Goal2Pixel: Grounding Goals to Pixels for Vision-Language Navigation
Pith reviewed 2026-06-28 15:37 UTC · model grok-4.3
The pith
Goal2Pixel reframes vision-language navigation as predicting a navigable pixel in the image, which back-projects to a 3D waypoint and replaces low-level action commands.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Goal2Pixel shows that reformulating VLN-CE as navigable pixel grounding lets a single VLM call produce a reliable 3D waypoint via back-projection, with auxiliary image regions handling turns and stops, and a keyframe memory supporting long horizons, yielding competitive success rates at far lower inference cost than action-prediction methods.
What carries the argument
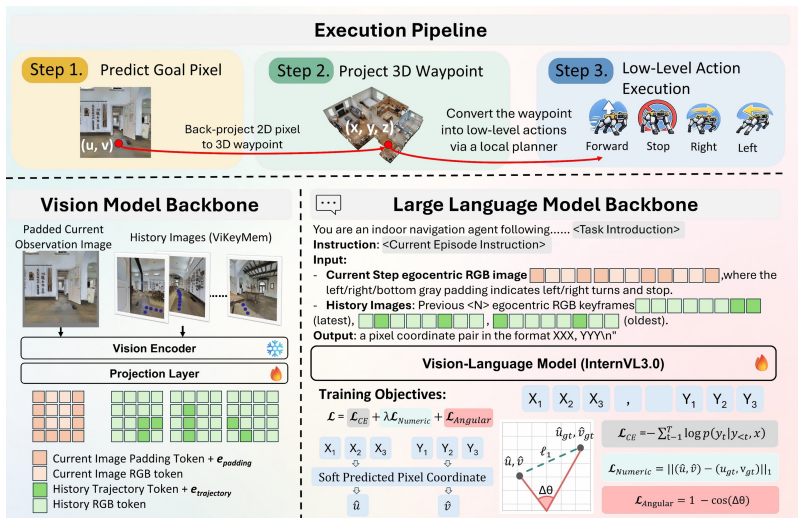
navigable pixel grounding: the VLM predicts a visible pixel that is back-projected to a 3D waypoint, with auxiliary left/right/bottom regions for turns and stops.
If this is right
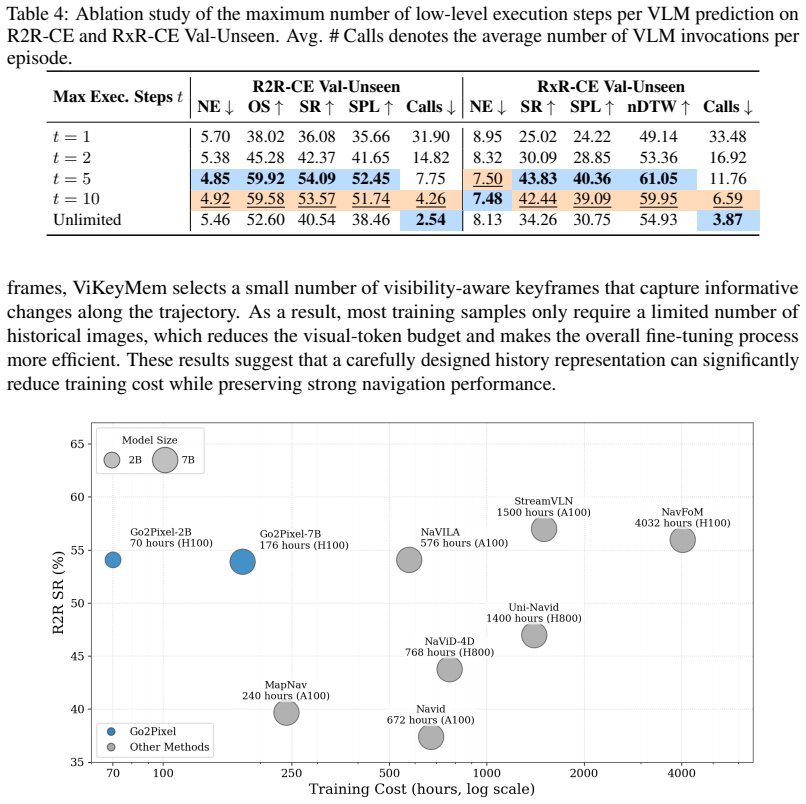
- Navigation succeeds with roughly one-sixth the VLM queries of direct action prediction while matching or exceeding prior success rates on R2R-CE and RxR-CE.
- The image plane serves as a unified interface, so no separate low-level action head or repeated short-horizon queries are required.
- Keyframe memory based on visibility keeps history short yet informative enough for multi-step paths.
- Semantic embeddings and coordinate-aware losses suffice to adapt existing VLMs without full retraining from scratch.
Where Pith is reading between the lines
- The method could extend to other embodied tasks that already output image coordinates, such as manipulation or object search, by reusing the same pixel interface.
- If back-projection accuracy varies with camera calibration, performance may degrade on robots whose intrinsics differ from the training setup.
- The auxiliary-region design assumes the agent always faces forward; environments requiring arbitrary in-place rotations might need additional regions.
Load-bearing premise
Back-projecting one predicted pixel to a waypoint, plus fixed auxiliary regions, produces reliable long trajectories without separate collision avoidance or recovery logic.
What would settle it
Run Goal2Pixel trajectories in environments where back-projection yields frequent collisions or dead-ends and measure whether success rate collapses without added recovery behaviors.
Figures





read the original abstract
Vision-language models (VLMs) have become a common foundation for vision-and-language navigation in continuous environments (VLN-CE). Yet most VLM-based methods cast navigation as low-level action prediction, an interface that is ambiguous, tied to short-horizon motion primitives, and inefficient due to repeated VLM querying. We propose Goal2Pixel, a pure pixel-based paradigm that reformulates VLN-CE as navigable pixel grounding. Rather than predicting actions, Goal2Pixel uses the image plane as a unified spatial interface between VLM reasoning and robot motion: the model predicts a visible navigable pixel to the agent, which is back-projected into a 3D waypoint for forward navigation. For non-forward actions, we append auxiliary directive regions to the image plane, where the left/right/bottom regions are interpreted as turning left, turning right, and stopping, respectively. To enable long-horizon navigation, we propose a visibility-aware keyframe memory for compact and informative history representation. To adapt pretrained VLMs to navigable pixel grounding, we introduce semantic embeddings and coordinate-aware auxiliary losses. Goal2Pixel achieves competitive state-of-the-art performance while requiring fewer VLM inference calls than prior methods. On R2R-CE Val-Unseen it achieves 54.1% SR and 52.5% SPL with just 7.75 VLM calls per episode, 6x fewer than the 46.62 required by direct action prediction at 32.9% SR. The same trend holds on RxR-CE.Project Page: https://baobao0926.github.io/Goal2Pixel/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Goal2Pixel, a pixel-grounding reformulation of VLN-CE in which a VLM predicts a single visible navigable pixel (back-projected to a 3D waypoint for forward motion) or one of three auxiliary image regions (left/right/bottom for turn-L/turn-R/stop). A visibility-aware keyframe memory supplies compact history, and the VLM is adapted via semantic embeddings plus coordinate-aware auxiliary losses. On R2R-CE Val-Unseen the method reports 54.1% SR / 52.5% SPL at 7.75 VLM calls per episode, versus 32.9% SR at 46.62 calls for direct action prediction; similar trends are claimed on RxR-CE.
Significance. If the empirical gains and call reduction hold under scrutiny, the work would demonstrate that a unified pixel interface can materially improve VLM efficiency for long-horizon navigation without sacrificing success rate. The reported 6× reduction in VLM queries while improving SR constitutes a concrete, falsifiable advance over action-prediction baselines.
major comments (2)
- [Method overview (abstract and §3)] Method overview (abstract and §3): the interface is defined solely by single-pixel back-projection plus auxiliary regions and visibility-aware memory; no collision checking, replanning, or explicit recovery policy is described. Because the central efficiency claim (7.75 calls/episode) and long-horizon SR rest on the assumption that every predicted waypoint is reachable and that auxiliary regions suffice for corrections, the absence of fallback mechanisms is load-bearing and requires either explicit justification or additional experiments on failure modes.
- [§4 (Experiments)] §4 (Experiments): the headline comparison attributes the SR jump (32.9% → 54.1%) and call reduction to the pixel interface, yet the text provides no ablation that isolates back-projection from the keyframe memory, semantic embeddings, or coordinate losses. Without such controls it remains unclear whether the reported numbers are robust to the interface change alone.
minor comments (2)
- [§3.3] The abstract states that auxiliary losses are 'coordinate-aware' but supplies no equation or implementation detail; a short derivation or pseudocode in §3.3 would clarify how these losses interact with the pixel-prediction head.
- Table captions and axis labels in the experimental figures should explicitly state the exact VLM backbone and number of episodes used for the call-count statistics to allow direct replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Method overview (abstract and §3)] Method overview (abstract and §3): the interface is defined solely by single-pixel back-projection plus auxiliary regions and visibility-aware memory; no collision checking, replanning, or explicit recovery policy is described. Because the central efficiency claim (7.75 calls/episode) and long-horizon SR rest on the assumption that every predicted waypoint is reachable and that auxiliary regions suffice for corrections, the absence of fallback mechanisms is load-bearing and requires either explicit justification or additional experiments on failure modes.
Authors: The Goal2Pixel interface requires the VLM to select a visible navigable pixel from the current observation, which by construction corresponds to free space reachable without collision. The auxiliary regions (left/right/bottom) provide explicit mechanisms for turn-L, turn-R, and stop to enable corrections. The visibility-aware keyframe memory supplies compact history to support consistent long-horizon decisions. We will add a dedicated paragraph in §3 providing explicit justification for these design choices and discussing edge cases (e.g., perception errors leading to unreachable predictions). No additional experiments are needed for this clarification. revision: yes
-
Referee: [§4 (Experiments)] §4 (Experiments): the headline comparison attributes the SR jump (32.9% → 54.1%) and call reduction to the pixel interface, yet the text provides no ablation that isolates back-projection from the keyframe memory, semantic embeddings, or coordinate losses. Without such controls it remains unclear whether the reported numbers are robust to the interface change alone.
Authors: We acknowledge the value of component-wise ablations. The primary experimental contrast is between the full pixel-grounding system and a direct action-prediction baseline; the keyframe memory, semantic embeddings, and coordinate losses are introduced specifically to enable effective pixel grounding with pretrained VLMs. The 6× reduction in VLM calls is a direct consequence of the longer-horizon pixel interface. We will revise §4 to clarify the attribution and the role of each adaptation. Full isolation ablations would require new runs and are not currently available. revision: partial
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper describes an empirical reformulation of VLN-CE as pixel grounding, with back-projection to waypoints, auxiliary image regions for non-forward actions, a visibility-aware keyframe memory, and auxiliary losses for VLM adaptation. No equations, fitted parameters renamed as predictions, or self-citation chains are present in the provided text that would reduce any claimed result to its inputs by construction. Reported SR/SPL metrics are presented as benchmark outcomes rather than derived quantities. This aligns with the absence of load-bearing self-definitional or fitted-input patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Krantz, E
J. Krantz, E. Wijmans, A. Majumdar, D. Batra, and S. Lee. Beyond the nav-graph: Vision-and- language navigation in continuous environments. InEuropean Conference on Computer Vision, pages 104–120. Springer, 2020
2020
-
[2]
A. Ku, P. Anderson, R. Patel, E. Ie, and J. Baldridge. Room-across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4392–4412, 2020
2020
-
[3]
Y . Hong, Q. Wu, Y . Qi, C. Rodriguez-Opazo, and S. Gould. Vln bert: A recurrent vision-and- language bert for navigation. InProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 1643–1653, 2021
2021
-
[4]
Chen, P.-L
S. Chen, P.-L. Guhur, C. Schmid, and I. Laptev. History aware multimodal transformer for vision- and-language navigation.Advances in neural information processing systems, 34:5834–5847, 2021
2021
-
[5]
Y . Hong, C. Rodriguez, Q. Wu, and S. Gould. Sub-instruction aware vision-and-language navigation. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 3360–3376, 2020
2020
-
[6]
Y . Qi, Z. Pan, Y . Hong, M.-H. Yang, A. Van Den Hengel, and Q. Wu. The road to know- where: An object-and-room informed sequential bert for indoor vision-language navigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1655–1664, 2021
2021
-
[7]
Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024
2024
-
[8]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y . Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y . Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
J. Lin, H. Yin, W. Ping, P. Molchanov, M. Shoeybi, and S. Han. Vila: On pre-training for visual language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26689–26699, 2024
2024
-
[10]
H. Liu, C. Li, Q. Wu, and Y . J. Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[11]
Efficient-VLN: A Simple yet Strong Baseline for Efficient Vision-Language Navigation
D. Zheng, S. Huang, Y . Li, and L. Wang. Efficient-vln: A training-efficient vision-language navigation model.arXiv preprint arXiv:2512.10310, 2025
work page internal anchor Pith review arXiv 2025
- [12]
-
[13]
Uni-NaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation Tasks
J. Zhang, K. Wang, S. Wang, M. Li, H. Liu, S. Wei, Z. Wang, Z. Zhang, and H. Wang. Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks.arXiv preprint arXiv:2412.06224, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Z. Yu, Y . Long, Z. Yang, C. Zeng, H. Fan, J. Zhang, and H. Dong. Correctnav: Self-correction flywheel empowers vision-language-action navigation model. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18737–18745, 2026. 9
2026
-
[15]
NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
J. Zhang, K. Wang, R. Xu, G. Zhou, Y . Hong, X. Fang, Q. Wu, Z. Zhang, and H. Wang. Navid: Video-based vlm plans the next step for vision-and-language navigation.arXiv preprint arXiv:2402.15852, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Zheng, S
D. Zheng, S. Huang, L. Zhao, Y . Zhong, and L. Wang. Towards learning a generalist model for embodied navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13624–13634, 2024
2024
- [17]
- [18]
-
[19]
A.-C. Cheng, Y . Ji, Z. Yang, Z. Gongye, X. Zou, J. Kautz, E. Bıyık, H. Yin, S. Liu, and X. Wang. Navila: Legged robot vision-language-action model for navigation.arXiv preprint arXiv:2412.04453, 2024
-
[20]
Zhang, X
L. Zhang, X. Hao, Q. Xu, Q. Zhang, X. Zhang, P. Wang, J. Zhang, Z. Wang, S. Zhang, and R. Xu. Mapnav: A novel memory representation via annotated semantic maps for vlm-based vision-and-language navigation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13032–13056, 2025
2025
-
[21]
B. Lin, Y . Nie, Z. Wei, J. Chen, S. Ma, J. Han, H. Xu, X. Chang, and X. Liang. Navcot: Boosting llm-based vision-and-language navigation via learning disentangled reasoning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[22]
X. Song, W. Chen, Y . Liu, W. Chen, G. Li, and L. Lin. Towards long-horizon vision-language navigation: Platform, benchmark and method. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[23]
Krantz, A
J. Krantz, A. Gokaslan, D. Batra, S. Lee, and O. Maksymets. Waypoint models for instruction- guided navigation in continuous environments. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15162–15171, 2021
2021
-
[24]
Zhang and P
Y . Zhang and P. Kordjamshidi. Narrowing the gap between vision and action in navigation. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 856–865, 2024
2024
- [25]
- [26]
- [27]
-
[28]
S. Wang, Y . Wang, Z. Fan, Y . Wang, M. Chen, K. Wang, Z. Su, W. Li, X. Cai, Y . Jin, et al. Monodream: Monocular vision-language navigation with panoramic dreaming. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 10074–10082, 2026
2026
-
[29]
Anderson, Q
P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. Sünderhauf, I. Reid, S. Gould, and A. Van Den Hengel. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3674–3683, 2018. 10
2018
- [30]
- [31]
-
[32]
J. Chen, B. Lin, X. Liu, L. Ma, X. Liang, and K.-Y . K. Wong. Affordances-oriented planning using foundation models for continuous vision-language navigation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 23568–23576, 2025
2025
-
[33]
K. Chen, D. An, Y . Huang, R. Xu, Y . Su, Y . Ling, I. Reid, and L. Wang. Constraint-aware zero-shot vision-language navigation in continuous environments.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
- [34]
-
[35]
Y . Hong, Z. Wang, Q. Wu, and S. Gould. Bridging the gap between learning in discrete and continuous environments for vision-and-language navigation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15439–15449, 2022
2022
-
[36]
Y . Hong, Y . Zhou, R. Zhang, F. Dernoncourt, T. Bui, S. Gould, and H. Tan. Learning naviga- tional visual representations with semantic map supervision. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3055–3067, 2023
2023
-
[37]
H. Wang, W. Liang, L. Van Gool, and W. Wang. Dreamwalker: Mental planning for continuous vision-language navigation. InProceedings of the IEEE/CVF international conference on computer vision, pages 10873–10883, 2023
2023
-
[38]
X. Yao, J. Gao, and C. Xu. Navmorph: A self-evolving world model for vision-and-language navigation in continuous environments. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 5536–5546, 2025
2025
-
[39]
D. An, H. Wang, W. Wang, Z. Wang, Y . Huang, K. He, and L. Wang. Etpnav: Evolving topolog- ical planning for vision-language navigation in continuous environments.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[40]
Wang and G
Z. Wang and G. H. Lee. g3d-lf: Generalizable 3d-language feature fields for embodied tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14191–14202, 2025
2025
-
[41]
Zhang, Y
S. Zhang, Y . Qiao, Q. Wang, Z. Yan, Q. Wu, Z. Wei, and J. Liu. Cosmo: Combination of selective memorization for low-cost vision-and-language navigation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5511–5522, 2025
2025
- [42]
-
[43]
Krantz and S
J. Krantz and S. Lee. Sim-2-sim transfer for vision-and-language navigation in continuous environments. InEuropean conference on computer vision, pages 588–603. Springer, 2022
2022
- [44]
-
[45]
R. Liu, W. Wang, and Y . Yang. Vision-language navigation with energy-based policy.Advances in Neural Information Processing Systems, 37:108208–108230, 2024. 11
2024
-
[46]
Taioli, S
F. Taioli, S. Rosa, A. Castellini, L. Natale, A. Del Bue, A. Farinelli, M. Cristani, and Y . Wang. Mind the error! detection and localization of instruction errors in vision-and-language navigation. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 12993–13000. IEEE, 2024
2024
- [47]
-
[48]
Matterport3D: Learning from RGB-D Data in Indoor Environments
A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niessner, M. Savva, S. Song, A. Zeng, and Y . Zhang. Matterport3d: Learning from rgb-d data in indoor environments.arXiv preprint arXiv:1709.06158, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[49]
H. Tan, L. Yu, and M. Bansal. Learning to navigate unseen environments: Back translation with environmental dropout. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2610–2621, 2019
2019
-
[50]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth international conference on artifi- cial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Proceedings, 2011
2011
-
[51]
H. Liu, W. Wan, X. Yu, M. Li, J. Zhang, B. Zhao, Z. Chen, Z. Wang, Z. Zhang, and H. Wang. Navid-4d: Unleashing spatial intelligence in egocentric rgb-d videos for vision-and-language navigation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 10607–10615. IEEE, 2025
2025
-
[52]
J. Zhang. Autonomy stack for mecanum wheel platform. https://github.com/ jizhang-cmu/autonomy_stack_mecanum_wheel_platform, 2024. Accessed: 2025-04- 29
2024
-
[53]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[54]
SGDR: Stochastic Gradient Descent with Warm Restarts
I. Loshchilov and F. Hutter. Sgdr: Stochastic gradient descent with warm restarts.arXiv preprint arXiv:1608.03983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[55]
T. Dao, D. Fu, S. Ermon, A. Rudra, and C. Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35: 16344–16359, 2022
2022
-
[56]
Rasley, S
J. Rasley, S. Rajbhandari, O. Ruwase, and Y . He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pages 3505–3506, 2020
2020
-
[57]
XXX, YYY
S. Rajbhandari, J. Rasley, O. Ruwase, and Y . He. Zero: Memory optimizations toward training trillion parameter models. InSC20: international conference for high performance computing, networking, storage and analysis, pages 1–16. IEEE, 2020. 12 Appendix A More Implementation Details A.1 Training Setup Goal2Pixel is initialized from InternVL3 [7], whose l...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.