From Human Videos to Robot Manipulation: A Survey on Scalable Vision-Language-Action Learning with Human-Centric Data
Pith reviewed 2026-06-30 18:51 UTC · model grok-4.3
The pith
Human videos supply four kinds of action information that let Vision-Language-Action models learn robot manipulation without matching robot demonstrations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
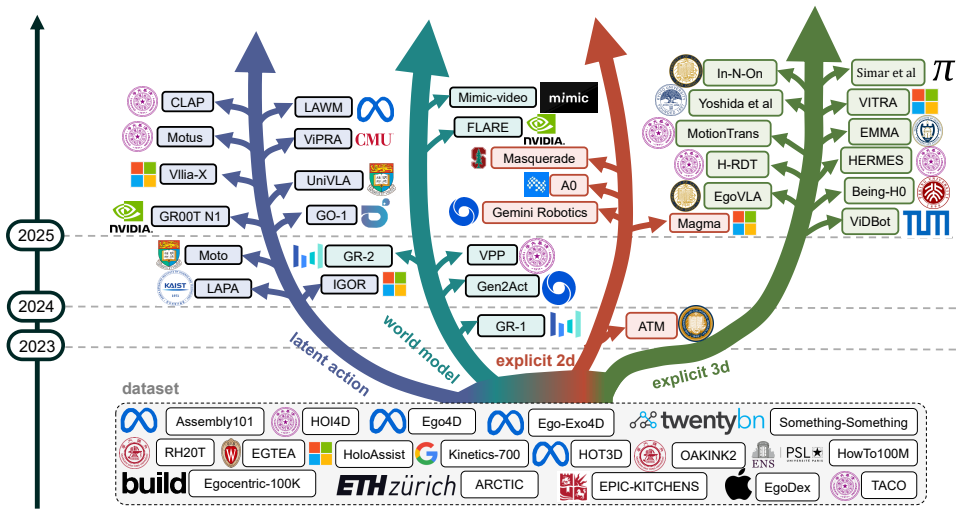
This survey claims that approaches converting human videos into knowledge for VLA models fall into four classes defined by the action-related information they derive: latent action representations that encode inter-frame changes, predictive world models that forecast future frames, explicit 2D supervision that extracts image-plane cues, and explicit 3D reconstruction that recovers geometry or motion. It further identifies three primary open challenges: structuring unstructured videos into training-ready episodes, grounding video-derived supervision into robot-executable actions under embodiment and viewpoint heterogeneity, and designing evaluation protocols that better predict real-world dep
What carries the argument
The four-class taxonomy that groups methods by the type of action-related information derived from human videos.
If this is right
- Methods within each category become easier to compare on how they handle embodiment differences.
- New work can be positioned explicitly against the taxonomy rather than described in isolation.
- Research effort can be directed at the three named challenges to increase transfer efficiency.
- Evaluation protocols can be redesigned to test generalization across embodiments more directly.
Where Pith is reading between the lines
- The taxonomy may be used to design hybrid approaches that combine signals from more than one class.
- Standardized benchmarks built around the three challenges could accelerate progress across research groups.
- Data collection efforts for human videos could be prioritized according to which category they best support.
Load-bearing premise
The four-category taxonomy fully covers the literature and the three listed challenges are the primary open problems limiting progress.
What would settle it
A published method that derives usable action information from human videos in a manner that fits none of the four categories, or an additional major challenge that is not among the three named in the survey.
Figures

read the original abstract
Recent progress in generalizable embodied control has been driven by large-scale pretraining of Vision-Language-Action (VLA) models. However, most existing approaches rely on large collections of robot demonstrations, which are costly to obtain and tightly coupled to specific embodiments. Human videos, by contrast, are abundant and capture rich interactions, providing diverse semantic and physical cues for real-world manipulation. Yet, embodiment differences and the frequent absence of task-aligned annotations make their direct use in VLA models challenging. This survey provides a unified view of how human videos are transformed into effective knowledge for VLA models. We categorize existing approaches into four classes based on the action-related information they derive: (i) latent action representations that encode inter-frame changes; (ii) predictive world models that forecast future frames; (iii) explicit 2D supervision that extracts image-plane cues; and (iv) explicit 3D reconstruction that recovers geometry or motion. Beyond this taxonomy, we highlight three key open challenges in this area: structuring unstructured videos into training-ready episodes, grounding video-derived supervision into robot-executable actions under embodiment and viewpoint heterogeneity, and designing evaluation protocols that better predict real-world deployment performance and transfer efficiency, thereby informing future research directions. A curated list of papers and resources is available at https://github.com/AaronFengZY/HumanCentricToVLA-Survey.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This survey categorizes methods that convert human videos into training signals for Vision-Language-Action (VLA) models into four classes based on the action-related information extracted: (i) latent action representations encoding inter-frame changes, (ii) predictive world models forecasting future frames, (iii) explicit 2D supervision providing image-plane cues, and (iv) explicit 3D reconstruction recovering geometry or motion. It additionally identifies three open challenges—structuring unstructured videos into episodes, grounding supervision under embodiment/viewpoint differences, and designing predictive evaluations—and supplies a curated GitHub resource list.
Significance. If the taxonomy is shown to be exhaustive and non-overlapping, the paper supplies a useful organizing framework for an active research area that seeks to replace expensive robot demonstrations with abundant human video data. The explicit listing of three challenges and the public resource repository constitute concrete aids to future work.
major comments (1)
- [Abstract] Abstract: the central claim that the literature is exhaustively partitioned into exactly these four classes is stated without enumeration of classification criteria, exclusion rules, or a systematic scan demonstrating coverage. If any cited work derives action information via hybrids (e.g., 2D-3D affordance fields) or other forms (e.g., language-conditioned flow without reconstruction), the unified view does not hold; the taxonomy section must supply explicit justification or a coverage table.
Simulated Author's Rebuttal
We thank the referee for the thoughtful feedback on our survey. The comment highlights a valid point about strengthening the presentation of our taxonomy. We address it directly below and commit to revisions that improve clarity without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the literature is exhaustively partitioned into exactly these four classes is stated without enumeration of classification criteria, exclusion rules, or a systematic scan demonstrating coverage. If any cited work derives action information via hybrids (e.g., 2D-3D affordance fields) or other forms (e.g., language-conditioned flow without reconstruction), the unified view does not hold; the taxonomy section must supply explicit justification or a coverage table.
Authors: We agree the abstract would benefit from a concise statement of the classification criteria. The taxonomy in Section 3 is organized by the primary action-related supervision signal derived from human videos (latent inter-frame encodings, future-frame prediction, 2D image-plane cues, and 3D geometry/motion recovery). This partitioning emerged from a systematic review of the literature; each cited work was assigned to the class matching its dominant supervision mechanism. Hybrids are placed according to their primary signal (e.g., a 2D-3D affordance method would fall under explicit 3D if geometry is central). To make this explicit, we will (i) add one sentence to the abstract listing the four criteria, (ii) insert a short paragraph in Section 3 on assignment rules and hybrid handling, and (iii) include a coverage table summarizing representative papers per class. These changes will be made in the revised manuscript. revision: yes
Circularity Check
No circularity: survey taxonomy organizes external literature without self-referential reduction
full rationale
This survey paper proposes a four-class taxonomy of methods that convert human videos into VLA knowledge but contains no derivations, equations, fitted parameters, or predictions. The categorization is presented as a descriptive partitioning of cited external works rather than a result obtained by construction from the paper's own inputs or self-citations. No load-bearing claim reduces to a self-definition, fitted input renamed as prediction, or uniqueness theorem imported from the authors' prior work. The paper is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
CORE: Common Outcome Regularities from Action-Free Visual Demonstrations for Robot Manipulation
CORE extracts visual goal prototypes from terminal embeddings in action-free demonstrations to condition robot policies, reporting success rate gains of up to 17 percentage points on manipulation benchmarks.
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, et al. Cosmos world foun- dation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Agibot world colosseo: A large-scale manipulation platform for scalable and intelli- gent embodied systems.IROS, pages 3549–3556, 2025
AgiBot-World-Contributors. Agibot world colosseo: A large-scale manipulation platform for scalable and intelli- gent embodied systems.IROS, pages 3549–3556, 2025
2025
-
[3]
Egocentric-100k, 2025
Build AI. Egocentric-100k, 2025
2025
-
[4]
Affordances from human videos as a versatile representation for robotics
Shikhar Bahl, Russell Mendonca, et al. Affordances from human videos as a versatile representation for robotics. In CVPR, 2023
2023
-
[5]
Hot3d: Hand and object tracking in 3d from egocentric multi-view videos
Prithviraj Banerjee, Sindi Shkodrani, Pierre Moulon, Shreyas Hampali, Shangchen Han, Fan Zhang, Linguang Zhang, Jade Fountain, Edward Miller, Selen Basol, et al. Hot3d: Hand and object tracking in 3d from egocentric multi-view videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7061–7071, 2025
2025
-
[6]
Gen2act: Human video generation in novel scenarios en- ables generalizable robot manipulation
Homanga Bharadhwaj, Debidatta Dwibedi, et al. Gen2act: Human video generation in novel scenarios en- ables generalizable robot manipulation. InCoRL, volume 305 ofPMLR, pages 3936–3951. PMLR, 2025
2025
-
[7]
Motus: A Unified Latent Action World Model
Hongzhe Bi, Hengkai Tan, et al. Motus: A unified latent action world model.arXiv:2512.13030, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
H-RDT: Human manipulation enhanced bimanual robotic manipulation
Hongzhe Bi, Lingxuan Wu, et al. H-RDT: Human manipulation enhanced bimanual robotic manipulation. arXiv:2507.23523, 2025
-
[9]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Casta ˜neda, et al. GR00T N1: An open foundation model for generalist humanoid robots. arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, et al.π 0: A vision- language-action flow model for general robot control. arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Scaling robot policy learning via zero-shot labeling with foundation models
Nils Blank, Moritz Reuss, et al. Scaling robot policy learning via zero-shot labeling with foundation models. Conference on Robot Learning (CoRL), 2024
2024
-
[12]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Affordance learn- ing from play for sample-efficient policy learning
Jessica Borja-Diaz, Oier Mees, et al. Affordance learn- ing from play for sample-efficient policy learning. In ICRA, Philadelphia, USA, 2022
2022
-
[14]
RT-2: Vision- language-action models transfer web knowledge to robotic control
Anthony Brohan, Noah Brown, et al. RT-2: Vision- language-action models transfer web knowledge to robotic control. InCoRL, 2023. arXiv preprint available
2023
-
[15]
UniVLA: Learning to act anywhere with task-centric latent actions
Qingwen Bu, Yanting Yang, et al. UniVLA: Learning to act anywhere with task-centric latent actions. InProceed- ings of Robotics: Science and Systems (RSS), 2025
2025
-
[16]
Xiongyi Cai, Ri-Zhao Qiu, et al. In-N-On: Scaling egocentric manipulation with in-the-wild and on-task data. arXiv:2511.15704, 2025
-
[17]
A short note on the kinetics-700 human action dataset.arXiv preprint arXiv:1907.06987, 2019
Joao Carreira, Eric Noland, Chloe Hillier, and Andrew Zisserman. A short note on the kinetics-700 human action dataset.arXiv preprint arXiv:1907.06987, 2019
-
[18]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Chi-Lam Cheang, Guangzeng Chen, et al. GR-2: A generative video-language-action model with web-scale knowledge for robot manipulation.arXiv:2410.06158, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
arXiv preprint arXiv:2411.00785 , year=
Xiaoyu Chen, Junliang Guo, et al. Igor: Image-goal representations are the atomic control units for foundation models in embodied AI.arXiv:2411.00785, 2024
-
[20]
VidBot: Learning gen- eralizable 3D actions from in-the-wild 2D human videos
Hanzhi Chen, Boyang Sun, et al. VidBot: Learning gen- eralizable 3D actions from in-the-wild 2D human videos. InCVPR, 2025
2025
-
[21]
Tianxing Chen, Zanxin Chen, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation. arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
villa-X: Enhancing Latent Action Modeling in Vision-Language-Action Models
Xiaoyu Chen, Hangxing Wei, et al. Villa-x: enhancing latent action modeling in vision-language-action models. arXiv preprint arXiv:2507.23682, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Moto: Latent motion token as the bridging language for learning robot manipulation from videos
Yi Chen, Yuying Ge, et al. Moto: Latent motion token as the bridging language for learning robot manipulation from videos. InICCV, 2025
2025
-
[24]
The EPIC- KITCHENS dataset: Collection, challenges and baselines
Dima Damen, Hazel Doughty, et al. The EPIC- KITCHENS dataset: Collection, challenges and baselines. TPAMI, 43(11), 2020
2020
-
[25]
Tam- ing transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Tam- ing transformers for high-resolution image synthesis. In CVPR, pages 12873–12883, 2021
2021
-
[26]
Arctic: A dataset for dexterous bimanual hand-object manipulation
Zicong Fan, Omid Taheri, et al. Arctic: A dataset for dexterous bimanual hand-object manipulation. InCVPR, pages 12943–12954, 2023
2023
-
[27]
arXiv preprint arXiv:2307.00595 , year=
Hao-Shu Fang, Hongjie Fang, Zhenyu Tang, Jirong Liu, Chenxi Wang, Junbo Wang, Haoyi Zhu, and Cewu Lu. Rh20t: A comprehensive robotic dataset for learning di- verse skills in one-shot.arXiv preprint arXiv:2307.00595, 2023
-
[28]
Learning la- tent action world models in the wild, 2026
Quentin Garrido, Tushar Nagarajan, et al. Learning la- tent action world models in the wild, 2026
2026
-
[29]
The ”something something” video database for learning and evaluating visual common sense
Raghav Goyal, Samira Ebrahimi Kahou, et al. The ”something something” video database for learning and evaluating visual common sense. InICCV, 2017
2017
-
[30]
Ego4D: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, et al. Ego4D: Around the world in 3,000 hours of egocentric video. In CVPR, 2022
2022
-
[31]
Ego-Exo4D: Understanding skilled human activity from first-and third- person perspectives
Kristen Grauman, Andrew Westbury, et al. Ego-Exo4D: Understanding skilled human activity from first-and third- person perspectives. InCVPR, 2024
2024
-
[32]
Lelan: Learn- ing a language-conditioned navigation policy from in-the- wild videos
Noriaki Hirose, Catherine Glossop, et al. Lelan: Learn- ing a language-conditioned navigation policy from in-the- wild videos. InConference on Robot Learning, 2024
2024
-
[33]
EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video
Ryan Hoque, Peide Huang, et al. Egodex: Learning dexterous manipulation from large-scale egocentric video. arXiv preprint arXiv:2505.11709, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Video prediction pol- icy: A generalist robot policy with predictive visual repre- sentations
Yucheng Hu, Yanjiang Guo, et al. Video prediction pol- icy: A generalist robot policy with predictive visual repre- sentations. InICML. PMLR, 2024
2024
-
[35]
Pu Hua, Minghuan Liu, Annabella Macaluso, Yunfeng Lin, Weinan Zhang, Huazhe Xu, and Lirui Wang. Gen- sim2: Scaling robot data generation with multi-modal and reasoning llms.arXiv preprint arXiv:2410.03645, 2024
-
[36]
Simar Kareer, Karl Pertsch, et al. Emergence of human to robot transfer in vision-language-action models.arXiv preprint arXiv:2512.22414, 2025
-
[37]
Droid: A large-scale in-the-wild robot manipulation dataset
Alexander Khazatsky, Karl Pertsch, et al. Droid: A large-scale in-the-wild robot manipulation dataset. In DGR@RSS 2024 (Poster), 2024
2024
-
[38]
OpenVLA: An open- source vision-language-action model
Moo Jin Kim, Karl Pertsch, et al. OpenVLA: An open- source vision-language-action model. InProceedings of the Conference on Robot Learning (CoRL), 2024
2024
-
[39]
Masquerade: Learn- ing from in-the-wild human videos using data-editing
Marion Lepert, Jiaying Fang, et al. Masquerade: Learn- ing from in-the-wild human videos using data-editing. InH2R Workshop at the Conference on Robot Learning (CoRL), 2025
2025
-
[40]
In the eye of the beholder: Gaze and actions in first person video.IEEE transactions on pattern analysis and machine intelligence, 45(6):6731–6747, 2021
Yin Li, Miao Liu, and James M Rehg. In the eye of the beholder: Gaze and actions in first person video.IEEE transactions on pattern analysis and machine intelligence, 45(6):6731–6747, 2021
2021
-
[41]
Chengshu Li, Ruohan Zhang, et al. Behavior-1k: A human-centered, embodied ai benchmark with 1,000 ev- eryday activities and realistic simulation.arXiv preprint arXiv:2403.09227, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Evaluating real-world robot manipulation policies in simulation
Xuanlin Li, Kyle Hsu, et al. Evaluating real-world robot manipulation policies in simulation. InConference on Robot Learning, 2024
2024
-
[43]
Qixiu Li, Yu Deng, et al. Scalable vision-language- action model pretraining for robotic manipulation with real-life human activity videos.arXiv:2510.21571, 2025
-
[44]
HOI4D: A 4d egocentric dataset for category-level human-object interaction
Yunze Liu, Yun Liu, et al. HOI4D: A 4d egocentric dataset for category-level human-object interaction. In CVPR, 2022
2022
-
[45]
Libero: Benchmarking knowledge transfer for lifelong robot learning.NIPS, 36:44776–44791, 2023
Bo Liu, Yifeng Zhu, et al. Libero: Benchmarking knowledge transfer for lifelong robot learning.NIPS, 36:44776–44791, 2023
2023
-
[46]
Taco: Bench- marking generalizable bimanual tool-action-object under- standing
Yun Liu, Haolin Yang, Xu Si, Ling Liu, Zipeng Li, Yuxiang Zhang, Yebin Liu, and Li Yi. Taco: Bench- marking generalizable bimanual tool-action-object under- standing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21740– 21751, 2024
2024
-
[47]
Hao Luo, Yicheng Feng, et al. Being-H0: Vision- language-action pretraining from large-scale human videos.arXiv:2507.15597, 2025
-
[48]
VIP: Towards universal visual reward and representation via value-implicit pre-training
Jason Yecheng Ma, Shagun Sodhani, et al. VIP: Towards universal visual reward and representation via value-implicit pre-training. InICLR, 2023. Spotlight pre- sentation
2023
-
[49]
Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
Oier Mees, Lukas Hermann, et al. Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
2022
-
[50]
Grounding lan- guage with visual affordances over unstructured data
Oier Mees, Jessica Borja-Diaz, et al. Grounding lan- guage with visual affordances over unstructured data. In ICRA, London, UK, 2023
2023
-
[51]
HowTo100M: Learning a text-video embedding by watching hundred million narrated video clips
Antoine Miech, Dimitri Zhukov, et al. HowTo100M: Learning a text-video embedding by watching hundred million narrated video clips. InICCV, 2019
2019
-
[52]
R3M: A univer- sal visual representation for robot manipulation
Suraj Nair, Aravind Rajeswaran, et al. R3M: A univer- sal visual representation for robot manipulation. InCoRL, 2022
2022
-
[53]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth´ee Darcet, et al. Dinov2: Learn- ing robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[54]
Open X- Embodiment: Robotic learning datasets and RT-X models
Abby O’Neill, Abdul Rehman, et al. Open X- Embodiment: Robotic learning datasets and RT-X models. InICRA, 2024
2024
-
[55]
mimic-video: Video-Action Models for Generalizable Robot Control Beyond VLAs
Jonas Pai, Liam Achenbach, et al. mimic-video: Video- action models for generalizable robot control beyond vlas. arXiv preprint arXiv:2512.15692, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Dexmv: Imitation learning for dexterous manipulation from human videos
Yuzhe Qin, Yueh-Hua Wu, et al. Dexmv: Imitation learning for dexterous manipulation from human videos. InECCV, 2022
2022
-
[57]
Embodied hands: Modeling and capturing hands and bodies together
Javier Romero, Dimitrios Tzionas, et al. Embodied hands: Modeling and capturing hands and bodies together. ACM Transactions on Graphics, 36(6), 2017
2017
-
[58]
Sandeep Routray, Hengkai Pan, et al. ViPRA: Video prediction for robot actions.arXiv:2511.07732, 2025
-
[59]
Assem- bly101: A large-scale multi-view video dataset for under- standing procedural activities
Fadime Sener, Dibyadip Chatterjee, et al. Assem- bly101: A large-scale multi-view video dataset for under- standing procedural activities. InCVPR, 2022
2022
-
[60]
Wave humanoid robot
Shenzhen ShARPA Robotics. Wave humanoid robot. https://www.sharpa.com/pages/wave, 2024. Accessed 2025-01
2024
-
[61]
Multimodal Reinforcement Learning with Adaptive Verifier for AI Agents
Reuben Tan, Baolin Peng, et al. Multimodal reinforce- ment learning with agentic verifier for ai agents.arXiv preprint arXiv:2512.03438, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Gemini Robotics: Bringing AI into the Physical World
Gemini Robotics Team. Gemini Robotics: Bringing AI into the physical world.arXiv:2503.20020, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Tesla ai day 2022
Tesla, Inc. Tesla ai day 2022. https://www.youtube. com/watch?v=ODSJsviD SU, September 2022. Official technical presentation
2022
-
[64]
Neural dis- crete representation learning.NIPS, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural dis- crete representation learning.NIPS, 30, 2017
2017
-
[65]
Bridgedata v2: A dataset for robot learning at scale
Homer Rich Walke, Kevin Black, Tony Z Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen-Estruch, An- dre Wang He, Vivek Myers, Moo Jin Kim, Max Du, et al. Bridgedata v2: A dataset for robot learning at scale. In Conference on Robot Learning, pages 1723–1736. PMLR, 2023
2023
-
[66]
Holoas- sist: an egocentric human interaction dataset for interac- tive ai assistants in the real world
Xin Wang, Taein Kwon, Mahdi Rad, Bowen Pan, Is- hani Chakraborty, Sean Andrist, Dan Bohus, Ashley Fe- niello, Bugra Tekin, Felipe Vieira Frujeri, et al. Holoas- sist: an egocentric human interaction dataset for interac- tive ai assistants in the real world. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20270–20281, 2023
2023
-
[67]
Gensim: Generating robotic simulation tasks via large language models, 2024
Lirui Wang, Yiyang Ling, Zhecheng Yuan, Mohit Shrid- har, Chen Bao, Yuzhe Qin, Bailin Wang, Huazhe Xu, and Xiaolong Wang. Gensim: Generating robotic simulation tasks via large language models, 2024
2024
-
[68]
Any-point trajectory modeling for policy learning
Chuan Wen, Xingyu Lin, et al. Any-point trajectory modeling for policy learning. InRSS, 2024
2024
-
[69]
Unleashing large-scale video generative pre-training for visual robot manipula- tion
Hongtao Wu, Ya Jing, et al. Unleashing large-scale video generative pre-training for visual robot manipula- tion. InICLR, 2024. Poster presentation
2024
-
[70]
Masked visual pre- training for motor control.arXiv:2203.06173, 2022
Tete Xiao, Ilija Radosavovic, et al. Masked visual pre- training for motor control.arXiv:2203.06173, 2022
-
[71]
A0: An affordance- aware hierarchical model for general robotic manipulation
Rongtao Xu, Jian Zhang, et al. A0: An affordance- aware hierarchical model for general robotic manipulation. InICCV, 2025
2025
-
[72]
Magma: A foundation model for multimodal AI agents
Jianwei Yang, Reuben Tan, et al. Magma: A foundation model for multimodal AI agents. InCVPR, 2025
2025
-
[73]
EgoVLA: Learning Vision-Language-Action Models from Egocentric Human Videos
Ruihan Yang, Qinxi Yu, et al. EgoVLA: Learn- ing vision-language-action models from egocentric human videos.arXiv:2507.12440, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
Latent action pretrain- ing from videos
Seonghyeon Ye, Joel Jang, et al. Latent action pretrain- ing from videos. InICLR, 2025. Poster presentation
2025
-
[75]
Develop- ing vision-language-action model from egocentric videos
Tomoya Yoshida, Shuhei Kurita, et al. Develop- ing vision-language-action model from egocentric videos. arXiv:2509.21986, 2025
-
[76]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, et al. Rep- resentation alignment for generation: Training diffusion transformers is easier than you think.arXiv preprint arXiv:2410.06940, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[77]
Motiontrans: Human vr data enable motion-level learning for robotic manipulation policies
Chengbo Yuan, Rui Zhou, et al. Motiontrans: Human vr data enable motion-level learning for robotic manipulation policies. InH2R Workshop at the Conference on Robot Learning (CoRL), 2025
2025
-
[78]
Hermes: Human- to-robot embodied learning from multi-source motion data for mobile dexterous manipulation
Zhecheng Yuan, Tianming Wei, et al. Hermes: Human- to-robot embodied learning from multi-source motion data for mobile dexterous manipulation. InProceedings of the 9th Conference on Robot Learning (CoRL), 2025
2025
-
[79]
Oakink2: A dataset of bimanual hands-object manipulation in complex task com- pletion
Xinyu Zhan, Lixin Yang, et al. Oakink2: A dataset of bimanual hands-object manipulation in complex task com- pletion. InCVPR, pages 445–456, 2024
2024
-
[80]
Clap: Contrastive la- tent action pretraining for learning vision-language-action models from human videos, 2026
Chubin Zhang, Jianan Wang, et al. Clap: Contrastive la- tent action pretraining for learning vision-language-action models from human videos, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.