WEAVER, Better, Faster, Longer: An Effective World Model for Robotic Manipulation
Pith reviewed 2026-06-27 06:21 UTC · model grok-4.3
The pith
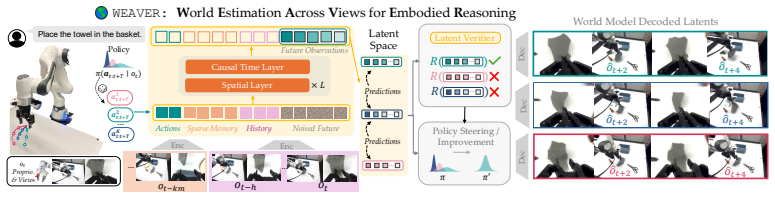
WEAVER uses a multi-view flow-matching world model to simulate robotic manipulation with high fidelity, long-term consistency, and speed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
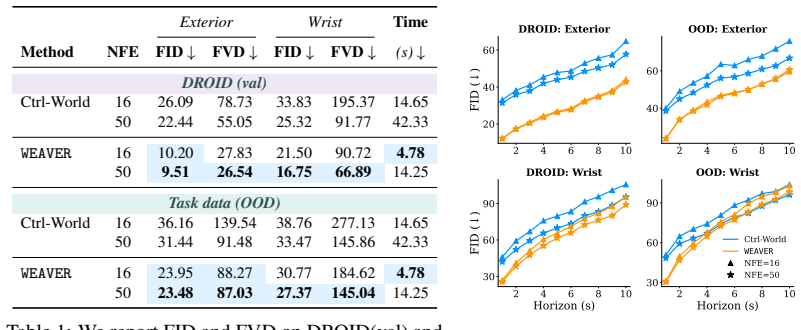
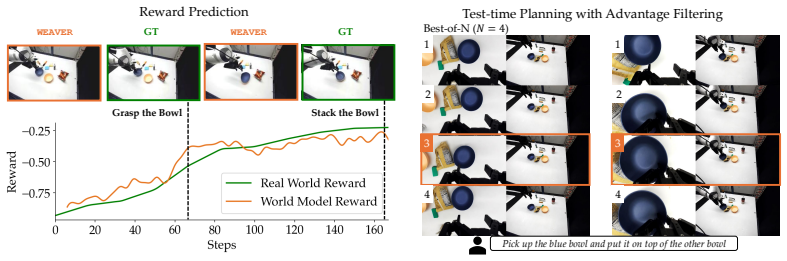
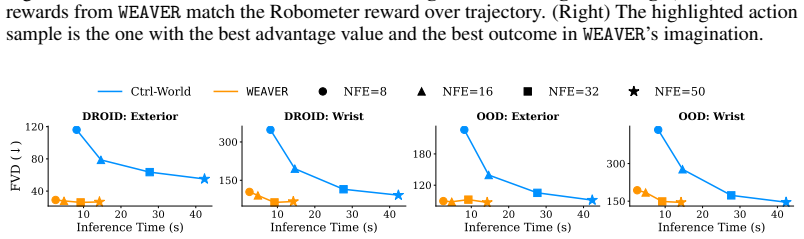
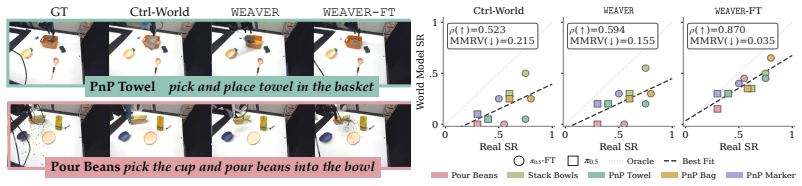
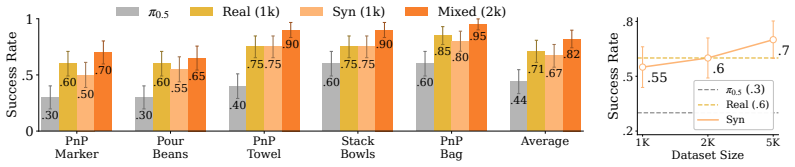
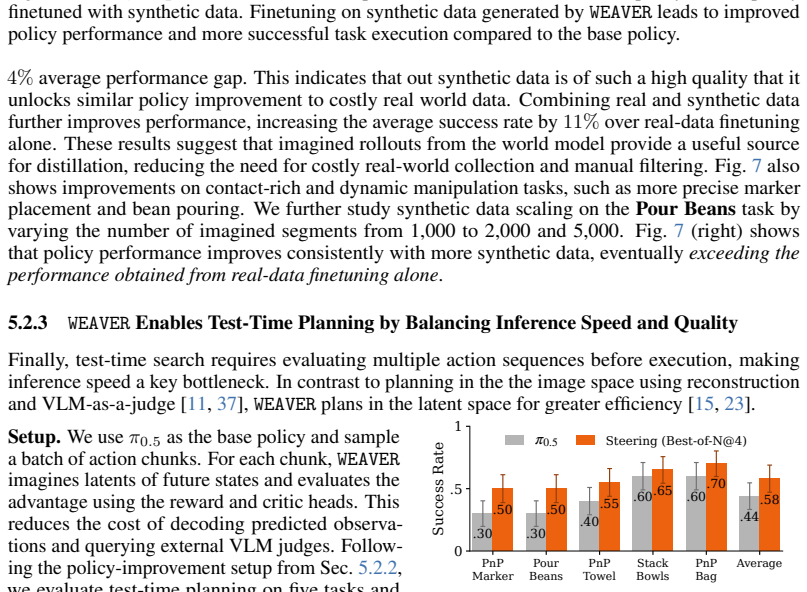
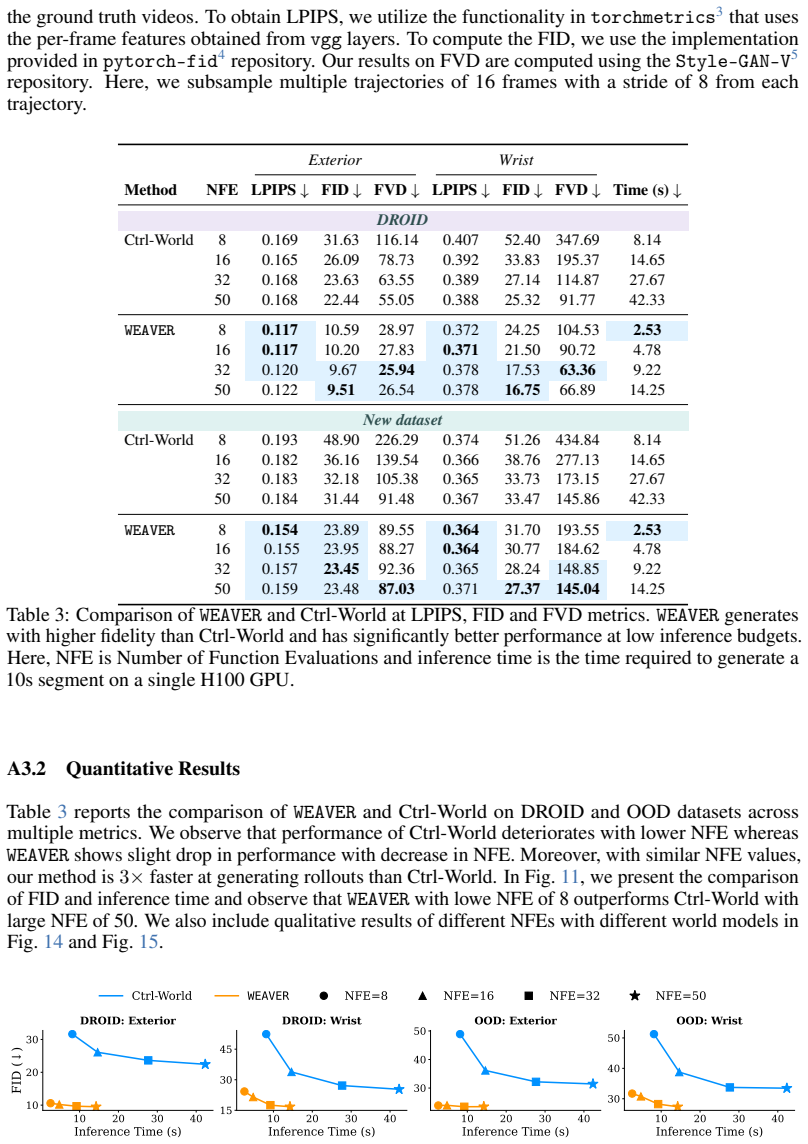
WEAVER is a multi-view world model trained to predict future latents and reward values via a flow-matching loss. It simultaneously satisfies fidelity measured by 0.870 correlation with real-world success rates, consistency over long horizons for dynamic manipulation, and efficiency with 5-10 times speedup over prior world models, producing 38 percent real-world success improvement for policy improvement and 14 percent improvement for test-time planning on robotic hardware, with better out-of-distribution results than earlier approaches.
What carries the argument
Multi-view architecture trained with flow-matching loss to predict future latents and rewards, allowing joint satisfaction of fidelity, consistency, and efficiency.
If this is right
- Policy evaluation can rely on simulated rollouts with 0.870 correlation to real outcomes instead of extensive hardware trials.
- Policy improvement on top of a foundation model reaches 38 percent higher real success rates through simulated data.
- Test-time planning gains 14 percent success with 5-10 times faster simulation than earlier world models.
- Performance remains higher than prior world models when tested on out-of-distribution manipulation scenarios.
Where Pith is reading between the lines
- The same multi-view flow-matching design could reduce real-world data needs for other robot learning settings that require long-horizon prediction.
- Replacing standard prediction losses with flow-matching might improve coherence in world models used for non-manipulation tasks.
- Embedding this style of world model into additional robot foundation models could further cut the amount of physical interaction required for training.
Load-bearing premise
The measured correlation between simulated trajectories and real success rates carries over to policy improvement and planning experiments on the tested hardware and tasks without further adjustments.
What would settle it
Replicating the policy improvement experiments on new hardware or tasks and measuring no statistically significant real-world success gains would show the simulation-to-reality transfer does not hold as claimed.
Figures












read the original abstract
The potential impacts of world models (WMs, i.e., learned simulators) on robotics are far-reaching -- policy evaluation, policy improvement, and test-time planning -- all with limited real-world interaction. To unlock these downstream capabilities, a WM needs to jointly satisfy three desiderata: $\textit{(i)}$ fidelity (i.e., producing simulated trajectories that correlate with reality), $\textit{(ii)}$ consistency (i.e., producing simulated trajectories that are coherent over long horizons), and $\textit{(iii)}$ efficiency (i.e., producing simulated trajectories quickly). We propose WEAVER (World Estimation Across Views for Embodied Reasoning): a WM architecture that simultaneously achieves all three desiderata, providing state-of-the-art results on robotic manipulation tasks. WEAVER is a multi-view WM trained to predict future latents and reward values via a flow-matching loss. We distill the key design decisions across model architecture, memory, and prediction objectives required to unlock the kinds of long-horizon dynamic manipulation tasks that have confounded prior world modeling approaches. We apply WEAVER in robotic hardware, demonstrating its effectiveness at policy evaluation ($\rho$=0.870 correlation with real-world success rate), policy improvement (real-world success rate improvement of $38\%$ on top of the $\pi_{0.5}$ robot foundation model), and test-time planning (real-world success rate improvement of $14\%$ with a $5-10\times$ speedup over prior WMs). WEAVER also demonstrates better performance than prior WMs when evaluated on out-of-distribution scenarios. Code, models, and videos at: https://arnavkj1995.github.io/WEAVER/ .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes WEAVER, a multi-view world model for robotic manipulation trained via flow-matching to predict future latents and rewards. It claims to jointly achieve fidelity (ρ=0.870 correlation with real-world success rates), consistency over long horizons, and efficiency, enabling state-of-the-art results in policy evaluation, 38% real-world success rate improvement for policy improvement on top of π_{0.5}, and 14% improvement with 5-10× speedup in test-time planning, plus better out-of-distribution performance.
Significance. If the empirical claims hold with proper statistical support, WEAVER would represent a meaningful step forward for world models in robotics by distilling architectural and objective choices that address long-horizon manipulation challenges, directly linking the three desiderata to measurable gains in policy improvement and planning with limited real-world data. The public release of code, models, and videos strengthens reproducibility.
major comments (2)
- [Experiments] Experiments section: the fidelity claim rests on ρ=0.870 correlation with real-world success rate, yet no error bars, number of independent trials, data selection criteria, or verification procedure for the metric are provided; this directly affects assessment of whether the correlation supports the reported 38% and 14% downstream gains.
- [Policy Improvement and Test-time Planning] Policy improvement and test-time planning results: the manuscript does not include an explicit analysis or ablation demonstrating that the measured correlation transfers to the observed success-rate improvements without unstated task- or hardware-specific adjustments, which is load-bearing for the central claim that fidelity + consistency + efficiency jointly enable the gains.
minor comments (2)
- [Method] Notation for the flow-matching loss and latent prediction objectives could be clarified with an explicit equation reference to distinguish from prior flow-matching formulations.
- [Figures] Figure captions for qualitative trajectory comparisons should explicitly state the horizon length and number of rollouts shown to aid assessment of consistency.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating where revisions will strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the fidelity claim rests on ρ=0.870 correlation with real-world success rate, yet no error bars, number of independent trials, data selection criteria, or verification procedure for the metric are provided; this directly affects assessment of whether the correlation supports the reported 38% and 14% downstream gains.
Authors: We agree that these statistical details are required for rigorous assessment. In the revised manuscript we will add error bars computed across independent trials, report the exact number of trials and seeds, specify data selection criteria for the correlation computation, and describe the verification procedure. These additions will clarify the reliability of ρ=0.870 and its relation to the reported downstream gains. revision: yes
-
Referee: [Policy Improvement and Test-time Planning] Policy improvement and test-time planning results: the manuscript does not include an explicit analysis or ablation demonstrating that the measured correlation transfers to the observed success-rate improvements without unstated task- or hardware-specific adjustments, which is load-bearing for the central claim that fidelity + consistency + efficiency jointly enable the gains.
Authors: The experiments separately establish the correlation via policy evaluation and demonstrate the success-rate gains via dedicated policy-improvement and test-time-planning sections on the same hardware and tasks. We acknowledge that an explicit linking analysis would strengthen the argument. In revision we will add a dedicated discussion that examines how the fidelity metric aligns with the observed improvements and notes any task- or hardware-specific factors; we will also include any feasible ablations using existing data. revision: partial
Circularity Check
No significant circularity
full rationale
The paper presents WEAVER as an empirical architecture for world models in robotics, trained via flow-matching on multi-view latents and rewards, with performance validated through direct hardware experiments measuring correlation (ρ=0.870), policy improvement (+38%), and planning speedup (+14% at 5-10×). No equations, derivations, or self-referential definitions appear that would reduce any claimed prediction or result to its own fitted inputs by construction. The three desiderata (fidelity, consistency, efficiency) are tied to downstream metrics via external benchmarks rather than internal renaming or self-citation chains. The central claims rest on reproducible hardware comparisons outside any fitted parameter loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Thinking fast and slow with deep learning and tree search
Thomas Anthony, Zheng Tian, and David Barber. Thinking fast and slow with deep learning and tree search. InNeural Information Processing Systems (NeurIPS), 2017
2017
-
[2]
Self-supervised learning from images with a joint- embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint- embedding predictive architecture. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, (CVPR), 2023
2023
-
[3]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.CoRR, abs/2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.CoRR, abs/2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Robust noise attenuation via adaptive pooling of transformer outputs
Greyson Brothers. Robust noise attenuation via adaptive pooling of transformer outputs. In International Conference on Learning Representations (ICLR), 2025
2025
-
[6]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[7]
Diffusion forcing: Next-token prediction meets full-sequence diffusion
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion. InNeural Information Processing Systems (NeurIPS), 2024
2024
-
[8]
Jade Copet, Quentin Carbonneaux, Gal Cohen, Jonas Gehring, Jacob Kahn, Jannik Kossen, Felix Kreuk, Emily McMilin, Michel Meyer, Yuxiang Wei, et al. Cwm: An open-weights llm for research on code generation with world models.CoRR, abs/2510.02387, 2025
-
[9]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[10]
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
Shenyuan Gao, William Liang, Kaiyuan Zheng, Ayaan Malik, Seonghyeon Ye, Sihyun Yu, Wei-Cheng Tseng, Yuzhu Dong, Kaichun Mo, Chen-Hsuan Lin, et al. Dreamdojo: A generalist robot world model from large-scale human videos.CoRR, abs/2602.06949, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Yanjiang Guo, Tony Lee, Lucy Xiaoyang Shi, Jianyu Chen, Percy Liang, and Chelsea Finn. Vlaw: Iterative co-improvement of vision-language-action policy and world model.CoRR, abs/2602.12063, 2026
-
[12]
Ctrl-world: A controllable generative world model for robot manipulation
Yanjiang Guo, Lucy Xiaoyang Shi, Jianyu Chen, and Chelsea Finn. Ctrl-world: A controllable generative world model for robot manipulation. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[13]
David Ha and Jürgen Schmidhuber. World models.CoRR, abs/1803.10122, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Dream to control: Learning behaviors by latent imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. InInternational Conference on Learning Representa- tions (ICLR), 2020
2020
-
[15]
Mastering atari with discrete world models
Danijar Hafner, Timothy P Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[16]
Training Agents Inside of Scalable World Models
Danijar Hafner, Wilson Yan, and Timothy Lillicrap. Training agents inside of scalable world models.CoRR, abs/2509.24527, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Temporal difference learning for model predictive control
Nicklas Hansen, Xiaolong Wang, and Hao Su. Temporal difference learning for model predictive control. InInternational Conference on Machine Learning (ICML), 2022. 11
2022
-
[18]
Matrix-game 2.0: An open-source real-time and streaming interactive world model
Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Yangyang Ren, et al. Matrix-game 2.0: An open-source real-time and streaming interactive world model.CoRR, abs/2508.13009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Query-key normalization for transformers
Alex Henry, Prudhvi Raj Dachapally, Shubham Shantaram Pawar, and Yuxuan Chen. Query-key normalization for transformers. InConference on Empirical Methods in Natural Language Processing (EMNLP), 2020
2020
-
[20]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. InNeural Information Processing Systems (NeurIPS), 2017
2017
-
[21]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. pi0.5: a vision- language-action model with open-world generalization.CoRR, abs/2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Learning robust dynamics through variational sparse gating
Arnav Kumar Jain, Shiva Kanth Sujit, Shruti Joshi, Vincent Michalski, Danijar Hafner, and Samira Ebrahimi Kahou. Learning robust dynamics through variational sparse gating. InNeural Information Processing Systems (NeurIPS), 2022
2022
-
[23]
A smooth sea never made a skilled SAILOR: Robust imitation via learning to search
Arnav Kumar Jain, Vibhakar Mohta, Subin Kim, Atiksh Bhardwaj, Juntao Ren, Yunhai Feng, Sanjiban Choudhury, and Gokul Swamy. A smooth sea never made a skilled SAILOR: Robust imitation via learning to search. InNeural Information Processing Systems (NeurIPS), 2026
2026
-
[24]
Yuxin Jiang, Shengcong Chen, Siyuan Huang, Liliang Chen, Pengfei Zhou, Yue Liao, Xindong He, Chiming Liu, Hongsheng Li, Maoqing Yao, et al. Enerverse-ac: Envisioning embodied environments with action condition.CoRR, abs/2505.09723, 2025
-
[25]
Huang, Luke Zettlemoyer, Dieter Fox, Yu Xiang, Anqi Li, Andreea Bobu, Abhishek Gupta, Stephen Tu, Erdem Biyik, and Jesse Zhang
Anthony Liang, Yigit Korkmaz, Jiahui Zhang, Minyoung Hwang, Abrar Anwar, Sidhant Kaushik, Aditya Shah, Alex S. Huang, Luke Zettlemoyer, Dieter Fox, Yu Xiang, Anqi Li, Andreea Bobu, Abhishek Gupta, Stephen Tu, Erdem Biyik, and Jesse Zhang. Robometer: Scaling general-purpose robotic reward models via trajectory comparisons. InRobotics: Science and Systems 2...
2026
-
[26]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In International Conference on Learning Representations (ICLR), 2024
2024
-
[27]
Flow matching for generative modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[28]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[29]
Zhiting Mei, Tenny Yin, Ola Shorinwa, Apurva Badithela, Zhonghe Zheng, Joseph Bruno, Madison Bland, Lihan Zha, Asher Hancock, Jaime Fernández Fisac, et al. Video generation models in robotics-applications, research challenges, future directions.CoRR, abs/2601.07823, 2026
-
[30]
Sprint: Sparse-dense residual fusion for efficient diffusion transformers
Dogyun Park, Moayed Haji-Ali, Yanyu Li, Willi Menapace, Sergey Tulyakov, Hyunwoo J Kim, Aliaksandr Siarohin, and Anil Kag. Sprint: Sparse-dense residual fusion for efficient diffusion transformers. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[31]
Notes on the history of correlation.Biometrika, 13(1):25–45, 1920
Karl Pearson. Notes on the history of correlation.Biometrika, 13(1):25–45, 1920
1920
-
[32]
Inference-time enhancement of generative robot policies via predictive world modeling.IEEE Robotics and Automation Letters, 11(5):5534–5541, 2026
Han Qi, Haocheng Yin, Aris Zhu, Yilun Du, and Heng Yang. Inference-time enhancement of generative robot policies via predictive world modeling.IEEE Robotics and Automation Letters, 11(5):5534–5541, 2026
2026
-
[33]
Worldgym: World model as an environment for policy evaluation
Julian Quevedo, Ansh Kumar Sharma, Yixiang Sun, Varad Suryavanshi, Percy Liang, and Sherry Yang. Worldgym: World model as an environment for policy evaluation. InInternational Conference on Learning Representations (ICLR), 2026. 12
2026
-
[34]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning (ICML), 2021
2021
-
[35]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[36]
GAIA-2: A Controllable Multi-View Generative World Model for Autonomous Driving
Lloyd Russell, Anthony Hu, Lorenzo Bertoni, George Fedoseev, Jamie Shotton, Elahe Arani, and Gianluca Corrado. Gaia-2: A controllable multi-view generative world model for autonomous driving (2025).CoRR, abs/2503.20523, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Ansh Kumar Sharma, Yixiang Sun, Ninghao Lu, Yunzhe Zhang, Jiarao Liu, and Sherry Yang. World-gymnast: Training robots with reinforcement learning in a world model.CoRR, abs/2602.02454, 2026
-
[38]
GLU Variants Improve Transformer
Noam Shazeer. Glu variants improve transformer.CoRR, abs/2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[39]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[40]
MIT press Cambridge, 1998
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
1998
-
[41]
Droid: A large-scale in-the-wild robot manipulation dataset
DROID Team. Droid: A large-scale in-the-wild robot manipulation dataset. InRobotics: Science and Systems, 2024
2024
-
[42]
arXiv preprint arXiv:2512.10675 (2025)
Gemini Robotics Team, Krzysztof Choromanski, Coline Devin, Yilun Du, Debidatta Dwibedi, Ruiqi Gao, Abhishek Jindal, Thomas Kipf, Sean Kirmani, Isabel Leal, et al. Evaluating gemini robotics policies in a veo world simulator.CoRR, abs/2512.10675, 2025
-
[43]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges. CoRR, abs/1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[44]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[45]
Drive- dreamer: Towards real-world-drive world models for autonomous driving
Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jiagang Zhu, and Jiwen Lu. Drive- dreamer: Towards real-world-drive world models for autonomous driving. InEuropean Confer- ence on Computer Vision (ECCV), 2024
2024
-
[46]
Interactive world simulator for robot policy training and evaluation.CoRR, abs/2603.08546, 2026
Yixuan Wang, Rhythm Syed, Fangyu Wu, Mengchao Zhang, Aykut Onol, Jose Barreiros, Hooshang Nayyeri, Tony Dear, Huan Zhang, and Yunzhu Li. Interactive world simulator for robot policy training and evaluation.CoRR, abs/2603.08546, 2026
-
[47]
Video models are zero-shot learners and reasoners
Thaddäus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos. Video models are zero-shot learners and reasoners. CoRR, abs/2509.20328, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
The spearman correlation formula.Science, 22(558):309–311, 1905
Clark Wissler. The spearman correlation formula.Science, 22(558):309–311, 1905
1905
-
[49]
Day- dreamer: World models for physical robot learning
Philipp Wu, Alejandro Escontrela, Danijar Hafner, Pieter Abbeel, and Ken Goldberg. Day- dreamer: World models for physical robot learning. InConference on Robot Learning (CoRL), 2023
2023
-
[50]
From foresight to forethought: Vlm- in-the-loop policy steering via latent alignment
Yilin Wu, Ran Tian, Gokul Swamy, and Andrea Bajcsy. From foresight to forethought: Vlm- in-the-loop policy steering via latent alignment. InRobotics: Science and Systems (RSS), 2025
2025
-
[51]
PlayWorld: Learning Robot World Models from Autonomous Play
Tenny Yin, Zhiting Mei, Zhonghe Zheng, Miyu Yamane, David Wang, Jade Sceats, Samuel M Bateman, Lihan Zha, Apurva Badithela, Ola Shorinwa, et al. Playworld: Learning robot world models from autonomous play.CoRR, abs/2603.09030, 2026. 13
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
Root mean square layer normalization
Biao Zhang and Rico Sennrich. Root mean square layer normalization. InNeural Information Processing Systems (NeurIPS), 2019
2019
-
[53]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018
2018
-
[54]
Dino-wm: World models on pre-trained visual features enable zero-shot planning
Gaoyue Zhou, Hengkai Pan, Yann LeCun, and Lerrel Pinto. Dino-wm: World models on pre-trained visual features enable zero-shot planning. InInternational Conference on Machine Learning (ICML), 2025. 14 Contents A1 Robot Setup & Tasks 16 A1.1 Tasks Details . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 A1.2 Action Space . . . . ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.