ReasonBreak: Probing Vulnerabilities in Reasoning-Enabled Vision-Language-Action Models for Autonomous Driving
Pith reviewed 2026-06-29 11:07 UTC · model grok-4.3
The pith
Reasoning-enabled VLA models for autonomous driving can be fooled by realistic text perturbations into wrong reasoning and unsafe trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
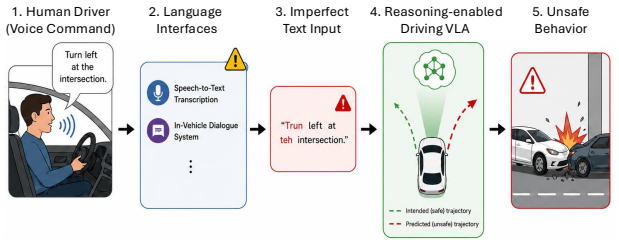
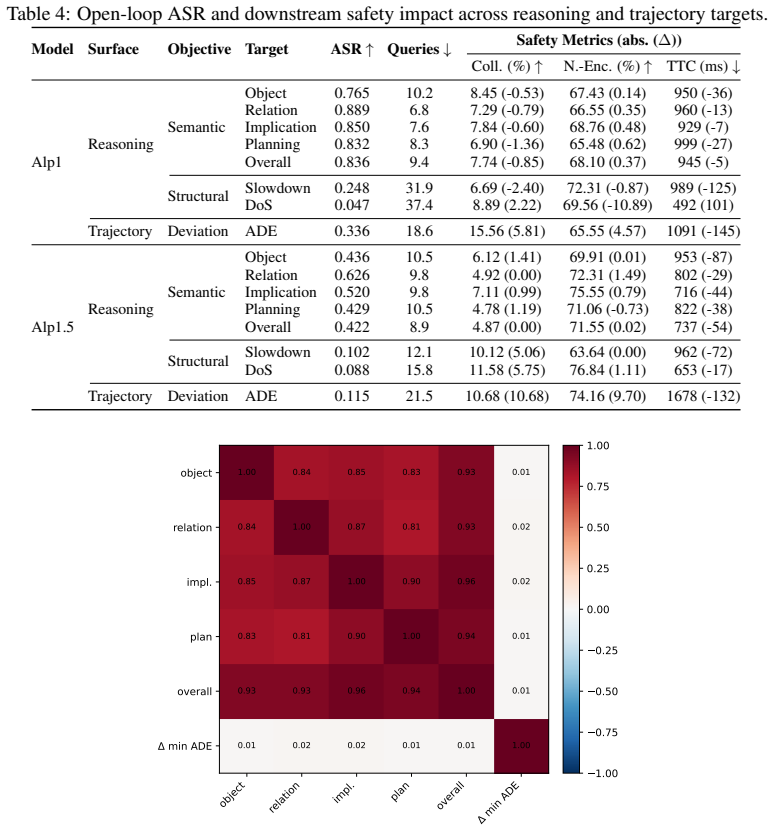
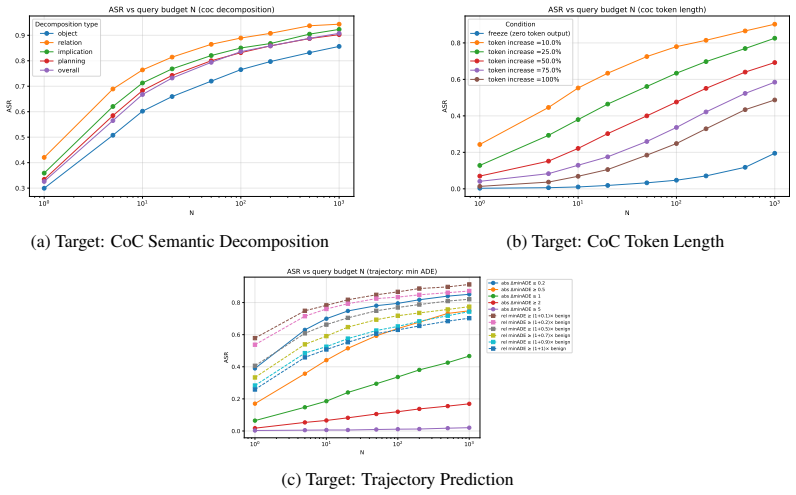
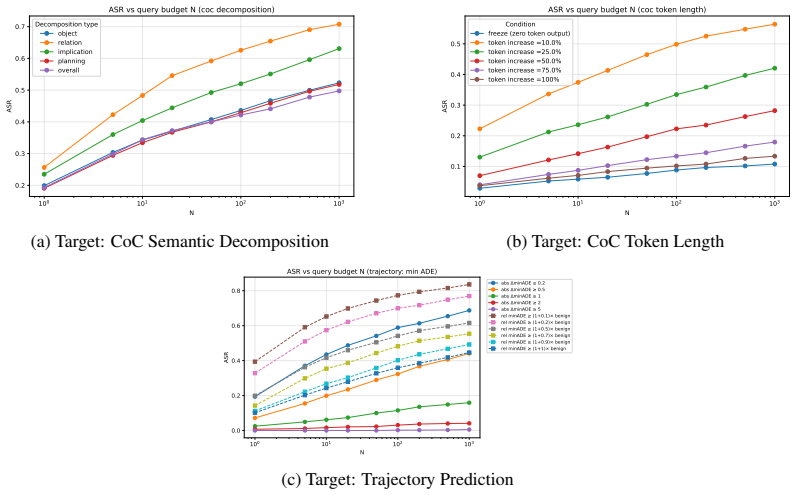
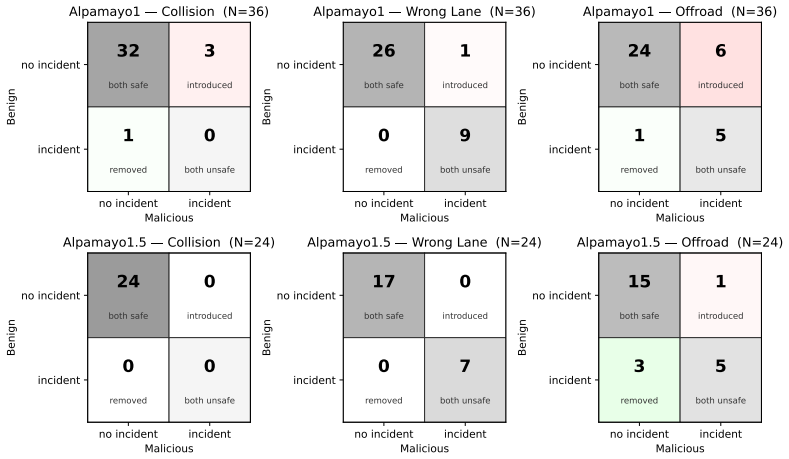
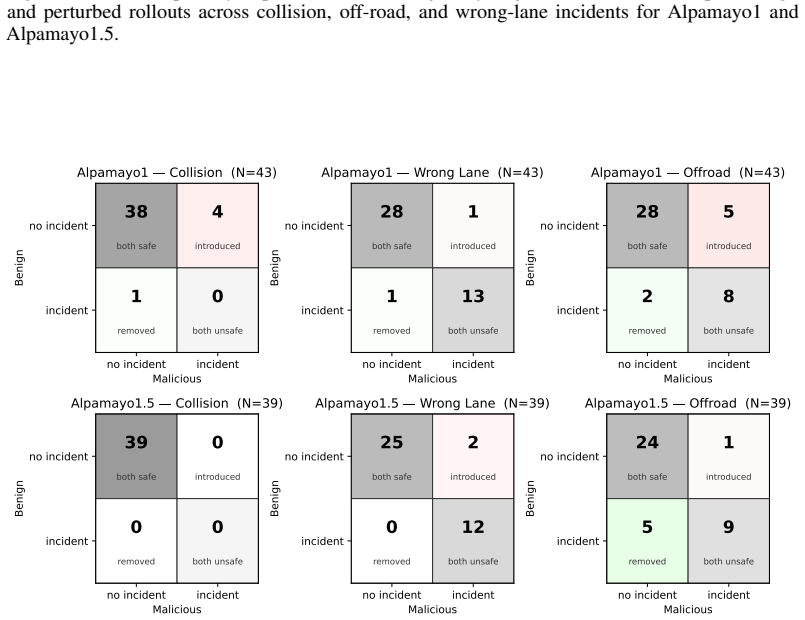
The paper claims that realistic textual input corruptions produce attack success rates up to 89 percent on reasoning and 72 percent on trajectory manipulation in closed-loop simulation when applied to reasoning-enabled VLA models such as NVIDIA's Alpamayo, directly increasing collision rates and degrading safety metrics.
What carries the argument
A reasoning-aware evaluation framework that measures both semantic and structural correctness of reasoning together with safety-centric driving metrics, applied under black-box conditions to expose reasoning-trajectory coupling.
If this is right
- These models require stronger defenses before they can be considered safe for driving tasks.
- The new benchmark enables repeatable testing of how attacks on reasoning affect trajectory outputs.
- Closed-loop results show that reasoning failures translate into measurable increases in collisions and safety violations.
- Black-box attacks suffice to expose the vulnerabilities without model internals.
Where Pith is reading between the lines
- Similar coupling between language reasoning and control outputs may create comparable risks in other embodied AI domains that rely on multimodal inputs.
- Designs that add explicit verification steps between reasoning and action generation could reduce the impact of input noise.
- Extending the evaluation to sensor-level noise rather than only text would test whether the observed vulnerabilities persist in fuller system settings.
Load-bearing premise
The textual input corruptions tested are realistic and representative of perturbations that could occur in deployed autonomous driving systems.
What would settle it
An experiment in which the same models receive the tested input corruptions yet produce unchanged reasoning outputs and unchanged safe trajectories in the closed-loop simulator.
Figures


read the original abstract
Vision-Language-Action (VLA) models with integrated reasoning have been proposed for end-to-end autonomous driving, assuming a tight coupling between reasoning and trajectory generation. However, the robustness of such systems under realistic input perturbations remains largely unexplored. We show that these models are highly vulnerable to realistic input perturbations, achieving up to 89% attack success rate (ASR) on reasoning and up to 72% on trajectory manipulation in closed-loop simulation, leading to increased collision rates and degraded safety metrics. Using NVIDIA's recent Alpamayo models as representative industry-developed VLAs, we conduct the first systematic black-box study of reasoning-enabled VLA models under realistic textual input corruptions, evaluating their impact on reasoning and driving behavior. We introduce a reasoning-aware evaluation framework capturing both semantic and structural aspects of reasoning, along with safety-centric measures. We also introduce a benchmark for evaluating attacks and defenses on reasoning-trajectory interactions in autonomous driving. Our results highlight the need for rigorous evaluation and improved defenses to ensure the safety of reasoning-enabled VLA systems in autonomous driving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReasonBreak, a black-box attack study on reasoning-enabled Vision-Language-Action (VLA) models for autonomous driving. Using NVIDIA Alpamayo models as representatives, it applies textual input corruptions and reports up to 89% attack success rate (ASR) on reasoning outputs and 72% on trajectory manipulation in closed-loop simulation, with consequent increases in collision rates and degradation of safety metrics. The work also presents a reasoning-aware evaluation framework that captures semantic and structural aspects of reasoning, plus a new benchmark for evaluating attacks and defenses on reasoning-trajectory interactions.
Significance. If the central claims hold after addressing realism concerns, the results would highlight a previously underexplored attack surface in emerging end-to-end VLA driving systems and motivate improved defenses. The introduction of a reasoning-aware evaluation framework and an associated benchmark constitutes a concrete contribution that could be reused by the community for future robustness studies. The closed-loop safety-metric evaluation is a positive design choice relative to open-loop metrics alone.
major comments (2)
- [§3 (Attack Methodology)] §3 (Attack Methodology): The manuscript asserts that the chosen textual corruptions are 'realistic' and representative of perturbations that could reach the reasoning module in deployed VLA pipelines, yet provides no quantitative mapping from the corruption types to measured real-world error distributions (e.g., OCR noise statistics, V2X packet corruption rates, or perception-module output errors). Without this mapping, the reported 89% ASR and 72% trajectory-manipulation rates cannot be interpreted as evidence of practical risk.
- [§5 (Experimental Evaluation)] §5 (Experimental Evaluation): The study evaluates only the Alpamayo family and offers no comparative results against other released or publicly documented reasoning-enabled VLA systems. This omission weakens the claim that Alpamayo models are representative of industry-developed VLAs and leaves open whether the observed vulnerabilities are model-specific or general.
minor comments (1)
- [Abstract] The abstract states headline ASR figures without referencing the underlying dataset sizes, number of closed-loop trials, or statistical significance tests; adding these details would improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating planned revisions where appropriate to strengthen the manuscript's claims on attack realism and model selection.
read point-by-point responses
-
Referee: §3 (Attack Methodology): The manuscript asserts that the chosen textual corruptions are 'realistic' and representative of perturbations that could reach the reasoning module in deployed VLA pipelines, yet provides no quantitative mapping from the corruption types to measured real-world error distributions (e.g., OCR noise statistics, V2X packet corruption rates, or perception-module output errors). Without this mapping, the reported 89% ASR and 72% trajectory-manipulation rates cannot be interpreted as evidence of practical risk.
Authors: We acknowledge the absence of a direct quantitative mapping to empirical real-world error distributions. The corruptions were chosen to reflect plausible textual perturbations arising in VLA pipelines (e.g., from perception OCR errors or V2X packet loss), informed by prior robustness literature in autonomous driving. In revision we will expand the methodology section with additional references to real-world sensor and communication error studies and insert a clarifying statement that the reported ASRs illustrate vulnerability under these perturbations rather than calibrated practical risk estimates. This constitutes a partial revision. revision: partial
-
Referee: §5 (Experimental Evaluation): The study evaluates only the Alpamayo family and offers no comparative results against other released or publicly documented reasoning-enabled VLA systems. This omission weakens the claim that Alpamayo models are representative of industry-developed VLAs and leaves open whether the observed vulnerabilities are model-specific or general.
Authors: Alpamayo constitutes one of the few publicly released and documented reasoning-enabled VLA systems from industry. Other candidate systems remain proprietary and inaccessible for independent black-box evaluation. We will revise the experimental section to explicitly justify the selection of Alpamayo on grounds of public availability and architectural relevance, and add a discussion of potential generalizability based on the shared reasoning-trajectory coupling present in this class of models. revision: partial
Circularity Check
Empirical attack evaluation with no derivation chain
full rationale
The paper is a black-box empirical study of input perturbations on Alpamayo VLA models, reporting attack success rates and safety metric changes from closed-loop simulations. No equations, fitted parameters, predictions, or derivation steps appear in the abstract or described content. The central claims rest on experimental measurements rather than any claimed first-principles reduction, self-citation chain, or ansatz, so no circularity of the enumerated kinds is present.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Large language models robustness against perturbation: S
Saeed S Alahmari, Lawrence Hall, Peter R Mouton, and Dmitry Goldgof. Large language models robustness against perturbation: S. alahmari et al.Scientific Reports, 2025
2025
-
[2]
Improving autonomous vehicle controls and quality using natural language processing-based input recognition model.Sustainability, 15(7):5749, 2023
Mohd Anjum and Sana Shahab. Improving autonomous vehicle controls and quality using natural language processing-based input recognition model.Sustainability, 15(7):5749, 2023
2023
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
End to End Learning for Self-Driving Cars
Mariusz Bojarski, Davide Del Testa, Daniel Dworakowski, Bernhard Firner, Beat Flepp, Prasoon Goyal, Lawrence D Jackel, Mathew Monfort, Urs Muller, Jiakai Zhang, et al. End to end learning for self-driving cars.arXiv preprint arXiv:1604.07316, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Comparison of text preprocessing methods.Natural language engineering, 29(3):509–553, 2023
Christine P Chai. Comparison of text preprocessing methods.Natural language engineering, 29(3):509–553, 2023
2023
-
[6]
Decictor: Towards evaluating the robustness of decision-making in autonomous driving systems
Mingfei Cheng, Yuan Zhou, Xiaofei Xie, Junjie Wang, Guozhu Meng, and Kairui Yang. Decictor: Towards evaluating the robustness of decision-making in autonomous driving systems. arXiv preprint arXiv:2402.18393, 2024
-
[7]
Transfuser: Imitation with transformer-based sensor fusion for autonomous driving.IEEE transactions on pattern analysis and machine intelligence, 45(11):12878–12895, 2022
Kashyap Chitta, Aditya Prakash, Bernhard Jaeger, Zehao Yu, Katrin Renz, and Andreas Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving.IEEE transactions on pattern analysis and machine intelligence, 45(11):12878–12895, 2022
2022
-
[8]
End-to-end driving via conditional imitation learning
Felipe Codevilla, Matthias Müller, Antonio López, Vladlen Koltun, and Alexey Dosovitskiy. End-to-end driving via conditional imitation learning. In2018 IEEE international conference on robotics and automation (ICRA), pages 4693–4700. IEEE, 2018
2018
-
[9]
Exploring the limitations of behavior cloning for autonomous driving
Felipe Codevilla, Eder Santana, Antonio M López, and Adrien Gaidon. Exploring the limitations of behavior cloning for autonomous driving. InProceedings of the IEEE/CVF international conference on computer vision, pages 9329–9338, 2019
2019
-
[10]
Tong Cui, Jinghui Xiao, Liangyou Li, Xin Jiang, and Qun Liu. An approach to improve robustness of nlp systems against asr errors.arXiv preprint arXiv:2103.13610, 2021
-
[11]
Yu Cui and Cong Zuo. Practical reasoning interruption attacks on reasoning large language models.arXiv preprint arXiv:2505.06643, 2025
-
[12]
Wenliang Dai, Samuel Cahyawijaya, Tiezheng Yu, Elham J Barezi, Peng Xu, Cheuk Tung Shadow Yiu, Rita Frieske, Holy Lovenia, Genta Indra Winata, Qifeng Chen, et al. Ci- avsr: A cantonese audio-visual speech dataset for in-car command recognition.arXiv preprint arXiv:2201.03804, 2022
-
[13]
Accents in speech recognition through the lens of a world englishes evaluation set.Research in Language, 21(3):225–244, 2023
Miguel Del Río, Corey Miller, Ján Profant, Jennifer Drexler-Fox, Quinn Mcnamara, Nishchal Bhandari, Natalie Delworth, Ilya Pirkin, Migüel Jetté, Shipra Chandra, et al. Accents in speech recognition through the lens of a world englishes evaluation set.Research in Language, 21(3):225–244, 2023
2023
-
[14]
GraspVLA: a Grasping Foundation Model Pre-trained on Billion-scale Synthetic Action Data
Shengliang Deng, Mi Yan, Songlin Wei, Haixin Ma, Yuxin Yang, Jiayi Chen, Zhiqi Zhang, Taoyu Yang, Xuheng Zhang, Wenhao Zhang, et al. Graspvla: a grasping foundation model pre-trained on billion-scale synthetic action data.arXiv preprint arXiv:2505.03233, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Carla: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. Carla: An open urban driving simulator. InConference on robot learning, pages 1–16. PMLR, 2017
2017
-
[16]
Bootstrap methods: another look at the jackknife
Bradley Efron. Bootstrap methods: another look at the jackknife. InBreakthroughs in statistics: Methodology and distribution, pages 569–593. Springer, 1992
1992
-
[17]
Reasoning robustness of llms to adversarial typographical errors
Esther Gan, Yiran Zhao, Liying Cheng, Mao Yancan, Anirudh Goyal, Kenji Kawaguchi, Min- Yen Kan, and Michael Shieh. Reasoning robustness of llms to adversarial typographical errors. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 10449–10459, 2024. 10
2024
-
[18]
ICR-Drive: Instruction Counterfactual Robustness for End-to-End Language-Driven Autonomous Driving
Kaiser Hamid, Can Cui, and Nade Liang. Icr-drive: Instruction counterfactual robustness for end-to-end language-driven autonomous driving.arXiv preprint arXiv:2604.05378, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
TRAP: Hijacking VLA CoT-Reasoning via Adversarial Patches
Zhengxian Huang, Wenjun Zhu, Haoxuan Qiu, Xiaoyu Ji, and Wenyuan Xu. Trap: Hijacking vla cot-reasoning via adversarial patches.arXiv preprint arXiv:2603.23117, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Best-of-n jailbreaking
John Hughes, Sara Price, Aengus Lynch, Rylan Schaeffer, Fazl Barez, Arushi Somani, Sanmi Koyejo, Henry Sleight, Erik Jones, Ethan Perez, et al. Best-of-n jailbreaking. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[21]
Adversarial attacks on robotic vision language action models.arXiv preprint arXiv:2506.03350, 2025
Eliot Krzysztof Jones, Alexander Robey, Andy Zou, Zachary Ravichandran, George J Pappas, Hamed Hassani, Matt Fredrikson, and J Zico Kolter. Adversarial attacks on robotic vision language action models.arXiv preprint arXiv:2506.03350, 2025
-
[22]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Overthink: Slowdown attacks on reasoning llms.arXiv preprint arXiv:2502.02542, 2025
Abhinav Kumar, Jaechul Roh, Ali Naseh, Marzena Karpinska, Mohit Iyyer, Amir Houmansadr, and Eugene Bagdasarian. Overthink: Slowdown attacks on reasoning llms.arXiv preprint arXiv:2502.02542, 2025
-
[24]
MolmoAct: Action Reasoning Models that can Reason in Space
Jason Lee, Jiafei Duan, Haoquan Fang, Yuquan Deng, Shuo Liu, Boyang Li, Bohan Fang, Jieyu Zhang, Yi Ru Wang, Sangho Lee, et al. Molmoact: Action reasoning models that can reason in space.arXiv preprint arXiv:2508.07917, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
HybridVLA: Collaborative Diffusion and Autoregression in a Unified Vision-Language-Action Model
Jiaming Liu, Hao Chen, Pengju An, Zhuoyang Liu, Renrui Zhang, Chenyang Gu, Xiaoqi Li, Ziyu Guo, Sixiang Chen, Mengzhen Liu, et al. Hybridvla: Collaborative diffusion and autoregression in a unified vision-language-action model.arXiv preprint arXiv:2503.10631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Xiaogeng Liu, Xinyan Wang, Yechao Zhang, Sanjay Kariyappa, Chong Xiang, Muhao Chen, G Edward Suh, and Chaowei Xiao. Reasoningbomb: A stealthy denial-of-service attack by inducing pathologically long reasoning in large reasoning models.arXiv preprint arXiv:2602.00154, 2026
-
[27]
Evaluating Robustness of Large Language Models Against Multilingual Typographical Errors
Yihong Liu, Raoyuan Zhao, Lena Altinger, Hinrich Schütze, and Michael A Hedderich. Eval- uating robustness of large language models against multilingual typographical errors.arXiv preprint arXiv:2510.09536, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Hui Lu, Yi Yu, Yiming Yang, Chenyu Yi, Qixin Zhang, Bingquan Shen, Alex C Kot, and Xudong Jiang. When robots obey the patch: Universal transferable patch attacks on vision- language-action models.arXiv preprint arXiv:2511.21192, 2025
-
[29]
Phantom menace: Exploring and enhancing the robustness of vla models against physical sensor attacks
Xuancun Lu, Jiaxiang Chen, Shilin Xiao, Zizhi Jin, Zhangrui Chen, Hanwen Yu, Bohan Qian, Ruochen Zhou, Xiaoyu Ji, and Wenyuan Xu. Phantom menace: Exploring and enhancing the robustness of vla models against physical sensor attacks. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 35689–35697, 2026
2026
-
[30]
Physical ai autonomous vehicles dataset
NVIDIA. Physical ai autonomous vehicles dataset. https://huggingface.co/datasets/ nvidia/PhysicalAI-Autonomous-Vehicles, 2025. Accessed: April 2026
2025
-
[31]
Physical ai autonomous vehicles nurec dataset
NVIDIA. Physical ai autonomous vehicles nurec dataset. https://huggingface.co/ datasets/nvidia/PhysicalAI-Autonomous-Vehicles-NuRec , 2025. Accessed: April 2026
2025
-
[32]
Nvidia announces alpamayo family of open-source ai models and tools to accelerate safe, reasoning-based autonomous vehicle development
NVIDIA. Nvidia announces alpamayo family of open-source ai models and tools to accelerate safe, reasoning-based autonomous vehicle development. https://nvidianews.nvidia. com/news/alpamayo-autonomous-vehicle-development, 2026. Accessed: April 2026
2026
-
[33]
Alpasim: A modular, lightweight, and data-driven research simulator for autonomous driving, October 2025
NVIDIA, Yulong Cao, Riccardo de Lutio, Sanja Fidler, Guillermo Garcia Cobo, Zan Gojcic, Maximilian Igl, Boris Ivanovic, Peter Karkus, Janick Martinez Esturo, Marco Pavone, Aaron Smith, Ellie Tanimura, Michal Tyszkiewicz, Michael Watson, Qi Wu, and Le Zhang. Alpasim: A modular, lightweight, and data-driven research simulator for autonomous driving, October...
2025
-
[34]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
A reduction of imitation learning and structured prediction to no-regret online learning
Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth interna- tional conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Proceedings, 2011
2011
-
[36]
Luke Rowe, Rodrigue de Schaetzen, Roger Girgis, Christopher Pal, and Liam Paull. Poutine: Vision-language-trajectory pre-training and reinforcement learning post-training enable robust end-to-end autonomous driving.arXiv preprint arXiv:2506.11234, 2025
-
[37]
Muhammad A Shah, David Solans Noguero, Mikko A Heikkila, Bhiksha Raj, and Nicolas Kourtellis. Speech robust bench: A robustness benchmark for speech recognition.arXiv preprint arXiv:2403.07937, 2024
-
[38]
Excessive reasoning attack on reasoning llms.arXiv preprint arXiv:2506.14374, 2025
Wai Man Si, Mingjie Li, Michael Backes, and Yang Zhang. Excessive reasoning attack on reasoning llms.arXiv preprint arXiv:2506.14374, 2025
-
[39]
Speech recognition error patterns for steady-state noise and interrupted speech.The Journal of the Acoustical Society of America, 142(3):EL306–EL312, 2017
Kimberly G Smith and Daniel Fogerty. Speech recognition error patterns for steady-state noise and interrupted speech.The Journal of the Acoustical Society of America, 142(3):EL306–EL312, 2017
2017
-
[40]
Challenges and feasibility of automatic speech recognition for modeling student collaborative discourse in classrooms.International Educa- tional Data Mining Society, 2022
Rosy Southwell, Samuel Pugh, M Perkoff, Charis Clevenger, Jeffrey Bush, Rachel Lieber, Wayne Ward, Peter Foltz, and Sidney D’Mello. Challenges and feasibility of automatic speech recognition for modeling student collaborative discourse in classrooms.International Educa- tional Data Mining Society, 2022
2022
-
[41]
Lu Wang, Tianyuan Zhang, Yang Qu, Siyuan Liang, Yuwei Chen, Aishan Liu, Xianglong Liu, and Dacheng Tao. Black-box adversarial attack on vision language models for autonomous driving.arXiv preprint arXiv:2501.13563, 2025
-
[42]
Exploring the adversarial vulnerabilities of vision- language-action models in robotics
Taowen Wang, Cheng Han, James Liang, Wenhao Yang, Dongfang Liu, Luna Xinyu Zhang, Qifan Wang, Jiebo Luo, and Ruixiang Tang. Exploring the adversarial vulnerabilities of vision- language-action models in robotics. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6948–6958, 2025
2025
-
[43]
Xin Wang, Jie Li, Zejia Weng, Yixu Wang, Yifeng Gao, Tianyu Pang, Chao Du, Yan Teng, Yingchun Wang, Zuxuan Wu, et al. Freezevla: Action-freezing attacks against vision-language- action models.arXiv preprint arXiv:2509.19870, 2025
-
[44]
Yan Wang, Wenjie Luo, Junjie Bai, Yulong Cao, Tong Che, Ke Chen, Yuxiao Chen, Jenna Dia- mond, Yifan Ding, Wenhao Ding, et al. Alpamayo-r1: Bridging reasoning and action prediction for generalizable autonomous driving in the long tail.arXiv preprint arXiv:2511.00088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Yiru Wang, Zichong Gu, Yu Gao, Anqing Jiang, Zhigang Sun, Shuo Wang, Yuwen Heng, and Hao Sun. Hist-vla: A hierarchical spatio-temporal vision-language-action model for end-to-end autonomous driving.arXiv preprint arXiv:2602.13329, 2026
-
[46]
Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation.IEEE Robotics and Automation Letters, 2025
Junjie Wen, Yichen Zhu, Jinming Li, Minjie Zhu, Zhibin Tang, Kun Wu, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, et al. Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation.IEEE Robotics and Automation Letters, 2025
2025
-
[47]
Conversational in-vehicle dialog systems: The past, present, and future.IEEE Signal Processing Magazine, 33(6):49–60, 2016
Fuliang Weng, Pongtep Angkititrakul, Elizabeth E Shriberg, Larry Heck, Stanley Peters, and John HL Hansen. Conversational in-vehicle dialog systems: The past, present, and future.IEEE Signal Processing Magazine, 33(6):49–60, 2016
2016
-
[48]
SABER: A Stealthy Agentic Black-Box Attack Framework for Vision-Language-Action Models
Xiyang Wu, Guangyao Shi, Qingzi Wang, Zongxia Li, Amrit Singh Bedi, and Dinesh Manocha. Saber: A stealthy agentic black-box attack framework for vision-language-action models.arXiv preprint arXiv:2603.24935, 2026. 12
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
Haochuan Xu, Yun Sing Koh, Shuhuai Huang, Zirun Zhou, Di Wang, Jun Sakuma, and Jingfeng Zhang. Model-agnostic adversarial attack and defense for vision-language-action models.arXiv preprint arXiv:2510.13237, 2025
-
[50]
Yuping Yan, Yuhan Xie, Yixin Zhang, Lingjuan Lyu, Handing Wang, and Yaochu Jin. When alignment fails: Multimodal adversarial attacks on vision-language-action models.arXiv preprint arXiv:2511.16203, 2025
-
[51]
Shuai Yang, Hao Li, Bin Wang, Yilun Chen, Yang Tian, Tai Wang, Hanqing Wang, Feng Zhao, Yiyi Liao, and Jiangmiao Pang. Instructvla: Vision-language-action instruction tuning from understanding to manipulation.arXiv preprint arXiv:2507.17520, 2025
-
[52]
Naifu Zhang, Wei Tao, Xi Xiao, Qianpu Sun, Yuxin Zheng, Wentao Mo, Peiqiang Wang, and Nan Zhang. Attention-guided patch-wise sparse adversarial attacks on vision-language-action models.arXiv preprint arXiv:2511.21663, 2025
-
[53]
Visual Adversarial Attack on Vision-Language Models for Autonomous Driving
Tianyuan Zhang, Lu Wang, Xinwei Zhang, Yitong Zhang, Boyi Jia, Siyuan Liang, Shengshan Hu, Qiang Fu, Aishan Liu, and Xianglong Liu. Visual adversarial attack on vision-language models for autonomous driving.arXiv preprint arXiv:2411.18275, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
X. Zhou, X. Han, F. Yang, Y . Ma, V . Tresp, and A. Knoll. Opendrivevla: Towards end-to-end autonomous driving with large vision language action model. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 13782–13790, 2026
2026
-
[55]
Xueyang Zhou, Guiyao Tie, Guowen Zhang, Hechang Wang, Pan Zhou, and Lichao Sun. Badvla: Towards backdoor attacks on vision-language-action models via objective-decoupled optimization.arXiv preprint arXiv:2505.16640, 2025
-
[56]
Zewei Zhou, Tianhui Cai, Seth Z Zhao, Yun Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma. Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning.arXiv preprint arXiv:2506.13757, 2025. 13 Table 4: Open-loop ASR and downstream safety impact across reasoning and trajectory targets. Model ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.