RASFT: Rollout-Adaptive Supervised Fine-Tuning for Reasoning
Pith reviewed 2026-06-27 22:23 UTC · model grok-4.3
The pith
RASFT improves LLM reasoning by adjusting expert imitation strength per problem using the model's own verified rollouts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
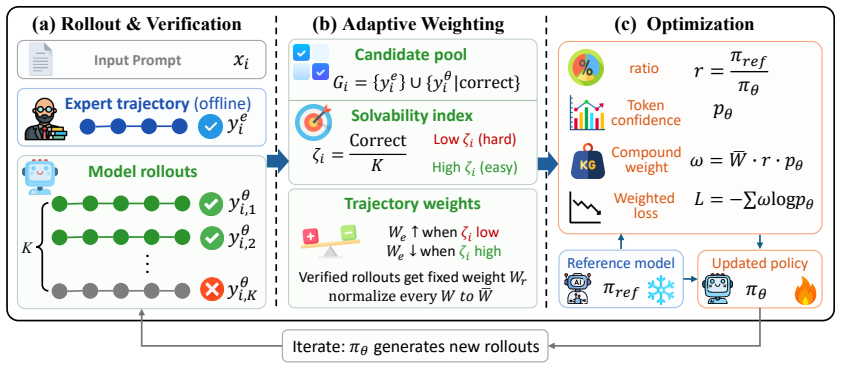
RASFT is a policy-aware SFT framework that calibrates expert supervision according to problem-level solvability estimated from verified on-policy rollouts. For each problem, RASFT strengthens expert guidance when the current policy struggles, while relaxing rigid imitation and incorporating correct self-generated trajectories when the model already exhibits reliable reasoning behavior. To preserve useful reasoning priors, RASFT further introduces a clipped inverse ratio between the frozen reference model and the current policy to constrain excessive policy drift.
What carries the argument
problem-level solvability estimated from verified on-policy rollouts, which dynamically scales the weight of expert trajectories and decides whether to accept self-generated correct solutions.
If this is right
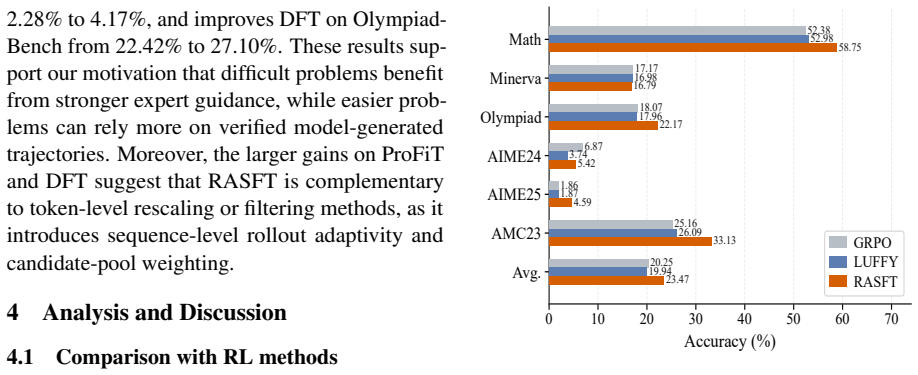
- RASFT produces higher overall accuracy than standard SFT and SFT variants on mathematical and code reasoning tasks.
- The method outperforms representative RL baselines while remaining within a supervised fine-tuning regime.
- The clipped inverse-ratio term keeps policy updates from erasing useful reasoning behavior learned in pre-training.
- Correct trajectories generated by the model itself are retained as training targets when the policy already solves the problem reliably.
Where Pith is reading between the lines
- The same per-problem adaptation logic could be applied to non-reasoning tasks where fixed imitation risks overwriting model capabilities.
- Because the method only needs on-policy samples that are already generated during training, it may reduce the volume of external expert data required.
- The approach offers a middle ground between pure SFT and full RL that could be combined with existing preference or reward-model techniques.
Load-bearing premise
Problem-level solvability estimated from verified on-policy rollouts provides a reliable, unbiased signal for dynamically calibrating the strength of expert supervision without introducing training instability or selection artifacts.
What would settle it
Training identical models with the same expert data but replacing the rollout-derived solvability signal by a random or constant value and observing no accuracy gain on the same benchmarks would show that the adaptive calibration is not responsible for the reported improvement.
Figures
read the original abstract
Supervised fine-tuning (SFT) is a prevailing method for adapting large language models to reasoning tasks by imitating offline expert demonstrations, often treating a single expert trajectory as the target behavior. However, reasoning is not simple path imitation: rigidly following one demonstrated solution may overfit to surface forms and suppress the model's own reasoning distribution. We propose Rollout-Adaptive Supervised Fine-Tuning (RASFT), a policy-aware SFT framework that calibrates expert supervision according to problem-level solvability estimated from verified on-policy rollouts. For each problem, RASFT strengthens expert guidance when the current policy struggles, while relaxing rigid imitation and incorporating correct self-generated trajectories when the model already exhibits reliable reasoning behavior. To preserve useful reasoning priors, RASFT further introduces a clipped inverse ratio between the frozen reference model and the current policy to constrain excessive policy drift. Experiments across multiple models on six mathematical reasoning benchmarks and two code reasoning benchmarks show that RASFT achieves better overall performance than SFT, SFT variants, and representative RL methods. The code is available at https://github.com/zjd1sq/RASFT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Rollout-Adaptive Supervised Fine-Tuning (RASFT), a policy-aware variant of SFT for reasoning tasks. For each problem, RASFT estimates solvability from verified on-policy rollouts and uses this signal to strengthen expert imitation on hard problems while relaxing imitation and incorporating correct self-generated trajectories on problems the current policy already solves reliably. A clipped inverse-ratio term between the reference model and current policy is added to bound drift. The abstract states that experiments on multiple models across six mathematical reasoning benchmarks and two code reasoning benchmarks show RASFT outperforming SFT, SFT variants, and representative RL methods.
Significance. If the reported gains are robust, RASFT would provide a concrete mechanism for making SFT adaptive to the model's evolving capabilities without full RL, potentially improving sample efficiency on reasoning tasks. The public release of code at https://github.com/zjd1sq/RASFT is a clear strength that supports reproducibility and further investigation.
major comments (2)
- [Method description of solvability estimation and adaptive weighting] The central performance claim rests on the reliability of the per-problem solvability signal derived from finite verified on-policy rollouts. On hard problems the success-rate estimator necessarily has high variance; the manuscript provides no analysis, ablation, or stability diagnostics showing that this variance does not produce erratic supervision weights or selection artifacts across training iterations.
- [Description of the clipped inverse-ratio term and its integration with rollout-based weighting] The interaction between the adaptive weighting and the clipped inverse-ratio term is presented as stabilizing policy drift, yet no derivation or empirical check demonstrates that the combination prevents the on-policy conditioning from introducing systematic bias in the supervision signal.
minor comments (1)
- [Abstract] The abstract asserts superior performance but contains no numerical results, dataset sizes, or statistical details; moving at least the headline numbers into the abstract would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the reliability of the solvability signal and the interaction of the drift constraint. We respond to each major comment below.
read point-by-point responses
-
Referee: The central performance claim rests on the reliability of the per-problem solvability signal derived from finite verified on-policy rollouts. On hard problems the success-rate estimator necessarily has high variance; the manuscript provides no analysis, ablation, or stability diagnostics showing that this variance does not produce erratic supervision weights or selection artifacts across training iterations.
Authors: We agree that finite rollouts can produce high variance in the solvability estimate on hard problems and that the manuscript lacks explicit stability diagnostics. To address this directly, we will add an ablation varying the number of rollouts (4 vs. 8) and report weight variance across iterations in the revised version. revision: yes
-
Referee: The interaction between the adaptive weighting and the clipped inverse-ratio term is presented as stabilizing policy drift, yet no derivation or empirical check demonstrates that the combination prevents the on-policy conditioning from introducing systematic bias in the supervision signal.
Authors: The clipped inverse-ratio term follows standard importance-sampling bounds to limit drift from the reference policy. While we provide no formal derivation of the joint effect, the reported results show consistent gains without degradation indicative of bias. We will add an empirical policy-drift analysis (KL and success-rate trends) with and without the term in the revision. revision: yes
Circularity Check
No circularity: RASFT performance claims rest on external benchmarks, not definitional reduction
full rationale
The paper defines RASFT via on-policy rollout solvability estimates and a clipped inverse-ratio term to a frozen reference model, then reports empirical gains on six math and two code benchmarks against SFT and RL baselines. No equations reduce the reported performance to a fitted quantity or self-generated signal by construction; the evaluation uses held-out benchmarks independent of the training signal. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the derivation. This is the normal non-circular case for an empirical method paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year =
On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification , author =. International Conference on Learning Representations , year =. doi:10.48550/arXiv.2508.05629 , url =. 2508.05629 , archivePrefix =
-
[2]
International Conference on Learning Representations , year =
Anchored Supervised Fine-Tuning , author =. International Conference on Learning Representations , year =. doi:10.48550/arXiv.2509.23753 , url =. 2509.23753 , archivePrefix =
-
[3]
ProFit: Leveraging High-Value Signals in SFT via Probability-Guided Token Selection
ProFit: Leveraging High-Value Signals in SFT via Probability-Guided Token Selection , author =. arXiv preprint arXiv:2601.09195 , year =. doi:10.48550/arXiv.2601.09195 , url =. 2601.09195 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.09195
-
[4]
Wang, Xiaoxuan and Zhang, Han and Wang, Haixin and Shi, Yidan and Li, Ruoyan and Han, Kaiqiao and Tong, Chenyi and Deng, Haoran and Sun, Renliang and Taylor, Alexander and Zhu, Yanqiao and Cong, Jason and Sun, Yizhou and Wang, Wei , journal =. 2026 , eprint =. doi:10.48550/arXiv.2602.21534 , url =
-
[5]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
arXiv preprint arXiv:2512.02556 , year =. doi:10.48550/arXiv.2512.02556 , url =. 2512.02556 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.02556
-
[6]
arXiv preprint arXiv:2503.02951 , year =
KodCode: A Diverse, Challenging, and Verifiable Synthetic Dataset for Coding , author =. arXiv preprint arXiv:2503.02951 , year =. doi:10.48550/arXiv.2503.02951 , url =. 2503.02951 , archivePrefix =
-
[7]
Li, Jia and Beeching, Edward and Tunstall, Lewis and Lipkin, Ben and Soletskyi, Roman and Huang, Shengyi Costa and Rasul, Kashif and Yu, Longhui and Jiang, Albert and Shen, Ziju and Qin, Zihan and Dong, Bin and Zhou, Li and Fleureau, Yann and Lample, Guillaume and Polu, Stanislas , year =
-
[8]
Let's Verify Step by Step , author =. arXiv preprint arXiv:2305.20050 , year =. doi:10.48550/arXiv.2305.20050 , url =. 2305.20050 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.20050
-
[9]
Solving Quantitative Reasoning Problems with Language Models
Solving Quantitative Reasoning Problems with Language Models , author =. arXiv preprint arXiv:2206.14858 , year =. doi:10.48550/arXiv.2206.14858 , url =. 2206.14858 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2206.14858
-
[10]
OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year =. doi:10.48550/arXiv.2402.14008 , url =. 2402.14008 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.14008
-
[11]
2024 , howpublished =
2024
-
[12]
2025 , howpublished =
2025
-
[13]
2023 , howpublished =
2023
-
[14]
Program Synthesis with Large Language Models
Program Synthesis with Large Language Models , author =. arXiv preprint arXiv:2108.07732 , year =. doi:10.48550/arXiv.2108.07732 , url =. 2108.07732 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2108.07732
-
[15]
Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code , author =. arXiv preprint arXiv:2107.03374 , year =. doi:10.48550/arXiv.2107.03374 , url =. 2107.03374 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2107.03374
-
[16]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems , year =. doi:10.48550/arXiv.2201.11903 , url =. 2201.11903 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2201.11903
-
[17]
WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct
WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct , author =. International Conference on Learning Representations , year =. doi:10.48550/arXiv.2308.09583 , url =. 2308.09583 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.09583
-
[18]
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models , author =. International Conference on Learning Representations , year =. doi:10.48550/arXiv.2309.12284 , url =. 2309.12284 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.12284
-
[19]
InfoSFT: Learn More and Forget Less with Information-Aware Token Weighting
InfoSFT: Learn More and Forget Less with Information-Aware Token Weighting , author =. arXiv preprint arXiv:2605.14967 , year =. doi:10.48550/arXiv.2605.14967 , url =. 2605.14967 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.14967
-
[20]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training , author =. International Conference on Machine Learning , year =. doi:10.48550/arXiv.2501.17161 , url =. 2501.17161 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.17161
-
[21]
arXiv preprint arXiv:1707.06347 , year=
Proximal Policy Optimization Algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[22]
Proximal Supervised Fine-Tuning
Proximal Supervised Fine-Tuning , author =. arXiv preprint arXiv:2508.17784 , year =. doi:10.48550/arXiv.2508.17784 , url =. 2508.17784 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.17784
-
[23]
Good SFT Optimizes for SFT, Better SFT Prepares for Reinforcement Learning
Good SFT Optimizes for SFT, Better SFT Prepares for Reinforcement Learning , author =. arXiv preprint arXiv:2602.01058 , year =. doi:10.48550/arXiv.2602.01058 , url =. 2602.01058 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.01058
-
[24]
arXiv preprint arXiv:2412.19437 , year =. doi:10.48550/arXiv.2412.19437 , url =. 2412.19437 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.19437
-
[25]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
arXiv preprint arXiv:2501.12948 , year =. doi:10.48550/arXiv.2501.12948 , url =. 2501.12948 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948
-
[26]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Yang, An and Zhang, Beichen and Hui, Binyuan and Gao, Bofei and Yu, Bowen and Li, Chengpeng and Liu, Dayiheng and Tu, Jianhong and Zhou, Jingren and Lin, Junyang and Lu, Keming and Xue, Mingfeng and Lin, Runji and Liu, Tianyu and Ren, Xingzhang and Zhang, Zhenru , journal =. 2024 , eprint =. doi:10.48550/arXiv.2409.12122 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.12122 2024
-
[27]
Solving math word problems with process- and outcome-based feedback
Solving Math Word Problems with Process- and Outcome-Based Feedback , author =. arXiv preprint arXiv:2211.14275 , year =. doi:10.48550/arXiv.2211.14275 , url =. 2211.14275 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2211.14275
-
[28]
Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations , author =. arXiv preprint arXiv:2312.08935 , year =. doi:10.48550/arXiv.2312.08935 , url =. 2312.08935 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.08935
-
[29]
arXiv preprint arXiv:2408.06195 , year =
Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers , author =. arXiv preprint arXiv:2408.06195 , year =. doi:10.48550/arXiv.2408.06195 , url =. 2408.06195 , archivePrefix =
-
[30]
Reinforced Self-Training (ReST) for Language Modeling
Gulcehre, Caglar and Paine, Tom Le and Srinivasan, Srivatsan and Konyushkova, Ksenia and Weerts, Lotte and Sharma, Abhishek and Siddhant, Aditya and Ahern, Alex and Wang, Miaosen and Gu, Chenjie and Macherey, Wolfgang and Doucet, Arnaud and Firat, Orhan and de Freitas, Nando , journal =. Reinforced Self-Training. 2023 , eprint =. doi:10.48550/arXiv.2308.0...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.08998 2023
-
[31]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author =. arXiv preprint arXiv:2402.03300 , year =. doi:10.48550/arXiv.2402.03300 , url =. 2402.03300 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300
-
[32]
Learning to Reason under Off-Policy Guidance
Learning to Reason under Off-Policy Guidance , author =. arXiv preprint arXiv:2504.14945 , year =. doi:10.48550/arXiv.2504.14945 , url =. 2504.14945 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.14945
-
[33]
Qwen2.5 Technical Report , author =. arXiv preprint arXiv:2412.15115 , year =. doi:10.48550/arXiv.2412.15115 , url =. 2412.15115 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115
-
[34]
2024 , month = sep, day =
Llama 3.2: Revolutionizing Edge AI and Vision with Open, Customizable Models , author =. 2024 , month = sep, day =
2024
-
[35]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author =. arXiv preprint arXiv:2110.14168 , year =. doi:10.48550/arXiv.2110.14168 , url =. 2110.14168 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2110.14168
-
[36]
Scaling Relationship on Learning Mathematical Reasoning with Large Language Models
Scaling Relationship on Learning Mathematical Reasoning with Large Language Models , author =. arXiv preprint arXiv:2308.01825 , year =. doi:10.48550/arXiv.2308.01825 , url =. 2308.01825 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.01825
-
[37]
Zelikman, Eric and Wu, Yuhuai and Mu, Jesse and Goodman, Noah D. , booktitle =. 2022 , eprint =. doi:10.48550/arXiv.2203.14465 , url =
-
[38]
Journal of Machine Learning Research , volume =
Scaling Instruction-Finetuned Language Models , author =. Journal of Machine Learning Research , volume =. 2024 , eprint =
2024
-
[39]
Orca: Progressive Learning from Complex Explanation Traces of GPT-4
Mukherjee, Subhabrata and Mitra, Arindam and Jawahar, Ganesh and Agarwal, Sahaj and Palangi, Hamid and Awadallah, Ahmed , journal =. Orca: Progressive Learning from Complex Explanation Traces of. 2023 , eprint =. doi:10.48550/arXiv.2306.02707 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.02707 2023
-
[40]
MAmmoTH: Building Math Generalist Models through Hybrid Instruction Tuning
Yue, Xiang and Qu, Xingwei and Zhang, Ge and Fu, Yao and Huang, Wenhao and Sun, Huan and Su, Yu and Chen, Wenhu , journal =. 2023 , eprint =. doi:10.48550/arXiv.2309.05653 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.05653 2023
-
[41]
Training language models to follow instructions with human feedback
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems , year =. doi:10.48550/arXiv.2203.02155 , url =. 2203.02155 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.02155
-
[42]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , pages =
Self-Instruct: Aligning Language Models with Self-Generated Instructions , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , pages =. 2023 , doi =
2023
-
[43]
LIMA: Less Is More for Alignment
Zhou, Chunting and Liu, Pengfei and Xu, Puxin and Iyer, Srini and Sun, Jiao and Mao, Yuning and Ma, Xuezhe and Efrat, Avia and Yu, Ping and Yu, Lili and Zhang, Susan and Ghosh, Gargi and Lewis, Mike and Zettlemoyer, Luke and Levy, Omer , booktitle =. 2023 , eprint =. doi:10.48550/arXiv.2305.11206 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.11206 2023
-
[44]
Measuring Mathematical Problem Solving With the MATH Dataset
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , booktitle =. Measuring Mathematical Problem Solving With the. 2021 , eprint =. doi:10.48550/arXiv.2103.03874 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2103.03874 2021
-
[45]
Learning to summarize from human feedback
Learning to Summarize from Human Feedback , author =. Advances in Neural Information Processing Systems , year =. doi:10.48550/arXiv.2009.01325 , url =. 2009.01325 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2009.01325 2009
-
[46]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback , author =. arXiv preprint arXiv:2204.05862 , year =. doi:10.48550/arXiv.2204.05862 , url =. 2204.05862 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2204.05862
-
[47]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
Large Language Models are not Fair Evaluators , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , doi =
2024
-
[48]
International Conference on Learning Representations , year =
Evaluating Large Language Models at Evaluating Instruction Following , author =. International Conference on Learning Representations , year =. doi:10.48550/arXiv.2310.07641 , url =. 2310.07641 , archivePrefix =
-
[49]
Measuring Coding Challenge Competence With APPS
Hendrycks, Dan and Basart, Steven and Kadavath, Saurav and Mazeika, Mantas and Arora, Akul and Guo, Ethan and Burns, Collin and Puranik, Samir and He, Horace and Song, Dawn and Steinhardt, Jacob , booktitle =. Measuring Coding Challenge Competence With. 2021 , eprint =. doi:10.48550/arXiv.2105.09938 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2105.09938 2021
-
[50]
and Robson, Esme and Kohli, Pushmeet and de Freitas, Nando and Kavukcuoglu, Koray and Vinyals, Oriol , journal =
Li, Yujia and Choi, David and Chung, Junyoung and Kushman, Nate and Schrittwieser, Julian and Leblond, Rémi and Eccles, Tom and Keeling, James and Gimeno, Felix and Dal Lago, Agustin and Hubert, Thomas and Choy, Peter and de Masson d'Autume, Cyprien and Babuschkin, Igor and Chen, Xinyun and Huang, Po-Sen and Welbl, Johannes and Gowal, Sven and Cherepanov,...
2022
-
[51]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , booktitle =. Judging. 2023 , eprint =. doi:10.48550/arXiv.2306.05685 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.05685 2023
-
[52]
2023 , doi =
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , booktitle =. 2023 , doi =
2023
-
[53]
Qwen2.5-Coder Technical Report
Hui, Binyuan and Yang, Jian and Cui, Zeyu and Yang, Jiaxi and Liu, Dayiheng and Zhang, Lei and Liu, Tianyu and Zhang, Jiajun and Yu, Bowen and Lu, Keming and Dang, Kai and Fan, Yang and Zhang, Yichang and Yang, An and Men, Rui and Huang, Fei and Zheng, Bo and Miao, Yibo and Quan, Shanghaoran and Feng, Yunlong and Ren, Xingzhang and Ren, Xuancheng and Zhou...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.12186 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.