofeev, Scott Ettinger, Maxim Krivokon, Amy Gao, Aditya Joshi, Sheng Zhao, Shuyang Cheng, Yu Zhang, Jonathon Shlens, Zhifeng Chen, and Dragomir Angu...
2020
-
[4]
Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[5]
Exploring generative ai for sim2real in driving data synthesis
Haonan Zhao, Yiting Wang, Thomas Bashford-Rogers, Valentina Donzella, and Kurt Debattista. Exploring generative ai for sim2real in driving data synthesis. In2024 IEEE Intelligent Vehicles Symposium (IV), pages 3071–3077. IEEE, 2024
2024
-
[6]
Shift: A synthetic driving dataset for continuous multi-task domain adaptation
Tao Sun, Mattia Segu, Janis Postels, Yuxuan Wang, Luc Van Gool, Bernt Schiele, Federico Tombari, and Fisher Yu. Shift: A synthetic driving dataset for continuous multi-task domain adaptation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[7]
Meta-sim: Learning to generate synthetic datasets
Amlan Kar, Aayush Prakash, Ming-Yu Liu, Eric Cameracci, Justin Yuan, Matt Rusiniak, David Acuna, Antonio Torralba, and Sanja Fidler. Meta-sim: Learning to generate synthetic datasets. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019
2019
-
[8]
Controlvideo: Training-free controllable text-to-video generation
Yabo Zhang, Yuxiang Wei, Dongsheng Jiang, Xiaopeng Zhang, Wangmeng Zuo, and Qi Tian. Controlvideo: Training-free controllable text-to-video generation. InInternational Conference on Learning Representa- tions (ICLR), 2024
2024
-
[9]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning.arXiv preprint arXiv:2307.04725, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Magicdrive: Street view generation with diverse 3d geometry control,
Ruiyuan Gao, Kai Chen, Enze Xie, Lanqing Hong, Zhenguo Li, Dit-Yan Yeung, and Qiang Xu. Magicdrive: Street view generation with diverse 3d geometry control.arXiv preprint arXiv:2310.02601, 2024
-
[12]
Drivingdiffusion: Layout-guided multi-view driving scenarios video generation with latent diffusion model
Xiaofan Li, Yifu Zhang, and Xiaoqing Ye. Drivingdiffusion: Layout-guided multi-view driving scenarios video generation with latent diffusion model. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[13]
Wovogen: World volume-aware diffusion for controllable multi-camera driving scene generation
Jiachen Lu, Ze Huang, Zeyu Yang, Jiahui Zhang, and Li Zhang. Wovogen: World volume-aware diffusion for controllable multi-camera driving scene generation. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[14]
Drivedreamer: To- wards real-world-driven world models for autonomous driving
Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jiagang Zhu, and Jiwen Lu. Drivedreamer: To- wards real-world-driven world models for autonomous driving. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[15]
Drivedreamer-2: Llm-enhanced world models for diverse driving video generation
Guosheng Zhao, Xiaofeng Wang, Zheng Zhu, Xinze Chen, Guan Huang, Xiaoyi Bao, and Xingang Wang. Drivedreamer-2: Llm-enhanced world models for diverse driving video generation. InProceedings of the AAAI Conference on Artificial Intelligence, 2025. 11
2025
-
[16]
Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving
Yuqi Wang, Jiawei He, Lue Fan, Hongxin Li, Yuntao Chen, and Zhaoxiang Zhang. Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[17]
Jiageng Mao, Boyi Li, Boris Ivanovic, Yuxiao Chen, Yan Wang, Yurong You, Chaowei Xiao, Danfei Xu, Marco Pavone, and Yue Wang. Dreamdrive: Generative 4d scene modeling from street view images.arXiv preprint arXiv:2501.00601, 2025
-
[18]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. InAdvances in Neural Information Processing Systems, volume 30, pages 6626–6637, 2017
2017
-
[19]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Syl- vain Gelly. Towards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J. Fleet. Video diffusion models.arXiv preprint arXiv:2204.03458, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Weifeng Chen, Yatai Ji, Jie Wu, Hefeng Wu, Pan Xie, Jiashi Li, Xin Xia, Xuefeng Xiao, and Liang Lin. Control-a-video: Controllable text-to-video diffusion models with motion prior and reward feedback learn- ing.arXiv preprint arXiv:2305.13840, 2023
-
[23]
DragNUWA: Fine-grained Control in Video Generation by Integrating Text, Image, and Trajectory
Shengming Yin, Chenfei Wu, Jian Liang, Jie Shi, Houqiang Li, Ming Gong, and Nan Duan. Drag- nuwa: Fine-grained control in video generation by integrating text, image, and trajectory.arXiv preprint arXiv:2308.08089, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Mo- tionctrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Mo- tionctrl: A unified and flexible motion controller for video generation. InACM SIGGRAPH 2024 Conference Papers, 2024
2024
-
[25]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
World Simulation with Video Foundation Models for Physical AI
NVIDIA, Arslan Ali, et al. World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Dianbing Xi, Jiepeng Wang, Yuanzhi Liang, Xi Qi, Yuchi Huo, Rui Wang, Chi Zhang, and Xuelong Li. Omnivdiff: Omni controllable video diffusion for generation and understanding.arXiv preprint arXiv:2504.10825, 2025
-
[28]
Synscapes: A Photorealistic Synthetic Dataset for Street Scene Parsing
Magnus Wrenninge and Jonas Unger. Synscapes: A photorealistic synthetic dataset for street scene parsing. arXiv preprint arXiv:1810.08705, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
Unisim: A neural closed-loop sensor simulator
Ze Yang, Yun Chen, Jingkang Wang, Sivabalan Manivasagam, Wei-Chiu Ma, Anqi Joyce Yang, and Raquel Urtasun. Unisim: A neural closed-loop sensor simulator. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1389–1399, 2023
2023
-
[30]
GeoDiffu- sion: Text-prompted geometric control for object detection data generation
Kai Chen, Enze Xie, Zhe Chen, Yibo Wang, Lanqing Hong, Zhenguo Li, and Dit-Yan Yeung. GeoDiffu- sion: Text-prompted geometric control for object detection data generation. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[31]
Surfelgan: Synthesizing realistic sensor data for autonomous driving
Zhenpei Yang, Yuning Chai, Dragomir Anguelov, Yin Zhou, Pei Sun, Dumitru Erhan, Sean Rafferty, and Henrik Kretzschmar. Surfelgan: Synthesizing realistic sensor data for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[32]
Richter, Hassan Abu Alhaija, and Vladlen Koltun
Stephan R. Richter, Hassan Abu Alhaija, and Vladlen Koltun. Enhancing photorealism enhancement.arXiv preprint arXiv:2105.04619, 2021
-
[33]
Carla2real: A tool for reducing the sim2real appearance gap in carla simulator.IEEE Transactions on Intelligent Transportation Systems, 2025
Stefanos Pasios and Nikos Nikolaidis. Carla2real: A tool for reducing the sim2real appearance gap in carla simulator.IEEE Transactions on Intelligent Transportation Systems, 2025. 12
2025
-
[34]
World-consistent video-to-video synthesis
Arun Mallya, Ting-Chun Wang, Karan Sapra, and Ming-Yu Liu. World-consistent video-to-video synthesis. InEuropean Conference on Computer Vision, pages 359–378. Springer, 2020
2020
-
[35]
Flowvid: Taming imperfect optical flows for consistent video-to-video synthesis
Feng Liang, Bichen Wu, Jialiang Wang, Licheng Yu, Kunpeng Li, Yinan Zhao, Ishan Misra, Jia-Bin Huang, Peizhao Zhang, Peter Vajda, et al. Flowvid: Taming imperfect optical flows for consistent video-to-video synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8207–8216, 2024
2024
-
[36]
Panacea: Panoramic and controllable video generation for autonomous driving
Yuqing Wen, Yucheng Zhao, Yingfei Liu, Fan Jia, Yanhui Wang, Chong Luo, Chi Zhang, Tiancai Wang, Xiaoyan Sun, and Xiangyu Zhang. Panacea: Panoramic and controllable video generation for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6902–6912, 2024
2024
-
[37]
Yuqing Wen, Yucheng Zhao, Yingfei Liu, Binyuan Huang, Fan Jia, Yanhui Wang, Chi Zhang, Tiancai Wang, Xiaoyan Sun, and Xiangyu Zhang. Panacea+: Panoramic and controllable video generation for autonomous driving.arXiv preprint arXiv:2408.07605, 2024
-
[38]
Ruiyuan Gao, Kai Chen, Zhihao Li, Lanqing Hong, Zhenguo Li, and Qiang Xu. MagicDrive3D: Controllable 3d generation for any-view rendering in street scenes.arXiv preprint arXiv:2405.14475, 2024
-
[39]
GAIA-1: A Generative World Model for Autonomous Driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving.arXiv preprint arXiv:2309.17080, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Vista: A generalizable driving world model with high fidelity and versatile controllability
Shenyuan Gao, Jiazhi Yang, Li Chen, Kashyap Chitta, Yihang Qiu, Andreas Geiger, Jun Zhang, and Hongyang Li. Vista: A generalizable driving world model with high fidelity and versatile controllability. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[41]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
2024
-
[42]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Lulu Gu, Yuanhan Zhang, Jingwen He, Wei-Shi Zheng, Yu Qiao, and Ziwei Liu. Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
VideoPhy: Evaluating Physical Commonsense for Video Generation
Hritik Bansal, Zongyu Lin, Tianyi Xie, Zeshun Zong, Michal Yarom, Yonatan Bitton, Chenfanfu Jiang, Yizhou Sun, Kai-Wei Chang, and Aditya Grover. Videophy: Evaluating physical commonsense for video generation.arXiv preprint arXiv:2406.03520, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Towards World Simulator: Crafting Physical Commonsense-Based Benchmark for Video Generation
Fanqing Meng, Jiaqi Liao, Xinyu Tan, Wenqi Shao, Quanfeng Lu, Kaipeng Zhang, Yu Cheng, Dianqi Li, Yu Qiao, and Ping Luo. Towards world simulator: Crafting physical commonsense-based benchmark for video generation.arXiv preprint arXiv:2410.05363, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
WISE: A World Knowledge-Informed Semantic Evaluation for Text-to-Image Generation
Yuwei Niu, Munan Ning, Mengren Zheng, Weiyang Jin, Bin Lin, Peng Jin, Jiaqi Liao, Chaoran Feng, Kunpeng Ning, Bin Zhu, and Li Yuan. Wise: A world knowledge-informed semantic evaluation for text-to- image generation.arXiv preprint arXiv:2503.07265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Daoan Zhang, Che Jiang, Ruoshi Xu, Biaoxiang Chen, Zijian Jin, Yutian Lu, Jianguo Zhang, Liang Yong, Jiebo Luo, and Shengda Luo. Worldgenbench: A world-knowledge-integrated benchmark for reasoning- driven text-to-image generation.arXiv preprint arXiv:2505.01490, 2025
-
[47]
arXiv preprint arXiv:2503.06800 (2025) 3, 4
Hritik Bansal, Clark Peng, Yonatan Bitton, Roman Goldenberg, Aditya Grover, and Kai-Wei Chang. Videophy-2: A challenging action-centric physical commonsense evaluation in video generation.arXiv preprint arXiv:2503.06800, 2025
-
[48]
T2vworldbench: A benchmark for evaluating world knowledge in text-to-video generation
Yubin Chen, Xuyang Guo, Zhenmei Shi, Zhao Song, and Jiahao Zhang. T2vworldbench: A benchmark for evaluating world knowledge in text-to-video generation. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 6474–6485, 2026
2026
-
[49]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022. 13
2022
-
[50]
Depth anything v2.Advances in Neural Information Processing Systems, 37:21875–21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2.Advances in Neural Information Processing Systems, 37:21875–21911, 2024
2024
-
[51]
Rethinking Atrous Convolution for Semantic Image Segmentation
Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartwig Adam. Rethinking atrous convolution for semantic image segmentation.arXiv preprint arXiv:1706.05587, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[52]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 14
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.