Dive into the Scene: Breaking the Perceptual Bottleneck in Vision-Language Decision Making via Focus Plan Generation
Pith reviewed 2026-06-28 10:26 UTC · model grok-4.3
The pith
SceneDiver generates focus plans through scene graphs and iterative decomposition to reduce visual hallucinations in vision-language models for embodied tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
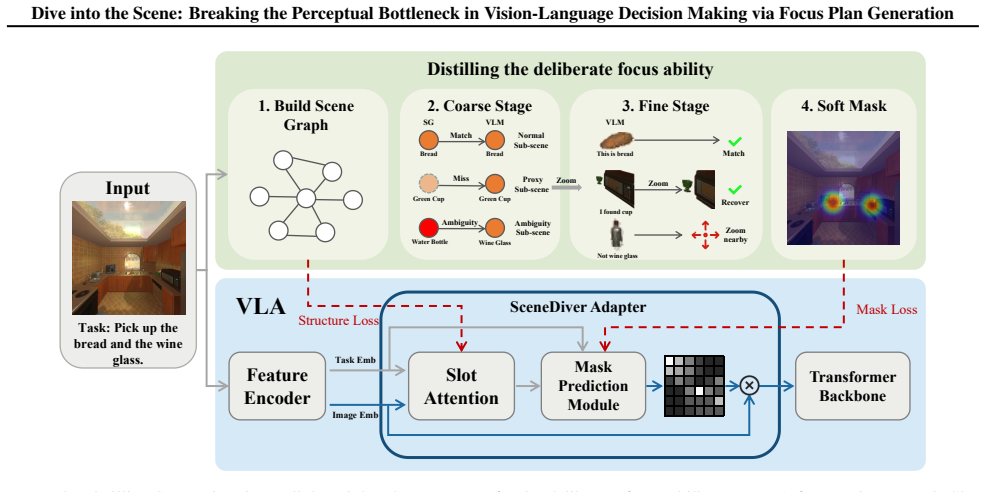
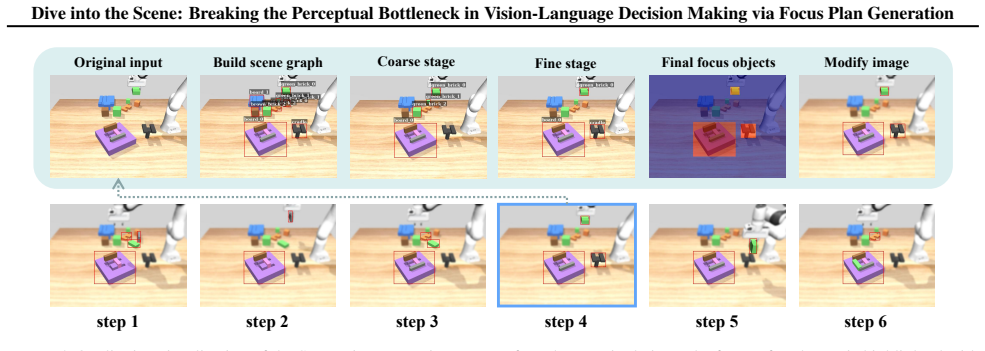
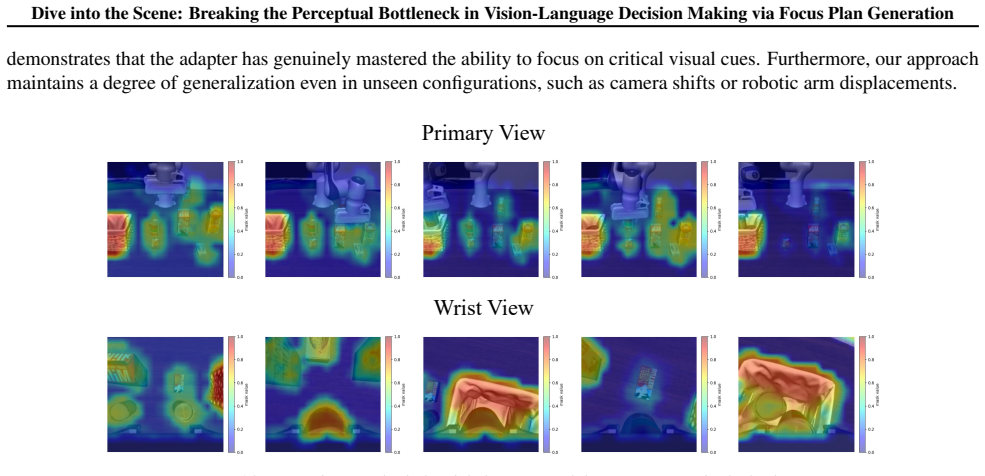
SceneDiver constructs a holistic scene graph to establish initial comprehension and then progressively decomposes the task into simpler sub-problems through an iterative cycle of recognition, understanding, and analysis, enabling accurate identification and focus on critical objects while filtering out irrelevant ones for both VLMs and VLAs.
What carries the argument
The coarse-to-fine focus plan generation process that begins with a holistic scene graph and proceeds via iterative recognition-understanding-analysis cycles.
If this is right
- Substantially reduces visual hallucinations for both VLMs and VLAs on standard embodied AI benchmarks.
- Preserves computational efficiency in tasks requiring fast execution.
- Leverages VLMs' long-term planning strengths for focus while enabling reactive control in VLAs via the adapter.
Where Pith is reading between the lines
- The scene graph representation could serve as a reusable intermediate structure for multiple sequential tasks in the same environment.
- The distillation adapter might allow similar focus improvements in other model families that lack built-in planning capacity.
- Iterative decomposition cycles could be tested in non-robotic vision-language settings such as image captioning with distractors.
Load-bearing premise
The assumption that a holistic scene graph plus iterative recognition-understanding-analysis cycles will produce effective deep scene understanding and focus without introducing new errors or excessive overhead.
What would settle it
A direct comparison on an embodied AI benchmark where SceneDiver produces no reduction in visual hallucination rates relative to baseline VLMs or VLAs, or where the added steps increase latency beyond the level needed for reactive control.
Figures










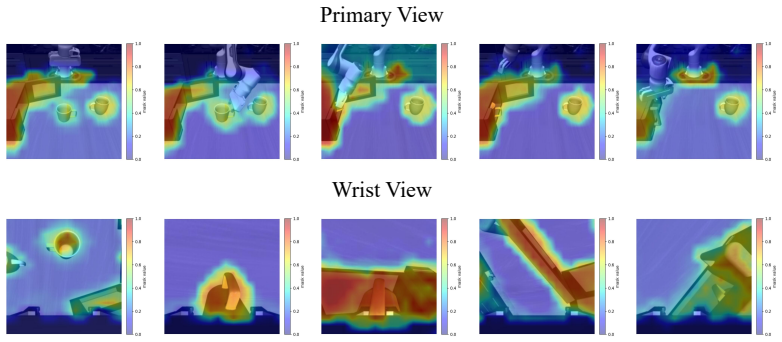
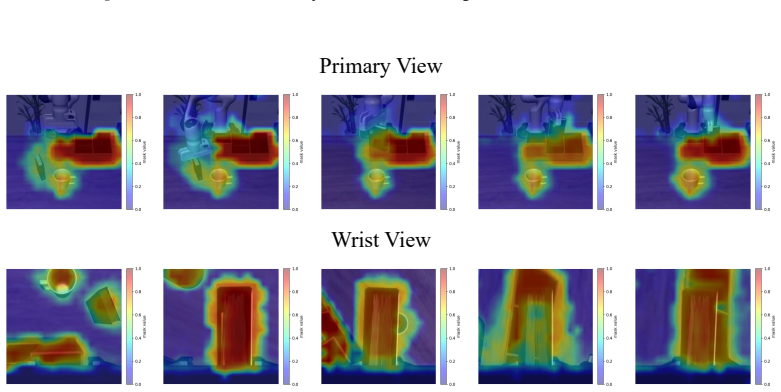
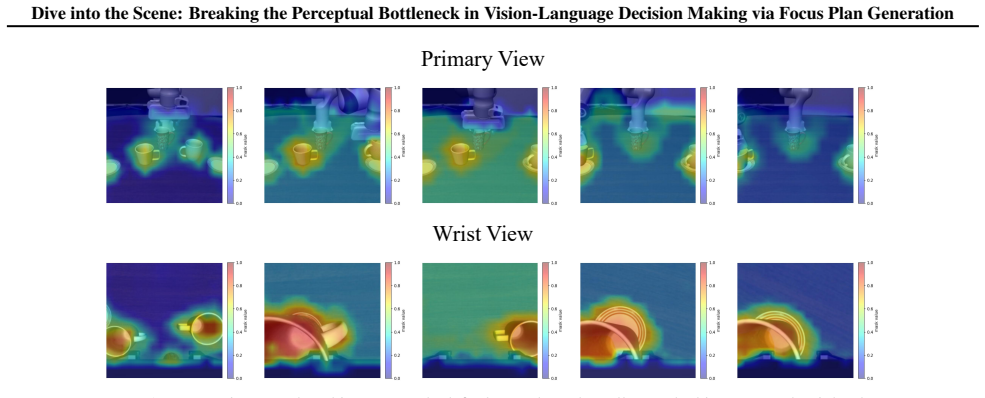
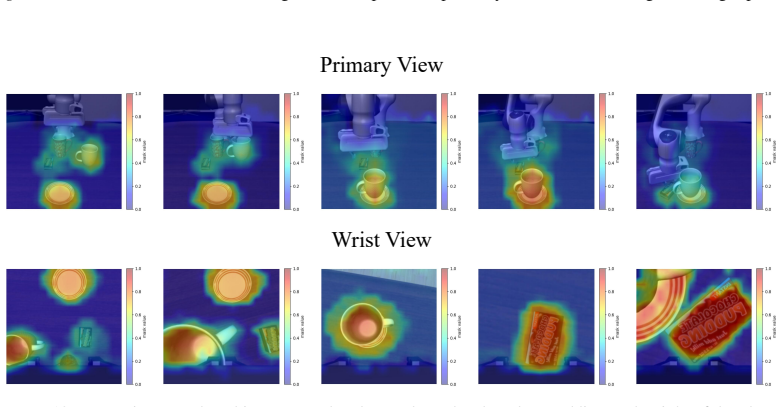
read the original abstract
In embodied vision-language decision making tasks such as robotic manipulation and navigation, Vision-Language and Vision-Language-Action Models (VLMs & VLAs) are powerful tools with different benefits: VLMs are better at long-term planning, while VLAs are better at reactive control. However, their performance is limited by the same perceptual bottleneck: visual hallucinations arise due to the models' inability to distinguish task-relevant objects from distractors. In principle, accurate identification and focus on critical objects while filtering out irrelevant ones is the key to break this limitation. A straightforward solution is one-step focus: directly attending to essential objects. However, this approach proves ineffective because effective focus inherently requires deep scene understanding. To this end, we propose SceneDiver, a coarse-to-fine focus plan generation method for VLMs leveraging their long-term planning abilities, that first constructs a holistic scene graph to establish initial comprehension, then progressively decomposes the task into simpler sub-problems through an iterative cycle of recognition, understanding, and analysis. To enable reactive control, we also design a lightweight adapter for distilling the deliberate focus ability into VLAs. Evaluations on standard embodied AI benchmarks confirm that our method substantially reduces visual hallucinations for both VLMs and VLAs, while preserving computational efficiency in tasks requiring fast execution. Our code and data are released at: https://future-item.github.io/SceneDiver.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SceneDiver, a coarse-to-fine focus plan generation method for VLMs in embodied vision-language decision making. It first builds a holistic scene graph for initial scene comprehension, then applies iterative cycles of recognition-understanding-analysis to decompose tasks and focus on relevant objects, thereby reducing visual hallucinations. A lightweight adapter distills the focus capability into VLAs for reactive control. The central claim is that this approach substantially reduces hallucinations on standard embodied AI benchmarks while preserving computational efficiency for fast-execution tasks; code and data are released.
Significance. If the empirical claims hold with adequate controls, the work could meaningfully improve reliability of VLMs and VLAs in robotic manipulation and navigation by addressing the perceptual bottleneck. The dual treatment of long-horizon planning (VLMs) and reactive control (VLAs), combined with the public release of code and data, strengthens reproducibility and potential adoption.
major comments (2)
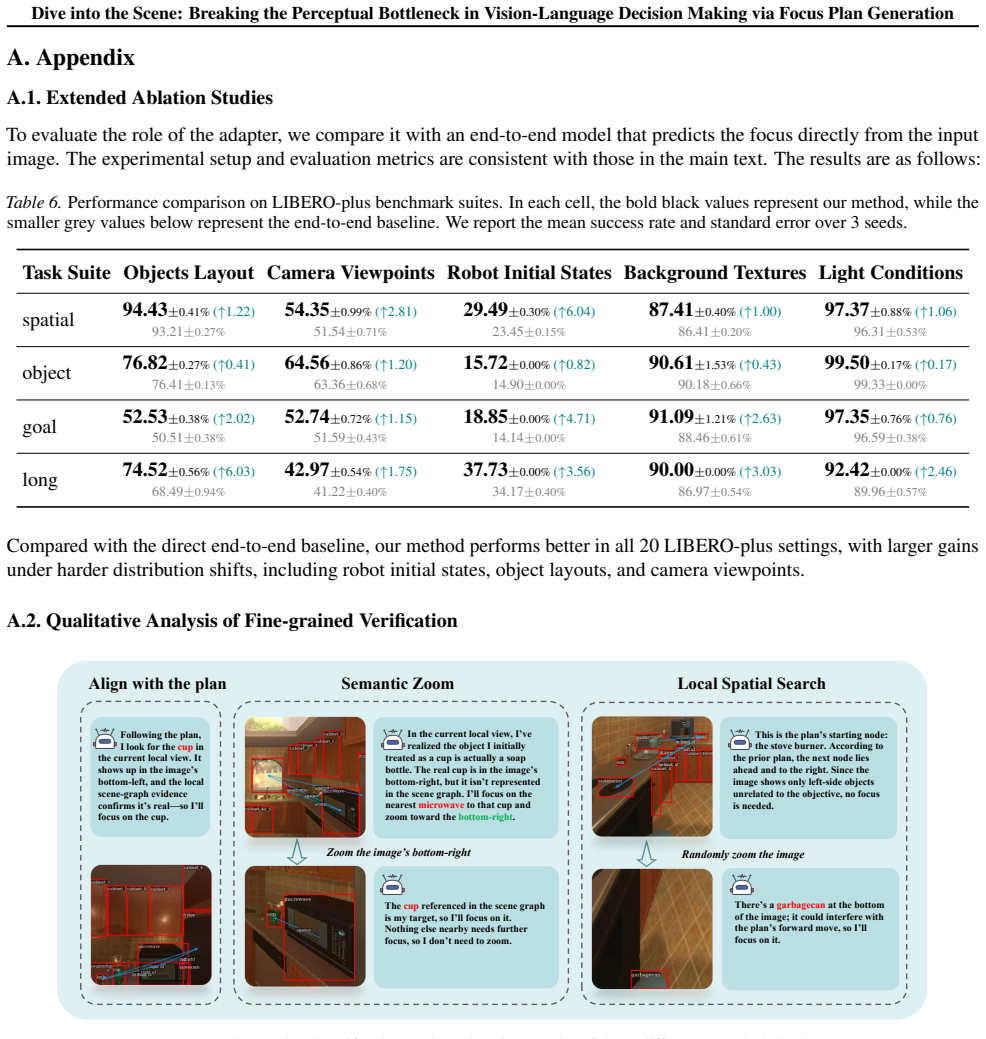
- [§4] §4 Experiments: the abstract and method overview assert 'substantial reductions' in visual hallucinations, yet the provided text supplies no concrete baseline comparisons, metrics (e.g., hallucination rate, success rate), error bars, or statistical tests; without these details the central empirical claim cannot be evaluated.
- [§3.2] §3.2 Iterative Cycle: the claim that the recognition-understanding-analysis loop produces effective deep scene understanding without introducing new errors or excessive overhead is load-bearing for both the hallucination-reduction and efficiency assertions, but no ablation or error-propagation analysis is described to bound this risk.
minor comments (3)
- [Abstract] Abstract: name the specific embodied AI benchmarks used rather than referring generically to 'standard' ones.
- [§3.1] Notation: the distinction between 'holistic scene graph' and subsequent 'focus plan' is introduced without a formal definition or diagram; a small illustrative figure would improve clarity.
- [§2] Related work: add explicit comparison to prior scene-graph and attention-focusing methods in VLMs to clarify incremental contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point-by-point below, indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [§4] §4 Experiments: the abstract and method overview assert 'substantial reductions' in visual hallucinations, yet the provided text supplies no concrete baseline comparisons, metrics (e.g., hallucination rate, success rate), error bars, or statistical tests; without these details the central empirical claim cannot be evaluated.
Authors: We agree that the abstract and method overview would benefit from more immediate quantitative grounding. The experiments section (§4) reports results on standard embodied AI benchmarks with baseline comparisons, including task success rates and hallucination metrics, along with error bars from repeated trials. To address the concern directly, we will revise the manuscript to add a summary of the key numerical improvements (e.g., relative reductions in hallucination rates and gains in success rate) to the abstract and include explicit statistical test results in §4. revision: yes
-
Referee: [§3.2] §3.2 Iterative Cycle: the claim that the recognition-understanding-analysis loop produces effective deep scene understanding without introducing new errors or excessive overhead is load-bearing for both the hallucination-reduction and efficiency assertions, but no ablation or error-propagation analysis is described to bound this risk.
Authors: This is a fair observation regarding the load-bearing nature of the iterative cycle. We will add a dedicated ablation study in the revised §4 that compares the full recognition-understanding-analysis loop against ablated variants (e.g., single-pass or non-iterative focus). The analysis will report effects on hallucination rates, task success, runtime overhead, and any observed error propagation, thereby bounding the risks and supporting the efficiency claims. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a proposed method (SceneDiver) that constructs a holistic scene graph then applies iterative recognition-understanding-analysis cycles plus an adapter for distillation; the central claims rest on asserted empirical reductions in hallucinations on standard embodied benchmarks. No equations, fitted parameters, self-citations used as load-bearing uniqueness theorems, or any derivation steps that reduce by construction to the inputs appear in the abstract or method sketch. The approach is therefore self-contained against external benchmarks with no circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
European conference on computer vision , pages=
Spice: Semantic propositional image caption evaluation , author=. European conference on computer vision , pages=. 2016 , organization=
2016
-
[2]
Terra: Hierarchical Terrain-Aware 3D Scene Graph for Task-Agnostic Outdoor Mapping
Terra: Hierarchical Terrain-Aware 3D Scene Graph for Task-Agnostic Outdoor Mapping , author=. arXiv preprint arXiv:2509.19579 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
Generating Actionable Robot Knowledge Bases by Combining 3D Scene Graphs with Robot Ontologies , author=. 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2025 , organization=
2025
-
[4]
Proceedings of the beyond vision and language: integrating real-world knowledge (LANTERN) , pages=
On the role of scene graphs in image captioning , author=. Proceedings of the beyond vision and language: integrating real-world knowledge (LANTERN) , pages=
-
[5]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Auto-encoding scene graphs for image captioning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[6]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Gqa: A new dataset for real-world visual reasoning and compositional question answering , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[7]
International journal of computer vision , volume=
Visual genome: Connecting language and vision using crowdsourced dense image annotations , author=. International journal of computer vision , volume=. 2017 , publisher=
2017
-
[8]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Image retrieval using scene graphs , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[9]
2023 , eprint=
SPHINX: The Joint Mixing of Weights, Tasks, and Visual Embeddings for Multi-modal Large Language Models , author=. 2023 , eprint=
2023
-
[10]
2024 , eprint=
LLaVA-OneVision: Easy Visual Task Transfer , author=. 2024 , eprint=
2024
-
[11]
Naval research logistics quarterly , volume=
The Hungarian method for the assignment problem , author=. Naval research logistics quarterly , volume=. 1955 , publisher=
1955
-
[12]
arXiv preprint arXiv:2505.04769 , year=
Vision-language-action models: Concepts, progress, applications and challenges , author=. arXiv preprint arXiv:2505.04769 , year=
-
[13]
Sensors , VOLUME =
Das, Murat and Hussain, Zawar and Nawaz, Muhammad , TITLE =. Sensors , VOLUME =. 2026 , NUMBER =
2026
-
[14]
2023 , eprint=
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control , author=. 2023 , eprint=
2023
-
[15]
2023 , eprint=
PaLM-E: An Embodied Multimodal Language Model , author=. 2023 , eprint=
2023
-
[16]
2022 , eprint=
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances , author=. 2022 , eprint=
2022
-
[17]
2023 , eprint=
Mitigating Object Hallucinations in Large Vision-Language Models through Visual Contrastive Decoding , author=. 2023 , eprint=
2023
-
[18]
2024 , eprint=
Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models , author=. 2024 , eprint=
2024
-
[19]
2023 , eprint=
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V , author=. 2023 , eprint=
2023
-
[20]
2026 , eprint=
_0 : A Vision-Language-Action Flow Model for General Robot Control , author=. 2026 , eprint=
2026
-
[21]
2024 , eprint=
Octo: An Open-Source Generalist Robot Policy , author=. 2024 , eprint=
2024
-
[22]
2025 , eprint=
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models , author=. 2025 , eprint=
2025
-
[23]
2020 , eprint=
Object-Centric Learning with Slot Attention , author=. 2020 , eprint=
2020
-
[24]
2025 , eprint=
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success , author=. 2025 , eprint=
2025
-
[25]
Imagine while Reasoning in Space: Multimodal Visualization-of-Thought
Imagine while reasoning in space: Multimodal visualization-of-thought , author=. arXiv preprint arXiv:2501.07542 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
arXiv preprint arXiv:2505.11409 (2025) 28 Z
Visual Planning: Let's Think Only with Images , author=. arXiv preprint arXiv:2505.11409 , year=
-
[27]
GoT-R1: Unleashing Reasoning Capability of MLLM for Visual Generation with Reinforcement Learning
Got-r1: Unleashing reasoning capability of mllm for visual generation with reinforcement learning , author=. arXiv preprint arXiv:2505.17022 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
arXiv preprint arXiv:2501.05452 , year=
Refocus: Visual editing as a chain of thought for structured image understanding , author=. arXiv preprint arXiv:2501.05452 , year=
-
[29]
arXiv preprint arXiv:2505.00684 , year=
Visual test-time scaling for gui agent grounding , author=. arXiv preprint arXiv:2505.00684 , year=
-
[30]
arXiv preprint arXiv:2507.00008 , year=
DiMo-GUI: Advancing Test-time Scaling in GUI Grounding via Modality-Aware Visual Reasoning , author=. arXiv preprint arXiv:2507.00008 , year=
-
[31]
arXiv preprint arXiv:2411.13591 , year=
Improved gui grounding via iterative narrowing , author=. arXiv preprint arXiv:2411.13591 , year=
-
[32]
2024 , eprint=
Expanding Scene Graph Boundaries: Fully Open-vocabulary Scene Graph Generation via Visual-Concept Alignment and Retention , author=. 2024 , eprint=
2024
-
[33]
2025 , eprint=
EmbodiedBench: Comprehensive Benchmarking Multi-modal Large Language Models for Vision-Driven Embodied Agents , author=. 2025 , eprint=
2025
-
[34]
2025 , eprint=
Reflective Planning: Vision-Language Models for Multi-Stage Long-Horizon Robotic Manipulation , author=. 2025 , eprint=
2025
-
[35]
Advances in neural information processing systems , volume=
Fine-tuning large vision-language models as decision-making agents via reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[36]
arXiv preprint arXiv:2402.14683 , year=
Visual hallucinations of multi-modal large language models , author=. arXiv preprint arXiv:2402.14683 , year=
-
[37]
arXiv preprint arXiv:2411.18142 , year=
Enhancing Visual Reasoning with Autonomous Imagination in Multimodal Large Language Models , author=. arXiv preprint arXiv:2411.18142 , year=
-
[38]
2024 , eprint=
Multi-Object Hallucination in Vision-Language Models , author=. 2024 , eprint=
2024
-
[39]
A Survey on Vision-Language-Action Models for Embodied AI
A survey on vision-language-action models for embodied ai , author=. arXiv preprint arXiv:2405.14093 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Conference on robot learning , pages=
Do as i can, not as i say: Grounding language in robotic affordances , author=. Conference on robot learning , pages=. 2023 , organization=
2023
-
[41]
International conference on machine learning , pages=
Language models as zero-shot planners: Extracting actionable knowledge for embodied agents , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[42]
Conference on Robot Learning , pages=
Bc-z: Zero-shot task generalization with robotic imitation learning , author=. Conference on Robot Learning , pages=. 2022 , organization=
2022
-
[43]
arXiv preprint arXiv:2407.20179 , year=
Theia: Distilling diverse vision foundation models for robot learning , author=. arXiv preprint arXiv:2407.20179 , year=
-
[44]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Self-supervised learning from images with a joint-embedding predictive architecture , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[45]
arXiv preprint arXiv:2302.12766 , year=
Language-driven representation learning for robotics , author=. arXiv preprint arXiv:2302.12766 , year=
-
[46]
2019 , eprint=
Object Hallucination in Image Captioning , author=. 2019 , eprint=
2019
-
[47]
2023 , eprint=
Plausible May Not Be Faithful: Probing Object Hallucination in Vision-Language Pre-training , author=. 2023 , eprint=
2023
-
[48]
2024 , eprint=
HallE-Control: Controlling Object Hallucination in Large Multimodal Models , author=. 2024 , eprint=
2024
-
[49]
2023 , eprint=
Ferret: Refer and Ground Anything Anywhere at Any Granularity , author=. 2023 , eprint=
2023
-
[50]
2024 , eprint=
GROUNDHOG: Grounding Large Language Models to Holistic Segmentation , author=. 2024 , eprint=
2024
-
[51]
2023 , eprint=
Aligning Large Multimodal Models with Factually Augmented RLHF , author=. 2023 , eprint=
2023
-
[52]
2024 , eprint=
Detecting and Preventing Hallucinations in Large Vision Language Models , author=. 2024 , eprint=
2024
-
[53]
2024 , eprint=
OPERA: Alleviating Hallucination in Multi-Modal Large Language Models via Over-Trust Penalty and Retrospection-Allocation , author=. 2024 , eprint=
2024
-
[54]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[55]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[56]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[57]
arXiv preprint arXiv:2501.02189 , year=
A survey of state of the art large vision language models: Alignment, benchmark, evaluations and challenges , author=. arXiv preprint arXiv:2501.02189 , year=
-
[58]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
GEOBench-VLM: Benchmarking Vision-Language Models for Geospatial Tasks , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[59]
arXiv preprint arXiv:2403.13164 , year=
VL-ICL Bench: The Devil in the Details of Multimodal In-Context Learning , author=. arXiv preprint arXiv:2403.13164 , year=
-
[60]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[61]
Visual Instruction Tuning , author=
-
[62]
and Chai, Joyce , title =
Chen, Xuweiyi and Ma, Ziqiao and Zhang, Xuejun and Xu, Sihan and Qian, Shengyi and Yang, Jianing and Fouhey, David F. and Chai, Joyce , title =. 2025 , isbn =
2025
-
[63]
arXiv preprint arXiv:2502.01969 , year=
Mitigating object hallucinations in large vision-language models via attention calibration , author=. arXiv preprint arXiv:2502.01969 , year=
-
[64]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[65]
2012 IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
MuJoCo: A physics engine for model-based control , author=. 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=. 2012 , organization=
2012
-
[66]
Qwen2.5-VL Technical Report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[68]
2025 , eprint=
Seed1.5-VL Technical Report , author=. 2025 , eprint=
2025
-
[69]
2025 , eprint=
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author=. 2025 , eprint=
2025
-
[70]
2024 , url =
OpenAI , title =. 2024 , url =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.