On Advantage Estimates for Max@K Policy Gradients
Pith reviewed 2026-06-28 02:18 UTC · model grok-4.3
The pith
The Leave-Two-Out baseline makes realized batch advantages exactly centered for max@K while preserving policy-gradient unbiasedness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
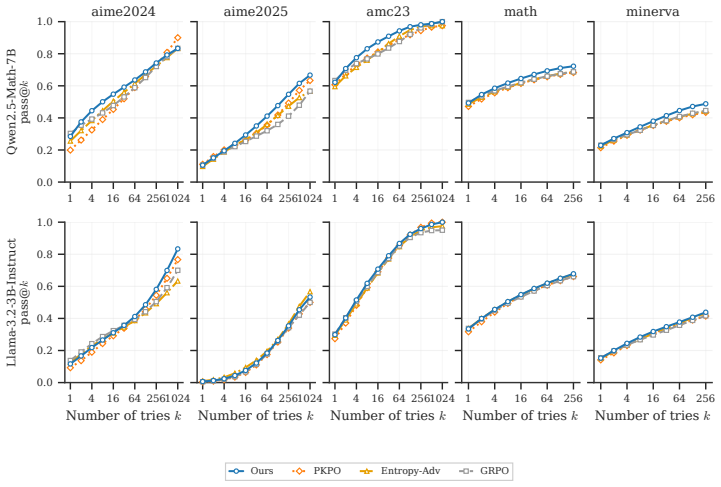
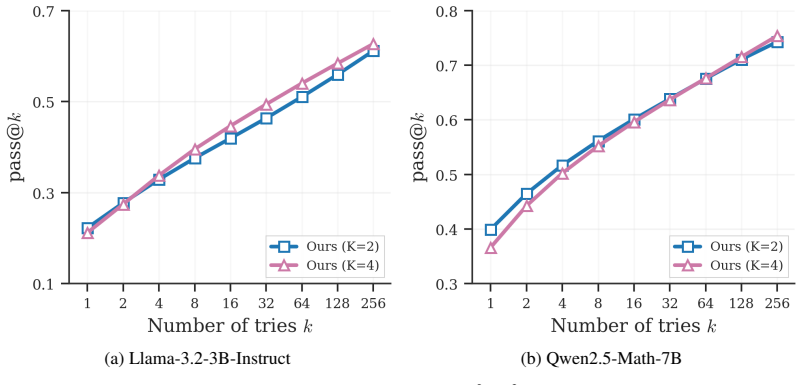
Starting from the advantage estimator of a leading method in the field, we show that it is policy-gradient unbiased but yields a non-centered advantage. We then introduce a Leave-Two-Out baseline that preserves policy-gradient unbiasedness while making realized batch advantages exactly centered. The resulting method, MaxPO, has an efficient quadratic-time implementation and integrates naturally into group-based RL for LLM post-training. We further derive the canonical finite-batch advantage for max@K, providing a unified view of existing advantage estimators. Empirically, we verify that the L2O baseline reduces gradient variance and outperforms non-centered alternatives.
What carries the argument
The Leave-Two-Out baseline, which uses leave-two-out estimates to ensure exact centering of batch advantages while maintaining unbiased policy gradients for the max@K objective.
If this is right
- The MaxPO method reduces gradient variance compared to non-centered estimators.
- The canonical finite-batch advantage unifies existing estimators for max@K.
- MaxPO integrates naturally into group-based RL training for LLMs.
- The L2O baseline has an efficient quadratic-time implementation.
Where Pith is reading between the lines
- If the variance reduction holds across tasks, MaxPO could enable more stable training with smaller batch sizes.
- The centering property might generalize to other group-based sampling methods in RL beyond max@K.
- Future work could test whether the unbiased centered advantages improve convergence speed on downstream reasoning benchmarks.
Load-bearing premise
The observed reduction in gradient variance from using the centered L2O baseline will translate into improved final performance on downstream tasks without introducing instabilities.
What would settle it
Running the same LLM post-training experiment with MaxPO versus a non-centered baseline and measuring the difference in final model accuracy or pass@K scores on held-out reasoning tasks would test if the centering improves outcomes.
Figures



read the original abstract
Reinforcement learning with verifiable rewards is widely used for post-training reasoning models, but sparse outcome rewards make exploration difficult. A complementary approach is to optimize inference-time objectives such as pass@K and max@K directly, yet existing policy-gradient estimators for these objectives use different signals, baselines, and normalizations, making their relationships unclear. We study this issue through baseline design and advantage centering. Starting from the advantage estimator of a leading method in the field, we show that it is policy-gradient unbiased but yields a non-centered advantage. We then introduce a Leave-Two-Out baseline that preserves policy-gradient unbiasedness while making realized batch advantages exactly centered. The resulting method, MaxPO, has an efficient quadratic-time implementation and integrates naturally into group-based RL for LLM post-training. We further derive the canonical finite-batch advantage for max@K, providing a unified view of existing advantage estimators. Empirically, we verify that the L2O baseline reduces gradient variance and outperforms non-centered alternatives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper starts from an existing advantage estimator for max@K policy gradients that is shown to be policy-gradient unbiased but non-centered. It introduces a Leave-Two-Out (L2O) baseline that preserves unbiasedness while forcing realized batch advantages to be exactly centered, yielding the MaxPO method with a quadratic-time implementation. The work also derives the canonical finite-batch advantage estimator for max@K and provides a unified view of prior estimators. Empirically, L2O is shown to reduce gradient variance and to outperform non-centered alternatives when integrated into group-based RL for LLM post-training with verifiable rewards.
Significance. If the unbiasedness and exact-centering claims are correct, the paper supplies a principled baseline design that addresses a practical difficulty in optimizing inference-time objectives under sparse outcome rewards. The derivation of the canonical estimator and the explicit centering construction are potentially useful for clarifying relationships among existing methods. The reported variance reduction is a concrete, measurable improvement, though its translation to final model quality remains the least-secured step.
major comments (2)
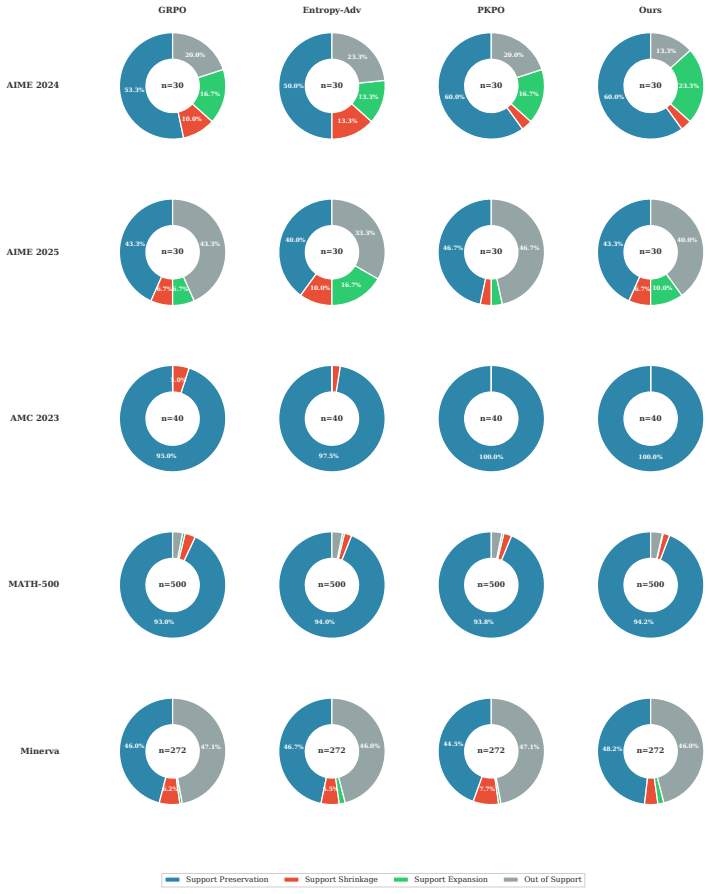
- [Empirical Evaluation / §5] Empirical Evaluation (abstract and §5): the manuscript reports that L2O reduces gradient variance and that MaxPO outperforms non-centered alternatives, yet supplies no analytic argument or controlled ablation showing that exact batch centering cannot suppress useful exploration signals under group-based sampling and sparse verifiable rewards; the link from lower-variance centered advantages to improved downstream task performance is therefore asserted rather than derived or isolated.
- [§3.2–3.3] §3.2–3.3: while the L2O construction is stated to preserve policy-gradient unbiasedness, the dependence introduced by the max@K operator over the group means that leaving out exactly two samples must be shown to cancel the bias term exactly; the provided derivation sketch does not explicitly verify this cancellation for the finite-batch case.
minor comments (2)
- [§2] Notation for the max@K objective and the group size K should be introduced once in §2 and used consistently thereafter to avoid redefinition.
- [§4] The quadratic-time implementation complexity is stated but not accompanied by a small worked example or pseudocode that would make the Leave-Two-Out procedure immediately reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. Below we respond point-by-point to the major concerns. We agree that both points identify areas where the manuscript can be strengthened and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Empirical Evaluation / §5] Empirical Evaluation (abstract and §5): the manuscript reports that L2O reduces gradient variance and that MaxPO outperforms non-centered alternatives, yet supplies no analytic argument or controlled ablation showing that exact batch centering cannot suppress useful exploration signals under group-based sampling and sparse verifiable rewards; the link from lower-variance centered advantages to improved downstream task performance is therefore asserted rather than derived or isolated.
Authors: We agree that the current manuscript does not isolate the effect of centering on exploration via a dedicated analytic argument or controlled ablation. While the reported variance reduction and downstream gains are empirical, a direct link to preserved exploration is not formally derived. In revision we will add a controlled ablation that measures response diversity (e.g., distinct n-gram coverage and entropy within groups) under centered versus non-centered estimators on the same sampling budget, thereby providing the requested isolation between variance reduction and potential suppression of useful signals. revision: yes
-
Referee: [§3.2–3.3] §3.2–3.3: while the L2O construction is stated to preserve policy-gradient unbiasedness, the dependence introduced by the max@K operator over the group means that leaving out exactly two samples must be shown to cancel the bias term exactly; the provided derivation sketch does not explicitly verify this cancellation for the finite-batch case.
Authors: We acknowledge that the derivation sketch in §3.2–3.3 is not fully expanded for the finite-batch case. The manuscript claims unbiasedness is preserved, but the explicit cancellation of the bias term induced by the max@K operator when exactly two samples are left out is only sketched. In the revision we will replace the sketch with a complete, step-by-step algebraic verification that shows the expectation of the L2O advantage estimator equals the true policy gradient for any finite group size K ≥ 2. revision: yes
Circularity Check
No significant circularity; derivation is self-contained from existing estimators and new constructions.
full rationale
The paper begins with the advantage estimator from a leading method in the field, establishes that it is policy-gradient unbiased but non-centered, then constructs a Leave-Two-Out baseline that preserves unbiasedness while enforcing exact centering on realized batch advantages. It further derives the canonical finite-batch advantage for max@K and provides an efficient implementation for MaxPO. These steps rely on standard policy-gradient theory and explicit algebraic constructions rather than fitting parameters to the target result or reducing to self-citations. No load-bearing step equates a prediction or uniqueness claim to its own inputs by definition, and the empirical verification of variance reduction is presented as an independent check. The derivation chain therefore remains independent of the final performance claims.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Finite-time analysis of the multiarmed bandit problem.Machine learning, 47(2):235–256, 2002
Peter Auer, Nicolo Cesa-Bianchi, and Paul Fischer. Finite-time analysis of the multiarmed bandit problem.Machine learning, 47(2):235–256, 2002. 10
2002
-
[2]
Farid Bagirov, Mikhail Arkhipov, Ksenia Sycheva, Evgeniy Glukhov, and Egor Bogomolov. The best of N worlds: Aligning reinforcement learning with best-of-N sampling via max@k optimisation.arXiv preprint arXiv:2510.23393, 2025
-
[3]
Chenjia Bai, Yang Zhang, Shuang Qiu, Qiaosheng Zhang, Kang Xu, and Xuelong Li. On- line preference alignment for language models via count-based exploration.arXiv preprint arXiv:2501.12735, 2025
-
[4]
Dake Bu, Wei Huang, Andi Han, Atsushi Nitanda, Bo Xue, Qingfu Zhang, Hau-San Wong, and Taiji Suzuki. Consistency is not always correct: Towards understanding the role of exploration in post-training reasoning.arXiv preprint arXiv:2511.07368, 2025
-
[5]
Exploration by Random Network Distillation
Yuri Burda, Harrison Edwards, Amos Storkey, and Oleg Klimov. Exploration by random network distillation.arXiv preprint arXiv:1810.12894, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
T., Krishnamurthy, A., and Foster, D
Fan Chen, Audrey Huang, Noah Golowich, Sadhika Malladi, Adam Block, Jordan T. Ash, Akshay Krishnamurthy, and Dylan J. Foster. The coverage principle: How pre-training enables post-training.arXiv preprint arXiv:2510.15020, 2025
-
[7]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, and Greg Brockman et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Zhipeng Chen, Xiaobo Qin, Youbin Wu, Yue Ling, Qinghao Ye, Wayne Xin Zhao, and Guang Shi. Pass@k training for adaptively balancing exploration and exploitation of large reasoning models.arXiv preprint arXiv:2508.10751, 2025
-
[9]
Daixuan Cheng, Shaohan Huang, Xuekai Zhu, Bo Dai, Xin Zhao, Zhenliang Zhang, and Furu Wei. Reasoning with exploration: An entropy perspective.Proceedings of the AAAI Conference on Artificial Intelligence, 40(36):30377–30385, 2026. doi: 10.1609/aaai.v40i36.40290
-
[10]
Deep reinforcement learning from human preferences
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[11]
Beyond variance reduction: Understanding the true impact of baselines on policy optimization
Wesley Chung, Valentin Thomas, Marlos C Machado, and Nicolas Le Roux. Beyond variance reduction: Understanding the true impact of baselines on policy optimization. InInternational conference on machine learning, pages 1999–2009. PMLR, 2021
1999
-
[12]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Weight ensembling improves reasoning in language models
Xingyu Dang, Christina Baek, Kaiyue Wen, Zico Kolter, and Aditi Raghunathan. Weight ensembling improves reasoning in language models. InSecond Conference on Language Modeling, 2025
2025
-
[15]
Jingtong Gao, Ling Pan, Yejing Wang, Rui Zhong, Chi Lu, Qingpeng Cai, Peng Jiang, and Xiangyu Zhao. Navigate the unknown: Enhancing LLM reasoning with intrinsic motivation guided exploration.arXiv preprint arXiv:2505.17621, 2025
-
[16]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, and Alex Vaughan et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Variance reduction techniques for gradient estimates in reinforcement learning.Journal of Machine Learning Research, 5(Nov): 1471–1530, 2004
Evan Greensmith, Peter L Bartlett, and Jonathan Baxter. Variance reduction techniques for gradient estimates in reinforcement learning.Journal of Machine Learning Research, 5(Nov): 1471–1530, 2004. 11
2004
-
[18]
MuProp: Unbiased Backpropagation for Stochastic Neural Networks
Shixiang Gu, Sergey Levine, Ilya Sutskever, and Andriy Mnih. Muprop: Unbiased backpropa- gation for stochastic neural networks.arXiv preprint arXiv:1511.05176, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[19]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, and Xiao Bi et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Andre He, Daniel Fried, and Sean Welleck. Rewarding the unlikely: Lifting GRPO beyond distribution sharpening.arXiv preprint arXiv:2506.02355, 2025
-
[21]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[22]
A class of statistics with asymptotically normal distribution
Wassily Hoeffding. A class of statistics with asymptotically normal distribution. InBreak- throughs in statistics: Foundations and basic theory, pages 308–334. Springer, 1992
1992
-
[23]
Emergent Slow Thinking in LLMs as Inverse Tree Freezing
Sihan Hu, Xiansheng Cai, Yuan Huang, Zhiyuan Yao, Linfeng Zhang, Pan Zhang, Youjin Deng, and Kun Chen. Emergent slow thinking in LLMs as inverse tree freezing.arXiv preprint arXiv:2509.23629, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Rethinking entropy regularization in large reasoning models.arXiv preprint arXiv:2509.25133, 2025
Yuxian Jiang, Yafu Li, Guanxu Chen, Dongrui Liu, Yu Cheng, and Jing Shao. Rethinking entropy regularization in large reasoning models.arXiv preprint arXiv:2509.25133, 2025
-
[25]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Emergence of exploration in policy gradient reinforcement learning via resetting, 2023
Sotetsu Koyamada, Paavo Parmas, Tadashi Kozuno, and Shin Ishii. Emergence of exploration in policy gradient reinforcement learning via resetting, 2023. URL https://openreview.net/forum? id=GKsNIC_mQRG
2023
-
[27]
Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Christopher Wilhelm, Luca Soldaini, Noah A
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James Validad Miranda, Alisa Liu, Nouha Dziri, Xinxi Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Christopher Wilhelm, Luca Soldaini, Noah A. Smith, Yizhong Wang, Pradeep Dasigi, and Hannaneh...
2025
-
[28]
Solving quantitative reasoning problems with language models
Aitor Lewkowycz, Anders Johan Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Venkatesh Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving quantitative reasoning problems with language models. InAdvances in Neural Information Processing Systems, 2022
2022
-
[29]
Tianjian Li, Yiming Zhang, Ping Yu, Swarnadeep Saha, Daniel Khashabi, Jason Weston, Jack Lanchantin, and Tianlu Wang. Jointly reinforcing diversity and quality in language model generations.arXiv preprint arXiv:2509.02534, 2025
-
[30]
Zhenwen Liang, Sidi Lu, Wenhao Yu, Kishan Panaganti, Yujun Zhou, Haitao Mi, and Dong Yu. Can LLMs guide their own exploration? gradient-guided reinforcement learning for LLM reasoning.arXiv preprint arXiv:2512.15687, 2025
-
[31]
Understanding r1-zero-like training: A critical perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective. InConference on Language Modeling (COLM), 2025
2025
-
[32]
RL squeezes, SFT expands: A comparative study of reasoning LLMs
Kohsei Matsutani, Shota Takashiro, Gouki Minegishi, Takeshi Kojima, Yusuke Iwasawa, and Yutaka Matsuo. RL squeezes, SFT expands: A comparative study of reasoning LLMs. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[33]
The role of baselines in policy gradient optimization.Advances in Neural Information Processing Systems, 35:17818–17830, 2022
Jincheng Mei, Wesley Chung, Valentin Thomas, Bo Dai, Csaba Szepesvari, and Dale Schuur- mans. The role of baselines in policy gradient optimization.Advances in Neural Information Processing Systems, 35:17818–17830, 2022. 12
2022
-
[34]
Variational inference for monte carlo objectives
Andriy Mnih and Danilo Rezende. Variational inference for monte carlo objectives. In International Conference on Machine Learning, pages 2188–2196. PMLR, 2016
2016
-
[35]
Asynchronous methods for deep reinforce- ment learning
V olodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforce- ment learning. InInternational conference on machine learning, pages 1928–1937. PmLR, 2016
1928
-
[36]
Emergence of exploration in policy gradient reinforcement learning via retrying
Soichiro Nishimori, Paavo Parmas, Sotetsu Koyamada, Tadashi Kozuno, Toshinori Kitamura, Shin Ishii, and Yutaka Matsuo. Emergence of exploration in policy gradient reinforcement learning via retrying. InForty-third International Conference on Machine Learning, 2026. URL https://openreview.net/forum?id=NpvBAOc87E
2026
-
[37]
OpenAI, Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. OpenAI o1 system card. arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Total stochastic gradient algorithms and applications in reinforcement learning
Paavo Parmas. Total stochastic gradient algorithms and applications in reinforcement learning. Advances in Neural Information Processing Systems, 31, 2018
2018
-
[39]
A unified view of likelihood ratio and reparameterization gradients
Paavo Parmas and Masashi Sugiyama. A unified view of likelihood ratio and reparameterization gradients. InInternational Conference on Artificial Intelligence and Statistics, pages 4078–4086. PMLR, 2021
2021
-
[40]
PIPPS: Flexible model- based policy search robust to the curse of chaos
Paavo Parmas, Carl Edward Rasmussen, Jan Peters, and Kenji Doya. PIPPS: Flexible model- based policy search robust to the curse of chaos. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning, volume 80 ofPro- ceedings of Machine Learning Research, pages 4065–4074. PMLR, 10–15 Jul 2018. URL https:...
2018
-
[41]
Beyond the Sampled Token: Preserving Candidate Support in RLVR
Ruotian Peng, Yi Ren, Zhouliang Yu, Weiyang Liu, and Yandong Wen. SimKO: Simple Pass@K policy optimization.arXiv preprint arXiv:2510.14807, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Reinforcement learning of motor skills with policy gradients
Jan Peters and Stefan Schaal. Reinforcement learning of motor skills with policy gradients. Neural networks, 21(4):682–697, 2008
2008
-
[43]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[44]
Y ., Snell, C., Greer, J., Wu, I., Smith, V ., Simchowitz, M., and Kumar, A
Amrith Setlur, Matthew YR Yang, Charlie Snell, Jeremy Greer, Ian Wu, Virginia Smith, Max Simchowitz, and Aviral Kumar. e3: Learning to explore enables extrapolation of test-time compute for LLMs.arXiv preprint arXiv:2506.09026, 2025
-
[45]
Darsh J Shah, Peter Rushton, Somanshu Singla, Mohit Parmar, Kurt Smith, Yash Vanjani, Ashish Vaswani, Adarsh Chaluvaraju, Andrew Hojel, Andrew Ma, Anil Thomas, Anthony Polloreno, Ashish Tanwer, Burhan Drak Sibai, Divya S Mansingka, Divya Shivaprasad, Ishaan Shah, Karl Stratos, Khoi Nguyen, Michael Callahan, Michael Pust, Mrinal Iyer, Philip Monk, Platon M...
-
[46]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
On entropy control in LLM-RL algorithms
Han Shen. On entropy control in LLM-RL algorithms. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[48]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. HybridFlow: A flexible and efficient RLHF framework. arXiv preprint arXiv:2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Outcome-based exploration for LLM reasoning
Yuda Song, Julia Kempe, and Remi Munos. Outcome-based exploration for LLM reasoning. arXiv preprint arXiv:2509.06941, 2025. 13
-
[50]
Kakade, Dean Foster, and Udaya Ghai
Yuda Song, Hanlin Zhang, Carson Eisenach, Sham M. Kakade, Dean Foster, and Udaya Ghai. Mind the gap: Examining the self-improvement capabilities of large language models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[51]
Optimizing language models for inference time objectives using reinforcement learning
Yunhao Tang, Kunhao Zheng, Gabriel Synnaeve, and Remi Munos. Optimizing language models for inference time objectives using reinforcement learning. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 59066–59085. PMLR, 2025
2025
-
[52]
Rebar: Low-variance, unbiased gradient estimates for discrete latent variable models.Advances in Neural Information Processing Systems, 30, 2017
George Tucker, Andriy Mnih, Chris J Maddison, John Lawson, and Jascha Sohl-Dickstein. Rebar: Low-variance, unbiased gradient estimates for discrete latent variable models.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[53]
J., Krishnamurthy, A., and Ash, J
Jens Tuyls, Dylan J Foster, Akshay Krishnamurthy, and Jordan T Ash. Representation-based ex- ploration for language models: From test-time to post-training.arXiv preprint arXiv:2510.11686, 2025
-
[54]
Pass@K policy optimization: Solving harder reinforcement learning problems.Advances in Neural Information Processing Systems, 38: 152416–152445, 2025
Christian Walder and Deep Tejas Karkhanis. Pass@K policy optimization: Solving harder reinforcement learning problems.Advances in Neural Information Processing Systems, 38: 152416–152445, 2025
2025
-
[55]
Zengzhi Wang, Fan Zhou, Xuefeng Li, and Pengfei Liu. OctoThinker: Mid-training incentivizes reinforcement learning scaling.arXiv preprint arXiv:2506.20512, 2025
-
[56]
The Optimal Reward Baseline for Gradient-Based Reinforcement Learning
Lex Weaver and Nigel Tao. The optimal reward baseline for gradient-based reinforcement learning.arXiv preprint arXiv:1301.2315, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[57]
Xumeng Wen, Zihan Liu, Shun Zheng, Zhijian Xu, Shengyu Ye, Zhirong Wu, Xiao Liang, Yang Wang, Junjie Li, Ziming Miao, Jiang Bian, and Mao Yang. Reinforcement learning with verifiable rewards implicitly incentivizes correct reasoning in base LLMs.arXiv preprint arXiv:2506.14245, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine Learning, 8(3):229–256, May 1992
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine Learning, 8(3):229–256, May 1992
1992
-
[59]
Variance Reduction for Policy Gradient with Action-Dependent Factorized Baselines
Cathy Wu, Aravind Rajeswaran, Yan Duan, Vikash Kumar, Alexandre M Bayen, Sham Kakade, Igor Mordatch, and Pieter Abbeel. Variance reduction for policy gradient with action-dependent factorized baselines.arXiv preprint arXiv:1803.07246, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[60]
The invisible leash: Why RLVR may or may not escape its origin.arXiv preprint arXiv:2507.14843, 2025
Fang Wu, Weihao Xuan, Ximing Lu, Mingjie Liu, Yi Dong, Zaid Harchaoui, and Yejin Choi. The invisible leash: Why RLVR may or may not escape its origin.arXiv preprint arXiv:2507.14843, 2025
-
[61]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. Qwen2.5-math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, and Chenxu Lv et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Zhaoning Yu, Will Su, Leitian Tao, Haozhu Wang, Aashu Singh, Hanchao Yu, Jianyu Wang, Hongyang Gao, Weizhe Yuan, Jason Weston, Ping Yu, and Jing Xu. RESTRAIN: From spurious votes to signals – self-driven rl with self-penalization.arXiv preprint arXiv:2510.02172, 2025. 14
-
[65]
Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[66]
Charlie Zhang, Graham Neubig, and Xiang Yue. On the interplay of pre-training, mid-training, and rl on reasoning language models.arXiv preprint arXiv:2512.07783, 2025
-
[67]
Shenao Zhang, Donghan Yu, Yihao Feng, Bowen Jin, Zhaoran Wang, John Peebles, and Zirui Wang. Learning to reason as action abstractions with scalable mid-training rl.arXiv preprint arXiv:2509.25810, 2025
-
[68]
Echo chamber: Rl post-training amplifies behaviors learned in pretraining
Rosie Zhao, Alexandru Meterez, Sham Kakade, Cengiz Pehlevan, Samy Jelassi, and Eran Malach. Echo chamber: Rl post-training amplifies behaviors learned in pretraining. InSecond Conference on Language Modeling, 2025
2025
-
[69]
Haizhong Zheng, Yang Zhou, Brian R Bartoldson, Bhavya Kailkhura, Fan Lai, Jiawei Zhao, and Beidi Chen. Act only when it pays: Efficient reinforcement learning for LLM reasoning via selective rollouts.arXiv preprint arXiv:2506.02177, 2025
-
[70]
First return, entropy-eliciting explore
Tianyu Zheng, Tianshun Xing, Qingshui Gu, Taoran Liang, Xingwei Qu, Xin Zhou, Yizhi Li, Zhoufutu Wen, Chenghua Lin, Wenhao Huang, et al. First return, entropy-eliciting explore. arXiv preprint arXiv:2507.07017, 2025
-
[71]
Yujun Zhou, Zhenwen Liang, Haolin Liu, Wenhao Yu, Kishan Panaganti, Linfeng Song, Dian Yu, Xiangliang Zhang, Haitao Mi, and Dong Yu. Evolving language models without labels: Majority drives selection, novelty promotes variation.arXiv preprint arXiv:2509.15194, 2025. 15 A Additional Related Work A.1 RLVR in LLMs Reinforcement learning with verifiable rewar...
-
[72]
[29] employed a semantic diversity score with an external semantic comparator, and Tuyls et al
augmented training with a semantic novelty score computed from embeddings, Li et al. [29] employed a semantic diversity score with an external semantic comparator, and Tuyls et al. [53] computed a representation-based novelty score from hidden states to boost exploration. Liang et al
-
[73]
Setlur et al
leveraged reward-model gradients to improve temperature sampling. Setlur et al. [44] promoted in-context exploration via skill asymmetries and negative gradients, enabling reliable extrapolation with increased test-time compute. Other studies directly optimize the pass@K metric; these are discussed in App. A.4. A.3 Policy Gradient Estimator and Baseline P...
-
[74]
" " Com pu te s bi no mi al c o e f f i c i e n t C (n , k ) in log - space
and A3C [35]. In domains involving discrete latent variables or sequence generation, where learning a separate value function is often unstable or costly,sample-based baselineshave become the dominant approach. This concept was further refined in the context of variational inference by Mnih and Rezende[34] (VIMCO) and Gu et al. [18], which utilize the ave...
-
[75]
BoN mean
Connection to ui: Every K-subset I⊆ B with i∈I can be written as {i} ∪S where |S|=K−1. Thus: S(i, K,B) = B−1 K−1 B K ui = K B ui.(83) 2.Connection tov i: Consider the sum over the reduced poolU=B \ {i}: X j∈U S(j, K, U) = 1B−1 K X I⊆U,|I|=K X j∈I 1 M(I) =Kv i,(84) since eachK-subsetIcontains exactlyKindicesj. Dividing byB−1yields: 1 B−1 X j̸=i S(j,...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.