RoboNaldo: Accurate, Stable and Powerful Humanoid Soccer Shooting via Motion-Guided Curriculum Reinforcement Learning
Pith reviewed 2026-06-27 13:03 UTC · model grok-4.3
The pith
A three-stage curriculum RL method lets humanoid robots learn accurate powerful soccer shooting from one fixed human kick reference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
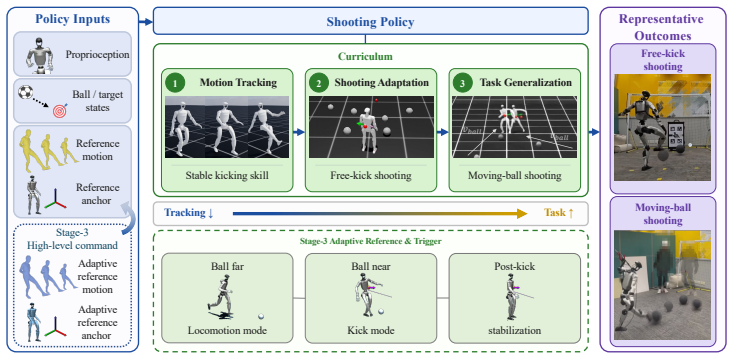
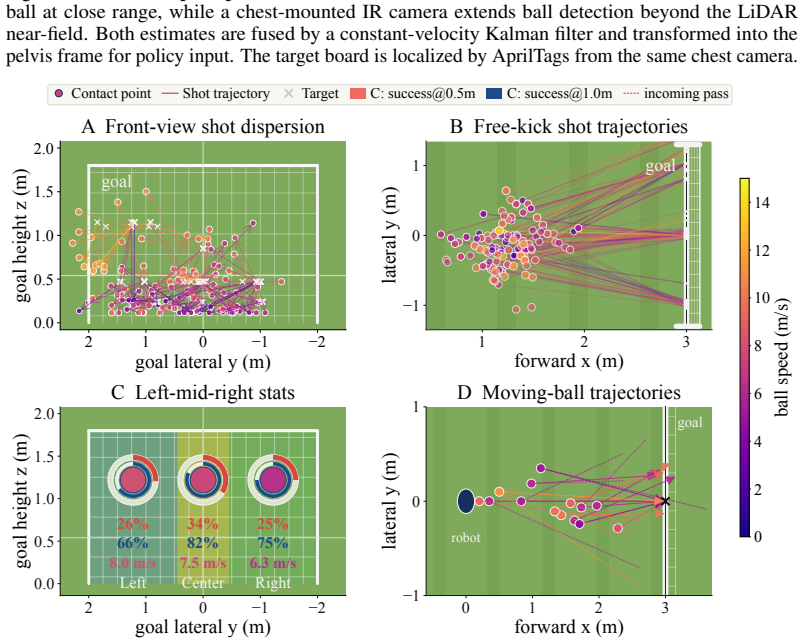
RoboNaldo is a three-stage motion-guided curriculum reinforcement learning framework that employs one fixed human-kick reference motion as a scaffold. Optimization first produces a stable whole-body kicking prior, then shifts toward task performance on free-kick scenarios with stationary balls at random positions, and finally extends the policy to moving-ball shooting through a locomotion-command and kick-trigger interface controlled by a high-level heuristic planner during training. Alternative high-level controllers can substitute for the planner at inference time. In simulation this yields free-kick shot error 48.6 percent lower and shoot velocity 2.96 times higher than prior baselines; o
What carries the argument
The three-stage motion-guided curriculum RL framework that progressively relaxes a single human-kick reference motion from a stable prior into task-optimized free-kick and moving-ball behaviors.
If this is right
- The low-level policy remains compatible with alternative high-level controllers at deployment time.
- The same curriculum progression produces policies that generalize from simulation to real-world stationary and moving-ball shooting.
- Whole-body stability and high impulse are retained while accuracy and velocity are improved through progressive task reward weighting.
- The approach supports both free-kick and moving-ball scenarios using the same trained policy.
Where Pith is reading between the lines
- The scaffolding technique could be reused for other high-impulse whole-body skills such as throwing or catching on humanoid platforms.
- Reliance on a single reference motion may lower the data-collection burden compared with methods that require many expert demonstrations.
- Integration of the low-level policy with onboard perception opens a path toward fully autonomous dynamic interaction tasks beyond soccer.
- Testing the same curriculum on robots with different morphologies would reveal how much of the learned behavior is hardware-specific.
Load-bearing premise
One fixed human-kick reference motion supplies a scaffold whose optimization can be shifted across three curriculum stages without losing stability or the ability to generalize to random stationary and moving ball conditions.
What would settle it
A non-curriculum policy trained from scratch or from the same reference without staged progression that nevertheless reaches comparable shot accuracy, velocity, and real-world transfer on the Unitree G1 would falsify the necessity of the motion-guided curriculum.
Figures


read the original abstract
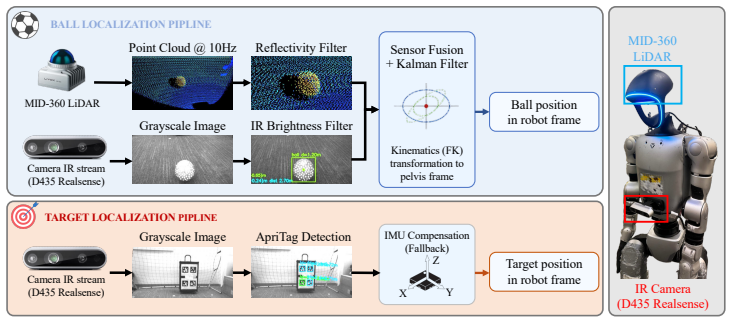
Elite humanoid soccer shooting requires whole-body stability, high-impulse whole-body interactions, and accuracy to targets. Motion tracking-driven reinforcement learning (RL) provides stability in whole-body movement coordination, but a fixed reference makes it hard to adapt to varied ball positions and strike timings; in contrast, task reward-driven RL struggles to explore and discover valid kicks from scratch. We therefore introduce RoboNaldo, a three-stage motion-guided curriculum RL framework for high-impulse humanoid interaction. A single human-kick reference is used as a scaffold and progressively shifts optimization towards shooting performance. The curriculum first learns a stable whole-body kicking prior, then adapts the kick to free-kick settings where the ball is stationary at random positions, and finally extends it to moving-ball shooting through a locomotion-command and kick-trigger interface. A high-level heuristic planner controls this interface during training, while alternative high-level controllers can drive the same low-level policy at inference. In simulation, RoboNaldo demonstrates free-kick shot error 48.6% lower and shoot velocity 2.96x than prior work baselines. In real world on a Unitree G1 with onboard perception, RoboNaldo attains 0.73 m and 0.86 m average target shooting error from 3 m away in free-kick and moving-ball cases, accordingly. And the post-contact ball velocity reaches 13.10 m/s, which is 59-71% of reported professional open-play shot speed. Project page: https://opendrivelab.com/RoboNaldo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RoboNaldo, a three-stage motion-guided curriculum RL framework for humanoid soccer shooting. A single fixed human-kick reference motion serves as a scaffold: stage 1 learns a stable whole-body kicking prior, stage 2 adapts it to free-kick settings with stationary balls at random positions, and stage 3 extends it to moving-ball shooting via a locomotion-command and kick-trigger interface controlled by a high-level heuristic planner. The paper reports simulation results of 48.6% lower free-kick shot error and 2.96x higher shoot velocity versus prior baselines, plus real-world results on a Unitree G1 (onboard perception) of 0.73 m and 0.86 m average target error from 3 m in free-kick and moving-ball cases, with post-contact ball velocity of 13.10 m/s (59-71% of professional open-play speeds).
Significance. If the curriculum successfully generalizes as described, the work would demonstrate a practical way to combine motion-tracking stability with task-driven optimization for high-impulse whole-body interactions, offering a template for other dynamic humanoid tasks such as manipulation or locomotion under contact. The real-world transfer on commodity hardware with onboard sensing adds practical value.
major comments (1)
- [Abstract / Curriculum description] Abstract and curriculum description: the central performance claims (48.6% error reduction, 2.96x velocity, real-world errors of 0.73 m / 0.86 m) rest on the assumption that a single fixed human-kick reference can scaffold stable generalization across the three stages to random stationary and moving ball conditions without instability or loss of exploration. No ablations, failure-case analysis, or stage-wise contribution metrics are described to test whether the progressive reward shift preserves the prior or leads to collapse when ball locations/timings vary, which is load-bearing for the method's validity.
minor comments (2)
- [Abstract] The abstract states clear quantitative gains but does not report error bars, number of trials, or statistical tests; these should be added to support the reported margins.
- [Methods] Training details (hyperparameters, reward weights per stage, data exclusion rules, random seed handling) are referenced as missing in the reader's assessment and should be supplied for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the curriculum design. The comment correctly identifies a gap in the current manuscript regarding explicit validation of the three-stage progression. We will address this through targeted revisions.
read point-by-point responses
-
Referee: [Abstract / Curriculum description] Abstract and curriculum description: the central performance claims (48.6% error reduction, 2.96x velocity, real-world errors of 0.73 m / 0.86 m) rest on the assumption that a single fixed human-kick reference can scaffold stable generalization across the three stages to random stationary and moving ball conditions without instability or loss of exploration. No ablations, failure-case analysis, or stage-wise contribution metrics are described to test whether the progressive reward shift preserves the prior or leads to collapse when ball locations/timings vary, which is load-bearing for the method's validity.
Authors: We agree that additional analysis is needed to substantiate the curriculum's role. In the revised manuscript we will add: (1) stage-wise ablations measuring policy performance and stability metrics (e.g., kick success rate, joint torque limits, and reference tracking error) after each stage; (2) failure-case analysis on out-of-distribution ball positions and timings, including cases that cause instability or collapse; and (3) quantitative metrics tracking how the reward weighting shift affects preservation of the motion prior versus task performance. These results will be presented in a new subsection and supporting figures. The existing simulation and real-world performance numbers already provide indirect evidence of successful generalization, but the requested analyses will make the claims more robust. revision: yes
Circularity Check
No circularity: derivation relies on external baselines and standard RL curriculum without self-referential reductions
full rationale
The paper describes a three-stage motion-guided curriculum RL method that starts from a single fixed human-kick reference motion, then shifts optimization toward task rewards for stationary and moving balls. All reported performance numbers (48.6% lower error, 2.96x velocity in simulation; 0.73 m / 0.86 m real-world error; 13.10 m/s ball velocity) are measured against external prior-work baselines and real hardware, not derived from quantities defined inside the method itself. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claim therefore remains independently falsifiable and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Curriculum learning with a single motion reference can progressively adapt a policy from motion tracking to varied task conditions without loss of stability
Reference graph
Works this paper leans on
-
[1]
Haarnoja, B
T. Haarnoja, B. Moran, G. Lever, S. H. Huang, D. Tirumala, J. Humplik, M. Wulfmeier, S. Tunyasuvunakool, N. Y . Siegel, R. Hafner, et al. Learning agile soccer skills for a bipedal robot with deep reinforcement learning.Science Robotics, 9(89):eadi8022, 2024
2024
- [2]
- [3]
- [4]
-
[5]
X. B. Peng, P. Abbeel, S. Levine, and M. van de Panne. Deepmimic: Example-guided deep reinforcement learning of physics-based character skills.ACM Transactions on Graphics (TOG), 37(4):1–14, 2018
2018
-
[6]
X. B. Peng, Z. Ma, P. Abbeel, S. Levine, and A. Kanazawa. Amp: Adversarial motion priors for stylized physics-based character control.ACM Transactions on Graphics (TOG), 40(4):1–20, 2021
2021
-
[7]
B. De-la Cruz-Torres, A. Ruiz-de Alarc ´on-Quintero, and M. Navarro-Castro. The role of shot velocity in advanced post-shot metrics: Evidence from the UEFA european football championships.Data, 11(2):39, 2026. doi:10.3390/data11020039
- [8]
- [9]
-
[10]
Y . Ma, A. Cramariuc, F. Farshidian, and M. Hutter. Learning coordinated badminton skills for legged manipulators.Science Robotics, 10(102):eadu3922, 2025. doi:10.1126/scirobotics. adu3922
-
[11]
W. Li, J. Ma, M. Lu, and P. Lu. Like playing a video game: Spatial-temporal optimization of foot trajectories for controlled football kicking in bipedal robots. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3565–3572, 2025. doi:10.1109/ IROS60139.2025.11246655. arXiv:2510.01843. 9
-
[12]
Z. Xu, M. Seo, D. Lee, H. Fu, J. Hu, J. Cui, Y . Jiang, Z. Wang, A. Brund, J. Biswas, and P. Stone. Learning agile striker skills for humanoid soccer robots from noisy sensory input. InIEEE International Conference on Robotics and Automation (ICRA), 2026. arXiv:2512.06571
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [13]
- [14]
- [15]
-
[16]
D. Kalaria, S. S. Harithas, P. Katara, S. Kwak, S. Bhagat, S. Sastry, S. Sridhar, S. Vemprala, A. Kapoor, and J. C.-K. Huang. DreamControl: Human-inspired whole-body humanoid control for scene interaction via guided diffusion.arXiv preprint arXiv:2509.14353, 2025
-
[17]
Falcon: Learning force- adaptive humanoid loco-manipulation.arXiv preprint arXiv:2505.06776, 2025
Y . Zhang, Y . Yuan, P. Gurunath, I. Gupta, S. Omidshafiei, A.-a. Agha-mohammadi, M. Vazquez- Chanlatte, L. Pedersen, T. He, and G. Shi. FALCON: Learning force-adaptive humanoid loco-manipulation. InLearning for Dynamics and Control Conference (L4DC), 2026. arXiv:2505.06776
-
[18]
S. Xu, H. Y . Ling, Y .-X. Wang, and L.-Y . Gui. InterMimic: Towards universal whole-body control for physics-based human-object interactions. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 12266–12277, June 2025. doi:10.1109/CVPR52734.2025.01145. Highlight Paper
-
[19]
Bengio, J
Y . Bengio, J. Louradour, R. Collobert, and J. Weston. Curriculum learning. InProceedings of the 26th Annual International Conference on Machine Learning, pages 41–48, 2009
2009
-
[20]
Narvekar, B
S. Narvekar, B. Peng, M. Leonetti, J. Sinapov, M. E. Taylor, and P. Stone. Curriculum learning for reinforcement learning domains: A framework and survey.Journal of Machine Learning Research, 21(181):1–50, 2020
2020
-
[21]
Rudin, D
N. Rudin, D. Hoeller, P. Reist, and M. Hutter. Learning to walk in minutes using massively parallel deep reinforcement learning. InConference on Robot Learning, pages 91–100, 2022
2022
-
[22]
Z. Shen, H. Pi, Y . Xia, Z. Cen, S. Peng, Z. Hu, H. Bao, R. Hu, and X. Zhou. World-grounded human motion recovery via gravity-view coordinates. InSIGGRAPH Asia 2024 Conference Papers, 2024. doi:10.1145/3680528.3687565
- [23]
-
[24]
Q. Liao, T. E. Truong, X. Huang, Y . Gao, G. Tevet, K. Sreenath, and C. K. Liu. Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion.arXiv preprint arXiv:2508.08241, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Mittal, C
M. Mittal, C. Yu, Q. Yu, J. Liu, N. Rudin, D. Hoeller, J. L. Yuan, R. Singh, Y . Guo, H. Mazhar, et al. Orbit: A unified simulation framework for interactive robot learning environments.IEEE Robotics and Automation Letters, 8:3740–3747, 2023
2023
-
[26]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Unitree g1 humanoid robot.https://www.unitree.com/g1, 2024
Unitree Robotics. Unitree g1 humanoid robot.https://www.unitree.com/g1, 2024. 10
2024
-
[28]
Makoviychuk, L
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning. InAdvances in Neural Information Processing Systems, 2021
2021
-
[29]
Tobin, R
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 23–30, 2017
2017
-
[30]
X. B. Peng, M. Andrychowicz, W. Zaremba, and P. Abbeel. Sim-to-real transfer of robotic control with dynamics randomization. InIEEE International Conference on Robotics and Automation (ICRA), pages 3803–3810, 2018
2018
-
[31]
Jocher and J
G. Jocher and J. Qiu. Ultralytics YOLO11. https://docs.ultralytics.com/models/ yolo11/, 2024
2024
-
[32]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5026–5033, 2012. 11 A Observation Space: Per-Dimension Breakdown Table A.1: Policy observation vector (547 dims). †In Stage 3 the anchor reference is replaced by a 9-dim heuristic locomo...
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.