PhoneWorld: Scaling Phone-Use Agent Environments
Pith reviewed 2026-06-29 07:39 UTC · model grok-4.3
The pith
PhoneWorld turns real GUI trajectories into controllable phone-use environments, tasks, and verifiers at scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
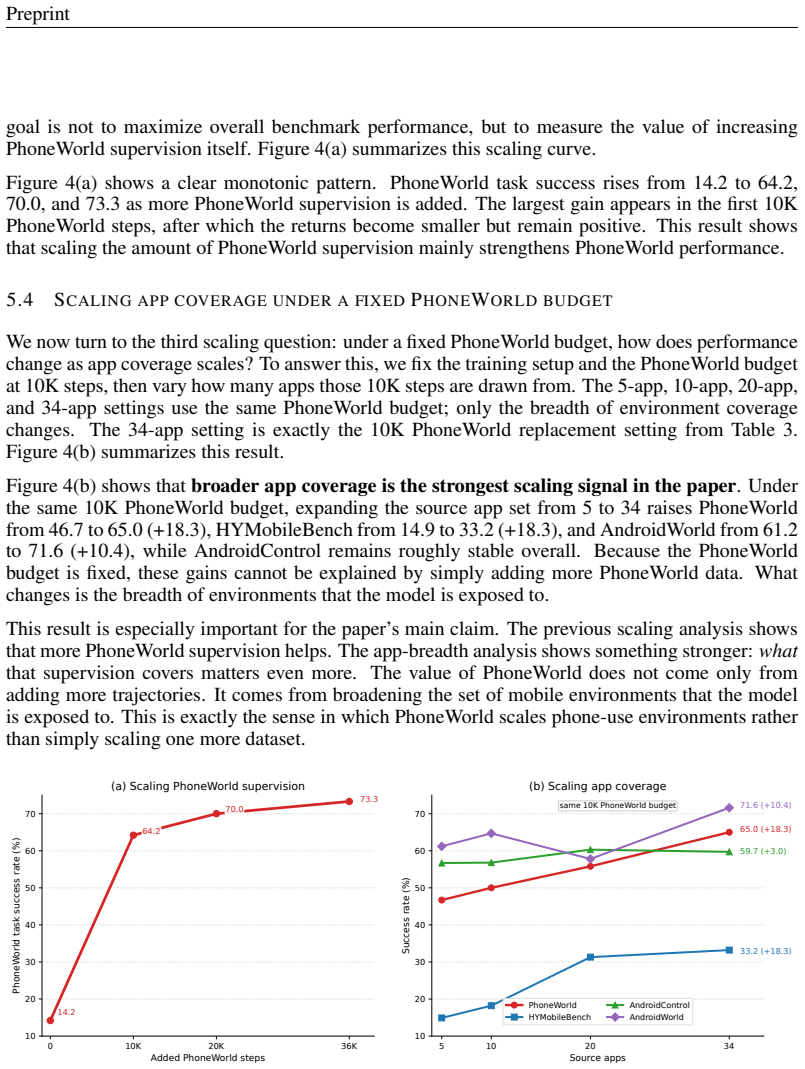
PhoneWorld recovers which screens matter, how they connect, which interactions change state, and which goals admit automatic verification from real trajectories. From these signals it builds runnable mock Android apps backed by read-only content and mutable state, then derives executable tasks, rule-based verifiers, and training rollouts from the same environments. Under a fixed training budget, replacing 10K steps from an auxiliary AndroidWorld corpus with broad PhoneWorld supervision improves HYMobileBench by 17.7 points, AndroidControl by 6.0 points, AndroidWorld by 14.7 points, and PhoneWorld by 52.5 points. Increasing the amount of PhoneWorld supervision further improves PhoneWorld perf
What carries the argument
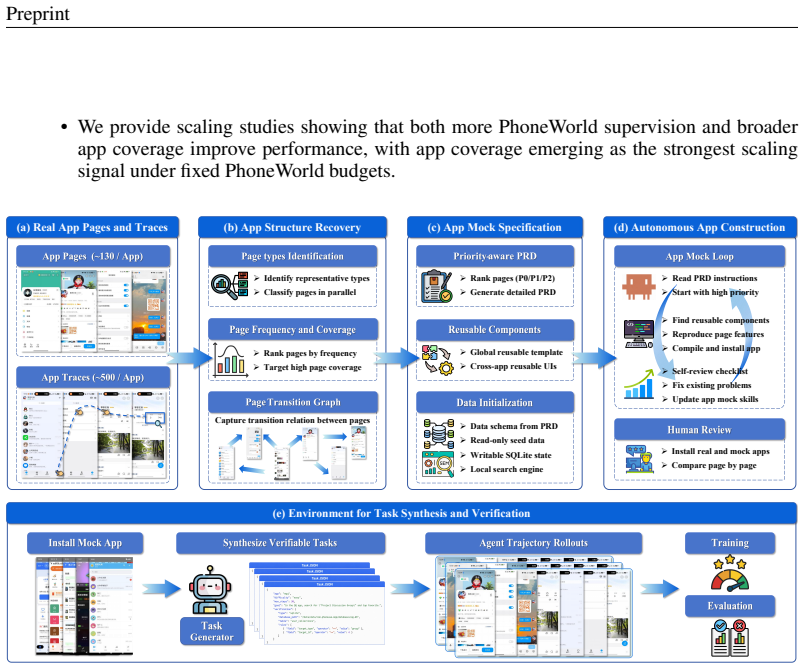
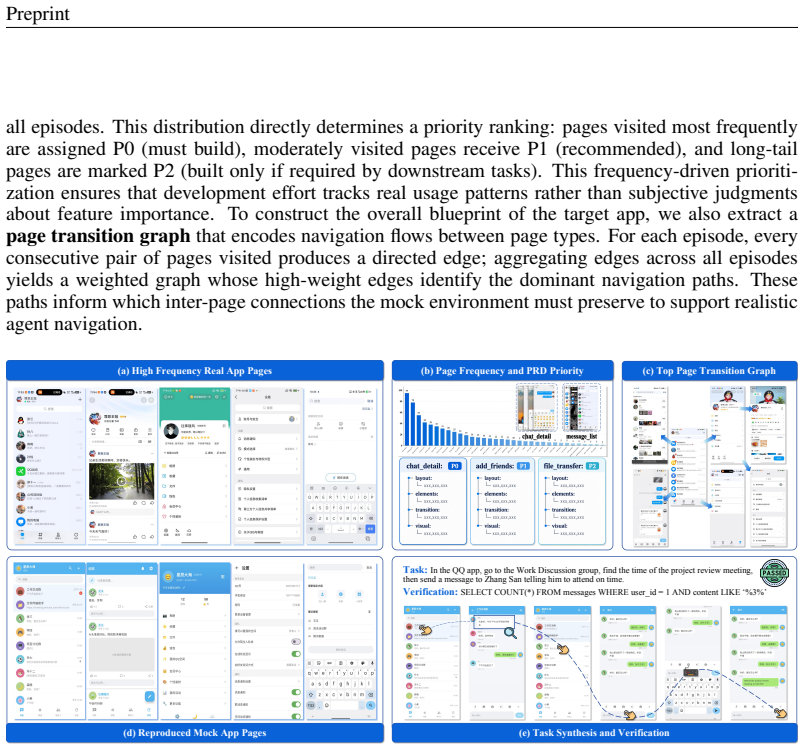
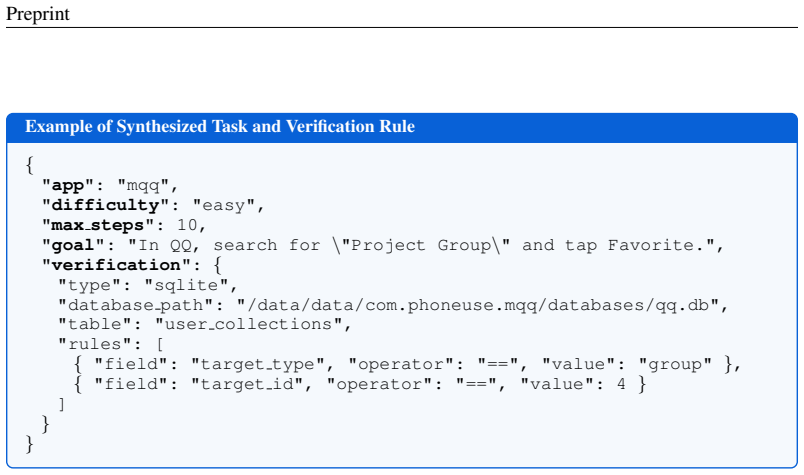
The PhoneWorld pipeline that extracts screens, connections, state-changing interactions, and verifiable goals from trajectories to generate mock apps and automatic verifiers.
If this is right
- Replacing auxiliary AndroidWorld data with PhoneWorld supervision raises scores on all four evaluation benchmarks simultaneously.
- Increasing the volume of PhoneWorld supervision produces strong gains on PhoneWorld itself.
- Under a fixed PhoneWorld budget, covering more apps yields larger performance improvements than adding steps within fewer apps.
- The same recovery process supplies both training rollouts and automatic verifiers for the generated environments.
Where Pith is reading between the lines
- The recovery approach could be applied to trajectories from other operating systems to generate environments beyond Android.
- Diverse app coverage may reduce overfitting to narrow task patterns that arise when training inside a single environment.
- If the pipeline scales to thousands of apps, the limiting factor for phone agents could shift from environment availability to model architecture or interaction modeling.
Load-bearing premise
The pipeline can accurately recover which screens matter, how they connect, which interactions change state, and which goals admit automatic verification from real trajectories.
What would settle it
Running the pipeline on a held-out set of trajectories and checking whether the generated mock apps and verifiers produce the same task outcomes as direct human evaluation on the original screens.
Figures
read the original abstract
A central bottleneck for phone-use agents is that controllable, reproducible environments covering real mobile behavior are hard to build at scale. Existing mobile-agent benchmarks have made important progress on evaluation, but they do not by themselves provide a scalable way to construct many new phone-use environments. We present PhoneWorld, a reusable pipeline that converts real GUI trajectories and screenshots into controllable phone-use environments, executable tasks, automatic verifiers, and training rollouts. Rather than hand-building one mobile benchmark at a time, PhoneWorld uses real trajectories to recover which screens matter, how screens connect, which interactions must change environment state, and which user goals admit automatic verification. From these signals, it builds runnable mock Android apps backed by read-only app content and mutable state, then derives executable tasks, rule-based verifiers, and training rollouts from the same environments. In its current instantiation, PhoneWorld covers 34 apps across 16 domains, spanning common consumer mobile behaviors such as search, browsing, shopping, booking, media, and social interaction. Under a fixed training budget, replacing 10K steps from an auxiliary AndroidWorld corpus in an AndroidWorld-based baseline with broad PhoneWorld supervision improves all four evaluation benchmarks at once, raising HYMobileBench by 17.7 points, AndroidControl by 6.0 points, AndroidWorld by 14.7 points, and PhoneWorld by 52.5 points. We then study two additional scaling questions: increasing the amount of PhoneWorld supervision strongly improves PhoneWorld performance, and under a fixed PhoneWorld budget, expanding app coverage yields even larger gains. Overall, PhoneWorld shifts the focus from building one mobile benchmark at a time to scaling the supply of phone-use environments themselves.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PhoneWorld, a reusable pipeline that converts real GUI trajectories and screenshots into controllable phone-use environments consisting of runnable mock Android apps, executable tasks, rule-based verifiers, and training rollouts. The pipeline recovers screens, transitions, state-changing interactions, and automatically verifiable goals from trajectories to build read-only content plus mutable state. In experiments, replacing 10K steps from an auxiliary AndroidWorld corpus with PhoneWorld supervision (covering 34 apps across 16 domains) improves all four benchmarks under a fixed training budget: +17.7 on HYMobileBench, +6.0 on AndroidControl, +14.7 on AndroidWorld, and +52.5 on PhoneWorld. Additional scaling studies examine increasing supervision volume and app coverage.
Significance. If the automatic recovery process produces faithful environments, the work would meaningfully address the scalability bottleneck in mobile-agent training by shifting from hand-crafted benchmarks to automated environment generation from real trajectories. The simultaneous gains across external and internal benchmarks, plus the scaling ablations, provide concrete evidence that the approach can improve agent performance; the multi-benchmark design and fixed-budget protocol are strengths.
major comments (2)
- [Section 3] Section 3: The pipeline description claims accurate recovery of 'which screens matter, how screens connect, which interactions change state, and which goals admit automatic verification,' followed by construction of runnable mocks and rule-based verifiers, yet reports no quantitative fidelity audit (e.g., precision of extracted state machines against held-out trajectories or soundness of verifiers measured by human agreement). This is load-bearing for the headline result because the reported cross-benchmark gains rest on the quality of the generated training signal; without such validation the improvements could arise from simplified or mis-specified environments rather than genuine scaling.
- [Evaluation] Evaluation (results paragraph): The +52.5 point gain is reported on the PhoneWorld benchmark itself, which is constructed from the same trajectory-to-environment pipeline; while the gains on the three external benchmarks (HYMobileBench, AndroidControl, AndroidWorld) provide independent grounding, the internal result requires explicit discussion of potential circularity and should be down-weighted in the overall claim.
minor comments (1)
- [Abstract and results] The abstract and results do not specify the exact model architecture, training hyperparameters, or data-split details used in the fixed-budget experiments, which would strengthen reproducibility claims.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments identify substantive gaps in validation and result interpretation. We address both below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Section 3] Section 3: The pipeline description claims accurate recovery of 'which screens matter, how screens connect, which interactions change state, and which goals admit automatic verification,' followed by construction of runnable mocks and rule-based verifiers, yet reports no quantitative fidelity audit (e.g., precision of extracted state machines against held-out trajectories or soundness of verifiers measured by human agreement). This is load-bearing for the headline result because the reported cross-benchmark gains rest on the quality of the generated training signal; without such validation the improvements could arise from simplified or mis-specified environments rather than genuine scaling.
Authors: We agree that a quantitative fidelity audit is necessary to substantiate the pipeline's claims and that its absence weakens the evidential basis for attributing gains to faithful environment recovery. In the revision we will add a new subsection (or appendix) reporting (1) precision/recall of recovered state machines on held-out trajectories and (2) human agreement rates on verifier soundness. These metrics will be computed on a random sample of 200 trajectories and verifiers. We view this addition as essential. revision: yes
-
Referee: [Evaluation] Evaluation (results paragraph): The +52.5 point gain is reported on the PhoneWorld benchmark itself, which is constructed from the same trajectory-to-environment pipeline; while the gains on the three external benchmarks (HYMobileBench, AndroidControl, AndroidWorld) provide independent grounding, the internal result requires explicit discussion of potential circularity and should be down-weighted in the overall claim.
Authors: We concur that the PhoneWorld-internal result carries circularity risk and should not be given equal weight. In the revised evaluation section we will (a) explicitly flag the shared pipeline origin, (b) present the three external-benchmark gains as the primary evidence, and (c) relegate the +52.5 figure to a secondary, caveated observation. The abstract and conclusion will be updated to reflect this re-weighting. revision: yes
Circularity Check
No significant circularity; claims rest on cross-benchmark empirical gains
full rationale
The paper describes an empirical pipeline that converts trajectories into environments, tasks, and verifiers, then reports performance gains after substituting PhoneWorld data into an AndroidWorld baseline. These gains are measured on four benchmarks, three of which (HYMobileBench, AndroidControl, AndroidWorld) are external to the PhoneWorld construction pipeline. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the abstract or described derivation. The central result is therefore not equivalent to its inputs by construction; independent external benchmarks supply grounding separate from the generated PhoneWorld set itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real GUI trajectories contain sufficient information to recover which screens matter, how screens connect, which interactions change environment state, and which user goals admit automatic verification.
Reference graph
Works this paper leans on
-
[1]
Yuan Cao, Dezhi Ran, Mengzhou Wu, Yuzhe Guo, Xin Chen, Ang Li, Gang Cao, Gong Zhi, Hao Yu, Linyi Li, et al. Gui-genesis: Automated synthesis of efficient environments with verifiable rewards for gui agent post-training.arXiv preprint arXiv:2602.14093,
-
[2]
Step: Success-rate- aware trajectory-efficient policy optimization.arXiv preprint arXiv:2511.13091,
Yuhan Chen, Yuxuan Liu, Long Zhang, Pengzhi Gao, Jian Luan, and Wei Liu. Step: Success-rate- aware trajectory-efficient policy optimization.arXiv preprint arXiv:2511.13091,
-
[3]
Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence
12 Preprint Guanting Dong, Junting Lu, Junjie Huang, Wanjun Zhong, Longxiang Liu, Shijue Huang, Zhenyu Li, Yang Zhao, Xiaoshuai Song, Xiaoxi Li, Jiajie Jin, Yutao Zhu, Hanbin Wang, Fangyu Lei, Qinyu Luo, Mingyang Chen, Zehui Chen, Jiazhan Feng, Ji-Rong Wen, and Zhicheng Dou. Agent- world: Scaling real-world environment synthesis for evolving general agent...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Kun Huang, Weikai Xu, Yuxuan Liu, Quandong Wang, Pengzhi Gao, Wei Liu, Jian Luan, Bin Wang, and Bo An. Mobileipl: Enhancing mobile agents thinking process via iterative preference learning.arXiv preprint arXiv:2505.12299,
-
[5]
Quyu Kong, Xu Zhang, Zhenyu Yang, Nolan Gao, Chen Liu, Panrong Tong, Chenglin Cai, Hanzhang Zhou, Jianan Zhang, Liangyu Chen, Zhidan Liu, Steven Hoi, and Yue Wang. Mobile- world: Benchmarking autonomous mobile agents in agent-user interactive, and mcp-augmented environments.arXiv preprint arXiv:2512.19432,
-
[6]
Yuxuan Liu, Weikai Xu, Kun Huang, Changyu Chen, Jiankun Zhao, Pengzhi Gao, Wei Liu, Jian Luan, Shuo Shang, Bo Du, et al. Come: Empowering channel-of-mobile-experts with informative hybrid-capabilities reasoning.arXiv preprint arXiv:2602.24142,
-
[7]
VideoAgentTrek: Computer use pretraining from unlabeled videos, 2025
Dunjie Lu, Yiheng Xu, Junli Wang, Haoyuan Wu, Xinyuan Wang, Zekun Wang, Junlin Yang, Hongjin Su, Jixuan Chen, Junda Chen, et al. Videoagenttrek: Computer use pretraining from unlabeled videos.arXiv preprint arXiv:2510.19488,
-
[8]
GUI-R1 : A Generalist R1-Style Vision-Language Action Model For GUI Agents
Run Luo, Lu Wang, Wanwei He, Longze Chen, Jiaming Li, and Xiaobo Xia. Gui-r1: A generalist r1-style vision-language action model for gui agents.arXiv preprint arXiv:2504.10458,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. Ui-tars: Pioneering automated gui interaction with native agents.arXiv preprint arXiv:2501.12326,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, Daniel Toyama, Robert Berry, Divya Tyamagundlu, Timothy Lillicrap, and Oriana Riva. Androidworld: A dynamic benchmark- ing environment for autonomous agents.arXiv preprint arXiv:2405.14573,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Yucheng Shi, Wenhao Yu, Zaitang Li, Yonglin Wang, Hongming Zhang, Ninghao Liu, Haitao Mi, and Dong Yu. Mobilegui-rl: Advancing mobile gui agent through reinforcement learning in online environment.arXiv preprint arXiv:2507.05720,
-
[12]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxiang Liu, Qinyu Luo, Shihao Liang, Shijue Huang, et al. Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning.arXiv preprint arXiv:2509.02544, 2025a. Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jita...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Agent World Model: Infinity Synthetic Environments for Agentic Reinforcement Learning
Xinyuan Wang, Bowen Wang, Dunjie Lu, Junlin Yang, Tianbao Xie, Junli Wang, Jiaqi Deng, Xiaole Guo, Yiheng Xu, Chen Wu, et al. Opencua: Open foundations for computer-use agents.Advances in Neural Information Processing Systems, 38:139756–139806, 2026a. Zhaoyang Wang, Canwen Xu, Boyi Liu, Yite Wang, Siwei Han, Zhewei Yao, Huaxiu Yao, and Yux- iong He. Agent...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
5: Multi-platform fundamental gui agents , author=
Haiyang Xu, Xi Zhang, Haowei Liu, Junyang Wang, Zhaozai Zhu, Shengjie Zhou, Xuhao Hu, Feiyu Gao, Junjie Cao, Zihua Wang, et al. Mobile-agent-v3. 5: Multi-platform fundamental gui agents. arXiv preprint arXiv:2602.16855, 2026a. Weikai Xu, Zhizheng Jiang, Yuxuan Liu, Pengzhi Gao, Wei Liu, Jian Luan, Yuanchun Li, Yunxin Liu, Bin Wang, and Bo An. Mobile-bench...
-
[15]
Abhay Zala, Jaemin Cho, Han Lin, Jaehong Yoon, and Mohit Bansal. Envgen: Generating and adapting environments via llms for training embodied agents.arXiv preprint arXiv:2403.12014,
-
[16]
Tongui: Internet-scale trajectories from multimodal web tutorials for generalized gui agents
Bofei Zhang, Zirui Shang, Zhi Gao, Wang Zhang, Rui Xie, Xiaojian Ma, Tao Yuan, Xinxiao Wu, Song-Chun Zhu, and Qing Li. Tongui: Internet-scale trajectories from multimodal web tutorials for generalized gui agents. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pp. 12367–12375, 2026a. Chi Zhang, Zhao Yang, Jiaxuan Liu, Yanda Li,...
2025
-
[17]
Infiniteweb: Scalable web environment synthesis for gui agent training, 2026
Ziyun Zhang, Zezhou Wang, Xiaoyi Zhang, Zongyu Guo, Jiahao Li, Bin Li, and Yan Lu. Infiniteweb: Scalable web environment synthesis for gui agent training.arXiv preprint arXiv:2601.04126, 2026b. Hanzhang Zhou, Xu Zhang, Panrong Tong, Jianan Zhang, Liangyu Chen, Quyu Kong, Chenglin Cai, Chen Liu, Yue Wang, Jingren Zhou, et al. Mai-ui technical report: Real-...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.