Functional Entropy: Predicting Functional Correctness in LLM-Generated Code with Uncertainty Quantification
Pith reviewed 2026-06-29 13:20 UTC · model grok-4.3
The pith
Replacing NLI with LLM-based functional equivalence assessment improves uncertainty quantification for detecting incorrect LLM-generated code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
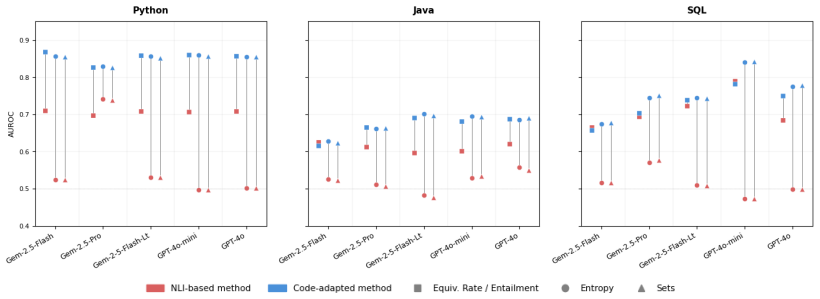
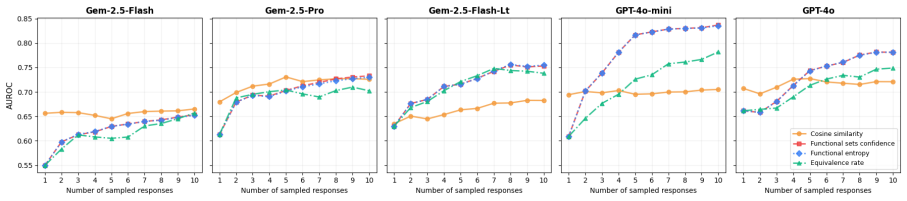
Functional equivalence methods achieve top AUROC in 11 out of 15 model-benchmark combinations and the best calibration across most settings, consistently outperforming both NLI-based counterparts and all other methods evaluated by using an LLM to assess functional equivalence rather than NLI to assess semantic equivalence.
What carries the argument
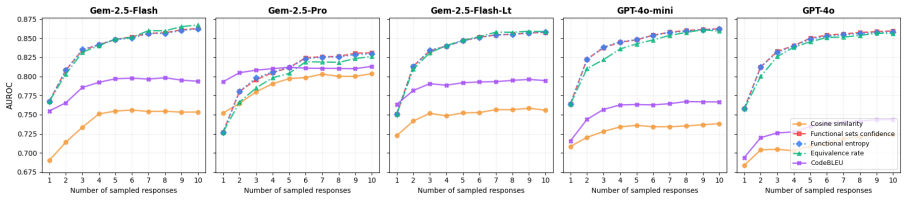
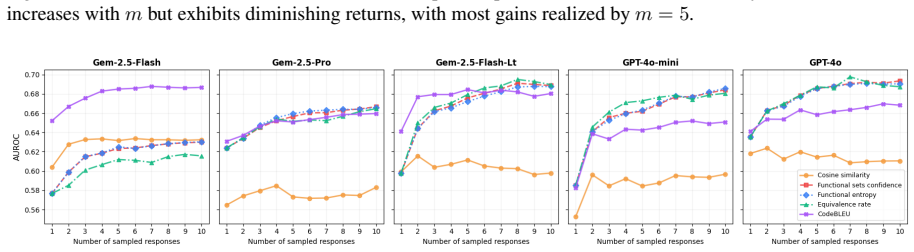
Functional entropy, the code analog of semantic entropy obtained by replacing NLI-based semantic equivalence with LLM-based functional equivalence assessment to quantify uncertainty over code samples.
If this is right
- Token-probability-based UQ methods transfer directly to code generation tasks without modification.
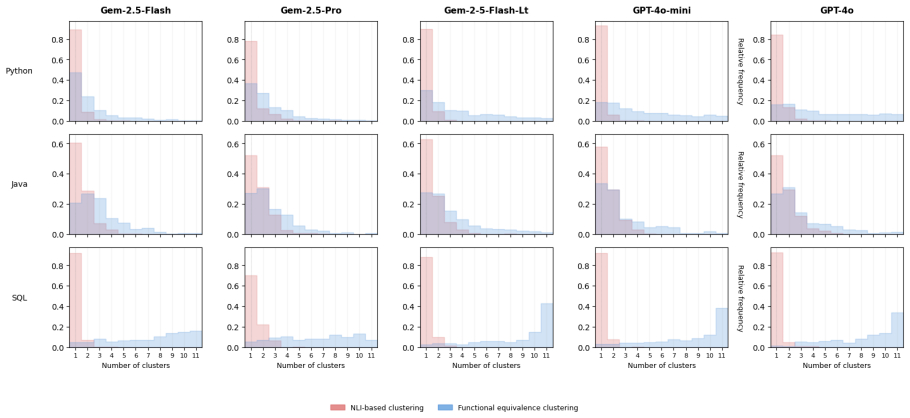
- NLI-based sampling methods fail for code because most responses collapse into a single semantic cluster.
- Functional equivalence methods deliver higher AUROC than NLI or token baselines in the majority of evaluated settings.
- The same methods also produce better-calibrated uncertainty estimates across most model-benchmark pairs.
Where Pith is reading between the lines
- Task-specific equivalence checkers may be required for reliable UQ whenever semantic similarity diverges from functional behavior.
- The approach could be tested on other structured generation tasks whose outputs are verifiable by execution or formal means.
- Using a separate model family for the functional assessor might reduce circularity risks when the generator and assessor share training data.
Load-bearing premise
An LLM-based functional equivalence assessor can reliably distinguish functionally distinct code without introducing systematic errors of its own or depending on the same model family being evaluated.
What would settle it
A test set where the functional equivalence LLM consistently labels distinct code as equivalent (or vice versa) while human or test-case verification shows the opposite would falsify the reliability of the assessor.
Figures
read the original abstract
Large language models have shown impressive capabilities in code generation, yet they often produce functionally incorrect code. Uncertainty quantification (UQ) methods have emerged as a promising approach for detecting hallucinations in natural language generation, but their effectiveness for code generation tasks remains underexplored. We systematically evaluate how UQ techniques transfer to code generation across three programming languages, five LLMs, and over 1,700 problems. We find that some token-probability-based methods generalize effectively without modification, while sampling-based methods relying on natural language inference (NLI) fail because NLI models cannot distinguish functionally different code, causing most responses to collapse into a single semantic cluster. To address this, we introduce functional equivalence methods, a family of code-specific methods that replace NLI-based semantic equivalence with an LLM-based functional equivalence assessment, including functional entropy, a code-specific analog of semantic entropy. Functional equivalence methods achieve top AUROC in 11 out of 15 model-benchmark combinations and the best calibration across most settings, consistently outperforming both NLI-based counterparts and all other methods evaluated.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates UQ methods for detecting functional incorrectness in LLM-generated code across three languages, five LLMs, and >1700 problems. It reports that NLI-based sampling methods fail because NLI cannot distinguish functional differences (causing cluster collapse), and introduces LLM-based functional equivalence methods (including functional entropy as a code analog of semantic entropy). These achieve top AUROC in 11/15 model-benchmark combinations and best calibration in most settings, outperforming NLI-based and other baselines.
Significance. If robust, the work fills a gap in code-specific UQ by adapting semantic entropy ideas to functional equivalence, supported by a broad multi-language, multi-model evaluation. This could improve reliability assessment for code generation. The systematic scope across 1700+ problems is a clear empirical strength.
major comments (1)
- [Abstract and Experimental Setup] Abstract and Experimental Setup: the central claim that functional equivalence methods (replacing NLI with an LLM judge) deliver reliable gains rests on the assessor's labels being independent of the generator's failure modes. No cross-family ablation (different model family for judge vs. generator) or execution-based ground-truth validation of equivalence labels is reported. This is load-bearing, as correlated blind spots (e.g., on off-by-one or type errors) would under-count distinct failures and inflate AUROC.
minor comments (2)
- Add explicit citations and version numbers for all benchmarks and the 1700+ problems to allow reproduction.
- [Methods] Clarify prompting details for the LLM functional equivalence judge (e.g., exact instructions or few-shot examples) in the methods section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The concern about potential correlation between the functional equivalence judge and generator models is valid and directly relevant to the robustness of our claims. We respond point-by-point below and commit to revisions.
read point-by-point responses
-
Referee: [Abstract and Experimental Setup] Abstract and Experimental Setup: the central claim that functional equivalence methods (replacing NLI with an LLM judge) deliver reliable gains rests on the assessor's labels being independent of the generator's failure modes. No cross-family ablation (different model family for judge vs. generator) or execution-based ground-truth validation of equivalence labels is reported. This is load-bearing, as correlated blind spots (e.g., on off-by-one or type errors) would under-count distinct failures and inflate AUROC.
Authors: We acknowledge this is a substantive limitation not addressed in the current manuscript. The experiments rely on LLM-based functional equivalence without reported cross-family ablations or execution-based validation of the labels, leaving open the possibility of correlated blind spots inflating AUROC. We agree this assumption is load-bearing for the central claim. In the revised manuscript we will add a cross-family ablation (e.g., using a distinct model family for the judge) and include execution-based validation on a subset of problems with available test cases, along with discussion of remaining limitations such as test coverage. These additions will appear in the Experimental Setup section and be noted in the abstract. revision: yes
Circularity Check
No circularity; purely empirical evaluation with no derivations or self-referential reductions
full rationale
The paper reports an empirical study comparing UQ methods on code generation tasks across LLMs, languages, and benchmarks. The central result (functional equivalence methods topping AUROC in 11/15 settings) is obtained by direct measurement of AUROC and calibration on held-out problems, not by any equation, parameter fit, or first-principles derivation that reduces to the inputs by construction. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the abstract or described claims. The introduction of functional entropy is presented as an empirical replacement for NLI clustering rather than a mathematical derivation. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multipl-e: A scalable and extensible approach to benchmarking neural code generation, 2022
Multipl-e: A scalable and extensible approach to benchmarking neural code generation.Preprint, arXiv:2208.08227. Jiuhai Chen and Jonas Mueller
- [2]
-
[3]
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal
Selectively answering ambiguous questions.Preprint, arXiv:2305.14613. Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal
-
[4]
Red-ct: A systems design method- ology for using llm-labeled data to train and de- ploy edge classifiers for computational social science. Preprint, arXiv:2408.08217. Cuiyun Gao, Guodong Fan, Chun Yong Chong, Shizhan Chen, Chao Liu, David Lo, Zibin Zheng, and Qing Liao
-
[5]
A systematic literature review of code hallucinations in llms: Characterization, mitigation methods, challenges, and future directions for reli- able ai.arXiv preprint arXiv:2511.00776. Google. [link]. Kaifeng He, Mingwei Liu, Chong Wang, Zike Li, Yanlin Wang, Xin Peng, and Zibin Zheng
-
[6]
AdaDec: A Uncertainty-Guided Lookahead Decoding Framework for LLM-Based Code Generation
Adadec: Uncertainty-guided adaptive decoding for llm-based code generation.arXiv preprint arXiv:2506.08980. Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Deberta: Decoding- enhanced bert with disentangled attention.Preprint, arXiv:2006.03654. Kait Healy, Bharathi Srinivasan, Visakh Madathil, and Jing Wu
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[8]
Internal representations as indicators of hallucinations in agent tool selection.Preprint, arXiv:2601.05214. Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu
-
[9]
A survey on hallucination in large lan- guage models: Principles, taxonomy, challenges, and open questions.Preprint, arXiv:2311.05232. Yuheng Huang, Jiayang Song, Zhijie Wang, Sheng- ming Zhao, Huaming Chen, Felix Juefei-Xu, and Lei Ma
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Live- codebench: Holistic and contamination free evalu- ation of large language models for code.Preprint, arXiv:2403.07974. Nan Jiang, Qi Li, Lin Tan, and Tianyi Zhang
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Collu-bench: A benchmark for predicting lan- guage model hallucinations in code.Preprint, arXiv:2410.09997. Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Ba...
-
[12]
Language Models (Mostly) Know What They Know
Language models (mostly) know what they know.Preprint, arXiv:2207.05221. Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Semantic uncertainty: Linguistic invariances for un- certainty estimation in natural language generation. Preprint, arXiv:2302.09664. Zhen Lin, Shubhendu Trivedi, and Jimeng Sun
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Fang Liu, Yang Liu, Lin Shi, Zhen Yang, Li Zhang, Xi- aoli Lian, Zhongqi Li, and Yuchi Ma
Generating with confidence: Uncertainty quantifica- tion for black-box large language models.Preprint, arXiv:2305.19187. Fang Liu, Yang Liu, Lin Shi, Zhen Yang, Li Zhang, Xi- aoli Lian, Zhongqi Li, and Yuchi Ma
-
[15]
Beyond functional correctness: Exploring hallucinations in llm-generated code.Preprint, arXiv:2404.00971. Andrey Malinin and Mark Gales
-
[16]
Uncertainty estimation in autoregressive structured prediction. Preprint, arXiv:2002.07650. Potsawee Manakul, Adian Liusie, and Mark J. F. Gales
-
[17]
Selfcheckgpt: Zero-resource black-box hal- lucination detection for generative large language models.Preprint, arXiv:2303.08896. OpenAI
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Semantic den- sity: Uncertainty quantification for large language models through confidence measurement in semantic space.Preprint, arXiv:2405.13845. Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma
-
[19]
CodeBLEU: a Method for Automatic Evaluation of Code Synthesis
Codebleu: a method for automatic evaluation of code synthesis.Preprint, arXiv:2009.10297. Daniel Scalena, Leonidas Zotos, Elisabetta Fersini, Malvina Nissim, and Ahmet Üstün
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[20]
EAGer: Entropy-Aware GEneRation for Adaptive Inference-Time Scaling
Eager: Entropy-aware generation for adaptive inference- time scaling.Preprint, arXiv:2510.11170. Arindam Sharma and Cristina David
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Ola Shorinwa, Zhiting Mei, Justin Lidard, Allen Z
Assessing correctness in llm-based code generation via uncer- tainty estimation.arXiv preprint arXiv:2502.11620. Ola Shorinwa, Zhiting Mei, Justin Lidard, Allen Z. Ren, and Anirudha Majumdar
-
[22]
A survey on un- certainty quantification of large language models: Taxonomy, open research challenges, and future di- rections.Preprint, arXiv:2412.05563. Claudio Spiess, David Gros, Kunal Suresh Pai, Michael Pradel, Md Rafiqul Islam Rabin, Amin Alipour, Sus- mit Jha, Prem Devanbu, and Toufique Ahmed
-
[23]
Calibration and correctness of language models for code.Preprint, arXiv:2402.02047. Kla Tantithamthavorn, Hong Yi Lin, Patanamon Thongtanunam, Wachiraphan Charoenwet, Minwoo Jeong, and Ming Wu
-
[24]
Hallujudge: A reference-free hallucination detection for context misalignment in code review automation.Preprint, arXiv:2601.19072. BIRD Team
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
https://github.com/bird- bench/livesqlbench
Livesqlbench: A dynamic and contamination-free benchmark for evaluating llms on real-world text-to-sql tasks. https://github.com/bird- bench/livesqlbench. Accessed: 2025-05-22. Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D. Manning
2025
-
[26]
Just ask for cali- bration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback.Preprint, arXiv:2305.14975. Yuchen Tian, Weixiang Yan, Qian Yang, Xuandong Zhao, Qian Chen, Wen Wang, Ziyang Luo, Lei Ma, and Dawn Song
-
[27]
Helena Vasconcelos, Gagan Bansal, Adam Fourney, Q Vera Liao, and Jennifer Wortman Vaughan
Codehalu: Investigating code hallucinations in llms via execution-based verifica- tion.Preprint, arXiv:2405.00253. Helena Vasconcelos, Gagan Bansal, Adam Fourney, Q Vera Liao, and Jennifer Wortman Vaughan
-
[28]
Generation probabilities are not enough: Uncertainty highlighting in ai code completions.ACM Transac- tions on Computer-Human Interaction, 32(1):1–30. Roman Vashurin, Ekaterina Fadeeva, Artem Vazhentsev, Lyudmila Rvanova, Daniil Vasilev, Akim Tsvigun, Sergey Petrakov, Rui Xing, Abdelrahman Sadallah, Kirill Grishchenkov, Alexander Panchenko, Timothy Baldwi...
-
[29]
Efficient Hallucination Detection for LLMs Using Uncertainty-Aware Attention Heads
Uncertainty-aware attention heads: Efficient unsu- pervised uncertainty quantification for llms.arXiv preprint arXiv:2505.20045. Bo Yang, Yinfen Xia, Weisong Sun, and Yang Liu
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Yuqi Zhu, Ge Li, Xue Jiang, Jia Li, Hong Mei, Zhi Jin, and Yihong Dong
Hallucination detection for llm-based text-to-sql gen- eration via two-stage metamorphic testing.Preprint, arXiv:2512.22250. Yuqi Zhu, Ge Li, Xue Jiang, Jia Li, Hong Mei, Zhi Jin, and Yihong Dong
-
[31]
Uncertainty-guided chain- of-thought for code generation with llms.arXiv preprint arXiv:2503.15341. A Calibration We report two calibration metrics for all methods evaluated in the main text: Expected Calibration Error (ECE) and Brier Score. ECE measures the average gap between predicted confidence and ob- served accuracy across binned confidence interval...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.