Flash-WAM: Modality-Aware Distillation for World Action Models
Pith reviewed 2026-06-28 06:58 UTC · model grok-4.3
The pith
Flash-WAM distills joint video-action world models to single-step inference by matching consistency functions to each modality's noise regime.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
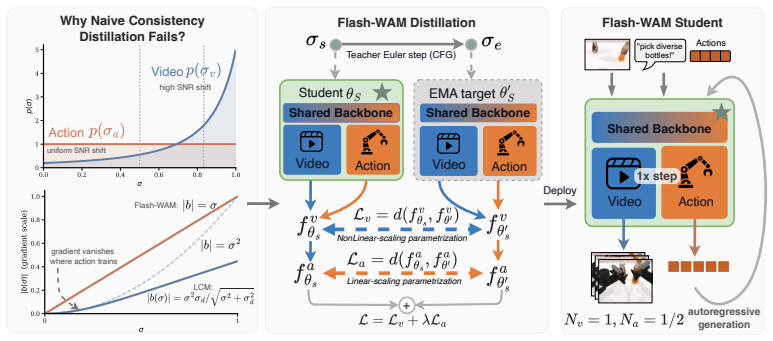
Flash-WAM is a modality-aware step-distillation framework that selects a linear-gradient-scaling parametrization for the action stream and a variance-preserving parametrization for the video stream, grounded in structural analysis of the consistency-function family under the consistency boundary condition, to compress inference to a single step in each modality while preserving task success.
What carries the argument
modality-aware selection of consistency functions matched to noise regimes via structural analysis of the consistency-function family
If this is right
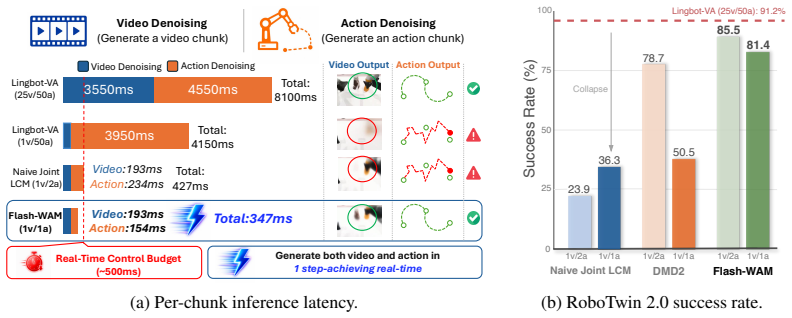
- Per-chunk latency drops from 8.1 seconds to 348 ms on NVIDIA L40S, a 23x speedup that supports real-time control.
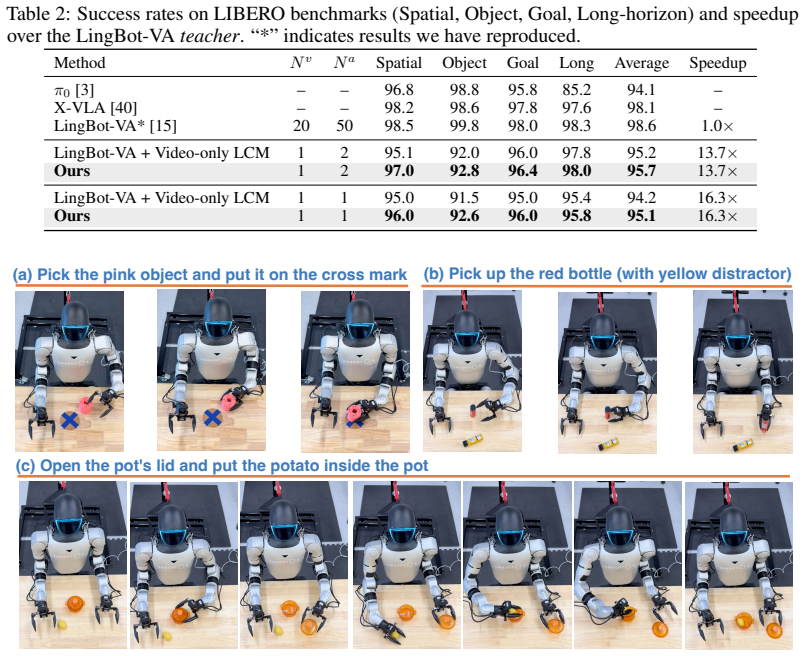
- Task success holds at 85.5 percent on RoboTwin 2.0 and 95.7 percent on LIBERO.
- Real-world performance on a Unitree G1 humanoid recovers to 60 percent average.
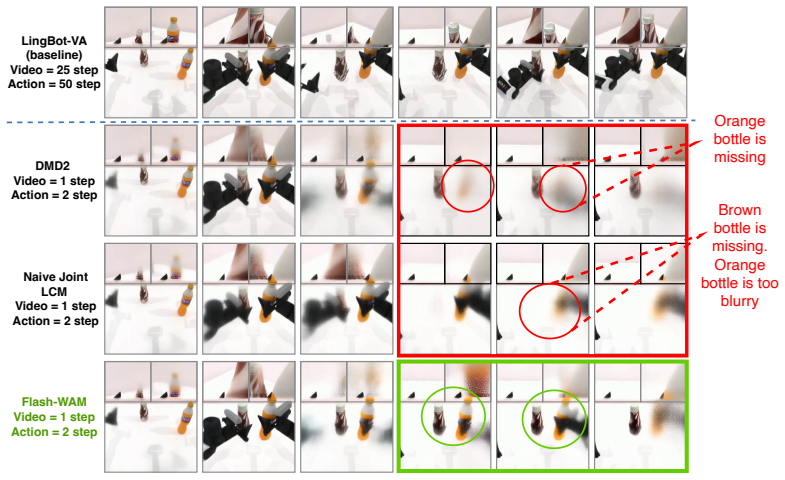
- Naive consistency distillation falls to 24 percent success at the same one-step budget.
Where Pith is reading between the lines
- The approach could extend to other multi-modal diffusion setups that combine streams with mismatched noise schedules.
- The structural analysis might be automated to detect suitable parametrizations without manual inspection for new modalities.
- Single-step capability could allow closed-loop deployment of world models in settings that demand immediate action generation.
Load-bearing premise
The structural analysis of the consistency-function family correctly identifies that a linear-gradient-scaling parametrization matches the action stream's low-noise regime and a variance-preserving parametrization matches the video stream's high-noise regime.
What would settle it
Apply the same consistency function to both modalities or swap the two parametrizations, then measure whether one-step task success on RoboTwin 2.0 falls well below 85.5 percent.
Figures
read the original abstract
World-action models (WAMs) jointly generate future video and robot actions through iterative diffusion, achieving strong performance on manipulation benchmarks but requiring tens of denoising steps, a cost that precludes real-time control. Step distillation has emerged as the natural remedy, but off-the-shelf methods break down in the joint video-action setting because video and action streams use different SNR-shifted noise schedules and reach training with substantially different marginal noise distributions, an asymmetry that single-modality distillation methods cannot accommodate. We introduce \textbf{Flash-WAM}, a modality-aware step-distillation framework inspired by consistency distillation that selects the consistency function for each modality to match its noise regime: a linear-gradient-scaling parametrization for the action stream's low-noise regime, paired with a variance-preserving parametrization for the video stream's high-noise regime, grounded in a structural analysis of the consistency-function family that characterizes the achievable gradient scaling under the consistency boundary condition. Instantiated on LingBot-VA, Flash-WAM compresses inference to a single step in each modality. On RoboTwin 2.0, this reduces per-chunk latency from $8.1$ seconds to $348$ ms on NVIDIA L40S, a $23{\times}$ speedup that enables real-time inference. Flash-WAM preserves task success on simulation benchmarks ($85.5\%$ RoboTwin 2.0, $95.7\%$ LIBERO) and substantially recovers real-world performance ($60\%$ average on a Unitree G1 humanoid robot), while naive consistency distillation drops to $24\%$ at the same step budget.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Flash-WAM, a modality-aware step-distillation framework for world-action models (WAMs) that jointly generate future video and robot actions via diffusion. It selects a linear-gradient-scaling consistency parametrization for the action stream (low-noise regime) and a variance-preserving parametrization for the video stream (high-noise regime), grounded in a structural analysis of the consistency-function family under the consistency boundary condition. This enables single-step inference per modality, yielding a 23× speedup (8.1 s to 348 ms per chunk on NVIDIA L40S) on RoboTwin 2.0 while reporting 85.5% task success (vs. 24% for naive distillation), 95.7% on LIBERO, and 60% average real-world recovery on a Unitree G1.
Significance. If the structural analysis and experimental claims hold, the work provides a principled solution to the multi-modal asymmetry problem in distilling joint video-action diffusion models, potentially enabling real-time robotic control applications that were previously precluded by iterative denoising costs.
major comments (2)
- [Abstract and structural analysis section] Abstract and structural analysis (likely §3): The central claim that the modality-specific parametrizations are justified by a structural analysis characterizing 'achievable gradient scaling under the consistency boundary condition' is load-bearing, yet the manuscript supplies no derivation, equations, or explicit verification that the boundary condition holds under joint video-action SNR-shifted schedules and differing marginal noise distributions. Without this, it is unclear whether the analysis accounts for modality interactions or implicitly assumes independence.
- [Experiments section] Experiments (RoboTwin 2.0 results): The reported preservation of 85.5% success at 1-step inference (vs. 24% naive) is presented as following from the parametrization choice alone, but no ablation isolating the linear-gradient-scaling vs. variance-preserving selection, no verification of the low-noise/high-noise regime assumptions, and no details on training adjustments are supplied. This directly undermines evaluation of the weakest assumption identified in the structural analysis.
minor comments (2)
- The abstract states performance numbers and the 23× speedup without referencing specific tables or figures; adding explicit cross-references would improve traceability.
- Notation for the consistency functions and SNR schedules should be defined earlier and used consistently when describing the joint diffusion process.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract and structural analysis section] Abstract and structural analysis (likely §3): The central claim that the modality-specific parametrizations are justified by a structural analysis characterizing 'achievable gradient scaling under the consistency boundary condition' is load-bearing, yet the manuscript supplies no derivation, equations, or explicit verification that the boundary condition holds under joint video-action SNR-shifted schedules and differing marginal noise distributions. Without this, it is unclear whether the analysis accounts for modality interactions or implicitly assumes independence.
Authors: We agree that an explicit derivation would strengthen the presentation. In the revised manuscript we will expand the structural analysis section to include the full derivation of achievable gradient scaling under the consistency boundary condition, explicitly treating the joint SNR-shifted schedules and differing marginal distributions. The derivation will show that modality interactions are captured through the shared training objective rather than by assuming independence. revision: yes
-
Referee: [Experiments section] Experiments (RoboTwin 2.0 results): The reported preservation of 85.5% success at 1-step inference (vs. 24% naive) is presented as following from the parametrization choice alone, but no ablation isolating the linear-gradient-scaling vs. variance-preserving selection, no verification of the low-noise/high-noise regime assumptions, and no details on training adjustments are supplied. This directly undermines evaluation of the weakest assumption identified in the structural analysis.
Authors: The existing results demonstrate the overall benefit relative to naive distillation. We acknowledge that isolating ablations would allow stronger attribution to the parametrization choices. In the revision we will add an ablation study comparing the selected parametrizations against alternatives, include explicit verification of the noise-regime assumptions, and provide training-adjustment details in the appendix. revision: yes
Circularity Check
No circularity: structural analysis presented as independent contribution
full rationale
The paper's central claim rests on a modality-aware choice of consistency parametrizations, justified by an internal structural analysis of the consistency-function family under the boundary condition. No equations, fitted parameters, or predictions are shown to reduce to their own inputs by construction. The analysis is described as characterizing achievable gradient scaling, and the abstract presents it as grounding the framework rather than assuming it from prior self-work. No load-bearing self-citations or ansatzes smuggled via citation appear in the provided text. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Motus: A Unified Latent Action World Model
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, Hongyan Zhao, Hanyu Liu, Zhizhong Su, Lei Ma, Hang Su, and Jun Zhu. Motus: A unified latent action world model, 2025. URL https://arxiv.org/abs/2512.13030
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Real-Time Execution of Action Chunking Flow Policies
Kevin Black, Manuel Y . Galliker, and Sergey Levine. Real-time execution of action chunking flow policies, 2025. URLhttps://arxiv.org/abs/2506.07339
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky. π0: A visi...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
DOLLAR: Few-Step Video Generation via Distillation and Latent Reward Optimization
Zihan Ding, Chi Jin, Difan Liu, Haitian Zheng, Krishna Kumar Singh, Qiang Zhang, Yan Kang, Zhe Lin, and Yuchen Liu. Dollar: Few-step video generation via distillation and latent reward optimization, 2024. URLhttps://arxiv.org/abs/2412.15689
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis, 2024. URL https://arxiv.org/abs/ 2403.03206
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Phased dmd: Few-step distribution matching distillation via score matching within subintervals, 2026
Xiangyu Fan, Zesong Qiu, Zhuguanyu Wu, Fanzhou Wang, Zhiqian Lin, Tianxiang Ren, Dahua Lin, Ruihao Gong, and Lei Yang. Phased dmd: Few-step distribution matching distillation via score matching within subintervals, 2026. URLhttps://arxiv.org/abs/2510.27684
-
[8]
One Step Diffusion via Shortcut Models
Kevin Frans, Danijar Hafner, Sergey Levine, and Pieter Abbeel. One step diffusion via shortcut models, 2025. URLhttps://arxiv.org/abs/2410.12557
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Zhengyang Geng, Ashwini Pokle, William Luo, Justin Lin, and J. Zico Kolter. Consistency models made easy, 2024. URLhttps://arxiv.org/abs/2406.14548
-
[10]
World Model for Robot Learning: A Comprehensive Survey
Bohan Hou, Gen Li, Jindou Jia, Tuo An, Xinying Guo, Sicong Leng, Haoran Geng, Yanjie Ze, Tatsuya Harada, Philip Torr, Oier Mees, Marc Pollefeys, Zhuang Liu, Jiajun Wu, Pieter Abbeel, Jitendra Malik, Yilun Du, and Jianfei Yang. World model for robot learning: A comprehensive survey, 2026. URLhttps://arxiv.org/abs/2605.00080
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsc...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Elucidating the Design Space of Diffusion-Based Generative Models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models, 2022. URLhttps://arxiv.org/abs/2206.00364
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success, 2025. URLhttps://arxiv.org/abs/2502.19645. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
T2v-turbo-v2: Enhancing video generation model post-training through data, reward, and conditional guidance design, 2025
Jiachen Li, Qian Long, Jian Zheng, Xiaofeng Gao, Robinson Piramuthu, Wenhu Chen, and William Yang Wang. T2v-turbo-v2: Enhancing video generation model post-training through data, reward, and conditional guidance design, 2025. URL https://arxiv.org/abs/2410. 05677
2025
-
[15]
Causal world modeling for robot control,
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, Yujun Shen, and Yinghao Xu. Causal world modeling for robot control,
-
[16]
URLhttps://arxiv.org/abs/2601.21998
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
A Comprehensive Survey on World Models for Embodied AI
Xinqing Li, Xin He, Le Zhang, Min Wu, Xiaoli Li, and Yun Liu. A comprehensive survey on world models for embodied ai, 2025. URLhttps://arxiv.org/abs/2510.16732
work page internal anchor Pith review arXiv 2025
-
[18]
Video Generators are Robot Policies
Junbang Liang, Pavel Tokmakov, Ruoshi Liu, Sruthi Sudhakar, Paarth Shah, Rares Ambrus, and Carl V ondrick. Video generators are robot policies, 2025. URLhttps://arxiv.org/abs/ 2508.00795
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
V ote: Vision-language-action optimization with trajectory ensemble voting, 2025
Juyi Lin, Amir Taherin, Arash Akbari, Arman Akbari, Lei Lu, Guangyu Chen, Taskin Padir, Xiaomeng Yang, Weiwei Chen, Yiqian Li, Xue Lin, David Kaeli, Pu Zhao, and Yanzhi Wang. V ote: Vision-language-action optimization with trajectory ensemble voting, 2025. URLhttps: //arxiv.org/abs/2507.05116
-
[20]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling, 2023. URLhttps://arxiv.org/abs/2210.02747
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning, 2023. URL https: //arxiv.org/abs/2306.03310
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Ma, Xiaohua Xie, and Jian-Huang Lai
Yanzuo Lu, Yuxi Ren, Xin Xia, Shanchuan Lin, Xing Wang, Xuefeng Xiao, Andy J. Ma, Xiaohua Xie, and Jian-Huang Lai. Adversarial distribution matching for diffusion distillation towards efficient image and video synthesis, 2025. URL https://arxiv.org/abs/2507. 18569
2025
-
[23]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference, 2023. URL https://arxiv. org/abs/2310.04378
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Weijian Luo, Zemin Huang, Zhengyang Geng, J. Zico Kolter, and Guo jun Qi. One-step diffusion distillation through score implicit matching, 2024. URL https://arxiv.org/abs/ 2410.16794
-
[25]
Transition matching distillation for fast video generation, 2026
Weili Nie, Julius Berner, Nanye Ma, Chao Liu, Saining Xie, and Arash Vahdat. Transition matching distillation for fast video generation, 2026. URL https://arxiv.org/abs/2601. 09881
2026
-
[26]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA, :, Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi "Jim" Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, Y...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
How VLAs (Really) Work In Open-World Environments
Amir Rasouli, Yangzheng Wu, Zhiyuan Li, Rui Heng Yang, Xuan Zhao, Charles Eret, and Sajjad Pakdamansavoji. How vlas (really) work in open-world environments, 2026. URL https://arxiv.org/abs/2604.21192
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Human Cognition in Machines: A Unified Perspective of World Models
Timothy Rupprecht, Pu Zhao, Amir Taherin, Arash Akbari, Arman Akbari, Yumei He, Sean Duffy, Juyi Lin, Yixiao Chen, Rahul Chowdhury, Enfu Nan, Yixin Shen, Yifan Cao, Haochen Zeng, Weiwei Chen, Geng Yuan, Jennifer Dy, Sarah Ostadabbas, Silvia Zhang, David Kaeli, Edmund Yeh, and Yanzhi Wang. Human cognition in machines: A unified perspective of world models,...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Progressive distillation for fast sampling of diffusion models,
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models,
-
[30]
URLhttps://arxiv.org/abs/2202.00512
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models, 2023. URL https://arxiv.org/abs/2303.01469
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Tidal: Temporally interleaved diffusion and action loop for high-frequency vla control,
Yuteng Sun, Haoran Wang, Ruofei Bai, Zhengguo Li, Jun Li, Meng Yee, Chuah, and Wei Yun Yau. Tidal: Temporally interleaved diffusion and action loop for high-frequency vla control,
-
[33]
URLhttps://arxiv.org/abs/2601.14945
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Animatelcm: Computation-efficient personalized style video generation without personalized video data, 2024
Fu-Yun Wang, Zhaoyang Huang, Weikang Bian, Xiaoyu Shi, Keqiang Sun, Guanglu Song, Yu Liu, and Hongsheng Li. Animatelcm: Computation-efficient personalized style video generation without personalized video data, 2024. URL https://arxiv.org/abs/2402. 00769
2024
-
[35]
Videolcm: Video latent consistency model, 2023
Xiang Wang, Shiwei Zhang, Han Zhang, Yu Liu, Yingya Zhang, Changxin Gao, and Nong Sang. Videolcm: Video latent consistency model, 2023. URL https://arxiv.org/abs/ 2312.09109
-
[36]
One-step diffusion models with f-divergence distribu- tion matching, 2025
Yilun Xu, Weili Nie, and Arash Vahdat. One-step diffusion models with f-divergence distribu- tion matching, 2025. URLhttps://arxiv.org/abs/2502.15681
-
[37]
Gigaworld-policy: An efficient action-centered world–action model, 2026
Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Hao Li, Hengtao Li, Jie Li, Jindi Lv, Jingyu Liu, Min Cao, Peng Li, Qiuping Deng, Wenjun Mei, Xiaofeng Wang, Xinze Chen, Xinyu Zhou, Yang Wang, Yifan Chang, Yifan Li, Yukun Zhou, Yun Ye, Zhichao Liu, and Zheng Zhu. Gigaworld-policy: An efficient action-centered world–action model, 2026. URL htt...
-
[38]
World action models are zero-shot policies,
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, Ayaan Malik, Kyungmin Lee, William Liang, Nadun Ranawaka, Jiasheng Gu, Yinzhen Xu, Guanzhi Wang, Fengyuan Hu, Avnish Narayan, Johan Bjorck, Jing Wang, Gwanghyun Kim, Dantong Niu, Ruijie Zheng, Yuqi Xie, Jimmy Wu, Qi ...
-
[39]
URLhttps://arxiv.org/abs/2602.15922
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and William T. Freeman. Improved distribution matching distillation for fast image synthesis,
- [41]
-
[42]
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T. Freeman, and Taesung Park. One-step diffusion with distribution matching distillation, 2024. URLhttps://arxiv.org/abs/2311.18828
-
[43]
Fast-WAM: Do World Action Models Need Test-time Future Imagination?
Tianyuan Yuan, Zibin Dong, Yicheng Liu, and Hang Zhao. Fast-wam: Do world action models need test-time future imagination?, 2026. URLhttps://arxiv.org/abs/2603.16666
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
Do World Action Models Generalize Better than VLAs? A Robustness Study
Zhanguang Zhang, Zhiyuan Li, Behnam Rahmati, Rui Heng Yang, Yintao Ma, Amir Rasouli, Sajjad Pakdamansavoji, Yangzheng Wu, Lingfeng Zhang, Tongtong Cao, Feng Wen, Xinyu Wang, Xingyue Quan, and Yingxue Zhang. Do world action models generalize better than vlas? a robustness study, 2026. URLhttps://arxiv.org/abs/2603.22078
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, Ya-Qin Zhang, Jiangmiao Pang, Jingjing Liu, Tai Wang, and Xianyuan Zhan. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model, 2025. URLhttps://arxiv.org/abs/2510.10274
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Dexgraspvla: A vision-language-action framework towards general dexterous grasping, 2025
Yifan Zhong, Xuchuan Huang, Ruochong Li, Ceyao Zhang, Zhang Chen, Tianrui Guan, Fanlian Zeng, Ka Num Lui, Yuyao Ye, Yitao Liang, Yaodong Yang, and Yuanpei Chen. Dexgraspvla: A vision-language-action framework towards general dexterous grasping, 2025. URL https: //arxiv.org/abs/2502.20900. 14 A Implementation Details We provide full implementation details ...
-
[47]
supply past-frame context through flex attention, exactly as in pretraining (block- causal across chunks; strict causality from noisy to clean tokens). The video input at the next step is constructed by re-noising the predicted clean video: xv σi+1 = (1−σ i+1) ˆxv,(i) 0 +σ i+1 ϵv,(i+1),ϵ v,(i+1) ∼ N(0,I).(17) The action stream input depends on the variant...
-
[48]
In both variants, the critic and reference model produce their predictions in a single forward pass on the joint input( ˜xv, ˜xa)
For Video-only DMD2 + reg, the action input to scoring is constructed by 17 perturbing the ground-truth action xa 0 at noise level σa directly. In both variants, the critic and reference model produce their predictions in a single forward pass on the joint input( ˜xv, ˜xa). The fake and real predicted clean outputs for video are ˆxv,fake 0 = ˜xv −σ v vv θ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.